- The paper presents PeftCD, a novel framework integrating PEFT with VFMs to enhance remote sensing change detection.
- It shows that freezing backbone weights and fine-tuning lightweight modules like LoRA and Adapter significantly improves IoU and F1 scores.
- The method achieves scalability and resource efficiency while maintaining high boundary accuracy and robust detection across benchmarks.
PeftCD: Parameter-Efficient Fine-Tuning of Vision Foundation Models for Remote Sensing Change Detection
Introduction
The PeftCD framework addresses the persistent challenges in remote sensing change detection (RSCD), including pseudo-change suppression, limited labeled data, and cross-domain generalization. The approach leverages Vision Foundation Models (VFMs)—specifically, Segment Anything Model v2 (SAM2) and DINOv3—using parameter-efficient fine-tuning (PEFT) strategies, namely LoRA and Adapter modules. By freezing the majority of backbone parameters and only training lightweight adaptation modules, PeftCD achieves high task adaptability with minimal computational overhead, while maintaining the strong representational priors of large-scale VFMs.
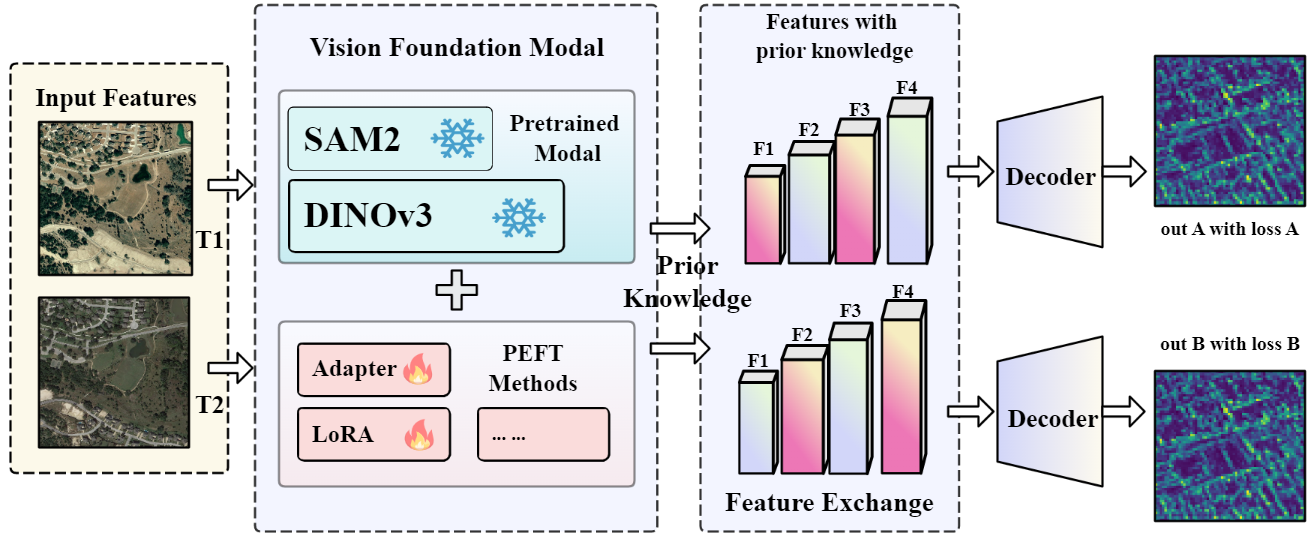
Figure 1: Architecture of PeftCD. Bi-temporal images are encoded by a shared VFM backbone with injected PEFT modules. Features undergo exchange before decoding into a change map.
Architecture and Methodology
Backbone Selection and PEFT Integration
PeftCD is instantiated with two leading VFMs:
- SAM2: A segmentation-oriented ViT backbone with strong boundary priors, trained on over 1.1B masks.
- DINOv3: A self-supervised ViT trained on 17B images, providing robust, generalizable semantic features.
PEFT is realized via:
- LoRA: Low-rank adapters injected into the qkv projections of MHSA layers, with $r=8$ and $\alpha=32$.
- Adapter: Bottleneck MLP modules (dim=32, GELU) inserted pre-block in each Transformer layer.
All backbone weights are frozen; only PEFT module parameters are updated during fine-tuning.
Bi-Temporal Feature Encoding and Exchange
A weight-sharing Siamese encoder processes the bi-temporal inputs. After feature extraction, a cross-temporal feature exchange is performed, swapping features at selected layers between the two streams to enhance change-relevant representation. This operation is critical for robust modeling of temporal differences.
Decoder Design
SAM2CD Instantiation
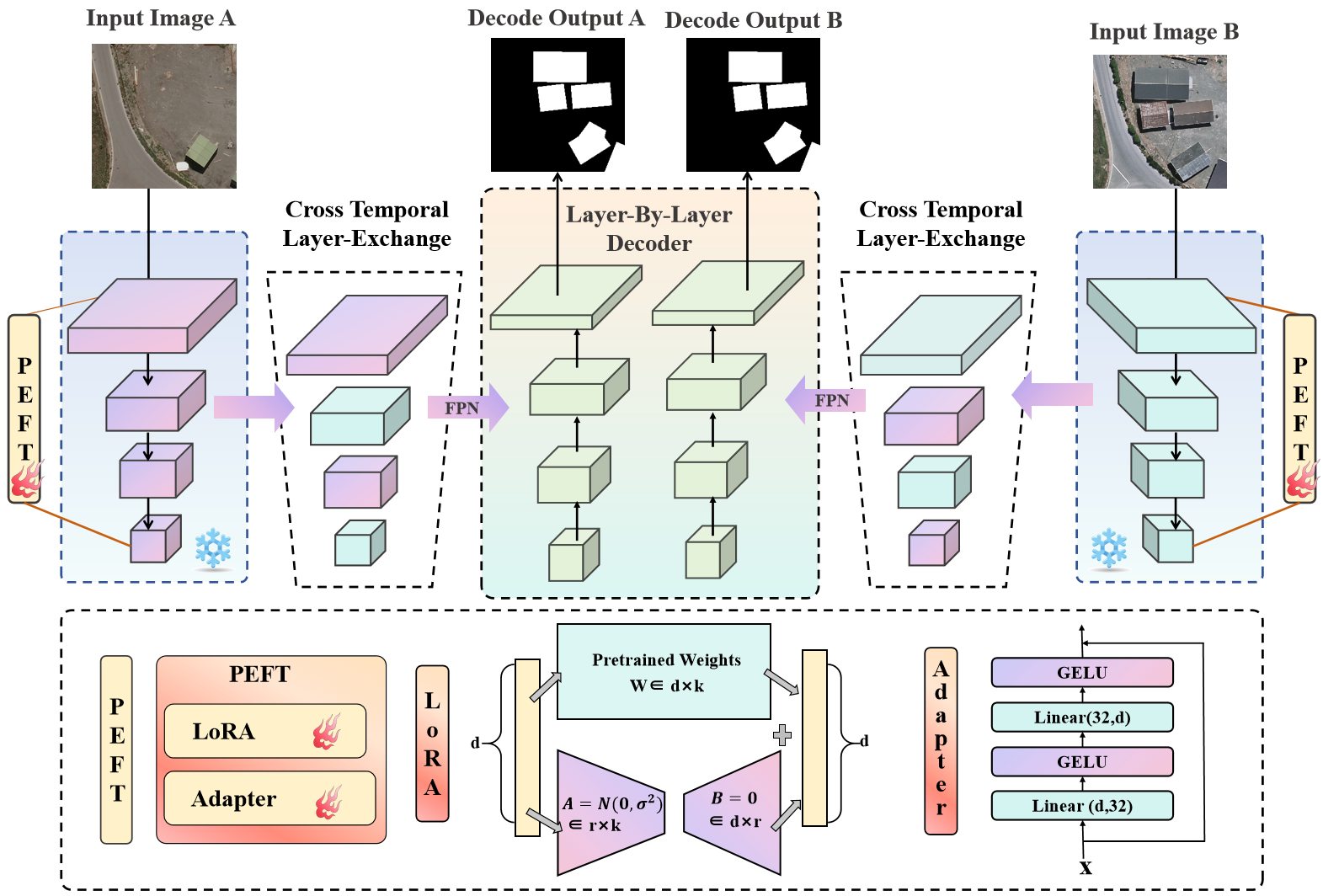
Figure 2: SAM2CD: PeftCD with SAM2 Backbone. Features are exchanged between temporal streams and fused through FPN before dual-branch decoding with shared weights.
- FPN-based Decoder: Aggregates multi-scale features from the SAM2 encoder.
- ResBlock-based Progressive Upsampling: Refines and upsamples features to produce the final change map.
- Dual-Branch Decoding: Each branch outputs a change probability map; outputs are averaged at inference for stability.
DINO3CD Instantiation
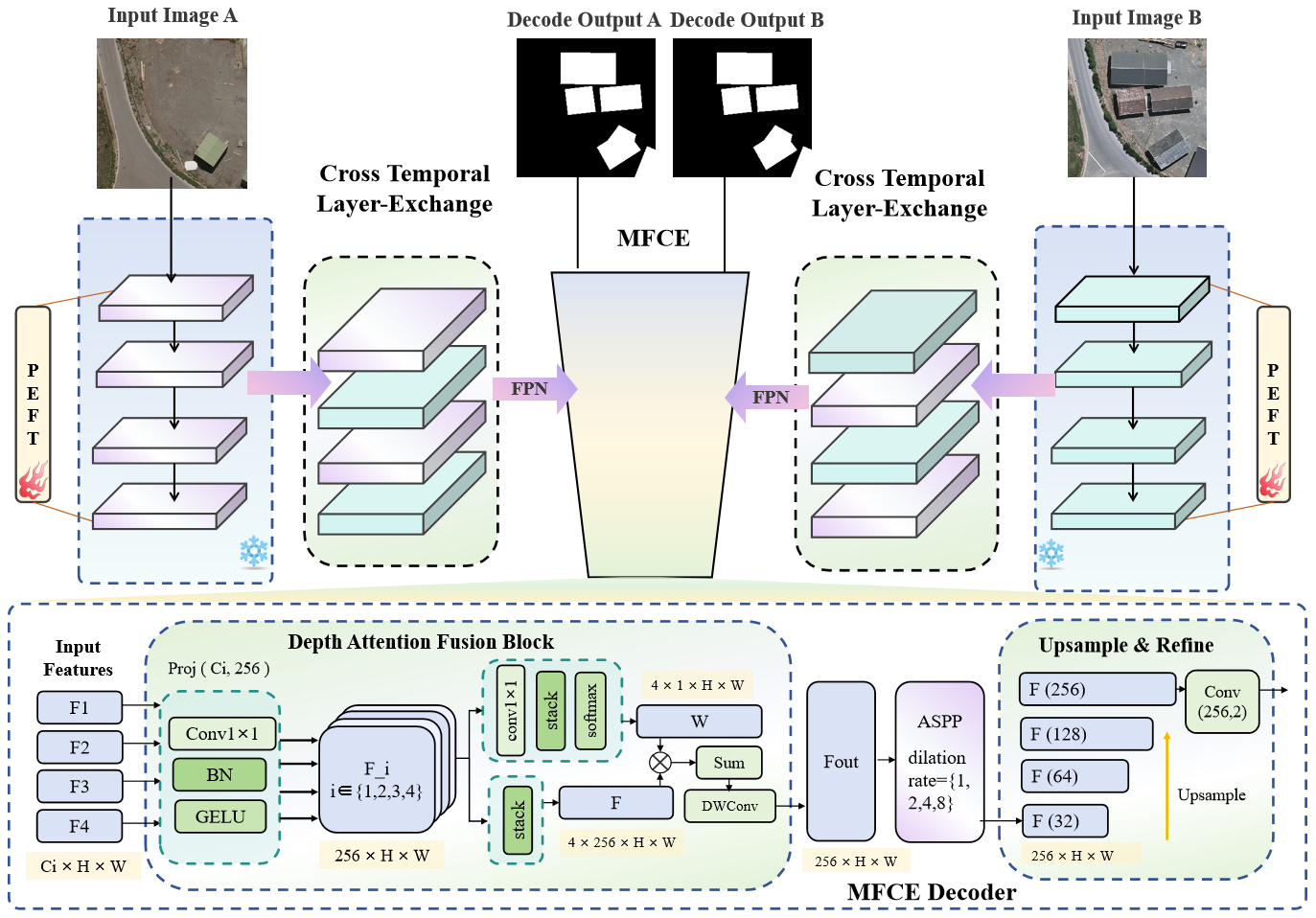
Figure 3: Architecture of the PeftCD model based on DINOv3 (denoted as DINO3CD).
- Same-Scale Multi-Layer Fusion: Features from multiple Transformer layers (e.g., 5, 11, 17, 23) are fused via position-adaptive attention.
- ASPP-based Contextual Enhancement: Multi-dilation convolutions capture diverse spatial context.
- Progressive Upsampling: Three-stage upsampling with depthwise separable convolutions restores spatial resolution.
This decoder design compensates for the lack of a spatial pyramid in ViT backbones, enabling precise boundary recovery and small-object detection.
Experimental Results
PeftCD is evaluated on seven public RSCD datasets: SYSU-CD, WHUCD, MSRSCD, MLCD, CDD, S2Looking, and LEVIR-CD. Across all benchmarks, PeftCD achieves state-of-the-art (SOTA) performance, with notable improvements in IoU, F1, and precision metrics.
- SYSU-CD: IoU 73.81%, F1 84.93%
- WHUCD: IoU 92.05%, F1 95.86%
- MSRSCD: IoU 64.07%, F1 78.10%
- MLCD: IoU 76.89%, F1 86.93%
- CDD: IoU 97.01%, F1 98.48%
- S2Looking: IoU 52.25%, F1 68.64%
- LEVIR-CD: IoU 85.62%, F1 92.25%
Qualitative comparisons demonstrate superior boundary delineation, reduced false positives, and robust detection of small and irregular change regions.

Figure 4: Qualitative comparison between PeftCD and competing methods on the SYSU-CD dataset.

Figure 5: Qualitative comparison between PeftCD and competing methods on the WHUCD dataset.
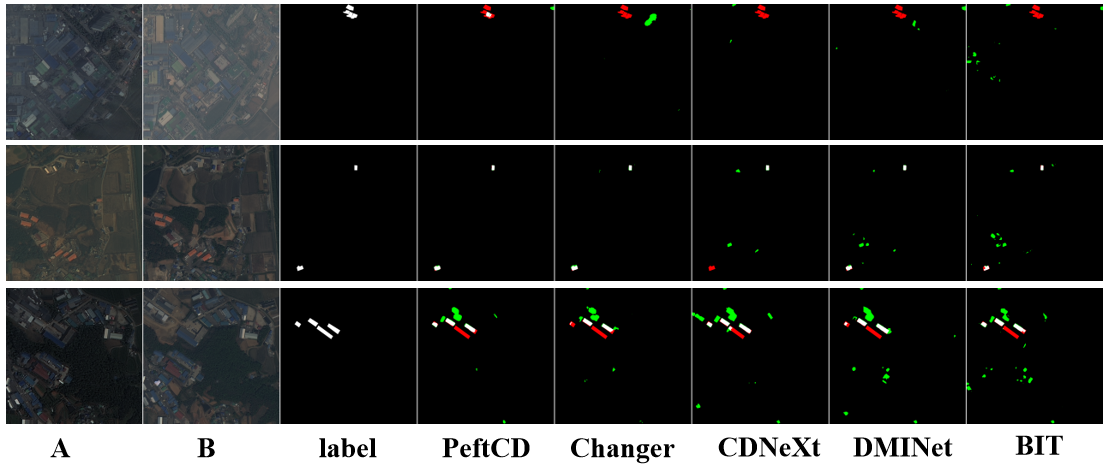
Figure 6: Qualitative comparison between PeftCD and competing methods on the S2Looking dataset.
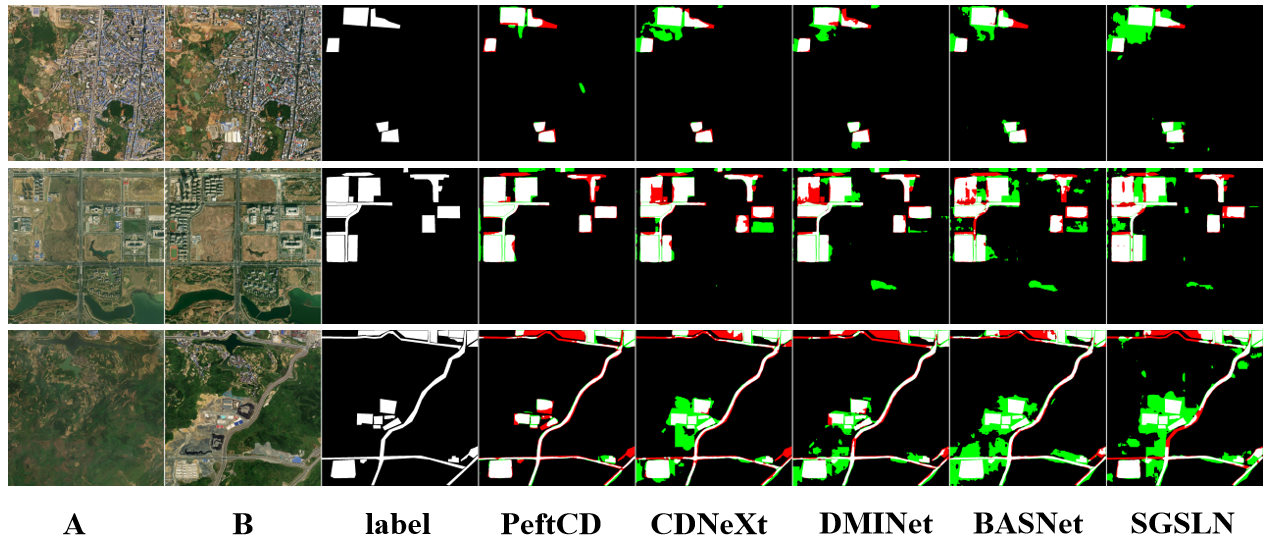
Figure 7: Qualitative comparison between PeftCD and competing methods on the MSRSCD dataset.

Figure 8: Qualitative comparison between PeftCD and competing methods on the MLCD dataset.

Figure 9: Qualitative comparison between PeftCD and competing methods on the CDD dataset.
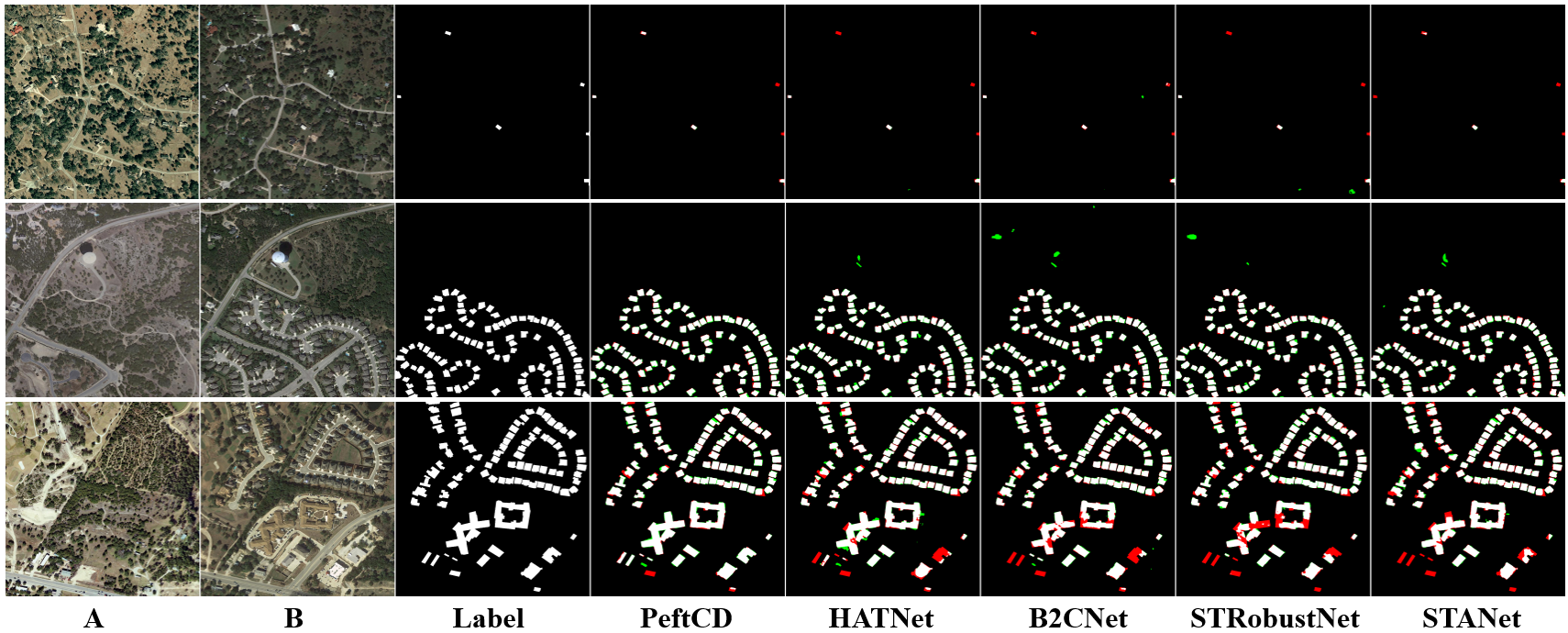
Figure 10: Qualitative comparison between PeftCD and competing methods on the LEVIR-CD dataset.
Ablation and Analysis
Ablation studies confirm:
- PEFT Efficacy: Both LoRA and Adapter yield substantial gains over frozen backbones, with DINOv3+LoRA providing the most consistent cross-dataset improvements.
- Decoder Design: The MFCE decoder in DINO3CD significantly outperforms baseline upsampling, validating the necessity of multi-layer fusion and context enhancement for ViT-based RSCD.
- Parameter Efficiency: PeftCD achieves SOTA results with 2.86M–11M trainable parameters, an order of magnitude fewer than many competing models (e.g., CDNeXt at 242M).
Discussion
Decoding with ViT Backbones
The single-scale nature of ViT backbones (e.g., DINOv3) limits spatial detail recovery. The proposed MFCE decoder, combining deep attention fusion and ASPP, partially mitigates this, but further research is needed for efficient multi-layer fusion and adaptive context modeling, especially for small-object and boundary-sensitive tasks.
PEFT Adaptability and Limitations
LoRA and Adapter modules enable rapid adaptation to RSCD with minimal overhead. However, adaptation capacity is constrained when domain gaps are large (e.g., side-looking imagery in S2Looking). Current PEFT configurations are static; future work should explore adaptive PEFT strategies and cross-layer interaction mechanisms.
Practical Implications
PeftCD's parameter efficiency and strong generalization make it suitable for deployment in resource-constrained or real-time remote sensing applications. The framework demonstrates that large-scale VFMs can be effectively adapted to specialized tasks without full fine-tuning, supporting scalable and sustainable model deployment in operational RSCD systems.
Conclusion
PeftCD establishes a new paradigm for remote sensing change detection by integrating vision foundation models with parameter-efficient fine-tuning. The framework achieves SOTA performance across diverse datasets, with strong boundary accuracy, pseudo-change suppression, and minimal trainable parameters. The results validate the effectiveness of PEFT for adapting large vision models to specialized geospatial tasks and highlight promising directions for efficient, generalizable, and scalable RSCD solutions.

