Hindsight is 20/20: Building Agent Memory that Retains, Recalls, and Reflects
Abstract: Agent memory has been touted as a dimension of growth for LLM-based applications, enabling agents that can accumulate experience, adapt across sessions, and move beyond single-shot question answering. The current generation of agent memory systems treats memory as an external layer that extracts salient snippets from conversations, stores them in vector or graph-based stores, and retrieves top-k items into the prompt of an otherwise stateless model. While these systems improve personalization and context carry-over, they still blur the line between evidence and inference, struggle to organize information over long horizons, and offer limited support for agents that must explain their reasoning. We present Hindsight, a memory architecture that treats agent memory as a structured, first-class substrate for reasoning by organizing it into four logical networks that distinguish world facts, agent experiences, synthesized entity summaries, and evolving beliefs. This framework supports three core operations -- retain, recall, and reflect -- that govern how information is added, accessed, and updated. Under this abstraction, a temporal, entity aware memory layer incrementally turns conversational streams into a structured, queryable memory bank, while a reflection layer reasons over this bank to produce answers and to update information in a traceable way. On key long-horizon conversational memory benchmarks like LongMemEval and LoCoMo, Hindsight with an open-source 20B model lifts overall accuracy from 39% to 83.6% over a full-context baseline with the same backbone and outperforms full context GPT-4o. Scaling the backbone further pushes Hindsight to 91.4% on LongMemEval and up to 89.61% on LoCoMo (vs. 75.78% for the strongest prior open system), consistently outperforming existing memory architectures on multi-session and open-domain questions.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy-to-Understand Summary of “Hindsight is 20/20: Building Agent Memory that Retains, Recalls, and Reflects”
Overview
This paper introduces Hindsight, a new way for AI assistants to remember and think over time. Instead of acting like a simple “answer machine,” Hindsight helps an AI keep track of what it learns, what it has experienced, and what it believes—so it can be more like a long-term helper who remembers past conversations and explains its reasoning.
What Questions Does the Paper Try to Answer?
The authors ask three big questions:
- How can an AI remember important information from long, ongoing conversations without getting confused or forgetting?
- How can it clearly separate what is a fact (like “Alice works at Google”) from what is an opinion (like “Python is better for data science”)?
- How can it think and respond consistently—like having a steady personality—while still updating its beliefs when new evidence shows up?
How Does Hindsight Work? (Methods Explained Simply)
Think of Hindsight like a smart, organized binder plus a thoughtful reviewer:
- The Binder: Four Sections of Memory Hindsight stores memories in four clearly labeled sections, so the AI knows what kind of information it’s using:
- World: Facts about the world (objective things that don’t depend on personal opinion).
- Experience: The AI’s own actions or things it did (“I recommended a hiking spot to Alice”).
- Opinion: The AI’s personal judgments (with a confidence score, like “I’m 85% sure Python is best for data science”).
- Observation: Neutral summaries about people or things (short profiles pulled from multiple facts).
- Three Core Operations (Like how a person handles a notebook)
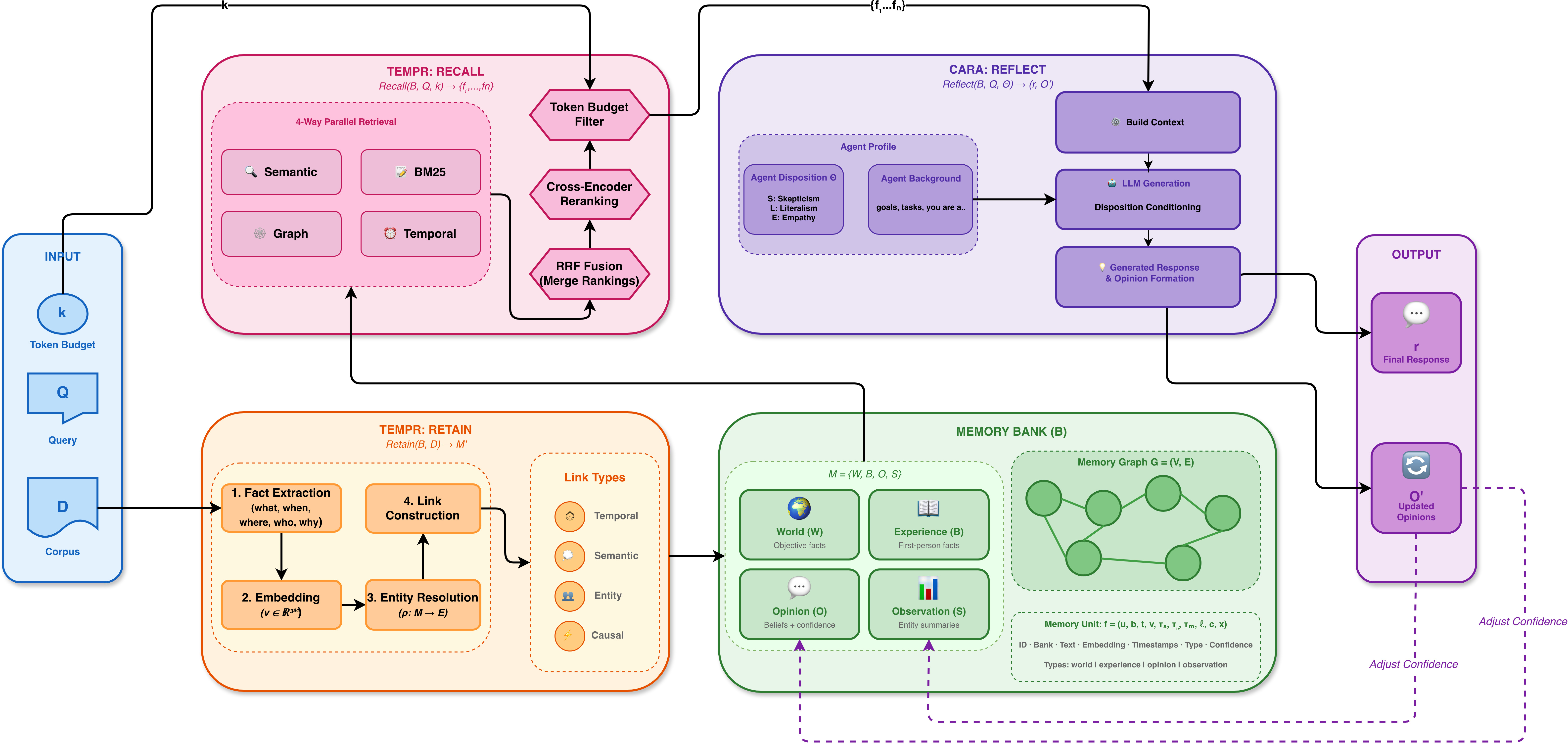
- Retain: Save new information. The AI turns conversations into clear, time-stamped facts, recognizes people and places, and links related ideas together.
- Recall: Find the right memories when answering a question. The AI searches using multiple strategies—by meaning, specific keywords, connections between people or events, and time ranges—then picks the best set that fits within a limited space.
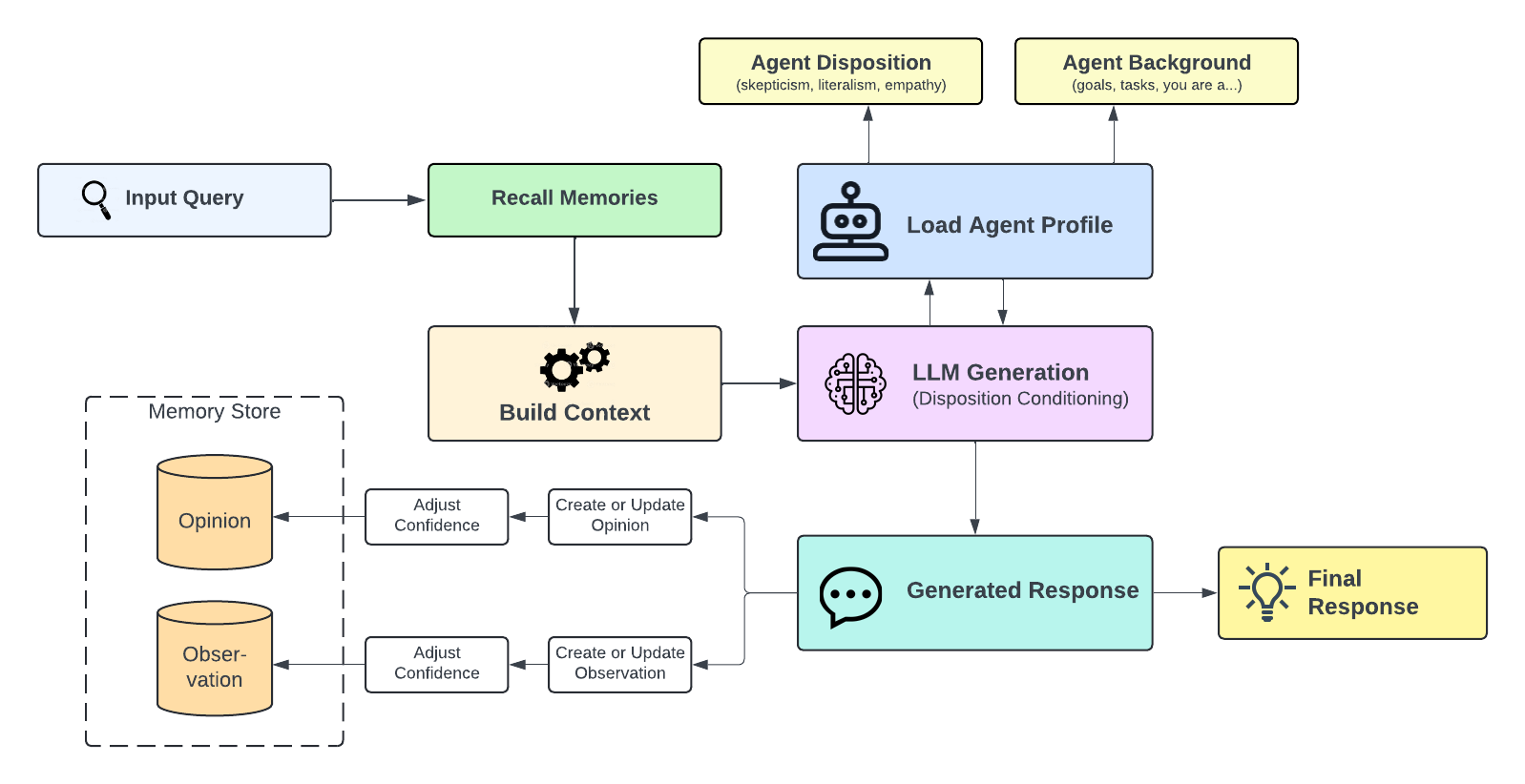
- Reflect: Think and respond. The AI combines the retrieved memories with its “behavior style” to give a consistent answer. It can also form or update opinions and record how confident it is.
- Two Main Parts (like teams that handle different jobs)
- TEMPR (Retain + Recall): The “librarian” that organizes the binder and finds the right pages. It builds a connected memory graph using:
- Time: When things happened.
- Entities: Who or what is involved (like Alice, Google, Yosemite).
- Meaning: How similar ideas are.
- Causes: What leads to what.
- It searches in parallel using multiple methods, fuses the results, re-ranks them with a smart model, and fits them into a token budget (like a page limit).
- CARA (Reflect): The “thinker” that writes the answer. It uses the AI’s profile—name, background, and behavior settings—to shape responses. Behavior settings include:
- Skepticism: How cautious or trusting it is.
- Literalism: How strictly it follows exact wording vs. reading between the lines.
- Empathy: How much it cares about feelings and relationships.
- Bias strength: How strongly the personality influences the final answer.
- CARA also keeps an Opinion network with confidence scores and updates beliefs when new evidence arrives.
What Did They Find? Why Is It Important?
The authors tested Hindsight on tough memory benchmarks where AIs must remember long, multi-session conversations and answer questions that depend on older details:
- LongMemEval:
- Using an open-source 20B model, Hindsight increased accuracy from 39.0% (baseline) to 83.6%.
- With a larger model, it reached 91.4%.
- LoCoMo:
- Using the same open 20B backbone, Hindsight improved accuracy from 75.78% to 85.67%.
- With larger models, it reached 89.61%, beating the strongest prior open systems and full-context GPT-4o in these settings.
Why this matters:
- It shows that organizing memory carefully and separating facts from opinions helps AI perform better on long, realistic conversations.
- It demonstrates that adding a consistent “personality” and tracking opinion confidence makes answers more stable and explainable.
What’s the Big Picture? (Implications)
Hindsight helps build AI assistants that:
- Remember across many sessions without mixing up facts and beliefs.
- Explain where their answers come from (traceable reasoning).
- Keep a consistent “style” or perspective while still updating beliefs when new information is found.
- Perform better on real-world tasks that need long-term memory—like tutoring, personal assistants, customer support, or research helpers.
In short, this work moves AI beyond short, one-off answers toward long-term partners that can learn, remember, reason, and reflect—much like a careful student who keeps a well-organized binder and writes thoughtful, consistent essays.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, articulated so future researchers can act on them:
- Formalize and evaluate the opinion reinforcement mechanism: how confidence is computed, updated, and calibrated when new, conflicting, or uncertain evidence arrives; criteria for contradiction/support; prevention of confirmation bias; and convergence/forgetting dynamics over long horizons.
- Traceability and explanation quality: the paper claims “traceable” updates and reasoning, but lacks a concrete method for attaching citations to specific memory units, edge types, and confidence scores in responses; define measurable explanation metrics and user-facing provenance formats.
- Reliability and evaluation of LLM-based narrative fact extraction: quantify extraction accuracy (factuality, completeness, cross-turn coherence) and error modes across domains and languages; provide benchmarks and ablations against rule-based or sentence-level pipelines.
- Entity resolution robustness: the heuristic combination of string/co-occurrence/temporal proximity with LLM-detected mentions lacks training and evaluation for ambiguity, nicknames, multilingual names, merges/splits (entity drift), and cross-bank duplicates; specify how are tuned and validated.
- Temporal normalization coverage: clarify handling of time zones, vague/implicit references, nested time expressions, multi-locale formats, and the distinction between occurrence intervals vs. mention timestamps; explore bi-temporal modeling and report temporal parsing accuracy.
- Causal link extraction validity: LLM-derived causal edges (causes, enables, prevents) are not validated for false positives/negatives; define supervised or weakly supervised methods, quality metrics, and downstream impact on retrieval/answers.
- Retrieval fusion and reranking: no ablations show contributions of semantic/BM25/graph/temporal channels, RRF vs. score fusion, or cross-encoder gains; assess domain mismatch of
ms-marcocross-encoder on conversational memory and consider task-specific training. - Token-budget packing policy: long narrative facts may crowd out diverse evidence; study packing strategies (e.g., dynamic summarization, split/merge policies, redundancy suppression) and their impact on answer quality under tight budgets.
- Observation generation neutrality and fidelity: define methods and metrics to ensure “preference-neutral” summaries align with underlying facts, avoid LLM bias or drift, and handle contentious/uncertain attributes; include versioning and auditability for observation updates.
- Asynchronous updates and eventual consistency: characterize latency, staleness, and concurrency effects when observations regenerate in the background; provide guarantees or strategies to avoid inconsistent reads at query time.
- Conflict resolution across networks: specify policies when world/experience facts contradict opinions or observations; how are conflicts surfaced, resolved, or preserved with metadata (e.g., confidence, validity intervals)?
- Preference consistency measurement: introduce quantitative metrics and human evaluations for the stability of behavioral style under CARA (effects of skepticism/literalism/empathy and ) across sessions and tasks; study plasticity vs. rigidity trade-offs.
- Safety and adversarial robustness: investigate prompt injection, memory poisoning (malicious writes), entity hijacking, and retrieval attacks; propose sanitization, trust scoring, and anomaly detection in retain/recall/reflect pipelines.
- Privacy and governance: define policies for PII handling, per-user isolation, right-to-be-forgotten, redaction, and audit logging across networks (especially experience vs. world); evaluate compliance and access control models.
- Scaling characteristics: report storage footprints, index sizes, latency/throughput, and cost under millions of facts and multi-bank deployments; study HNSW/GIN configuration, sharding/replication, and multi-tenant performance isolation.
- Learning graph weights and thresholds: link-type multipliers , decay , temporal , and semantic thresholds are heuristic; explore learning them end-to-end (or per-bank) with supervision or bandit feedback to improve retrieval quality.
- Retrieval intent detection: temporal intent detection is heuristic+
flan-t5-small; evaluate failure modes and multilingual coverage; integrate learned intent classifiers for temporal, causal, and entity-centric queries. - Handling change over time: define strategies for evolving entities (job changes, relationships), validity intervals, and deprecation; compare with bi-temporal approaches (valid time vs. transaction time) and introduce automated reconciliation.
- Interplay of observations and opinions at recall time: clarify when to prefer synthesized observations vs. raw facts vs. opinions; study ranking biases that might elevate subjective opinions over objective evidence.
- Reproducibility and release: identify the exact open-source 20B backbone, training/finetuning (if any), hyperparameters, and code/data artifacts needed to reproduce reported gains; report hardware resources and cost.
- Benchmarks and generalization: expand beyond LongMemEval/LoCoMo to continual-learning (e.g., MemoryBench), subjective/opinion tasks, non-English, and multimodal memory; measure robustness across domains and real user workloads.
- Chunking strategy sensitivity: evaluate how the “2–5 narrative facts per conversation” choice affects retrieval precision/recall, redundancy, and downstream accuracy; provide guidance or adaptive chunking methods.
- Opinion confidence calibration: establish calibration methods (e.g., Platt scaling, isotonic regression) and utility-aware calibration metrics (ECE, Brier) for so confidence is interpretable and useful in decision-making.
- Output grounding and chain-of-thought: explore structured justifications that reference specific memory nodes/edges, temporal intervals, and opinion confidences without revealing sensitive internal reasoning; evaluate user trust and utility.
Practical Applications
Below are practical, real-world applications that follow directly from the paper’s findings and innovations (four-network memory, retain/recall/reflect operations, TEMPR multi-strategy retrieval, CARA preference-conditioned reasoning, opinion confidence and evolution, and traceable updates). Each item names the sector and suggests potential tools/workflows, with assumptions or dependencies that could affect feasibility.
Immediate Applications
- Persistent, multi-session customer support agents (software, CX/CRM)
- Use Hindsight’s structured memory to retain world facts (products, policies), experience (past tickets and resolutions), observation profiles (customer summaries), and opinion evolution (agent’s recommendations with confidence).
- Tools/workflows: “Recall API” with token budget for on-demand context; “Observation profiles” auto-generated for each account; “Opinion reinforcement” on solution efficacy.
- Assumptions/Dependencies: Accurate entity resolution across customers/products; PII governance; latency control on multi-channel retrieval; reliable cross-encoder reranking.
- Sales and account management copilots with traceable memory (finance, enterprise SaaS)
- Maintain long-horizon deal history, stakeholder maps, and evolving viewpoints (e.g., risk assessment with confidence), while separating evidence (emails, call notes) from inference (deal likelihood).
- Tools/workflows: Memory graph service in the CRM; campaign planning via temporal recall; “belief audit” trails to explain recommendations.
- Assumptions/Dependencies: Integration with existing CRMs and email systems; robust temporal normalization; consent and data retention policies.
- Editorial research assistants with bias-managed reasoning (media/newsrooms)
- Support journalists by retrieving entity-aware, temporal facts and producing opinionated takes gated by configurable disposition (skepticism/literalism/empathy) and bias strength.
- Tools/workflows: Disposition console per desk (investigations vs. lifestyle); opinion network with confidence scores; citation-aware recall via graph links.
- Assumptions/Dependencies: Source credibility metadata; avoiding overfitting agent opinions to editorial stance; auditability for corrections.
- Long-term tutoring systems that track evolving understanding (education)
- Store student progress as world/experience facts and maintain a student “belief map” (opinions with confidence) to surface misconceptions and update them as evidence arrives.
- Tools/workflows: “Reflect” loop to form/reinforce learning opinions; temporal recall for spaced repetition; observation profiles per student for concise summaries.
- Assumptions/Dependencies: Domain-aligned extraction prompts; privacy/FERPA compliance; calibration of confidence scores to learning outcomes.
- Developer team assistants with project memory (software engineering, DevOps)
- Retain design decisions, code-review rationales, incident timelines; recall via entity/temporal links; reflect to keep a consistent persona (e.g., “skeptical, highly literal” for reliability).
- Tools/workflows: Repo and ticket ingestion into the memory bank; “temporal recall” for outages; opinion reinforcement on trade-offs.
- Assumptions/Dependencies: Access to code and issue trackers; mapping of entities (services, tickets) across tools; low-latency search in large graphs.
- Case management for public services with auditability (policy/government)
- Support social workers and case officers with longitudinal, multi-session memory that separates evidence (documents) from opinions (assessments, confidence).
- Tools/workflows: Audit trail of reflect operations; observation profiles per case; temporal recall constrained to case phases.
- Assumptions/Dependencies: Legal constraints on storing sensitive data; human oversight; standardized schemas for case notes.
- Enterprise knowledge bases with “evidence vs. inference” separation (enterprise IT)
- Replace ad-hoc wikis/RAG with four-network memory so answers cite world facts while opinions are explicitly marked and updated.
- Tools/workflows: Memory-as-a-Service (external-only memory for editability); Reciprocal Rank Fusion (fusion of BM25, semantic, graph, temporal); cross-encoder reranking.
- Assumptions/Dependencies: Coverage of internal source systems; quality of narrative fact extraction; cost budget tuning for recall depth.
- Meeting and workflow assistants with preference-consistent personas (productivity/daily life)
- Consistently summarize meetings, track decisions, and maintain a stable reasoning style over time; generate entity observations for participants/projects.
- Tools/workflows: Automatic retain after meetings; recall with token budgets; profile manager for tone/style consistency.
- Assumptions/Dependencies: Accurate speaker attribution; calendar/email integration; user control over disposition settings.
- Personal digital memory and journaling with confidence-tagged beliefs (daily life, wellness)
- Maintain a structured personal memory bank, separating what happened (world/experience) from evolving beliefs (opinion network with confidence).
- Tools/workflows: Background observation generation for people/places; “reflect” to form/revise beliefs about habits or goals; temporal recall for retrospectives.
- Assumptions/Dependencies: Local-first or privacy-preserving storage; easy entity resolution in informal text; controls for forgetting/retention.
- Compliance and governance overlays for AI agents (policy, risk/compliance)
- Enforce epistemic clarity by distinguishing evidence from inference in agent outputs; log belief updates with confidence and timestamps for audits.
- Tools/workflows: “Belief ledger” and reflect traces; risk dashboards showing opinion evolution; token-budget-aware recall to avoid prompt spills of sensitive data.
- Assumptions/Dependencies: Regulatory definitions of evidence vs. inference; secure storage; redaction pipelines.
Long-Term Applications
- Longitudinal clinical assistants with evolving patient models (healthcare)
- Maintain temporal, entity-aware patient memory (conditions, interventions) and a clinician opinion network (hypotheses with confidence), enabling consistent, traceable reasoning across visits.
- Tools/workflows: EHR ingestion into world/experience networks; temporal recall for episodes of care; belief reinforcement based on new labs/imaging.
- Assumptions/Dependencies: Clinical validation; strict privacy/compliance (HIPAA); integration with medical ontologies; human-in-the-loop safeguards.
- Organization-level “memory OS” for multi-agent ecosystems (enterprise platforms)
- Shared four-network memory across numerous agents, each with disposition profiles, coordinating via entity/causal links (e.g., marketing, sales, support, finance).
- Tools/workflows: Bank federation; multi-agent recall scheduling with cost budgets; global opinion harmonization and conflict resolution.
- Assumptions/Dependencies: Access control and tenancy; cross-team schema alignment; scalability of graph traversal and background observation regeneration.
- Safety and governance frameworks for opinion evolution (policy, AI safety)
- Standardize how agents store, update, and audit beliefs (confidence, timestamp), supporting regulatory checks, reproducibility, and explainability.
- Tools/workflows: Opinion taxonomies; audit APIs; standardized “reflect traces” and evaluation suites for long-horizon behaviors.
- Assumptions/Dependencies: Industry consensus on formats; benchmark adoption beyond LongMemEval/LoCoMo; third-party certification.
- Cognitive robotics with persistent, multi-session memory (robotics)
- Extend TEMPR/CARA with multimodal perception and 3D scene graphs to retain and recall spatial-temporal experiences, with consistent persona-driven decision-making.
- Tools/workflows: Sensor-to-fact extraction; entity linking across objects/places; causal links for manipulation outcomes.
- Assumptions/Dependencies: Robust multimodal extraction; real-time constraints; safety-critical validation; integration with embodied memory (e.g., KARMA-like scene graphs).
- Adaptive education platforms that model class-wide and individual beliefs (education EdTech)
- Maintain per-learner and cohort-level opinion networks (misconceptions with confidence) and auto-update observation profiles to personalize instruction long-term.
- Tools/workflows: Curriculum-aware retain pipelines; cohort-level causal link analysis; teacher dashboards for belief evolution.
- Assumptions/Dependencies: Pedagogical validation; data protection; fairness across demographics; interoperability with LMS systems.
- Financial advisory and “AI CFO” assistants with transparent strategies (finance)
- Separate market evidence (world facts) from strategic stances (opinions with confidence), maintain stable preference profiles, and update beliefs as new data arrives.
- Tools/workflows: Portfolio memory banks; temporal recall for market regimes; opinion reinforcement tied to performance metrics.
- Assumptions/Dependencies: Regulatory compliance; risk modeling validation; data licensing; robust backtesting and guardrails.
- Energy operations memory for grid and plant management (energy/utilities)
- Store long-horizon operational logs, incidents, and causal chains; recall temporally aligned events; reflect to build consistent reliability-centered recommendations.
- Tools/workflows: OT/SCADA log ingestion; causal link extraction for root-cause; observation profiles for assets/sites.
- Assumptions/Dependencies: Industrial data integration; safety and resiliency testing; specialized domain extraction templates.
- Collective memory for communities and platforms (social platforms, civic tech)
- Community agents maintain shared world/experience facts and openly track evolving opinions with confidence, enabling transparent decision-making and policy iteration.
- Tools/workflows: Public belief ledgers; temporal recall for governance cycles; disposition settings tuned for deliberation (e.g., high skepticism, high empathy).
- Assumptions/Dependencies: Moderation and misuse prevention; consent and representation; scalability of public memory graphs.
- Federated, privacy-preserving personal memory (daily life, privacy tech)
- Local-first memory banks with optional federated synchronization; opinions evolve on-device, and observations are shared selectively across apps.
- Tools/workflows: Federated retain/recall; on-device cross-encoder; encrypted opinion updates with differential privacy.
- Assumptions/Dependencies: Efficient on-device models; secure key management; standards for app interoperability.
- Agent evaluation and training focused on long-horizon consistency (academia, AI research)
- New benchmarks and methods to quantify preference consistency, opinion evolution quality, and epistemic clarity; training procedures that align retain/recall/reflect behaviors.
- Tools/workflows: Expanded LongMemEval/LoCoMo-like suites; synthetic evaluation harnesses; ablation tools for link types and fusion strategies.
- Assumptions/Dependencies: Community adoption; reproducible pipelines; comparative baselines across open and proprietary LLMs.
These applications leverage the paper’s key contributions—structured separation of evidence and inference, temporal/entity-aware retrieval with multi-strategy fusion, explicit opinion modeling with confidence and traceable updates, and configurable disposition profiles—to deliver deployable improvements now and to enable more ambitious, multi-agent and safety-critical systems over time.
Glossary
- Agent-Optimized Retrieval Interface: A retrieval interface that lets agents specify context size and effort instead of a fixed top-k; "Rather than exposing a fixed top- interface, TEMPR lets the caller specify how much context to retrieve and how much effort to spend finding it."
- Bias-strength parameter: A scalar controlling how strongly an agent’s behavioral profile influences reasoning; "behavioral profile (consisting of disposition behavioral parameters (skepticism, literalism, empathy) and a bias-strength parameter)"
- Bi-temporal modeling: Modeling both the valid time and the recording time of facts in a knowledge graph; "builds temporal knowledge graphs with bi-temporal modeling that tracks when facts are valid versus when they were recorded"
- BM25 ranking: A classic lexical retrieval scoring function used in full-text search; "we run a lexical channel using a full-text search with BM25 ranking over a GIN index on the memory text."
- Causal links: Graph edges representing cause-effect relationships between memories; "Causal Links. Causal relationships are extracted by the LLM and represent cause-effect relationships."
- Context window: The maximum token span an LLM can process at once; "Recent findings \citep{huang2025llms} show that LLMs lack true working memory and must externalize state into context windows."
- Coreference resolution: Identifying when different mentions refer to the same entity in text; "1) coreference resolution over the conversation to identify entity mentions and their referents;"
- Cosine similarity: A measure of vector similarity based on the normalized dot product; "The semantic retrieval channel performs vector similarity search using cosine similarity between the query embedding and memory embeddings."
- Cross-encoder reranking: Reranking candidates by jointly encoding query and candidate with a neural model; "After RRF fusion, TEMPR applies a neural cross-encoder reranker to refine precision on the top candidates."
- Disposition behavioral parameters: Configurable traits (skepticism, literalism, empathy) that shape an agent’s reasoning style; "consisting of disposition behavioral parameters (skepticism, literalism, empathy) and a bias-strength parameter"
- Embedding vector: A high-dimensional numeric representation of text for semantic search; "where is a unique identifier, is the bank identifier, is the narrative text, is the embedding vector"
- Entity-aware memory graph: A graph linking memories by shared entities, time, semantics, and causality; "turning raw conversational transcripts into a structured, temporal, entity-aware memory graph"
- Entity resolution: Mapping mentions to canonical entities to unify references across memories; "Entity resolution links memories that refer to the same underlying entity, enabling multi-hop reasoning over the memory graph."
- External memory: Memory stored outside model parameters that supports dynamic updates; "arguing for external memory that supports dynamic updates."
- GIN index: A Generalized Inverted Index used for fast full-text search in databases; "using a full-text search with BM25 ranking over a GIN index on the memory text."
- HNSW-based pgvector index: A Hierarchical Navigable Small World graph index for efficient vector search in Postgres; "We use an HNSW-based pgvector index to efficiently retrieve the top- memories by semantic score"
- LLMs: Scaled neural models trained to understand and generate natural language; "today are still built around short-context retrieval-augmented generation (RAG) pipelines and generic LLMs."
- Multi-strategy retrieval: A pipeline that combines semantic, lexical, graph, and temporal methods; "combining semantic vector search, keyword search, graph traversal, and temporal filtering into a unified multi-strategy retrieval pipeline"
- Opinion reinforcement mechanism: A process for updating opinion confidence when new evidence arrives; "when new evidence arrives, existing beliefs in are also updated through an opinion reinforcement mechanism"
- Parametric memory: Information stored within model parameters rather than external stores; "combining retrieval and parametric memory via fine-tuning"
- Participant attribution: Assigning actions or statements to specific participants in a conversation; "3) participant attribution to determine who did or said what in the conversation;"
- Preference-conditioned generation: Response generation shaped by an agent’s behavioral profile; "then applying preference-conditioned generation to produce a response"
- Preference consistency: Maintaining a stable reasoning style and viewpoint over time; "their inability to exhibit preference consistency, i.e., expressing a stable reasoning style and viewpoint across interactions rather than producing locally plausible but globally inconsistent responses"
- Recency-aware ranking: Ranking that prefers items closer in time to the query; "enabling precise historical queries and recency-aware ranking."
- Reciprocal Rank Fusion: A rank-based method to merge multiple retrieval lists; "applies Reciprocal Rank Fusion and cross-encoder reranking"
- Retrieval-augmented generation (RAG): Using retrieved context to improve generation quality; "built around short-context retrieval-augmented generation (RAG) pipelines"
- Semantic links: Graph edges connecting memories based on embedding similarity; "Semantic Links. For any two memories and with embeddings , we create a semantic link if their cosine similarity exceeds a threshold "
- Sequence-to-sequence model: A neural architecture mapping input sequences to output sequences; "we fall back to a lightweight sequence-to-sequence model (here, we use google/flan-t5-small)"
- Spreading activation: A graph-based retrieval technique that propagates relevance through links; "The third channel exploits the memory graph via spreading activation."
- Temporal expression normalization: Converting natural language time phrases to normalized timestamps; "2) temporal expression normalization and range extraction to convert relative time references (
last week'',in March'') into absolute timestamps ;" - Temporal filtering: Restricting retrieval to items matching a specified time range; "combining semantic vector search, keyword search, graph traversal, and temporal filtering into a unified multi-strategy retrieval pipeline"
- Temporal graph retrieval: A retrieval channel focused on events within the query’s time window; "we invoke a temporal graph retrieval channel backed by a hybrid temporal parser."
- Temporal knowledge graphs: Knowledge graphs where facts and relationships are annotated with time; "Zep \citep{rasmussen2025zep} builds temporal knowledge graphs with bi-temporal modeling"
- Temporal links: Graph edges connecting memories that are close in time; "Temporal Links. For any two memories and with temporal metadata, we create a temporal link if they are close in time."
- Temporal parser: A component that interprets date/time expressions into structured ranges; "backed by a hybrid temporal parser."
- Token budget: The maximum allowed tokens for retrieved memories to fit in the model context; "takes as input memory bank , query , and token budget "
- Vector similarity search: Retrieving items by comparing their embeddings in vector space; "The semantic retrieval channel performs vector similarity search using cosine similarity"
- Zettelkasten method: A note-taking system emphasizing atomic, linked notes that evolve; "A-Mem \citep{xu2025mem} uses the Zettelkasten method to create atomic notes with LLM-generated links that evolve over time"
Collections
Sign up for free to add this paper to one or more collections.