- The paper introduces ViMoGen, a unified diffusion transformer leveraging large-scale heterogeneous data to achieve state-of-the-art generalization in 3D motion generation.
- It systematically integrates optical, in-the-wild, and synthetic data, enhancing semantic coverage and achieving a generalization score of 0.68 on challenging benchmarks.
- The adaptive gating mechanism selects between text-to-motion and motion-to-motion branches, enabling robust instance-level adaptation for complex and rare actions.
Generalizable 3D Human Motion Generation: Data, Model, and Evaluation
Introduction
The paper "The Quest for Generalizable Motion Generation: Data, Model, and Evaluation" (2510.26794) addresses the persistent challenge of generalization in 3D human motion generation (MoGen). While generative models in adjacent domains such as video (ViGen) have demonstrated strong generalization to diverse instructions, MoGen models have lagged, primarily due to data scarcity and limited semantic coverage. This work proposes a comprehensive framework that systematically transfers knowledge from ViGen to MoGen, introducing innovations in three pillars: large-scale heterogeneous data (ViMoGen-228K), a unified diffusion transformer model (ViMoGen and ViMoGen-light), and a fine-grained, human-aligned evaluation benchmark (MBench).
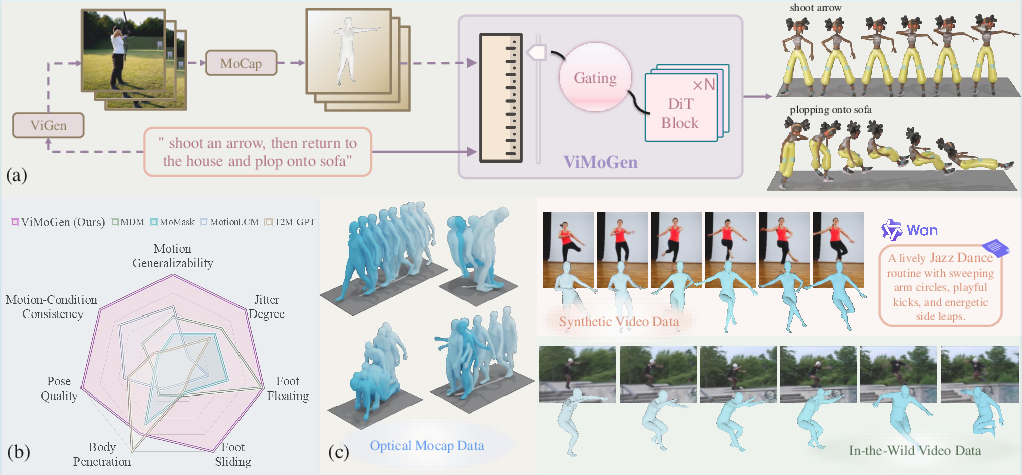
Figure 1: Overview of the approach: (a) ViMoGen model generalizes to complex prompts; (b) MBench enables comprehensive evaluation; (c) ViMoGen-228K dataset covers a wide activity spectrum.
ViMoGen-228K: Large-Scale, Heterogeneous Motion Dataset
A central bottleneck in MoGen is the lack of large, semantically diverse datasets. ViMoGen-228K addresses this by aggregating 228,000 motion sequences from three complementary sources:
- Optical MoCap Data: Aggregation and standardization of 30 public datasets, filtered for quality and semantic consistency, yielding 172k high-fidelity text-motion pairs.
- In-the-Wild Video Data: Extraction of 3D motion from 10M web videos using visual MoCap, with aggressive filtering to retain only ~1% of clips, resulting in 42k high-quality samples.
- Synthetic Video Data: Generation of 14k motion samples from a state-of-the-art ViGen model (Wan2.1), targeting underrepresented or long-tail actions.
The dataset is annotated with structured text descriptions using a multi-modal LLM pipeline, ensuring both breadth and depth in semantic coverage.

Figure 2: Visualization of ViMoGen-228K: (a) Optical MoCap, (b) In-the-Wild Video, (c) Synthetic Video Data.
The ViMoGen model is a flow-matching-based diffusion transformer (DiT) that unifies priors from both MoCap and ViGen models. The architecture is designed to balance motion quality and generalization via a dual-branch, gated fusion mechanism:
- Text-to-Motion (T2M) Branch: Leverages high-fidelity MoCap priors, excelling at actions well-represented in traditional datasets.
- Motion-to-Motion (M2M) Branch: Incorporates video-derived motion tokens, transferring semantic richness from ViGen models to handle novel or rare actions.
An adaptive gating module selects the appropriate branch at inference, based on the semantic alignment between the text prompt and the video-generated motion. This enables instance-level adaptation, dynamically trading off between robustness and generalization.
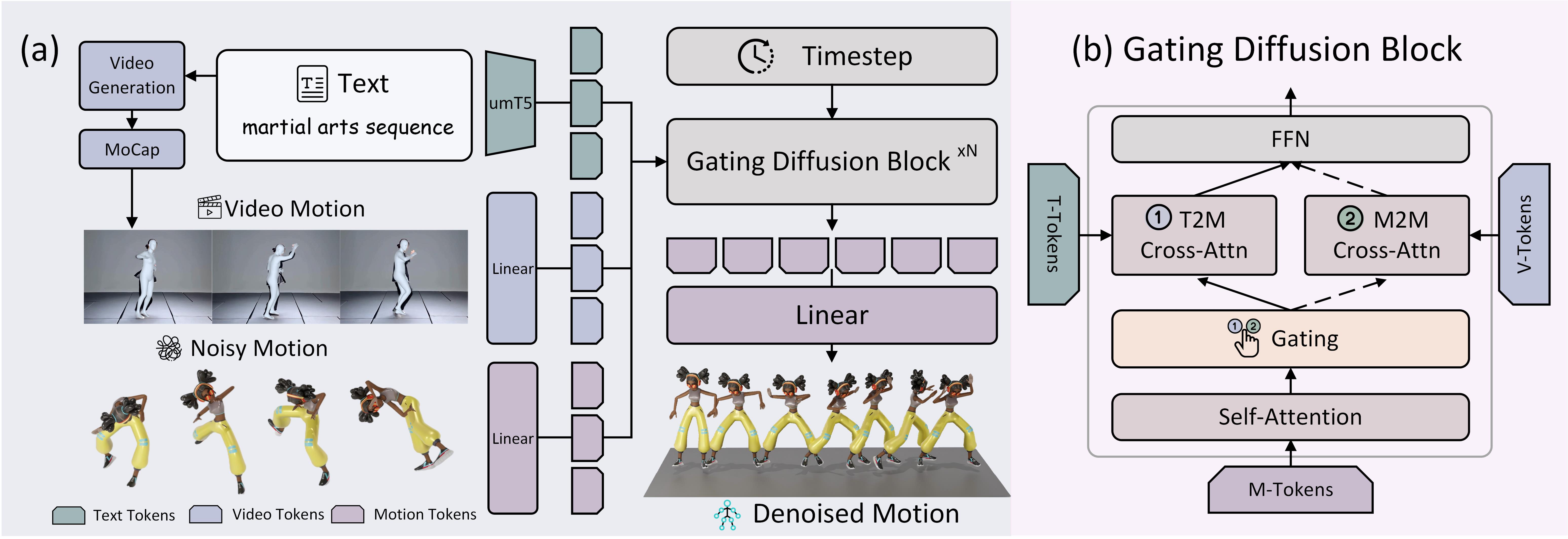
Figure 3: ViMoGen architecture: text and video motion tokens are fused with noisy motion inputs via gated diffusion blocks with adaptive branch selection.
ViMoGen-light, a distilled variant, eliminates the need for video generation at inference by training solely on T2M, using synthetic prompts and knowledge distillation from the full model. This results in a model with strong generalization and significantly reduced computational overhead.
MBench: Hierarchical, Human-Aligned Benchmark
Existing MoGen evaluation protocols are limited by coarse metrics and prompt sets dominated by simple actions. MBench is introduced as a comprehensive, hierarchical benchmark, decomposing evaluation into nine dimensions across three axes:
- Motion Generalizability: Assesses the ability to generate plausible motions for rare or out-of-distribution actions, using an open-world vocabulary and VLM-based semantic evaluation.
- Motion-Condition Consistency: Measures alignment between generated motion and text prompt, using chain-of-thought VLM prompting and distractor-based selection.
- Motion Quality: Evaluates both temporal (jitter, foot contact, dynamics) and frame-wise (body penetration, pose naturalness) aspects, leveraging NRDF and collision detection.
MBench is validated through large-scale human preference studies, demonstrating strong correlation between automatic metrics and human judgments.
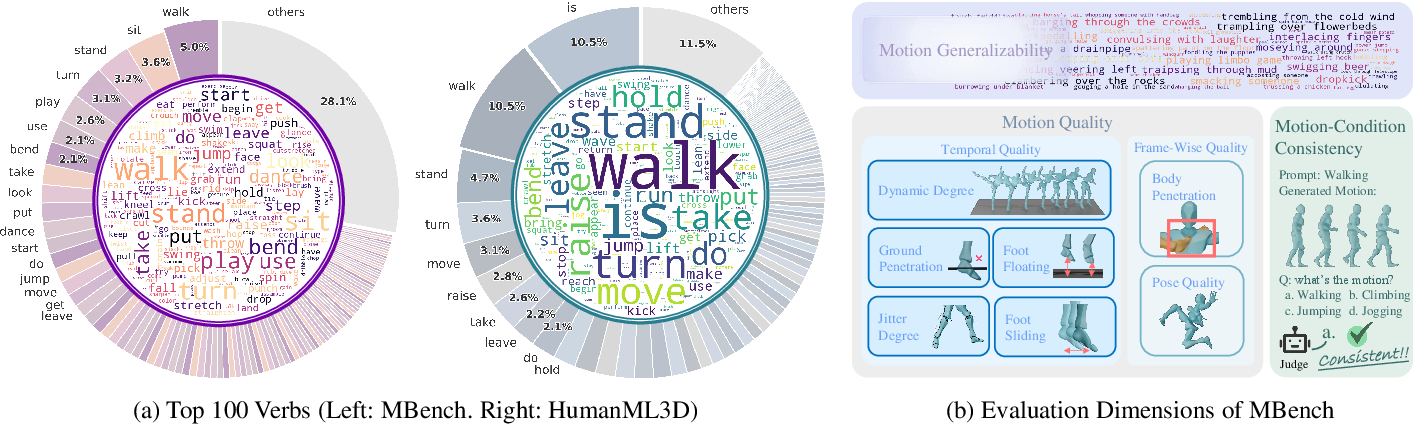
Figure 4: MBench overview: balanced prompt distribution and systematic evaluation across nine dimensions.
Experimental Results and Analysis
ViMoGen and ViMoGen-light are benchmarked against SOTA models (MDM, MotionLCM, T2M-GPT, MoMask) on MBench. ViMoGen achieves the highest scores in both motion-condition consistency and generalizability, with a generalization score of 0.68, substantially outperforming all baselines. ViMoGen-light matches or exceeds the best baseline in generalization, confirming the effectiveness of knowledge distillation.
Qualitative results show that ViMoGen produces plausible, semantically aligned motions for both common and rare prompts, while baselines often fail on out-of-domain instructions.
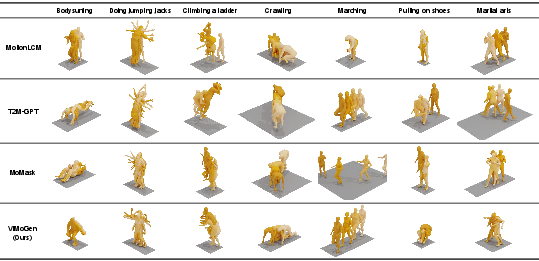
Figure 5: Qualitative comparison on MBench prompts, highlighting ViMoGen's superior semantic alignment and physical plausibility.

Figure 6: On HumanML3D, ViMoGen-light generates more plausible, well-aligned motions for complex, multi-step prompts compared to prior works.
Adaptive Branch Selection
Ablation studies confirm that the adaptive gating mechanism is critical for generalization. The model intelligently selects the M2M branch when video priors are reliable and falls back to T2M for physically challenging or poorly captured actions, yielding the best trade-off between accuracy and motion quality.

Figure 7: Adaptive branch selection: M2M refines plausible video priors; T2M is used when video priors are unreliable.
Data and Text Encoder Ablations
Incremental addition of diverse data sources (optical, in-the-wild, synthetic) leads to monotonic improvements in generalization. Notably, even a small amount of synthetic data provides a significant boost. T5-XXL outperforms CLIP and MLLM as a text encoder, indicating the importance of powerful LLMs for semantic alignment.
Training with descriptive, video-style text and testing on concise motion-style prompts yields the best robustness and generalization.

Figure 8: Training with video-style text improves robustness and generalization across prompt styles.
Additional Qualitative Comparisons
ViMoGen and ViMoGen-light consistently generate motions that adhere more faithfully to detailed text descriptions than prior methods, demonstrating superior semantic understanding and generation quality.
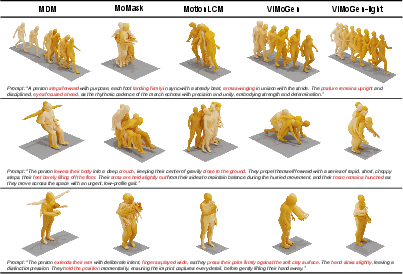
Figure 9: ViMoGen and ViMoGen-light outperform SOTA on MBench prompts in semantic fidelity and motion quality.
Implications and Future Directions
This work demonstrates that systematic transfer of knowledge from ViGen to MoGen, via large-scale heterogeneous data, unified diffusion transformer architectures, and human-aligned evaluation, can substantially advance the generalization capabilities of motion generation models. The adaptive gating mechanism and the use of synthetic data for semantic coverage are particularly effective.
Practically, these advances enable MoGen models to handle a broader range of instructions, including long-tail and compositional behaviors, which is critical for downstream applications in animation, robotics, and embodied AI. The release of ViMoGen-228K and MBench provides valuable resources for the community.
Theoretically, the results suggest that cross-modal knowledge transfer and adaptive multimodal fusion are promising directions for building general-purpose motion foundation models. Future work may explore scaling data and model size further, integrating richer environmental and interaction contexts, and extending to multi-agent or object-centric motion generation.
Conclusion
The paper establishes a new paradigm for generalizable 3D human motion generation by unifying data, model, and evaluation innovations. ViMoGen-228K provides unprecedented scale and diversity; ViMoGen and ViMoGen-light achieve state-of-the-art generalization and semantic alignment; and MBench sets a new standard for fine-grained, human-aligned evaluation. These contributions collectively advance the field toward robust, open-world motion generation and lay the groundwork for future research in motion foundation models.