- The paper introduces a dual-system framework that integrates MLLM-based agentic reasoning with a multimodal diffusion transformer to generate expressive avatar animations.
- The framework achieves state-of-the-art scores on FID, FVD, and hand keypoint metrics while ensuring semantic alignment and reduced motion unnaturalness.
- The approach enables robust performance across diverse subjects and complex multi-person scenarios by coordinating context-aware, semantically coherent behaviors.
Cognitive Simulation for Lifelike Avatar Animation: OmniHuman-1.5
Introduction and Motivation
OmniHuman-1.5 addresses a fundamental limitation in video avatar generation: the inability of existing models to synthesize character behaviors that are not only physically plausible but also semantically coherent and contextually expressive. Prior approaches predominantly rely on direct mappings from low-level cues (e.g., audio rhythm) to motion, resulting in repetitive, non-contextual outputs that lack authentic intent or emotion. The paper frames this gap through the lens of dual-system cognitive theory, distinguishing between reactive (System 1) and deliberative (System 2) processes. The proposed framework explicitly models both systems, leveraging Multimodal LLMs (MLLMs) for high-level reasoning and a specialized Multimodal Diffusion Transformer (MMDiT) for reactive rendering.
Figure 1: The framework simulates both System 1 and System 2 cognition, producing avatar behaviors that are diverse, contextually coherent, and semantically aligned with multimodal inputs.
Dual-System Simulation Framework
The architecture integrates two principal components:
- Agentic Reasoning (System 2): MLLM-based agents analyze multimodal inputs (audio, image, text) to generate a structured semantic schedule. This schedule encodes persona, intent, emotion, and environmental context, guiding the avatar's actions over time. The reasoning pipeline consists of an Analyzer (for context extraction) and a Planner (for action scheduling), both prompted via Chain-of-Thought (CoT) techniques. The framework supports reflective re-planning, allowing the Planner to revise its schedule based on generated outputs, thereby maintaining logical consistency in long-form synthesis.
- Multimodal Diffusion Transformer (System 1):
The MMDiT backbone fuses high-level semantic guidance with low-level reactive signals. Dedicated branches for audio, text, and video are fused via shared multi-head self-attention, enabling deep semantic alignment. The pseudo last frame strategy replaces conventional reference image conditioning, mitigating training artifacts and enhancing motion diversity without sacrificing identity preservation.
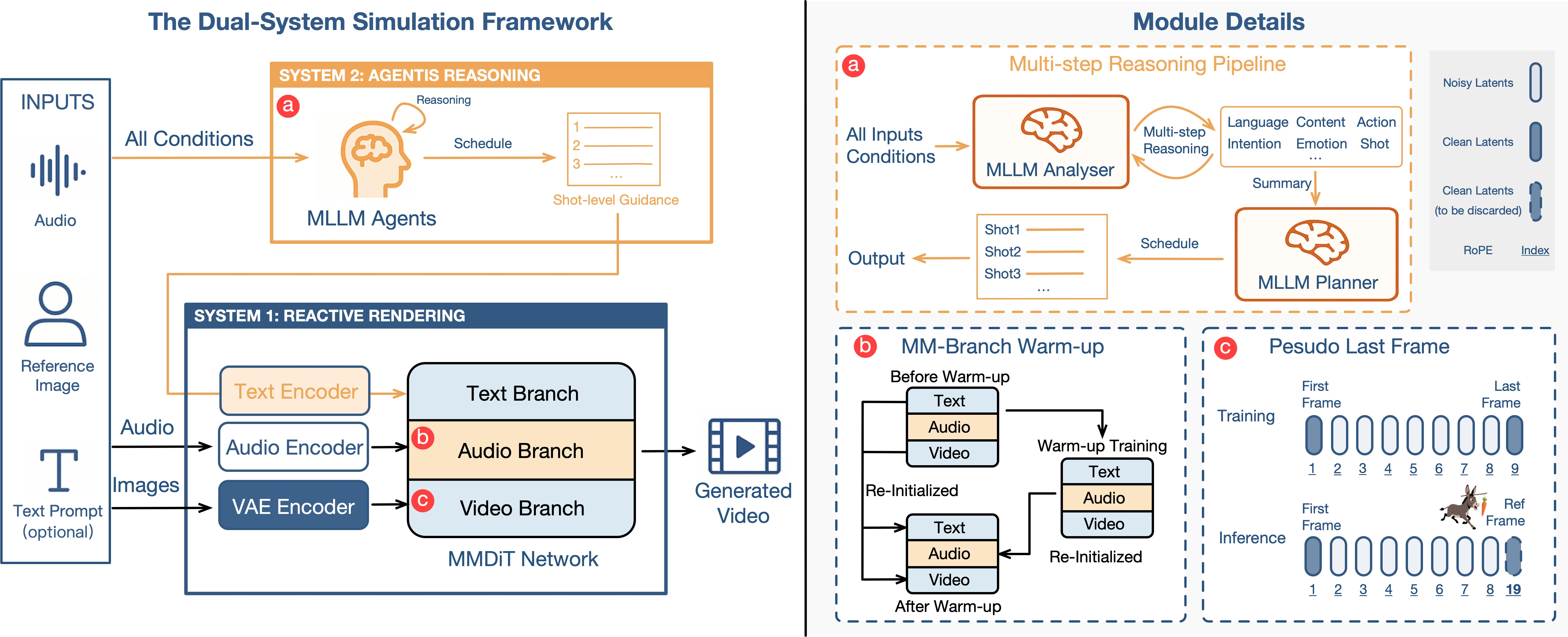
Figure 2: The dual-system pipeline integrates agentic reasoning for planning and multimodal fusion for rendering, with architectural innovations to resolve modality conflicts.
Generalization and Multi-Person Capabilities
The model demonstrates robust generalization across diverse subjects, including non-human and animated characters. In multi-person scenarios, speaker-specific masks and agentic reasoning enable coordinated, context-aware behaviors for all individuals in the scene. The Planner is augmented to handle speaker identification, and the fusion process ensures accurate audio-to-motion mapping for each character.
Figure 3: The model generalizes to non-human subjects and multi-person scenes, maintaining contextual coherence and coordinated behaviors.
Empirical Evaluation
Extensive experiments validate the framework's effectiveness:
The model achieves top-tier scores in FID, FVD, Sync-C, IQA, and hand keypoint metrics across both portrait and full-body benchmarks. Notably, it maintains high HKV (motion dynamics) without degrading HKC (local detail), outperforming strong baselines such as OmniHuman-1.
Human evaluators consistently prefer OmniHuman-1.5 for naturalness, plausibility, and semantic alignment. The model achieves a 33% Top-1 selection rate in best-choice tasks and a positive GSB score in pairwise comparisons against both academic and proprietary models. The agentic reasoning module yields a >20% reduction in perceived motion unnaturalness.
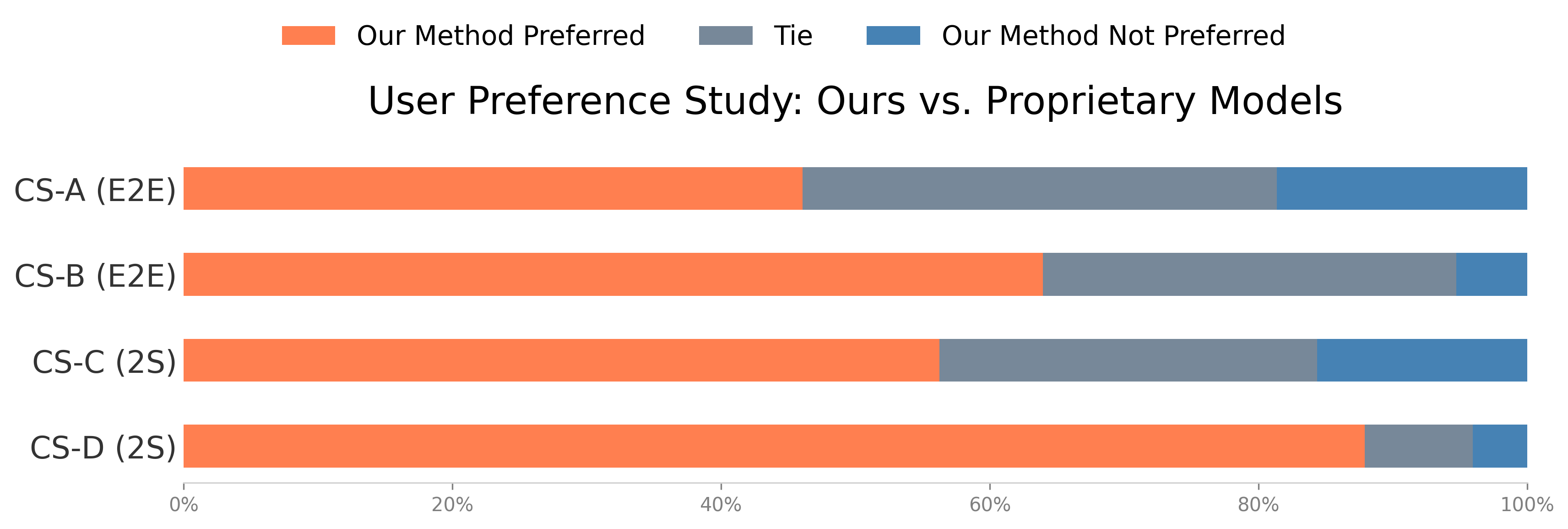
Figure 4: User studies confirm significant preference for the proposed method over academic and proprietary baselines.
Ablation and Qualitative Analysis
Ablation studies isolate the contributions of agentic reasoning and conditioning modules. Removing reasoning leads to static, less expressive animations, while omitting the pseudo last frame or MM-branch warm-up degrades motion diversity and semantic coherence. Qualitative results highlight the reflection process's ability to correct illogical action sequences and the model's superior semantic alignment compared to prior work.

Figure 5: Reflection enables logical correction of action plans, maintaining object and narrative consistency.

Figure 6: The model generates actions with higher semantic consistency to speech prompts than OmniHuman-1, accurately depicting described behaviors.
Implementation Considerations
The model is trained on 15,000 hours of filtered video data, with staged warm-up and fine-tuning phases to mitigate modality conflicts. The pseudo last frame strategy is critical for avoiding spurious correlations and ensuring dynamic motion.
The framework supports autoregressive synthesis for long-form videos, with reflection optionally enabled for enhanced logical consistency. Multi-person support is achieved via plug-and-play speaker mask predictors and Planner augmentation.
Training utilizes 256 compute nodes, with efficient parameterization in the audio branch to minimize overhead. The architecture is scalable to higher resolutions via super-resolution modules.
Implications and Future Directions
The explicit modeling of cognitive agency in avatar generation represents a significant step toward lifelike digital humans capable of context-aware, expressive behaviors. The dual-system framework is extensible to interactive conversational agents, creative content production, and multi-agent simulations. The integration of MLLM-driven planning with diffusion-based rendering sets a precedent for controllable, semantically rich generative models.
Potential future developments include:
- Enhanced real-time interaction via accelerated inference and more efficient agentic reasoning.
- Deeper integration of multimodal feedback for adaptive behavior synthesis.
- Extension to open-domain scenarios and unscripted multi-agent environments.
- Further exploration of ethical safeguards, including watermarking and content filtering, to mitigate misuse risks.
Conclusion
OmniHuman-1.5 introduces a dual-system cognitive simulation paradigm for avatar video generation, combining MLLM-based agentic reasoning with a specialized multimodal diffusion architecture. The framework achieves state-of-the-art performance in both objective and subjective evaluations, generating expressive, contextually coherent, and logically consistent character animations. The approach is robust to diverse subjects and complex multi-person scenarios, offering a scalable foundation for the next generation of lifelike digital humans and interactive agents.