- The paper introduces a novel feedforward framework that synthesizes complete 3D scenes from a single image by integrating visual and geometric features.
- The paper employs multi-stage feature extraction and aggregation using DINOv2, VGGT, and DiT blocks to achieve precise asset-level and scene-level details.
- The paper demonstrates superior performance over existing methods by optimizing spatial arrangements, texture quality, and inference speed.
Detailed Expert Summary of "SceneGen: Single-Image 3D Scene Generation in One Feedforward Pass" (2508.15769)
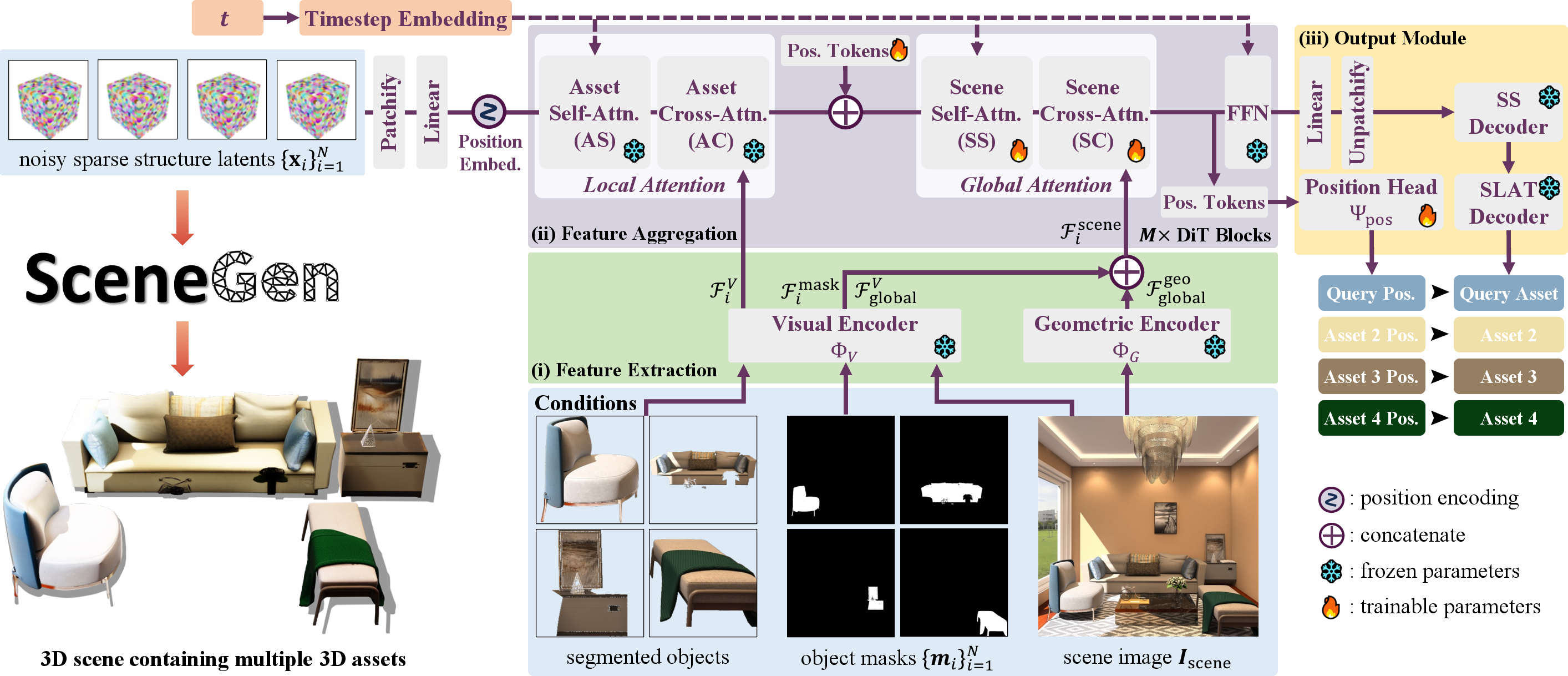
The paper introduces SceneGen, a comprehensive framework for generating multiple 3D assets from a single scene image in one feedforward pass. This study is aimed at facilitating the synthesis of coherent, high-quality 3D assets without requiring the traditional optimization or retrieval methods. By leveraging both visual and geometric encoders and a novel feature aggregation module, SceneGen represents an advancement in the domain of 3D scene generation.
Methodology
SceneGen Framework
SceneGen leverages a multi-stage approach, capturing both asset-level and scene-level features to generate 3D scenes efficiently.
- Feature Extraction: Utilizes DINOv2 for visual and VGGT for geometric features.
- Extracts individual asset features, mask features, and global scene features.
- Feature Aggregation: Employs DiT blocks to integrate local and global features.
- Integrates a local attention block for asset-level detail and a global attention block for inter-object interactions.
- Output Module: Decodes features into multiple 3D assets with their geometry, textures, and spatial configurations.
Training and Generalization
SceneGen is trained with emphasis on both geometric accuracy and textural quality, using a composite loss function that includes flow matching, position, and collision losses. Notably, SceneGen extends capabilities to multi-view inputs, demonstrating improved generation quality without requiring additional training.
- Data Augmentation: The training data is augmented from the 3D-FUTURE dataset, considering up to 30K samples with diverse asset configurations.
- Training Objectives: Combines flow-matching loss with position and collision constraints to improve robustness and physical plausibility of generated scenes.
Despite being trained on single-image inputs, SceneGen naturally extends to handle multi-view inputs by integrating features from multiple perspectives and averaging positional outputs, thus enhancing spatial understanding and textural details.

Figure 2: Qualitative Results with Multi-view Inputs. SceneGen demonstrates enhanced generation quality by leveraging multi-view input capabilities.
Results and Evaluations
SceneGen demonstrates significant improvements over baseline methods such as PartCrafter, DepR, Gen3DSR, and MIDI across various geometric and visual metrics, highlighting its effectiveness in generating coherent 3D scenes.
- Quantitative Evaluation: Achieves superior performance in both asset-level and scene-level metrics, with faster inference times than most competitive approaches.
- Qualitative Comparisons: Shows precise spatial arrangement and high-quality texture rendering, outperforming baselines in both controlled and real-world datasets.
Conclusion
SceneGen presents a promising direction for efficient and robust 3D scene generation. By synthesizing asset geometry, texture, and spatial relationships without post-processing, it sets a benchmark for practical 3D modeling applications in virtual/augmented reality and more. Future enhancements could explore broader dataset inclusion and physical constraint integration to further enhance its applicability and coherence.
In summary, SceneGen not only contributes a methodological advancement in 3D asset generation but also provides a scalable solution that bridges gaps in current 3D modeling technologies. It holds potentials for expanding the boundaries of how 3D environments can be efficiently realized for various digital applications.