- The paper presents a unified memory architecture combining short-term, long-term, and parametric modalities for scalable, lifelong learning.
- The approach leverages multimodal knowledge graphs and periodic distillation to enable fast, context-aware recall and robust cross-modal reasoning.
- MemVerse demonstrates superior performance in benchmark evaluations, achieving significant improvements in retrieval speed and accuracy over conventional methods.
MemVerse: A Unified Multimodal Memory Architecture for Lifelong Learning Agents
Motivation and Problem Statement
MemVerse addresses three core limitations in contemporary AI agent memory: tight binding of memory to model weights, lack of abstraction in external memory stores, and poor multimodal reasoning. Existing paradigms, such as parametric memory (knowledge encoded in weights) and retrieval-augmented external memory, provide either fast but rigid recall or flexible but inefficient retrieval, with both approaches exhibiting substantial drawbacks in scalability, continual learning, and multimodal grounding. These weaknesses preclude agents from coherent long-horizon reasoning and adaptive knowledge integration, especially as real-world interaction shifts toward open-ended, multimodal environments.
System Architecture
MemVerse is proposed as a model-agnostic, plug-and-play memory framework that simultaneously leverages fast parametric recall and hierarchical retrieval-based memory. The central innovation is a dual-path memory orchestration system, integrating three memory modalities:
- Short-term memory caches recent context, optimizing for efficiency in ongoing interactions.
- Long-term memory transforms raw multimodal experiences into specialized memory types (core, episodic, semantic) structured as hierarchical multimodal knowledge graphs (MMKGs). These graphs encode entities and semantic relationships, support continual abstraction, and maintain bounded growth via adaptive pruning and consolidation.
- Parametric memory is maintained as a lightweight neural module, periodically distilled from long-term memory for fast, differentiable recall and direct integration with agent reasoning pipelines.
A rule-based memory orchestrator mediates all storage, retrieval, and update operations across these components, enabling unified multimodal processing and robust lifelong learning.
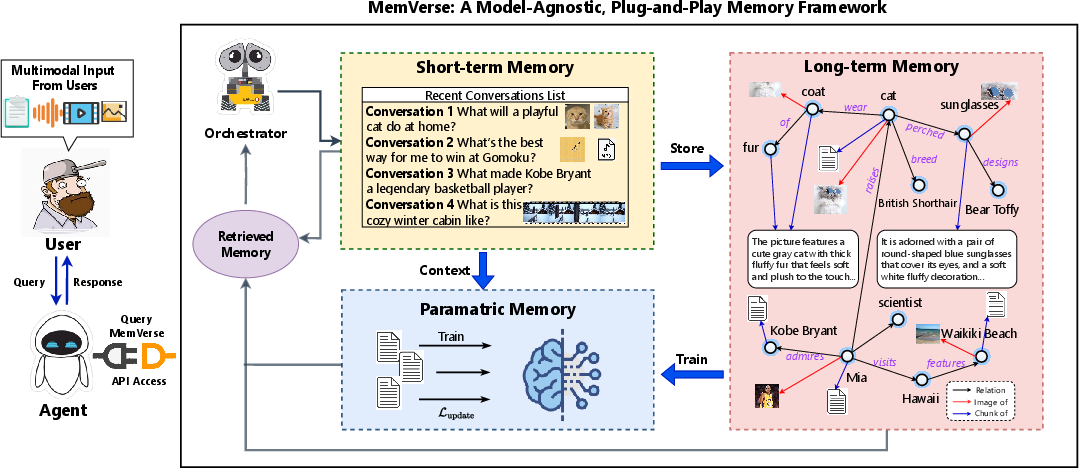
Figure 1: MemVerse incorporates short-term, long-term (MMKG), and parametric modalities under a central orchestrator to achieve scalable lifelong multimodal memory and reasoning.
Memory Construction and Distillation
Raw incoming multimodal data are initially encoded using pretrained modality-specific models and aligned via tokenization. Textual representations serve as the canonical linking substrate for constructing MMKGs, which are then abstracted to salient entities and relations via LLM-driven compression routines. Each graph node or relation maintains explicit references to supporting multimodal sources, preserving precise grounding and enabling rich relational reasoning.
Parametric memory is periodically distilled from the retrieval-based memory via supervised fine-tuning, using constructed (question, retrieved context, answer) triplets. This mechanism allows essential knowledge to be “internalized” into a compact neural module, preserving generalizability and enabling rapid context-aware inference.
Experimental Evaluation
MemVerse demonstrates strong performance across diverse multimodal benchmarks:
- ScienceQA: Using GPT-4o-mini as the backbone, MemVerse achieves an average accuracy of 85.48%, outperforming all baselines in both subject-specific and context-modality metrics. Notably, it yields 89.09% accuracy in language, 78.19% in image captions, and 88.11% for primary grade levels.
- Retrieval Speed: Parametric memory retrieval operates at 2.28 seconds per query—an 89% acceleration over RAG and 72% over long-term retrieval with only negligible degradation in downstream accuracy.
- MSR-VTT (Video Text Retrieval): MemVerse achieves R@1 scores of 90.4% (text-to-video) and 89.2% (video-to-text), representing over a 60 percentage point improvement versus CLIP baselines. These gains are realized without exposing explicit ground-truth alignments, demonstrating the agent’s capability in leveraging cross-modal associations from memory graphs.
Memory Utilization Analysis
Further ablation reveals nontrivial differences in memory utilization across model architectures. GPT-family models exploit retrieved content for reasoning integration effectively, whereas models like Qwen require more structured prompt design for optimal performance—underscoring the importance of tight retrieval-reasoning coupling and prompting heuristics for agentic architectures.
Periodic distillation and dynamic memory expansion schemes maintain stability, enable incremental knowledge acquisition, and scale across model sizes (1.5B–72B parameters) without loss in memory efficiency or reasoning throughput.
Practical and Theoretical Implications
MemVerse’s modular architecture enables scalable, interpretable, and multimodally grounded memory for agentic systems, supporting continual learning and lifelong adaptation. Practically, it offers a route to robust, lightweight deployment in open-domain applications (dialogue, video retrieval, interactive reasoning) wherein context persistence, semantic abstraction, and cross-modal association are paramount.
From a theoretical perspective, MemVerse establishes a template for unified dual-path memory systems that mimic biological cognition’s fast/slow abstraction and recall. The memory framework demonstrates that scalable memory and knowledge management, rather than mere model scaling, are pivotal for agent coherence and continual learning.
Future Directions
Potential advances include adaptive memory control strategies, hierarchical memory management in open-world settings, and integration of reinforcement learning for autonomous memory optimization. Deployment of MemVerse as a core memory substrate in multi-agent and tool-integrated environments offers further opportunities for scalable agentic intelligence.
Conclusion
MemVerse provides a unified, modular memory architecture for lifelong multimodal AI agents. Through hierarchical retrieval, structured knowledge graph construction, and fast parametric distillation, it achieves significant improvements in reasoning accuracy, efficiency, and context coherence. MemVerse’s design substantiates the claim that robust, scalable memory—not indiscriminate model enlargement—is the main driver of progress for continual learning systems. Further research into orchestration and adaptive strategies is warranted for next-generation agent deployment.
(2512.03627)