- The paper introduces Iceberg, a full-spectrum benchmark suite that exposes the disconnect between synthetic metrics and task-specific performance.
- The paper outlines an Information Loss Funnel model identifying embedding loss, metric misuse, and data distribution sensitivity as key contributors to performance gaps.
- The paper presents a decision tree for method selection that guides metric and algorithm choices to optimize real-life vector similarity search outcomes.
Task-Centric Re-evaluation of Vector Similarity Search: An Expert Summary of "Reveal Hidden Pitfalls and Navigate Next Generation of Vector Similarity Search from Task-Centric Views" (2512.12980)
Overview and Motivation
The paper critically revisits the prevailing methodologies in Vector Similarity Search (VSS), emphasizing the disconnect between synthetic metric-based evaluation and true downstream task utility across critical domains such as image classification, face recognition, text retrieval, and recommendation systems. Existing VSS benchmarks predominantly report recall-latency trade-offs with respect to distance-based ground truths, overlooking the semantics and label-alignment requirements of real-world applications. The authors introduce Iceberg, a full-spectrum benchmark suite, providing multi-layered diagnostics and actionable guidelines toward deploying VSS tuned for end-to-end task performance.
Three distinct stages underpin task-level information degradation in the VSS pipeline, conceptualized as the Information Loss Funnel:
Iceberg Benchmark Suite: Architecture and Evaluation Pipeline
Iceberg comprises eight heterogeneous, large-scale datasets spanning four representative tasks, using state-of-the-art embedding models and incorporating ground-truth labels and task-centric metrics such as Label Recall@K, Hit@K, and Matching Score@K. Thirteen leading VSS algorithms (partition-based and graph-based, supporting both ANNS and MIPS) are standardized and compared using both synthetic metrics and end-task measurements.
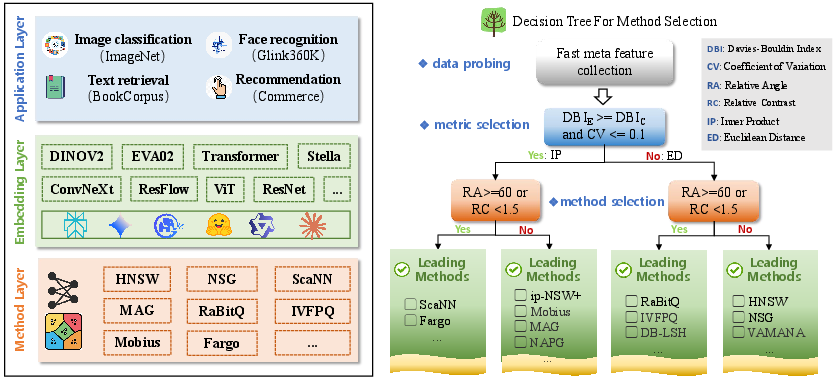
Figure 2: Iceberg's main contributions, including the decision tree, datasets, and evaluation framework across modalities and benchmarks.
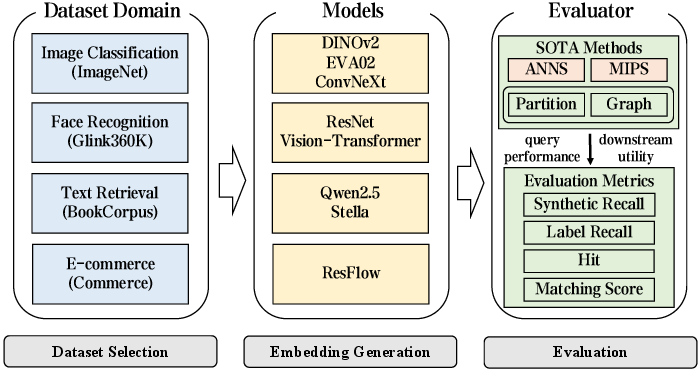
Figure 3: End-to-end benchmark pipeline of Iceberg from data ingestion, embedding generation, index construction, and task-specific evaluation.
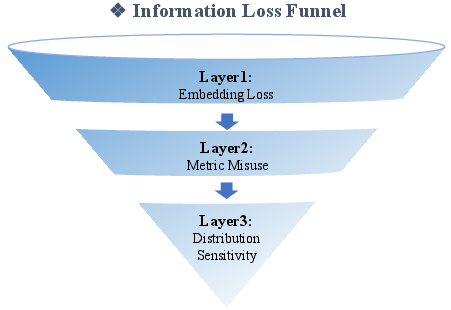
Figure 4: Schematic pipeline of the information loss funnel across embedding, metric selection, and index sensitivity layers.
Empirical Analysis: Pitfalls and Insights
1. Embedding Loss
Experiments reveal non-trivial upper bounds on task-centric accuracy even at 99.9% synthetic recall, e.g., DINOv2 embeddings on ImageNet achieve only ~71% label recall@100. Model architecture and loss formulations control maximal possible downstream utility.
2. Metric Misuse
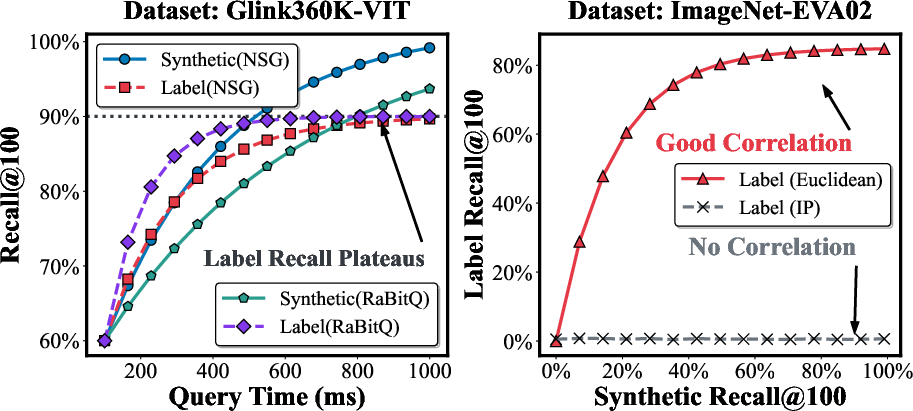
Selecting an inappropriate similarity metric for a given embedding can render high synthetic recall valueless. For instance, MIPS yields <1% label recall on some classification tasks, despite synthetic recall >99.9%. Conversely, semantic angular-margin losses (e.g., ArcFace) require inner-product metrics for optimal task utility.
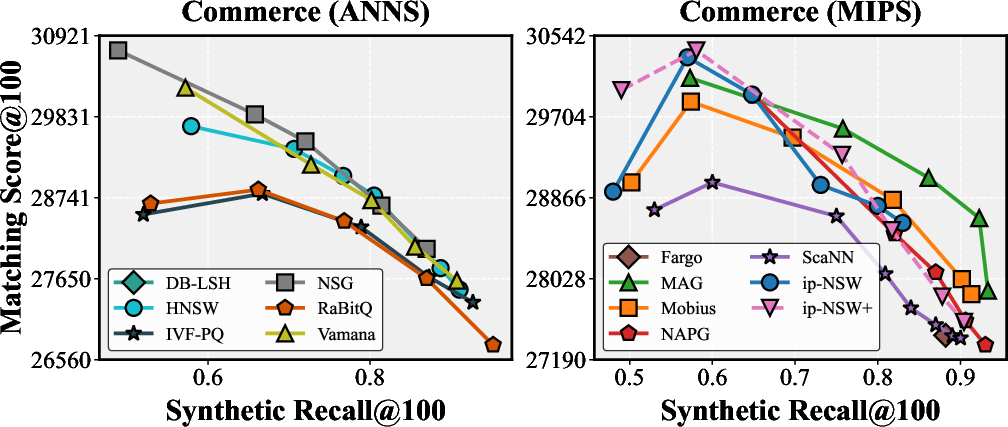
Figure 5: Downstream task-centric matching score versus synthetic metric recall on commerce recommendation—a non-monotonicity evidences metric misalignment.
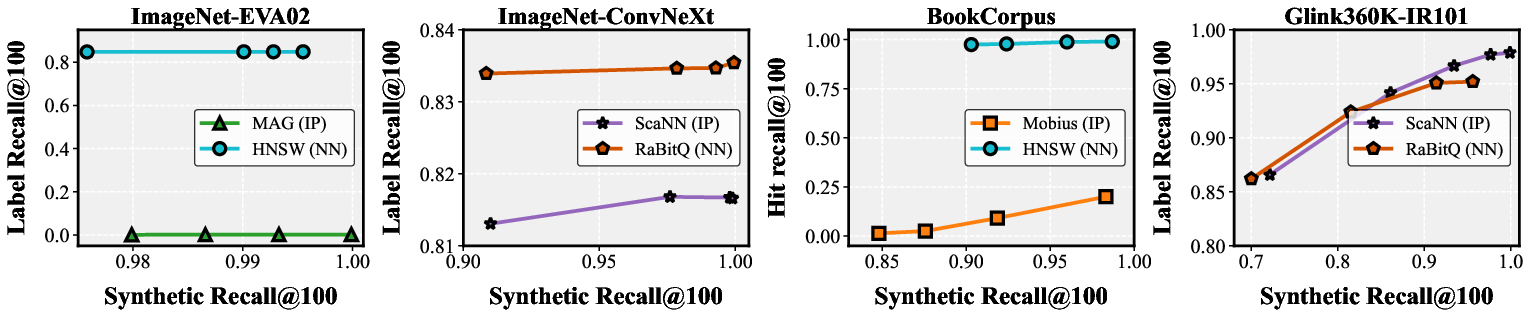
Figure 6: Task-centric performance differences as a function of similarity metric, demonstrating dependence on embedding geometry and loss.
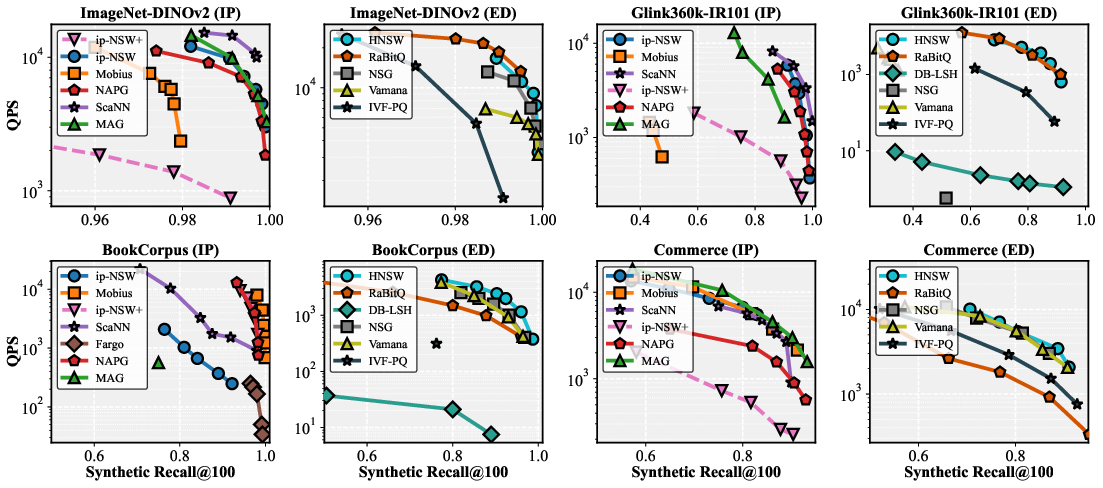
Figure 7: Synthetic recall curves across four representative datasets, contrasting methods and metric spaces.
3. Data Distribution Sensitivity
Partition-based methods outperform graph-based approaches for highly clustered or large angular dispersions in embeddings. In contrast, graph methods excel under moderate contrast and better connectivity. Erroneous method selection can sharply curtail achievable recall or throughput.
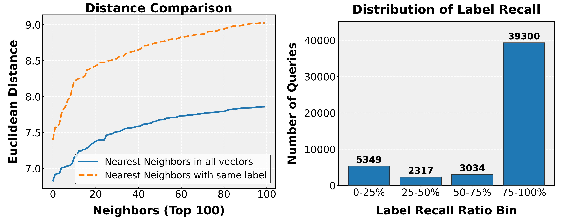
Figure 8: Label recall distributions and inter-query distance relationships under synthetic recall constraints, quantifying funnel bottlenecks.
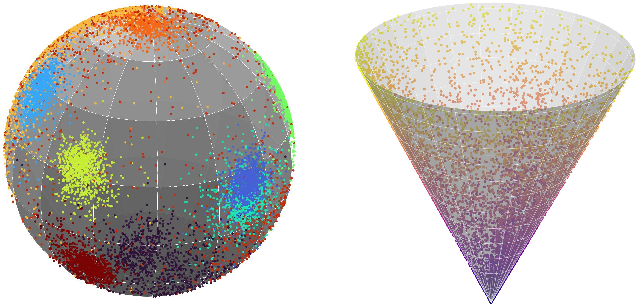
Figure 9: Visualization of representative dataset distributions—extreme angular separation in Glink360K versus norm-diverse, mixed structure in BookCorpus.
Decision Tree for Method Selection
Iceberg introduces an interpretable, meta-feature-driven decision tree guiding metric and method selection. Four meta-features govern these decisions:
- DBI (Davies-Bouldin Index): Separability and compactness of clusters (using either Euclidean or angular measures)
- CV (Coefficient of Variation of Norms): Uniformity in embedding norms
- RA (Relative Angle), RC (Relative Contrast): Inform angular dispersion and neighborhood density
Metric choice is dictated by joint DBI and CV thresholds. Subsequently, algorithmic selection leverages RA and RC, favoring partition-based methods for high angular dispersion or low local contrast, and graph-based methods for better global connectivity.
Iceberg's task-centric evaluations lead to substantial deviations from traditional synthetic recall-based rankings. For MIPS on commerce recommendation, ip-NSW+ outperforms graph-based MAG despite its synthetic recall supremacy. Across all domains, optimal method selection is dataset- and metric-dependent, necessitating adaptation beyond default best-practices.
Broader Implications and Future Directions
The layered analysis underscores that synthetic-centric optimization in VSS is fundamentally insufficient—pipeline information loss precludes end-task fidelity. The authors advocate for task-, metric-, and distribution-aware search algorithms capable of dynamic adaptation. Advances should include metric auto-selection, end-to-end optimization with downstream objectives, and hybrid indexing strategies. The interpretability of Iceberg’s decision tree facilitates actionable guidance for engineering teams and motivates principled algorithmic innovation.
Conclusion
This work operationalizes task-aligned evaluation for large-scale vector similarity search, exposing critical mismatches in current academic and industrial VSS practices. By formalizing the information loss funnel and introducing a comprehensive, integrated benchmark pipeline, it delivers both diagnostic insight and prescriptive tooling for robust, effective VSS deployment. Extension to emerging embedding paradigms and automated index adaptation emerges as the challenging and necessary trajectory for future research.