- The paper introduces a unified, fully automated pipeline that curates fine-grained motion annotations from 46.7K videos with 467K QA pairs, addressing data scarcity in motion reasoning.
- The paper leverages advanced detectors, keypoint models, and GPT-4o-assisted captioning to achieve significant performance boosts, including +14.9% on Robotics benchmarks.
- The paper demonstrates that mid-sized vision-language models trained with precise motion data can outperform larger models on dynamic spatial reasoning tasks.
FoundationMotion: Automated Large-Scale Motion Understanding for Vision-LLMs
Motivation and Context
Understanding object motion and spatial relations is a core requirement for physical reasoning in both artificial and embodied intelligence systems. Although state-of-the-art VLMs, such as Gemini and Qwen-VL, have demonstrated remarkable progress in scene and event understanding, they remain substantially deficient in fine-grained motion reasoning—specifically in recognizing, describing, and reasoning about dynamic behaviors ("how" as opposed to merely "what"). This gap is attributed primarily to the lack of large, high-granularity, and cost-effective motion-labelled video datasets. Manual annotation is prohibitively labor-intensive and cannot scale for VLM training, especially over diverse video domains and for richly structured multi-object scenarios.
FoundationMotion Data Curation Pipeline
The FoundationMotion pipeline introduces a unified, fully automated methodology for curating fine-grained object motion datasets at scale. It integrates state-of-the-art object recognition, segmentation, tracking, and LLM-based data summarization for end-to-end motion annotation in video corpora. The process encompasses four stages: motion-centric temporal segmentation, multi-object detection (including open-vocabulary and custom human-centric models for hands and body parts), long-term tracking (with hierarchical, ID-consistent propagation), GPT-4o-assisted caption generation, and structured QA pair synthesis emphasizing motion dynamics and spatial relationships.
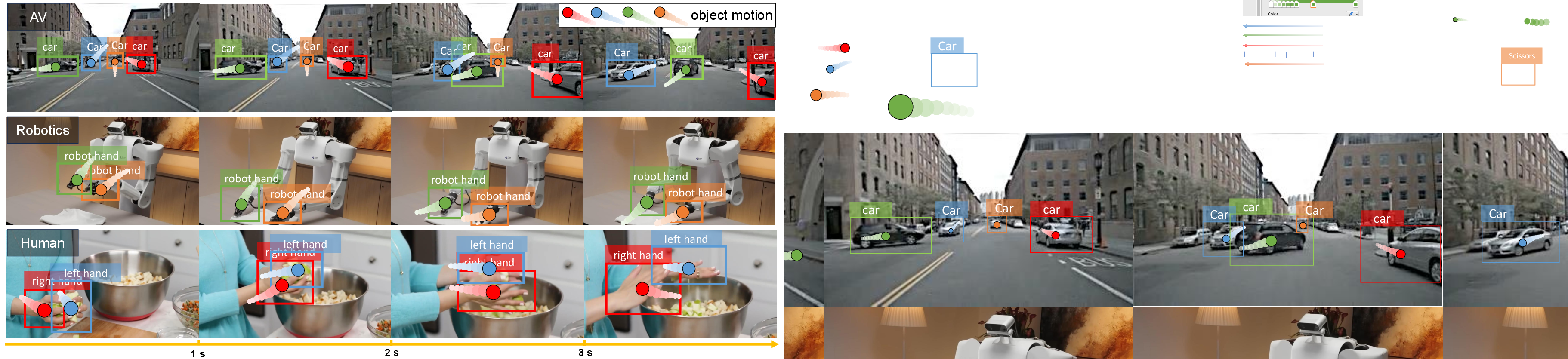
Figure 1: FoundationMotion automatically detects and tracks moving objects, annotating spatial movement in diverse domains including driving, robotics, and daily activities.
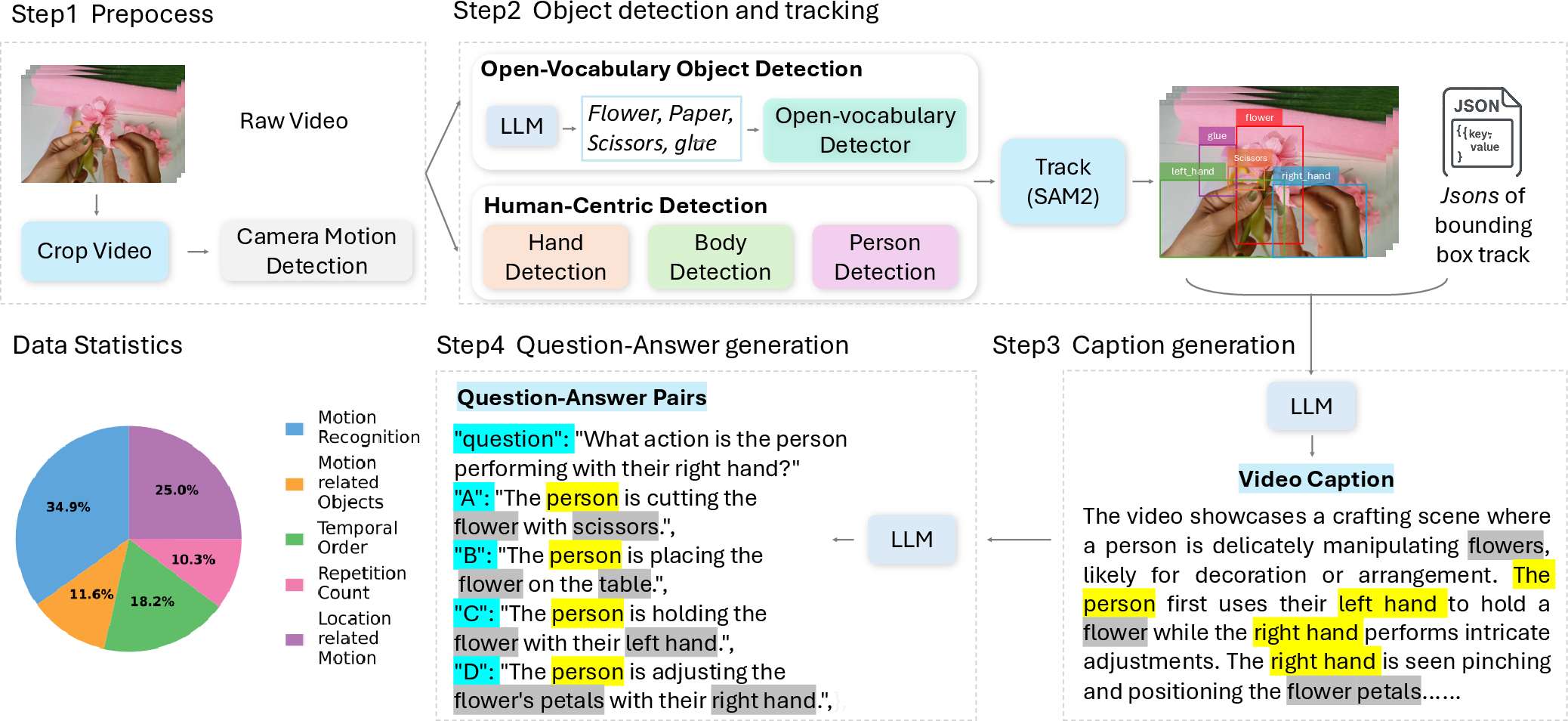
Figure 2: The fully automated FoundationMotion data curation pipeline: cropping, detection, tracking, annotation, captioning, and LLM-based QA generation.
Critical model choices include leveraging open-vocabulary detectors (Qwen2.5-VL and Grounded-DINO) for object scope, advanced keypoint and hand-object interaction models (ViTPose+, Hands23) for nuanced human motion parsing, and SAM2 for robust video-wide temporal tracking. The pipeline further applies stringent filtering for sequences with significant camera motion (using VGGT), maximizing track quality and annotation reliability.
Motion information, encoded as spatial bounding box trajectories per entity over frames, is serialized into JSON, which—jointly with sampled frames—serves as structured input for caption and QA generation via LLM prompting. The prompting covers detailed axes of motion (action/gesture, temporal order, spatial context, agent-action linkage, repetition, trajectory characteristics), yielding granular and temporally coherent motion descriptions and motion-centric QA pairs.
Dataset Composition and Benchmarks
FoundationMotion yields a dataset comprising 46.7K videos with 467K high-quality QA pairs. Videos originate from broad sources (e.g., InternVid) and cover significant variation in domain (autonomous driving, robotics, daily human tasks), action type, and temporal structure, with targeted durations (3–7 seconds).

Figure 3: Representative examples from zero-shot FoundationMotion evaluation benchmarks spanning diverse domains and motion types.
Evaluation is performed on standard benchmarks (MotionBench, VLM4D) for generalization on "what" behaviors and a set of four meticulously annotated "how" motion benchmarks: AV-Car, AV-Hand (autonomous vehicle scenes), Daily (hand-object interactions), and Robotics. These test sets are explicitly out-of-distribution relative to the training set, ensuring rigorous zero-shot assessment.
Empirical Results
Fine-tuning open-source VLMs (NVILA-Video-15B, Qwen2.5-VL-7B) on the FoundationMotion dataset yields significant accuracy improvements in a variety of motion reasoning benchmarks, consistently outperforming baseline pretraining and fine-tuning with alternative datasets such as PLM (PerceptionLM):
- For NVILA-Video-15B, FoundationMotion boosts performance on AV-Car by +7.1% (91.5% vs. 84.4%) and Robotics by +14.9% (36.3% vs. 21.4%).
- For Qwen2.5-VL-7B, all motion benchmarks show positive gains, with +11.7% on Daily and +5.6% on AV-Hand.
- FoundationMotion-trained 7B/15B models surpass the much larger (72B) Qwen2.5-VL and the closed-source Gemini-2.5-Flash on several motion understanding tasks.
- QA generation quality is substantially improved by structured bounding-box trajectory inputs, particularly in fine-grained action accuracy, specificity, and temporal coherence (+2.6 to +2.4 GPT-4o-evaluated score increments).
When analyzing QA categories, "Repetition Count" questions provided the highest individual performance lift (+14.6% over base), and combining different motion-centric question types produced a robust, generalizing accuracy improvement.
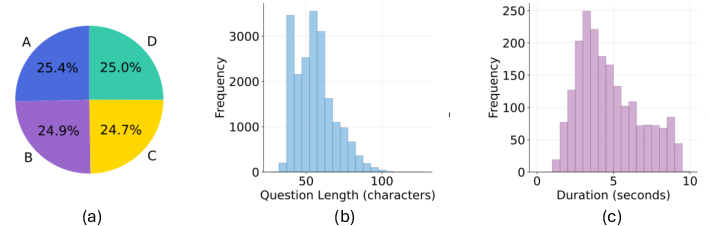
Figure 4: Dataset statistics: balanced answer distributions, concise question lengths, and diversity in video durations across the curated set.
Implications and Theoretical Considerations
FoundationMotion demonstrates that carefully engineered, automated pipelines can yield high-fidelity motion benchmarks at scale, effectively bridging key data deficiencies that impede the development of motion-aware VLMs. The empirical superiority of FoundationMotion-augmented fine-tuning, especially in generalizing to "how" reasoning about motion—across domains and benchmarks—underscores the critical role of annotation granularity, question diversity, and spatial trajectory grounding.
This work further indicates that mid-sized open-source VLMs, when appropriately supervised on structured motion signals, can surpass much larger parametric models which lack such targeted supervision. These findings challenge prevailing assumptions regarding required pretraining scale and suggest a shift towards more specialized, curation-driven regime for advancing multimodal physical reasoning.
Practically, FoundationMotion will be valuable for research and development in domains where low-level motion understanding is essential, including robotics manipulation, autonomous navigation, and human-object interaction modeling. The pipeline's modular structure allows direct integration with future advances in object recognition, tracking, and natural language reasoning.
Limitations and Future Developments
The spatial understanding in FoundationMotion remains fundamentally 2D; full 3D motion decomposition and the tracking of articulated structures (e.g., finger joints in dexterous hand manipulation) are not directly supported. Advancing to true 3D motion annotation, especially for embodied or robotic tasks, is a critical direction for further research. Additionally, while FoundationMotion ensures balanced QA design and removes annotation position bias, further explorations into temporal compositionality and reasoning about long-horizon dependencies remain open.
Conclusion
FoundationMotion establishes an end-to-end automated paradigm for large-scale video motion understanding, yielding immediate empirical benefits for VLM spatial and dynamic reasoning. It demonstrates that dataset curation, quality, and annotation precision are at least as determining for physical reasoning as model scale. FoundationMotion—released with code, benchmarks, and data—sets a strong precedent for future works in scalable, motion-centric multimodal model development.
Reference:
"FoundationMotion: Auto-Labeling and Reasoning about Spatial Movement in Videos" (2512.10927)

