- The paper introduces a novel unsupervised, open-vocabulary paradigm that integrates SAM2 and CLIP for change detection.
- It employs a cross-modal feature alignment module (SCFAM) with multi-term losses to fuse semantic and spatial features effectively.
- Experimental results on benchmarks like LEVIR-CD and WHU-CD demonstrate state-of-the-art F1 and mIoU performance.
UniVCD: Unsupervised Open-Vocabulary Change Detection via Cross-Modal Feature Alignment
Problem Context and Limitations of Existing Methods
Change detection (CD) in remote sensing is the task of identifying spatial and semantic modifications between multi-temporal observations. Conventional CD techniques are predominantly supervised or semi-supervised, posing reliance on large-scale annotated datasets with limited generalization capability to diverse scenes and categories. Recent efforts leveraging vision foundation models (VFMs), such as SAM2 and CLIP, improved robustness and generalization through learned priors but are typically constructed in a cascaded or naively fused manner, with insufficient cross-modal semantic and spatial integration. These approaches bear high computational cost, sensitivity to backbone choice, and tend to be brittle across varied imaging conditions.
UniVCD Framework
UniVCD introduces a fully unsupervised, open-vocabulary CD paradigm upon frozen SAM2 and CLIP backbones. The pipeline is comprised of four core components: a SAM2 encoder for rich spatial features, a CLIP encoder for robust semantic priors, a SAM-CLIP Feature Alignment Module (SCFAM) for multi-modal feature fusion, and a compact post-processing module for denoising and boundary refinement.
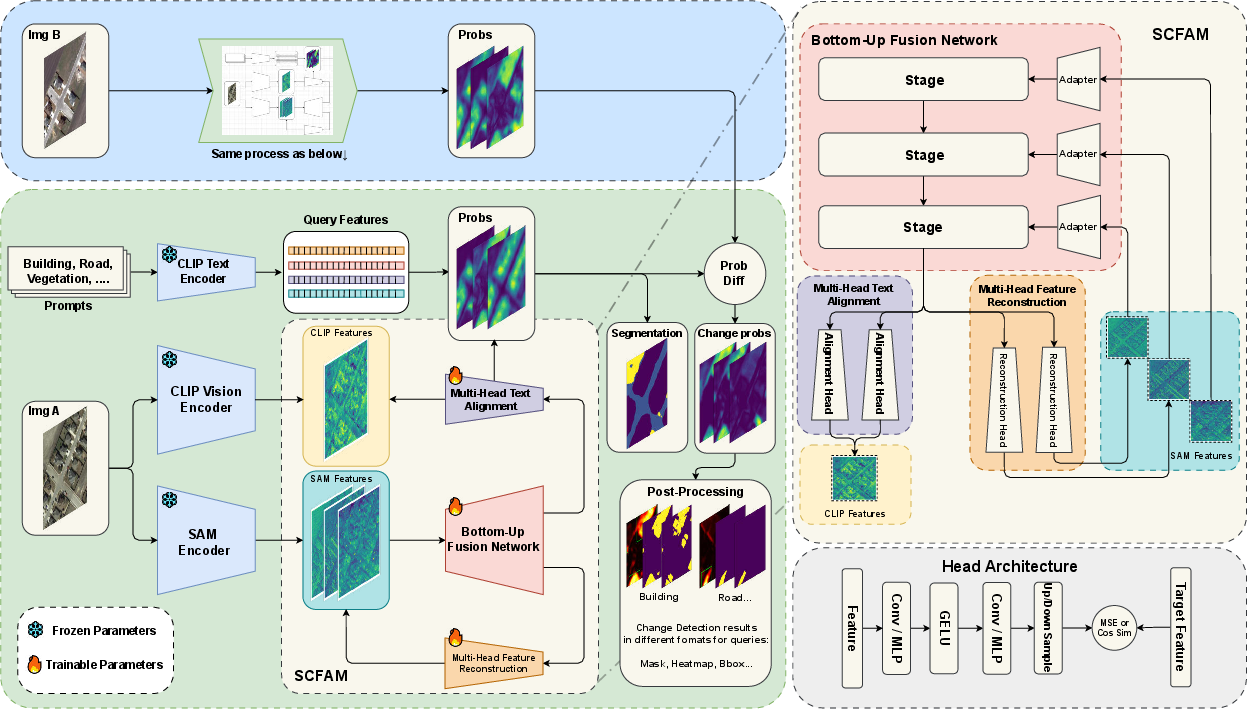
Figure 1: The UniVCD architecture integrates a frozen SAM2 encoder (spatial), a CLIP encoder (semantic), and the SCFAM fusion module, with high-resolution feature outputs post-processed for final change maps.
For each bi-temporal image pair, parallel feature extraction is conducted, followed by cross-modal feature alignment and hierarchical fusion in SCFAM. The module includes multiple lightweight residual adapters and ConvNeXt-based fusion blocks. Projected features are aligned at both semantic and spatial levels, and subsequent pixelwise comparisons are performed via category-specific CLIP-driven similarity. Post-processing involves Otsu thresholding and SAM2-guided segmentation refinement.
Feature Alignment and Loss Design
UniVCD’s SCFAM module is designed for efficient unsupervised transfer: spatial features from SAM2 at multiple scales are adapted and progressively fused, then projected for semantic consistency with CLIP features. The unsupervised loss is a multi-term composition: scale-wise MSE-based reconstruction losses on spatial (SAM2) features, and mean cosine similarity plus MSE-based alignment for semantic (CLIP) features. Loss weighting is calibrated to prioritize alignment over mere reconstruction. The approach ensures that high-fidelity spatial details remain intact, while categorical transfer is maximally injective from pretrained semantics.
Open-Vocabulary Detection and Segmentation Pipeline
Each fused feature map’s alignment with CLIP’s text feature embeddings yields class-probability maps for all queried categories. For change detection, class-specific per-pixel difference maps between temporal image predictions are computed, forming a class-agnostic or class-aware change likelihood basis. This is followed by adaptive binarization and morpho-geometric post-processing; for sharply-bounded categories (“building”, “road”) the SAM2-refined mask produces superior precision.
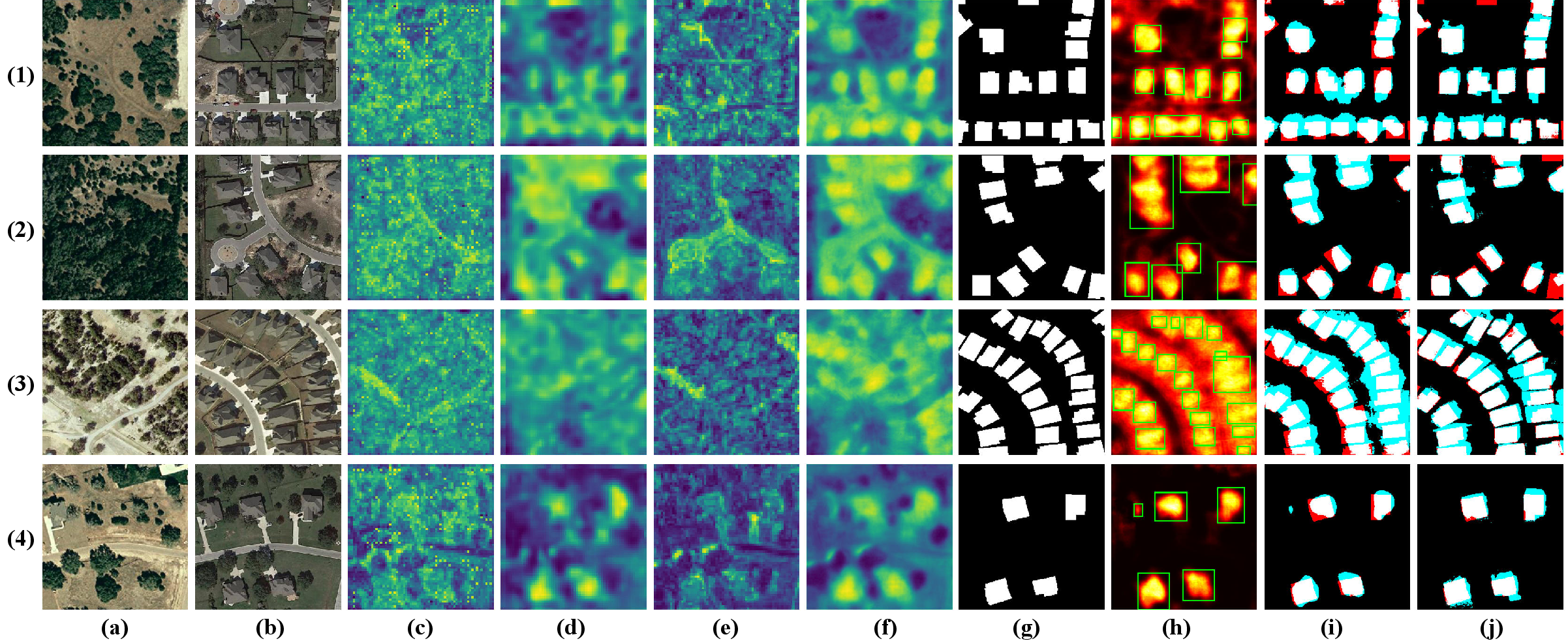
Figure 2: Visualization of CD feature maps and outputs: (a)-(b) pre/post images, (c)-(d) cosine similarity maps (SAM2/CLIP), (e)-(f) SCFAM-fused maps, (g) ground truth, (h)-(j) probability heatmaps and final binary masks.
The architecture can scale to high-resolution analyses by overlapping sliding-window feature extraction and patchwise aggregation.

Figure 3: High-resolution CD results with UniVCD on 1024×1024 and 512×512 images; panels show input images, ground-truth, heatmaps, binarized and post-processed change maps.
Open-Vocabulary and Class-Aware Capabilities
UniVCD generalizes to arbitrary unordered class sets. By prompting CLIP with custom category names and composing prompt templates, semantic alignment remains robust across diverse domains. The model generates per-class segmentation and change maps with a single unified framework. This extends naturally to semantic change detection and segmentation, with strong results highlighted for both dominant and minor classes.

Figure 4: UniVCD’s open-vocabulary segmentation and CD; (a)-(b) input images, (c)-(d) category maps, (e)-(g) change maps for Building, Road, Vegetation.
Small Object and Oblique View Robustness
Empirically, UniVCD demonstrates strong qualitative and quantitative performance on scenarios that challenge conventional CD methods—namely small-object changes and oblique cinematography. Vehicle-level change detection is achieved at scale, and building facade modifications are robustly isolated in UAV imagery.

Figure 5: Small object CD—vehicle-level changes on WHU-CD, shown pre/post, probability map, and refined results.
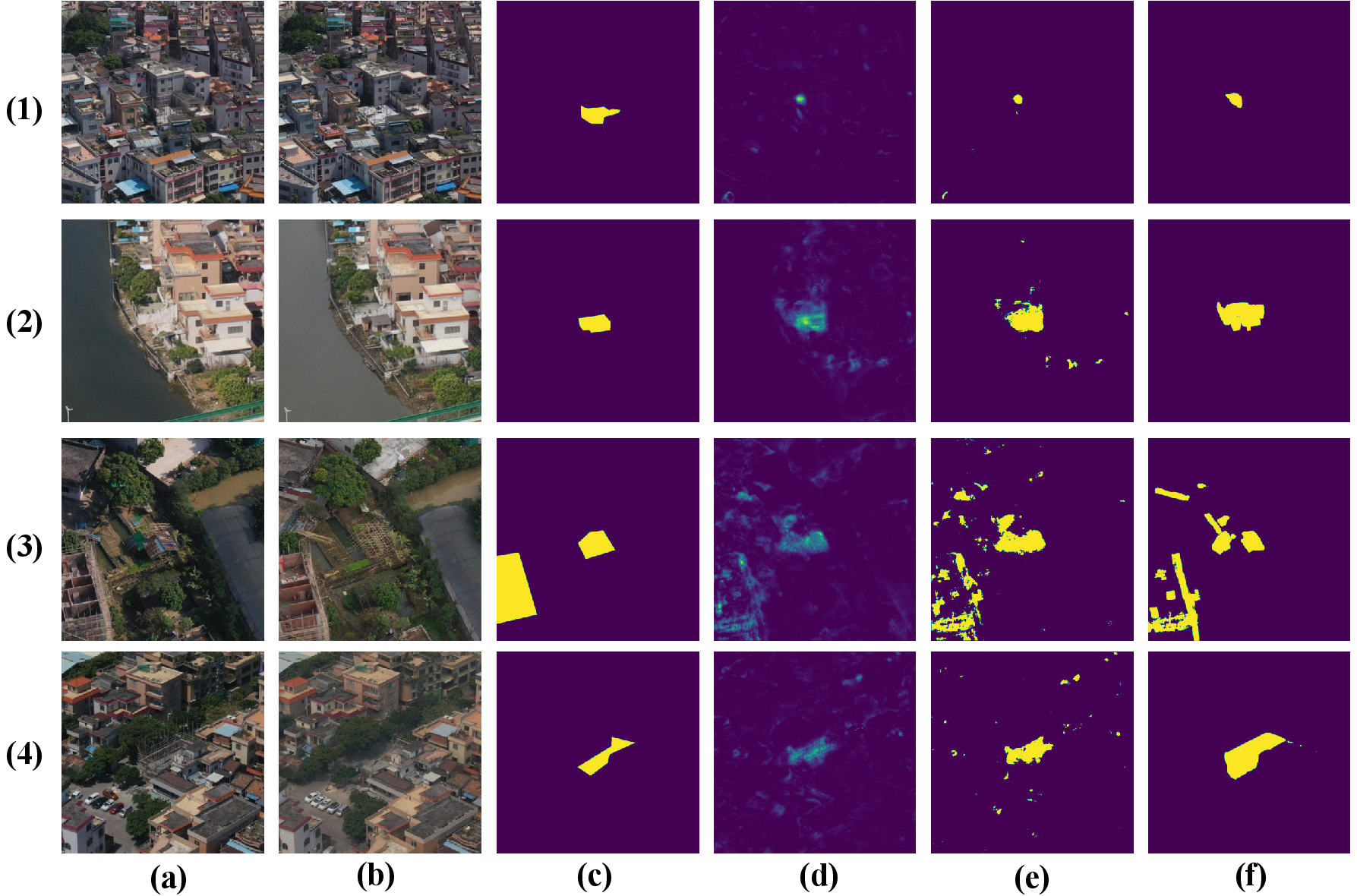
Figure 6: UniVCD CD output for oblique UAV imaging, demonstrating facade-level change detection.
Experimental Results
Table-based benchmarks on LEVIR-CD, WHU-CD, and SECOND datasets substantiate UniVCD’s claims. The proposed method attains state-of-the-art F1 and mIoU on both binary and semantic CD tasks, outstripping recent VFM-based and traditional approaches in both precision and robustness—especially on original high-resolution images and after SAM2-refined post-processing. Notably, UniVCD’s unsupervised training strategy requires neither paired nor labeled examples, positioning the method uniquely for fully scalable deployed CD scenarios. Ablation shows the importance of SCFAM fusion and the multi-component unsupervised loss: removing cross-modal alignment notably degrades all core performance metrics.
Highlighted claim: UniVCD consistently achieves or exceeds the best reported open-vocabulary CD performance on tested benchmarks in category-agnostic and class-aware settings, matching or surpassing prior SOTA in F1 and mIoU across both high- and low-resolution variants.
Discussion and Theoretical Implications
Practically, UniVCD enables truly plug-and-play remote sensing CD over arbitrary category sets, facilitating applications in urban monitoring, environmental analysis, and infrastructure management without the need for labeled data or model retraining per task. The reliance on strong vision and vision-language priors, augmented by lightweight unsupervised fusion and denoising, decouples CD performance from domain-specific dataset limitations.
Theoretically, UniVCD further validates that frozen VLMs retain sufficient representational versatility for high-level scene understanding tasks, provided appropriate cross-modal fusion and alignment. The observed improvements when switching to domain-specialized CLIP variants (e.g., RemoteCLIP for water class) support the hypothesis that open-vocabulary performance floors are largely dictated by pretraining corpus coverage and transferability.
Current limitations include reduced sensitivity to semantic-neutral changes and rare failure modes on visually ambiguous or semantically out-of-domain objects (e.g., playgrounds, as observed in experiments). Further, some recall is traded for precision under aggressive post-processing, though threshold calibration is flexible.
Future Directions
- Enhanced domain adaptation via fine-tuned or alternate VLMs for tailored applications (e.g., RemoteCLIP, BLIP variants).
- Investigation of alternate and more expressive feature alignment strategies, especially addressing the recall–precision tradeoff in post-processing for fuzzy-boundary categories.
- Extension to multi-modal or multi-sensor fusion (e.g., incorporating radar, multi-spectral, text) for increased robustness to imaging artefacts and atmospheric interference.
- Meta-learning or lifelong learning approaches atop the frozen backbone, leveraging unsupervised or weakly-supervised signals at inference time.
Conclusion
UniVCD establishes a powerful unsupervised, open-vocabulary, foundation model-centric paradigm for CD tasks, achieving leading quantitative performance and robust qualitative outputs across standard and challenging remote sensing scenarios. Its architectural and methodological innovations—cross-modal SCFAM fusion, unsupervised semantic-spatial alignment loss, and adaptive post-processing—constitute a practical and versatile approach. This paradigm advances the utility of large pretrained models as universal feature extractors, significantly reducing reliance on task-specific annotations and architectural redesign for each new application.

