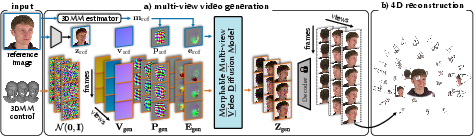
MVP4D: Multi-View Portrait Video Diffusion for Animatable 4D Avatars
Abstract: Digital human avatars aim to simulate the dynamic appearance of humans in virtual environments, enabling immersive experiences across gaming, film, virtual reality, and more. However, the conventional process for creating and animating photorealistic human avatars is expensive and time-consuming, requiring large camera capture rigs and significant manual effort from professional 3D artists. With the advent of capable image and video generation models, recent methods enable automatic rendering of realistic animated avatars from a single casually captured reference image of a target subject. While these techniques significantly lower barriers to avatar creation and offer compelling realism, they lack constraints provided by multi-view information or an explicit 3D representation. So, image quality and realism degrade when rendered from viewpoints that deviate strongly from the reference image. Here, we build a video model that generates animatable multi-view videos of digital humans based on a single reference image and target expressions. Our model, MVP4D, is based on a state-of-the-art pre-trained video diffusion model and generates hundreds of frames simultaneously from viewpoints varying by up to 360 degrees around a target subject. We show how to distill the outputs of this model into a 4D avatar that can be rendered in real-time. Our approach significantly improves the realism, temporal consistency, and 3D consistency of generated avatars compared to previous methods.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces MVP4D, a method that can create a lifelike, fully animatable “4D avatar” of a person starting from just one photo. The avatar looks real from all around the head (up to 360 degrees), moves smoothly, and can be controlled to make different expressions or head poses. The key idea is to first generate short videos of the person from several camera angles at the same time, and then turn those videos into a 3D character you can render in real time.
Goals and Questions
The researchers set out to answer simple, practical questions:
- Can we make realistic, animated digital people from a single photo, without expensive multi-camera setups?
- Can the animation stay consistent when viewed from many angles (so the face doesn’t “change” shape as the camera moves)?
- Can we control expressions and head pose precisely (smiles, blinks, turns), and keep the motion smooth over time?
- Can we convert the generated videos into a 3D avatar that runs in real time?
How It Works (in everyday language)
Think of the system like a movie studio and a turntable:
- You give it one photo of a person.
- It imagines that person on a turntable and “films” them from several camera angles at once, while the person moves their face and head (smiles, talks, looks around).
- Then it uses those “multi-angle movies” to build a detailed 3D character that can be animated in real time.
Here are the main steps, explained simply:
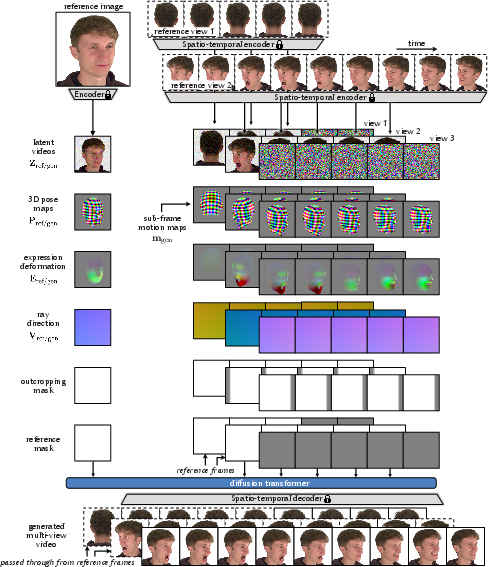
- Reading the photo and setting controls
- A face tracker looks at your photo and figures out a 3D face model: the head position, the facial expression, and where a virtual camera would be looking.
- This model is like a digital blueprint of your face (based on FLAME, a standard 3D head model).
- Multi-view video generation with diffusion
- MVP4D uses a “video diffusion model.” Imagine starting from a screen filled with TV static and then cleaning it up step by step until it becomes a realistic video. That’s what diffusion does.
- Unlike regular video AI that makes one video at a time, MVP4D makes several short videos at once, each from a different camera angle around the head. This helps keep things consistent across views.
- The model is based on a strong video AI called CogVideoX and adapted to understand many views and frames together.
- Smart training with mixed data
- There isn’t a big dataset of multi-view portrait videos (people filmed from many cameras at once), so they trained cleverly:
- Single-camera videos (to learn motion over time),
- Multi-view images (lots of photos from different angles, to learn 3D consistency),
- Some multi-view videos (to bridge both).
- A “training curriculum” slowly increases resolution, number of frames, and number of angles so the model learns efficiently.
- There isn’t a big dataset of multi-view portrait videos (people filmed from many cameras at once), so they trained cleverly:
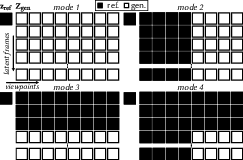
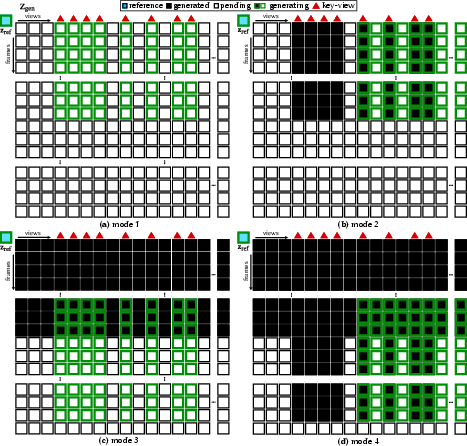
- Generation modes to scale up
- They use four “modes” during training and generation:
- Mode 1: generate everything from the one photo.
- Mode 2: use some angles as references to help generate the rest.
- Mode 3: use early frames as references to extend the video longer.
- Mode 4: combine Modes 2 and 3 to grow both angles and length.
- This lets them produce up to 48 views and 89 frames per view by expanding from “key” videos.
- They use four “modes” during training and generation:
- Turning videos into a real-time 4D avatar
- They fit a 3D representation called “Gaussian splatting.” Think of placing lots of tiny soft 3D dots (Gaussians) on a face mesh so, together, they render a detailed, lifelike head.
- The Gaussians move with the face mesh (based on the 3D face model), and a small neural network adds fine details like wrinkles that change with expressions.
- For hair, glasses, and earrings (which aren’t part of the face mesh), they detect matching points across angles and estimate their 3D positions, then attach extra Gaussians for these.
- After fitting, the avatar renders in real time at 512×512 resolution.
- Extra tricks that make it work well
- Multi-view guidance: A special “classifier-free guidance” trick helps keep each camera angle coherent without confusing views.
- Attention scaling: A math tweak keeps the AI focused when handling lots of frames and angles.
Main Results and Why They Matter
In tests against other methods, MVP4D showed strong improvements:
- More frames and angles at once
- MVP4D generates hundreds of frames across multiple views in a single run (e.g., 8 views × 49 frames = 392 frames), much more than many baselines.
- Better smoothness over time
- It scored higher on a motion smoothness metric (JOD), meaning less flicker and more stable animation.
- Strong 3D consistency
- It kept the face shape and features consistent as the camera moved around, reducing warping or mismatches between views.
- Human preference study
- In side-by-side comparisons, people preferred MVP4D most of the time for visual detail, expression transfer, motion quality, and overall look.
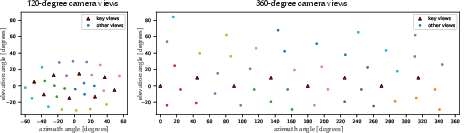
- Works all around the head
- MVP4D handles full 360° views better than methods that only work from the front.
These results matter because they show you can get a high-quality, lifelike avatar from just one photo, that stays believable even as the camera moves.
Implications and Impact
This research lowers the barrier to creating realistic digital humans:
- Practical uses
- Games, movies, and VR can get detailed avatars without expensive, time-consuming multi-camera setups.
- Social apps, education, and virtual meetings could use controllable, expressive avatars.
- You can drive the avatar with a video or even speech audio, and the team shows a text-to-4D pipeline too (generate a photo from text, then build the avatar).
- Controls and realism
- Precise control over head pose and expression makes animation more reliable and creative.
- Real-time rendering means avatars can be used interactively.
- Current limits
- Fast, tiny changes (like teeth appearing/disappearing quickly) are hard because the video encoder compresses time heavily.
- Very long sequences gradually lose quality when extended over and over.
- Extreme lighting isn’t handled well due to limited training data.
- Generating many views and frames takes hours on a high-end GPU.
Overall, MVP4D is a step toward making high-quality, animatable digital people from simple inputs. It mixes powerful video generation with clever training and a solid 3D reconstruction technique to produce avatars that look consistent, move smoothly, and render in real time.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a consolidated list of concrete gaps, limitations, and open questions left unresolved by the paper. Each item is phrased to enable actionable follow-up work.
- Lack of large-scale, diverse multi-view portrait video datasets: the curriculum compensates with mixed modalities, but it remains unclear how performance would scale with genuine large multi-view video training, especially for extreme motions, occlusions, and lighting.
- Reliance on an off-the-shelf 3DMM/face tracker (FlowFace/FLAME): robustness under tracker failure (e.g., occlusions, extreme expressions, fast motion, profile views) is not quantified; error propagation from tracking to generation and reconstruction remains unstudied.
- Limited lighting variability in training data: the model struggles with extreme or complex lighting; there is no relighting control or explicit modeling of specularities (e.g., eye highlights, glossy skin), backlighting, and shadows.
- Autoencoder temporal compression (4x) and VAE design constraints: high compression limits fine-grained dynamics (e.g., rapid teeth visibility, tongue and lip micro-motions, subtle eye blinks); the trade-off between compression level and temporal fidelity is not explored.
- Degradation in long-sequence generation: iterative first-frame conditioning (mode 3) causes cumulative quality decay; maximum sustainable video length and strategies to prevent drift are not characterized.
- Multi-view classifier-free guidance (CFG) requires per-view unconditional passes: this increases inference cost; alternative unconditional conditioning strategies that preserve view specificity without per-view forward passes remain unexplored.
- Scaling beyond 8 jointly generated views: while inference with V=8 improves quality over the trained V=4, the model’s stability, consistency, and failure modes when further increasing V (e.g., V≥16) are unknown.
- Generalization to 360° beyond limited 360° training data: the extent to which performance degrades for rear and extreme elevation views (especially hair and ear regions) has not been systematically quantified.
- Real-time rendering limited to 512×512: scalability to higher-resolution avatars (e.g., 1024×1024 or 4K), with maintained temporal/multi-view consistency and real-time performance, is not demonstrated.
- Computational cost and practicality: generation takes 6.5–10.5 hours per avatar (32–48 views, 89 frames) and training requires 14 days on 8×H100; pathways for reducing compute (e.g., fewer diffusion steps, consistency/rectified flows, distillation) are not evaluated.
- Distillation into 4DGS attached to FLAME mesh: fidelity for non-FLAME structures (hair, glasses, earrings) relies on sparse keypoint triangulation; the coverage, accuracy, and temporal stability of these Gaussians (especially in occluded or textureless regions) remain unquantified.
- Evaluation of geometry accuracy: beyond RE@LG with keypoints, there is no direct measurement of 3D geometric fidelity (e.g., multi-view photometric consistency under known lighting, multi-view stereo comparisons, mesh/landmark errors).
- Identity preservation across extreme views: identity metrics (ArcFace CSIM) are reported but not dissected for profile/rear views where face embeddings are less reliable; identity drift over long sequences or view transitions is not analyzed.
- Controllability scope: current controls target head pose and expressions; there is no explicit control for eye gaze, eyelid micro-dynamics, tongue/lip fine motions, or global lighting; a unified control interface (including audio-to-prosody, text-to-expression semantics) is not presented.
- Audio-driven pipeline is not end-to-end: speech-driven generation relies on Hallo3 to first produce a driving monocular video, followed by tracking; end-to-end audio-to-multi-view video generation and its benefits/risks are unstudied.
- Occlusions and self-occlusions: robustness to hands/objects in front of the face, hats, and dynamic occlusion events is not evaluated; failure modes and mitigation strategies (e.g., occlusion-aware conditioning) remain open.
- Camera/lens diversity: sensitivity to intrinsics, distortion, and rolling shutter effects is not reported; generalization to wide-angle, telephoto, and smartphone camera pipelines is unknown.
- Global multi-view synchronization when generating in clusters: the iterative expansion (modes 2–4) may introduce inter-cluster inconsistencies; quantitative analysis of global temporal and spatial alignment across all views is missing.
- Automatic key-view selection: key views are manually chosen; optimal selection strategies (e.g., view planning to minimize reconstruction error or maximize coverage/diversity) are not investigated.
- Failure case taxonomy: while some limitations are shown qualitatively, there is no systematic taxonomy of failure modes (e.g., flicker types, geometry artifacts, expression mis-transfers) or their prevalence.
- Fairness, diversity, and bias: datasets used may be limited in demographic and appearance diversity (skin tones, facial hair, hairstyles, age groups, cultural attire); bias and fairness assessments are absent.
- Ethical and consent considerations: generating photorealistic avatars from a single image poses risks (misuse, deepfakes, identity theft); the paper does not address safeguards, watermarking, consent verification, or provenance tracking.
- Comparison breadth: direct quantitative comparisons to recent multi-view video models (e.g., Human4DiT) are not provided; standardized evaluation protocols across methods are missing.
- Metric limitations: reliance on LPIPS and ArcFace CSIM may misrepresent geometry and identity under extreme viewpoints; alternative metrics (e.g., video-level identity persistence, 3D-aware perceptual measures) are not explored.
- Robustness to out-of-distribution styles: performance on stylized, heavily made-up, low-light, low-resolution, or noisy inputs is not studied; failure rates and recovery strategies (e.g., style normalization) are unknown.
- Influence of curriculum specifics: the contribution of each dataset modality and each training mode (1–4) to final performance is only partially ablated; deeper analyses (e.g., per-mode generalization, data mixing ratios) are needed.
- Effectiveness of sub-frame motion maps: the proposed 2D screen-space displacement conditioning for dropped frames is introduced but not isolated with controlled studies against alternative motion cues (e.g., optical flow, 3D velocity fields).
- Temporal regularization in 4DGS: the velocity/rotation regularizers are described but not ablated; their impact on reducing jitter, preserving detail, and avoiding over-smoothing is not quantified.
- Integration with physically based rendering: the pipeline does not model light transport explicitly; exploring PBR or differentiable relighting to improve cross-view and cross-light consistency remains open.
- End-to-end joint training of generation and distillation: the two-stage pipeline (video generation → 4DGS fitting) is not optimized end-to-end; potential gains from joint objectives (e.g., 3D-aware diffusion losses) are unexplored.
- Extension beyond heads to full-body avatars: applicability to full-body motion, clothing dynamics, hands, and complex interactions is unspecified; scaling the conditioning and representation to whole-body remains an open challenge.
- High-frequency detail retention: skin microstructure, beard stubble, and expression-dependent wrinkles are shown qualitatively but their temporal consistency and cross-view stability are not quantitatively assessed.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging the paper’s methods (multi-view video diffusion, 3DMM conditioning, multi-view CFG, attention scaling) and the 4D Gaussian-splatting avatar distillation pipeline.
- Studio-grade head avatar capture from a single photo
- Sectors: gaming, film/TV, XR (VR/AR), advertising
- Tools/Products/Workflows: “Single-photo-to-4D Avatar” pipeline (reference image → FLAME/FlowFace tracking → MVP4D multi-view video generation → 4DGS distillation → real-time rendering plugin for Unity/Unreal); asset management and versioning for shots/sequences
- Assumptions/Dependencies: high-quality portrait input; cloud or workstation GPU (hours of generation per avatar); licensed use of pre-trained models (CogVideoX, FLAME, FlowFace); limited robustness under extreme lighting; hair/glasses handled via SfM but may need artist cleanup
- VTuber and streaming-ready 360-degree talking-head avatars
- Sectors: creator economy, social media, live streaming
- Tools/Products/Workflows: OBS/VTuber plugins for live expression control; precomputed MVP4D avatars rendered in real time; optional speech-driven animation via Hallo3
- Assumptions/Dependencies: precomputation time (6–10.5 hours reported); live driving via face/audio tracking; content moderation policies; identity/likeness consent and rights management
- Telepresence in virtual meetings (privacy-preserving or bandwidth-friendly head avatars)
- Sectors: enterprise communications, collaboration software
- Tools/Products/Workflows: Zoom/Teams plugins to map user expressions to a precomputed MVP4D 4D avatar; real-time rendering at 512×512 as reported
- Assumptions/Dependencies: reliable face tracking; acceptable latency; corporate policies toward synthetic video; user consent and disclosure; limited performance in extreme lighting
- Rapid VFX/games head asset creation and previz
- Sectors: film/VFX, game development
- Tools/Products/Workflows: pipeline integration that replaces multi-camera capture rigs for early previz and mid-fidelity assets; batch generation of cast/extras heads; dailies with expression control sequences
- Assumptions/Dependencies: artistic QC for fine details (e.g., hair, teeth); potential manual cleanup; compute scheduling; consistent identity preservation across shots; licensing and attribution
- Speech-driven marketing and personalized content
- Sectors: marketing/advertising, brand engagement
- Tools/Products/Workflows: “Speech-to-4D Ad Maker” using Hallo3 to produce driving sequences → MVP4D generation → real-time render; A/B testing pipelines with expression variants
- Assumptions/Dependencies: brand safety and deepfake policies; disclosure/watermarking; consent for likeness; pipeline governance for provenance
- Academic research toolkit: reproducible multi-view diffusion components
- Sectors: academia (graphics, vision, generative modeling), software R&D
- Tools/Products/Workflows: adoption of the multi-modal training curriculum (monocular + multi-view images + limited multi-view videos); multi-view classifier-free guidance; attention scaling; benchmark suites for temporal and 3D consistency (JOD, RE@LG)
- Assumptions/Dependencies: access to datasets (VFHQ, RenderMe-360, Nersemble, Ava-256) under proper licenses; high-end compute (8×H100 reference); model/code availability and maintenance
- Synthetic multi-view dataset augmentation for trackers and identity models
- Sectors: computer vision, biometrics R&D
- Tools/Products/Workflows: generate diverse, temporally consistent multi-view portrait videos to train/test face tracking (3DMM), correspondence (DISK/LightGlue), and identity embeddings (ArcFace)
- Assumptions/Dependencies: domain shift risks; dataset bias and demographic coverage; clear data-use policies; careful evaluation of identity preservation and ethical safeguards
- Museum, education, and interactive exhibits (precomputed head busts with lifelike motion)
- Sectors: education, cultural heritage
- Tools/Products/Workflows: “Interactive Bust” installations (single archival photo → MVP4D → 4D avatar) with curated expression scripts; kiosk-based real-time rendering
- Assumptions/Dependencies: rights to archival images; curatorial oversight; acceptable realism (avoid uncanny valley for sensitive content); limited hair/occlusion fidelity in certain profiles
Long-Term Applications
These use cases require further research, scaling, or engineering. They build on the paper’s innovations but depend on advances in model efficiency, robustness, data, and governance.
- On-device or near-real-time avatar generation (not just rendering)
- Sectors: mobile XR, consumer software
- Potential Tools/Products/Workflows: model distillation/quantization for edge devices; streaming VAEs; incremental generation with low-latency diffusion or alternative generative backbones
- Assumptions/Dependencies: major efficiency improvements; better temporal priors (to reduce long-sequence degradation); optimized spatiotemporal compression; specialized hardware (NPUs)
- Full-body animatable 4D avatars (motion capture replacement)
- Sectors: gaming, film/VFX, digital fashion, robotics telepresence
- Potential Tools/Products/Workflows: extension of MMVDM conditioning from head-only FLAME to whole-body parametric models; mixed-modality training (multi-view image/video + mocap); integration with physics and cloth/hair simulation
- Assumptions/Dependencies: new datasets (multi-view dynamic whole-body with varied lighting/occlusion); accurate body/lip/tongue dynamics; handling self-occlusions; artist-in-the-loop workflows
- Live telepresence in AR glasses and volumetric social platforms
- Sectors: AR/VR hardware, social networking
- Potential Tools/Products/Workflows: low-bandwidth streaming of expression controls + local rendering of the 4D avatar; standardized avatar formats across platforms; volumetric chat rooms with consistent identity
- Assumptions/Dependencies: interoperability standards; scalable provenance/watermarking; latency constraints; user acceptance and trust
- Privacy-preserving telemedicine and education (identity masking with expression fidelity)
- Sectors: healthcare, education
- Potential Tools/Products/Workflows: avatarized consultations preserving critical nonverbal cues; patient-controlled identity obfuscation; training simulations for clinicians and teachers
- Assumptions/Dependencies: clinical validation of expression fidelity (including teeth/mouth detail); regulatory compliance (HIPAA/GDPR); inclusive datasets to avoid bias; ethical frameworks
- Provenance, watermarking, and disclosure standards for 4D avatars
- Sectors: policy, platform governance, media integrity
- Potential Tools/Products/Workflows: embedding cryptographic watermarks and provenance metadata at generation and distillation stages; platform-level detection; clear disclosure UX
- Assumptions/Dependencies: cross-industry standards; regulatory adoption; robustness against adversarial removal; compatibility with codecs and streaming formats
- Marketplace and rights management for 4D avatars (licensing, royalties, audit)
- Sectors: media, entertainment law, creator economy
- Potential Tools/Products/Workflows: contracts that bind avatar usage to consent; managed distribution with audit trails; automated revenue sharing; “avatar notarization”
- Assumptions/Dependencies: legal frameworks for synthetic likeness; scalable identity verification; platform enforcement; fair-use policies
- Cross-domain multi-view video diffusion (beyond portraits)
- Sectors: simulation (driving, robotics), panoramic media, digital twins
- Potential Tools/Products/Workflows: reuse of the multi-modal curriculum and multi-view CFG to generate multi-camera data for autonomous systems and panoramic storytelling
- Assumptions/Dependencies: domain-specific datasets and conditioning signals; calibration metadata; safety validation for synthetic simulation data
- Accessibility and assistive communication (high-fidelity lip-reading and emotion conveyance)
- Sectors: accessibility tech, communications
- Potential Tools/Products/Workflows: avatars that emphasize clear mouth/teeth dynamics for the hearing-impaired; emotion-aware visualizations for neurodiverse users
- Assumptions/Dependencies: improved modeling of fast mouth/teeth changes; user studies for efficacy; inclusive design; privacy guarantees
Key Cross-Cutting Assumptions and Dependencies
- Compute and latency: current generation requires hours on high-end GPUs; real-time rendering is feasible post-distillation, but real-time generation is not.
- Data and licensing: access to and use of VFHQ, Nersemble, RenderMe-360, Ava-256 under appropriate licenses; potential bias in datasets impacting fairness and generalization.
- Third-party components: reliance on CogVideoX (video VAE/diffusion), FLAME/FlowFace (3DMM tracking), Hallo3 (speech-driven animation), DISK/LightGlue (SfM keypoints).
- Technical limitations noted by the paper: reduced fidelity for fast temporal details (teeth/blinks), degradation for very long sequences in mode 3, limited robustness to extreme lighting.
- Ethics, consent, and governance: explicit permission for likeness use; watermarking/provenance to mitigate deepfake risks; clear disclosure to end-users; platform policies for synthetic media.
- Integration and standards: need for interoperable 4D avatar formats, real-time streaming protocols, and engine/tooling support (Unity/Unreal, OBS, conferencing platforms).
Glossary
- 3D Gaussian splatting (3DGS): A point-based 3D scene representation that renders images by projecting and blending anisotropic Gaussian primitives in space; here used in a deformable form for dynamic heads. Example usage: "optimizing a deformable 3D Gaussian splatting (3DGS)-based representation"
- 3D Morphable Model (3DMM): A parametric model of 3D face shape and appearance that supports controllable pose and expression. Example usage: "Most methods attempt to model motion via coarse geometry generated by 3DMMs"
- 4D avatar: A dynamic, animatable 3D human model over time (3D + time) suitable for real-time rendering. Example usage: "We reconstruct a 4D avatar by first using the MMVDM to generate a large set of multi-view videos"
- Attention biasing: Adjusting transformer attention behavior (e.g., via scaling) to counter token-count-induced entropy changes and stabilize multi-view, multi-frame inference. Example usage: "For further discussion on attention biasing and its effects, we refer the reader to Kant et al."
- Blendshapes: A linear basis of facial deformations used to animate expressions by blending predefined shape offsets. Example usage: "We animate the avatar by deforming the mesh with FLAME blendshapes"
- Classifier-free guidance (CFG): A diffusion sampling technique that mixes conditional and unconditional predictions to strengthen conditioning signals. Example usage: "We apply classifier-free guidance (CFG) by zeroing out all conditioning signals"
- Cross-reenactment: Driving a target identity with expressions/motion from a different source video. Example usage: "We evaluate cross-reenactment using 10 reference images from the FFHQ dataset"
- CSIM (cosine similarity of identity embeddings): A metric for identity preservation based on cosine similarity of face embeddings. Example usage: "identity preservation, measured using the cosine similarity of identity embeddings (CSIM)"
- DDIM sampling: Deterministic diffusion implicit sampling that reduces steps while preserving quality. Example usage: "We use DDIM sampling~\cite{song2021denoising} during inference"
- Diffusion transformer: A transformer-based denoiser architecture for diffusion models that processes spatio-temporal tokens. Example usage: "our model is based on a recent video diffusion transformer architecture"
- DISK: A learned local feature detector/descriptor for wide-baseline matching used for correspondences and evaluation. Example usage: "We use DISK and LightGlue to detect and match keypoints"
- Expression deformation maps: Image-aligned maps encoding 3D facial deformations relative to a neutral mesh to control expressions. Example usage: "expression deformation maps"
- FLAME: A parametric head model for faces (shape, pose, expression) used as a canonical template for conditioning and reconstruction. Example usage: "We attach Gaussians to the triangles of a FLAME head mesh"
- FlowFace: An off-the-shelf face tracker used to estimate FLAME parameters and conditioning signals. Example usage: "which is predicted from the reference image using FlowFace~\cite{taubner2024flowface}"
- Gaussian primitives: The anisotropic Gaussian elements used in Gaussian splatting to represent scene appearance and geometry. Example usage: "we introduce a Gaussian primitive that is animated with its nearest triangle on the 3DMM mesh."
- Guidance scale: A scalar controlling the strength of classifier-free guidance during diffusion sampling. Example usage: "where is the guidance scale."
- JOD: A perceptual temporal consistency metric (Just-Objectionable-Differences) used to quantify flicker/stability. Example usage: "temporal consistency (JOD)~\cite{mantiuk2021jod}"
- LightGlue: A learned feature matcher for robust keypoint correspondence across views. Example usage: "We use DISK and LightGlue to detect and match keypoints"
- LPIPS: A learned perceptual similarity metric comparing deep feature distances between images. Example usage: "perceptual similarity (LPIPS)"
- MMDM (Morphable Multi-view Diffusion Model): A diffusion model that synthesizes images across viewpoints with morphable-model controls. Example usage: "a morphable multi-view diffusion model (MMDM)"
- MMVDM (Morphable Multi-view Video Diffusion Model): A diffusion model that jointly generates synchronized multi-view videos with morphable-model controls. Example usage: "a morphable multi-view video diffusion model (MMVDM) that generates detailed, photorealistic avatars"
- Multi-modal training curriculum: A staged training strategy mixing monocular videos, multi-view videos, and multi-view images to learn spatio-temporal consistency. Example usage: "we design a multi-modal training curriculum"
- Multi-view classifier-free guidance: Extending CFG to multiple views by producing view-specific unconditional predictions for stable multi-view generation. Example usage: "Multi-view classifier-free guidance."
- Neural radiance fields: A volumetric neural representation that models view-dependent radiance to render photorealistic images. Example usage: "neural radiance fields \cite{mildenhall2021nerf}"
- RE@LG (reprojection error with LightGlue): A 3D consistency metric measuring keypoint reprojection error using LightGlue matches. Example usage: "reprojection error (RE@LG) of DISK~\cite{tyszkiewicz2020disk} keypoints"
- Rasterized canonical 3D coordinates: Per-pixel encodings of canonical-space 3D positions of the mesh, used as conditioning. Example usage: "which encode the rasterized canonical 3D coordinates of the head geometry"
- Self-reenactment: Reproducing the motion/expression of a subject from the same sequence to assess fidelity. Example usage: "We benchmark self-reenactment on ten forward-facing multi-view sequences"
- Sinusoidal positional encoding: A deterministic encoding of positions (space/time) with sinusoidal functions used by transformers. Example usage: "uses a sinusoidal positional encoding applied separately to each spatial and temporal dimension."
- Sinusoidal temporal embedding: A temporal encoding (here 8-channel) to condition networks on frame time. Example usage: "an 8-channel sinusoidal temporal embedding"
- Spatio-temporal video auto-encoder: A neural encoder-decoder that compresses video along spatial and temporal dimensions into a latent space. Example usage: "a pre-trained spatio-temporal video auto-encoder"
- Structure-from-motion: A multi-view geometry technique that reconstructs 3D points and camera poses from matched keypoints. Example usage: "we apply structure-from-motion to keypoints matched across the first frame of each view"
- Sub-frame motion map: An auxiliary map encoding motion between temporally compressed frames to recover fine temporal details. Example usage: "we introduce an additional sub-frame motion map, "
- Token patchification: Converting latent feature maps into token sequences by splitting into patches for transformer processing. Example usage: "The latent frames are patchified into tokens using a convolutional layer."
- U-Net: A convolutional encoder-decoder with skip connections used here to predict per-Gaussian deformations. Example usage: "we follow previous work \cite{taubner2024cap4d} and use a U-Net to predict frame-dependent, per-Gaussian deformations"
- Variational autoencoder (VAE): A probabilistic autoencoder that maps images/videos to a latent distribution for generative modeling. Example usage: "encoded into the latent space of a variational autoencoder"
- View ray direction and origin maps: Per-pixel encodings of camera ray origins and directions used to inject view geometry into the model. Example usage: "view ray direction and origin maps"
- Volume rendering: Rendering technique that integrates radiance and density along rays through a volume to synthesize images. Example usage: "or volume rendering~\cite{xu2024vasa,drobyshev2022megaportraits}"
Collections
Sign up for free to add this paper to one or more collections.

