- The paper proposes PACIFIC, a framework that deterministically generates contamination-resistant benchmarks to evaluate LLMs' compositional instruction following in code.
- It employs a modular design with controllable instruction counts and output lengths to stress-test stepwise reasoning and strict format adherence.
- Experimental results reveal significant accuracy degradation on complex benchmarks, highlighting gaps in current multi-step dry-run and reasoning capabilities.
PACIFIC: A Deterministic, Contamination-Resistant Benchmark Generation Framework for Code Instruction-Following Evaluation
Motivation and Core Design Principles
PACIFIC addresses fundamental deficiencies of existing benchmarks for evaluating LLM instruction-following in code: reliance on LLM-based evaluators, lack of deterministic evaluation, weak control over benchmark difficulty, and contamination risk. The framework is designed with four guiding principles: simple and deterministic evaluation, difficulty control, scalability and contamination resistance, and modular extensibility. All benchmarks are generated automatically, evaluated via straightforward output comparison against expected results, and can be scaled or adapted with new instructions, programming languages, or presentation formats.
PACIFIC does not require execution engines, external tools, or LLM-based judges. The evaluation focuses on the LLM's intrinsic capability to dry-run code and precisely follow sequenced instructions, providing a transparent methodology for isolating core reasoning skills from tool-augmented performance.
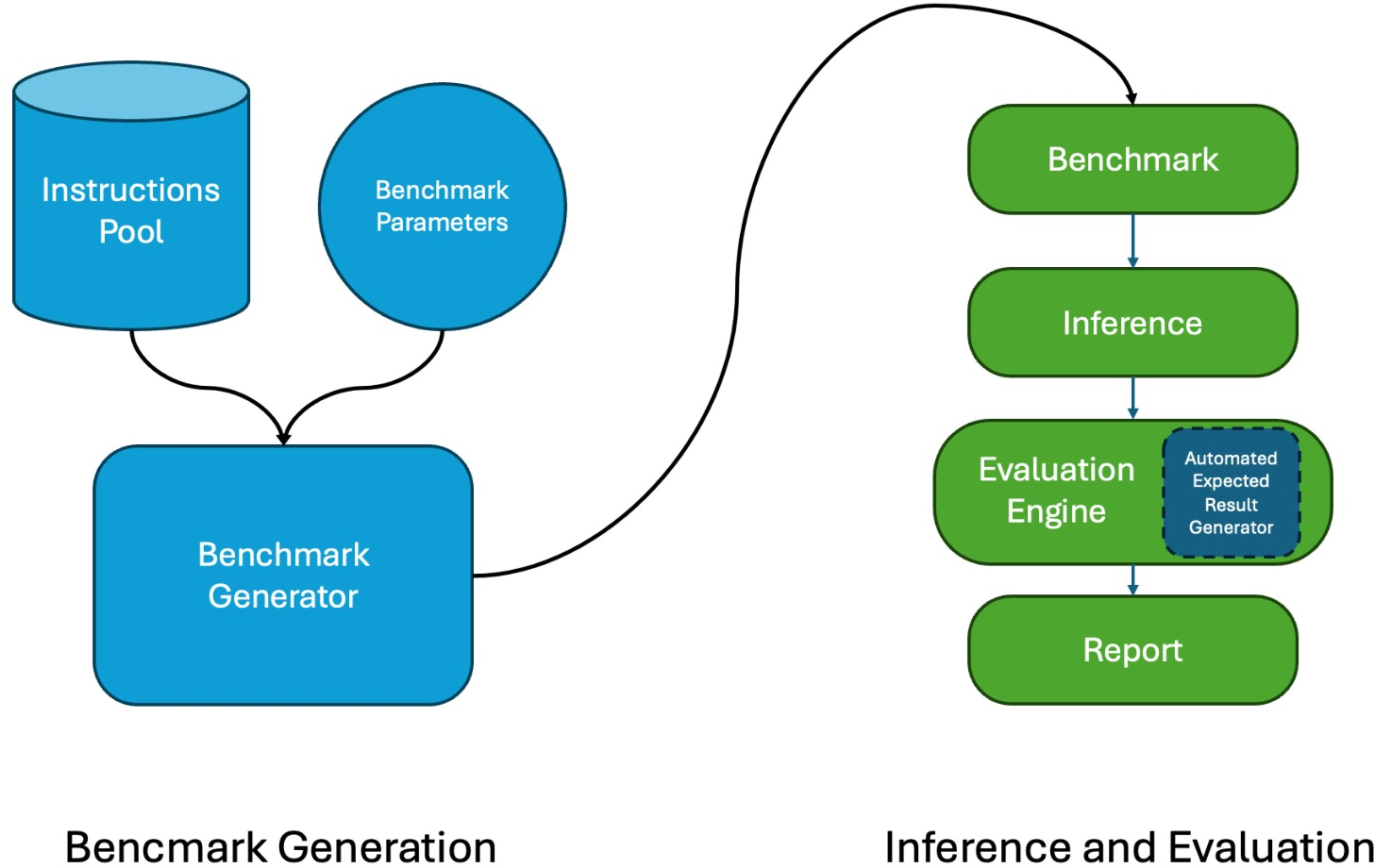
Figure 1: High-level architecture of PACIFIC, depicting end-to-end automated and deterministic evaluation pipeline from instruction pool and parameterized benchmark generation through to metric extraction.
Benchmark and Task Construction
The atomic element of a PACIFIC benchmark is a sample, which consists of an initial input (number or string) and a sequence of code instructions drawn from an extensible pool. Instructions are concatenated to form a compositional reasoning chain: each receives as input the previous instruction’s output, supporting four possible type transitions (number to number, number to string, string to string, string to number). Each instruction is formally defined, implemented, and validated in Python, Java, and C++, and expressed both as code and natural language.
To illustrate:
- "next_perfect_square": Output the first perfect square greater than the input.
- "shift_back": Subtract 1 from each character in the previous output, with wrap-around as in a Caesar cipher.
- "abs_digit_name": Replace each digit of the absolute value of the previous number with an alphabetic name code, producing a string.
Samples may be presented as a single prompt (Prompt mode) or as a multi-turn dialogue (Chat mode). PACIFIC handles type consistency and output length constraints during sample construction, dynamically selecting instruction sequences to match the desired difficulty.
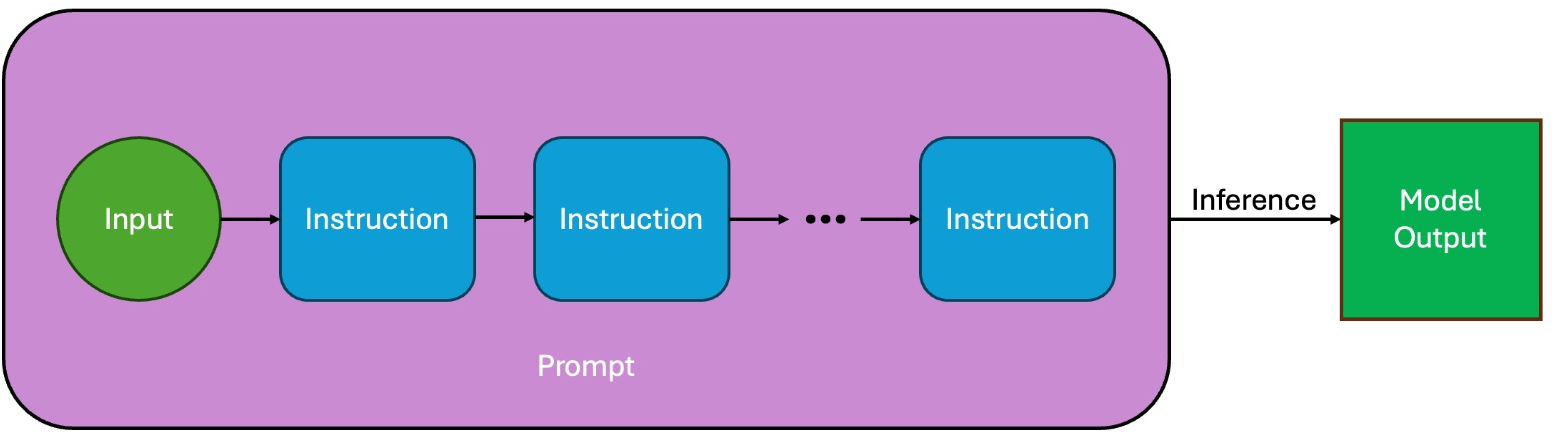
Figure 2: Structure of a benchmark sample—initial input and sequence of instructions forming a prompt for stepwise model processing.
Difficulty control is achieved through two orthogonal parameters:
- Instruction count: As the chain length increases, error propagation and compositional reasoning demand escalate.
- Target output length: Longer final outputs demand persistence of transformation consistency and increase format management complexity.
This two-dimensional parameterization allows systematic stress-testing of LLMs across the regime from trivial to extremely challenging compositional tasks, while modular design supports rapid expansion of instruction pools and supported languages.
Deterministic and Modular Evaluation Pipeline
Evaluation is rule-based and fully deterministic. For each instruction, the framework parses model outputs (using a strict tag-based format) and compares with reference outputs produced by executing the canonical code implementation. Prompt-Level Accuracy (PLA) measures the percentage of samples where all instructions are followed correctly; Instruction-Level Accuracy (ILA) reflects aggregate per-instruction correctness.
The framework categorizes errors into missing answers, type mismatches, and other format deviations. This structure reduces the evaluation cost to a minimum and employs no learned model in the evaluation loop, increasing transparency and reproducibility.
PACIFIC's contamination resistance is enabled via parameterized sample generation, representation diversity (code versus NL instructions, prompt versus chat, multiple programming languages), and random seed control. Thus, variants can be generated rapidly for new, uncontaminated evaluations whenever prior instance leakage is detected or suspected.
Empirical Evaluation and Findings
Difficulty Calibration and Model Degradation
A large-scale experiment includes 15 benchmarks over 5 instruction counts and 3 output lengths, with 99 samples per benchmark, in Python, Java, and C++. Evaluation of Claude-3.5-Haiku, Claude-4-Sonnet, GPT-OSS-120B, Llama-4-Maverick-17B-128E-Instruct, Qwen3-235B-A22B-Instruct, and Qwen3-Coder-480B-A35B-Instruct exposes pronounced accuracy degradation as task difficulty increases.
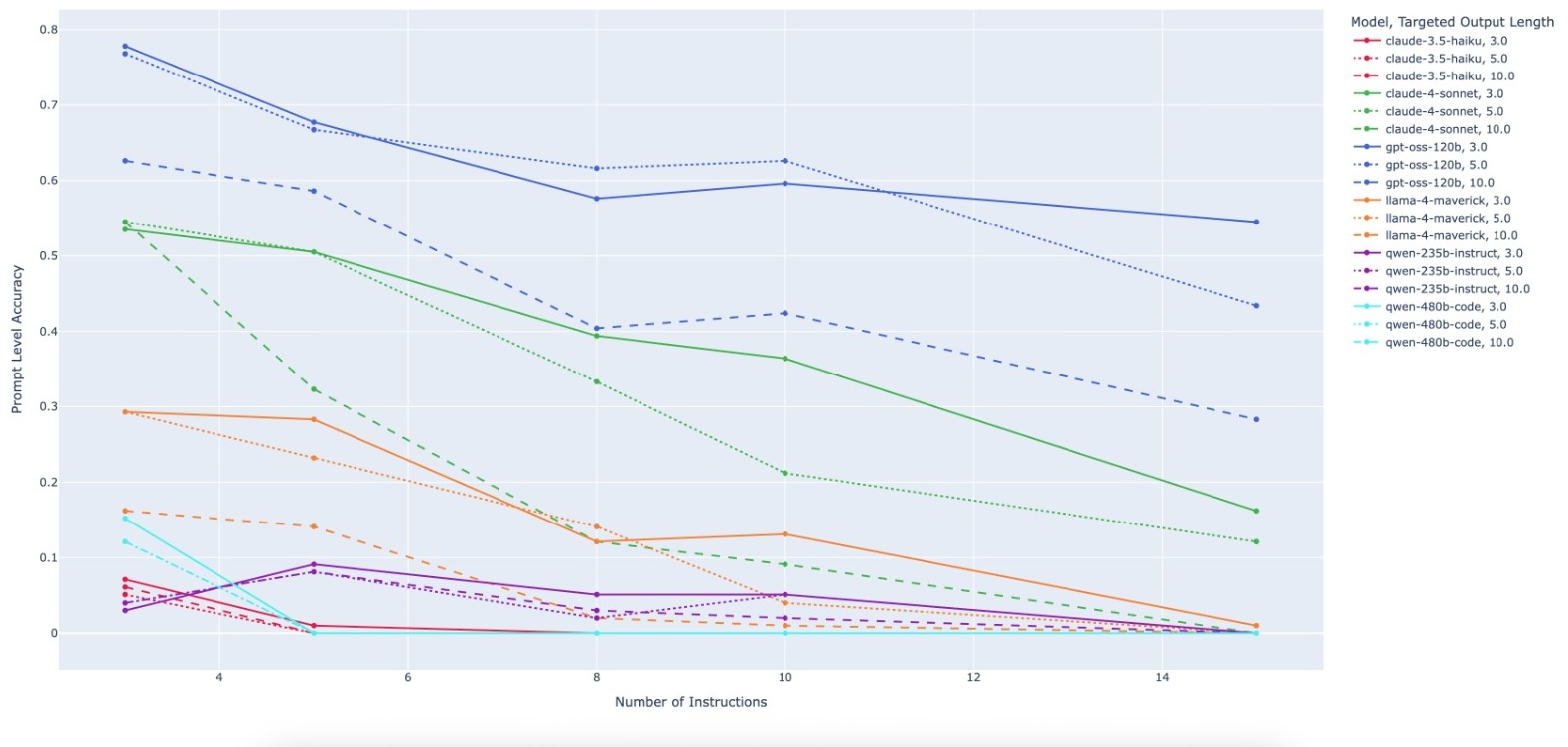
Figure 3: Prompt-Level Accuracy for all models across benchmark complexity parameters. Accuracy declines as instruction count and output length increase.
The loss in compositional instruction adherence is nonlinear, with many models dropping to 0% on the most challenging benchmarks. For example, on the hardest configuration, only one model attained 28% PLA, and the majority reached 0%. This characteristic distinguishes PACIFIC results from general instruction-following and code generation leaderboards, indicating alignment with a distinct reasoning capability.
Model Comparison
Aggregate model performance shows a clear stratification, yet collapses for all models at high difficulty. Notably, top performers in coding and traditional instruction-following (such as Qwen3-235B-A22B-Instruct) routinely underperform in PACIFIC, while gpt-oss-120b leads PACIFIC but lags on other leaderboards. This non-monotonic ranking highlights PACIFIC’s focus on compositional, step-level logical reasoning, rather than rote code generation or isolated instruction adherence.
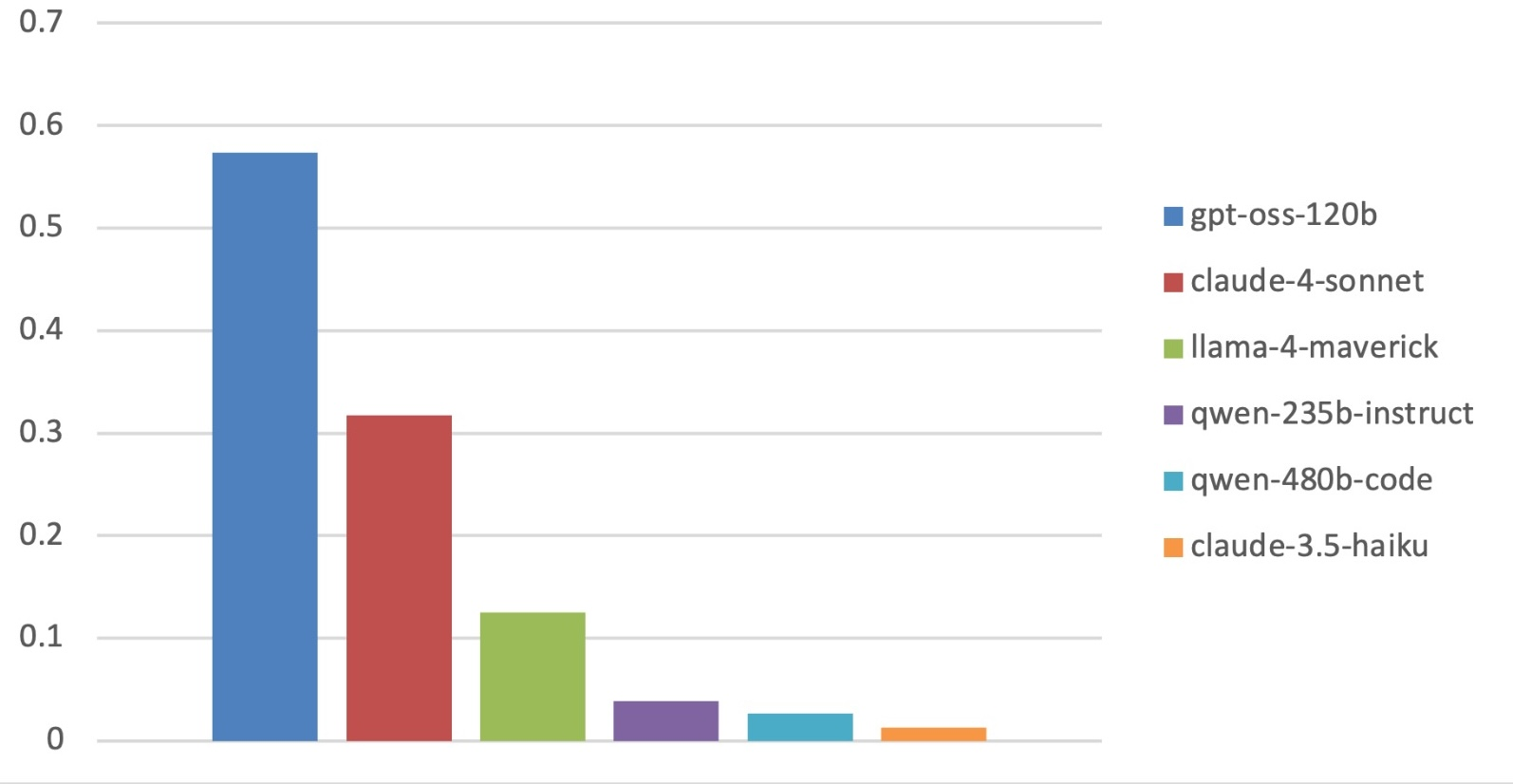
Figure 4: Aggregate mean Prompt-Level Accuracy illustrating model stratification and overall low success rates on hard benchmarks.
Complementary error analysis shows that error rates, especially missing answers and format violations, increase rapidly with instruction count, yet output length exerts lesser influence on format errors. Models vary widely in their robustness to strict output formatting requirements.
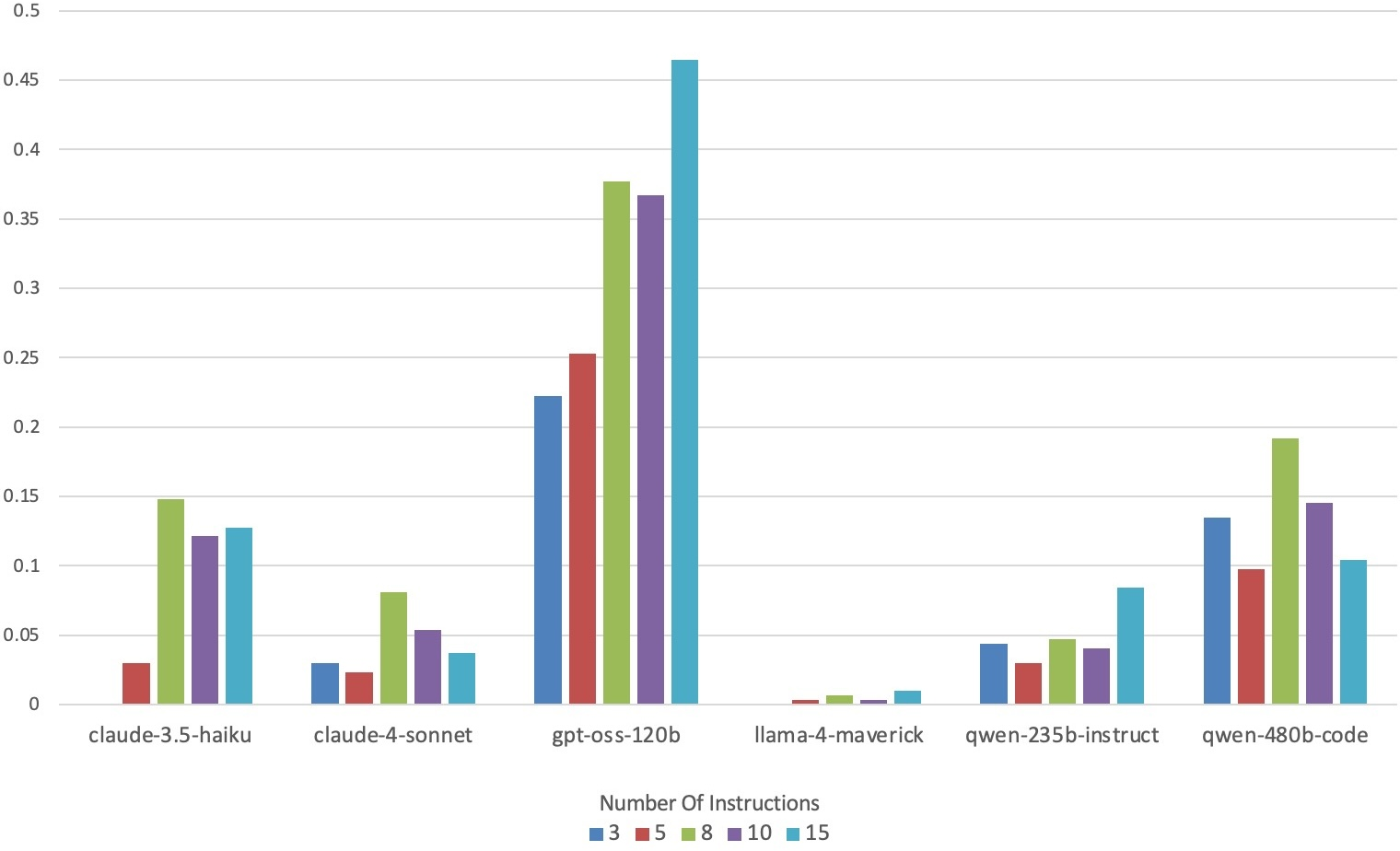
Figure 5: Missing answer rates by instruction count, highlighting format and generation fragility with increased compositional load.
Instruction-Level Analysis
Analysis of individual instruction accuracy reveals that simple atomic instructions (e.g., "to_roman", "next_perfect_square") typically exceed 85% accuracy, possibly due to memorization effects. However, "abs_digit_name", "shift_back", and "replace_vowels_with_gh", although computationally trivial for humans, are challenging for LLMs, especially when composed. Even high instruction-level accuracy on isolated tasks fails to yield robust chain execution in complex benchmarks.
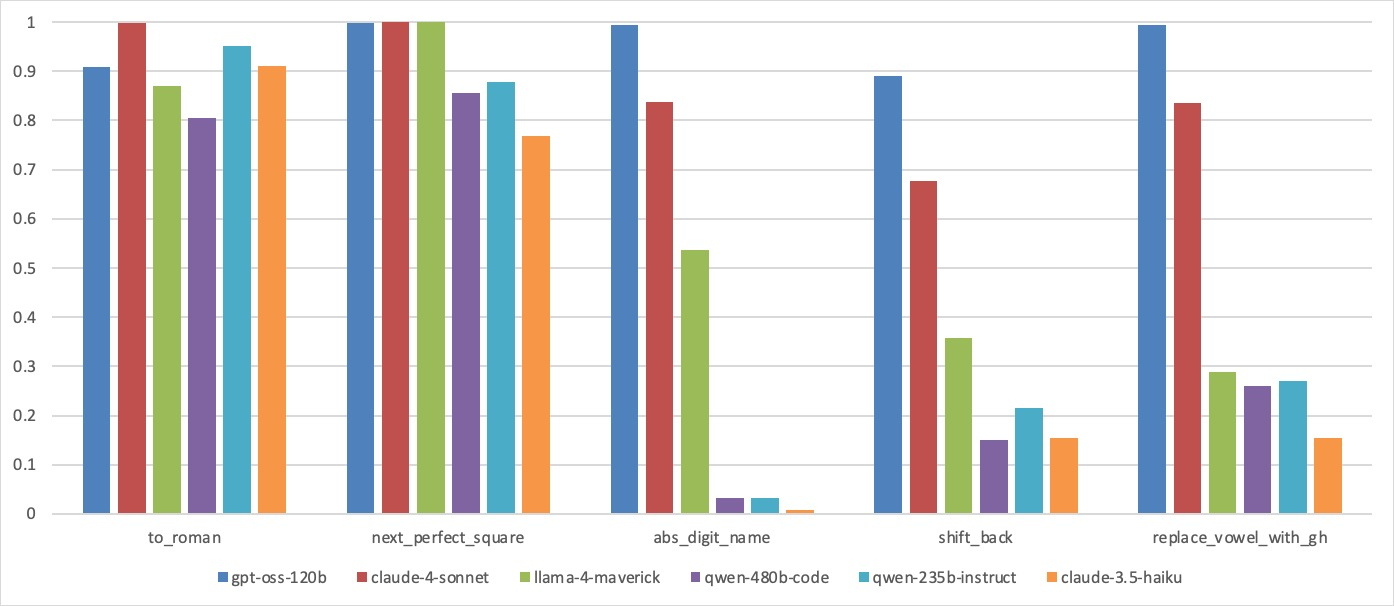
Figure 6: Instruction-level accuracy for representative “easy” and “hard” instructions, showing a contrast in atomic versus compositional performance.
Practical and Theoretical Implications
PACIFIC introduces a new standard for deterministic, contamination-resilient, difficulty-controllable evaluation of LLMs' instruction-following and code reasoning. The empirical finding that state-of-the-art LLMs degrade to near-zero performance on complex, but formal and deterministic, chains underscores a major gap in compositional skill acquisition in current architectures. This gap is masked by conventional code-generation and instruction-following tasks, which rarely impose stringent compositional structure or embargo agentic tool use.
By isolating dry-running (mental simulation of code) and stepwise instruction-following, PACIFIC offers a direct probe into the reasoning stack of LLMs without the confounders of black-box execution, LLM-based evaluation, or tool-augmented environments. The framework is robust against contamination and bias, extensible for new task classes and languages, and thus readily applicable to benchmark future foundation models as well as LLM-based agents with increasingly sophisticated compositional abilities.
The results suggest several research directions:
- Advancements in compositional generalization—architectural and training interventions are necessary to address multi-step instruction-following skill deficiency.
- Integration of PACIFIC into continual evaluation or red-teaming will improve traceability and transparency in model deployment for code assistant applications.
- Analysis of systematic error modes in compositional tasks may illuminate factors contributing to error propagation and formatting brittleness.
- Extension to additional data types, domains, and reasoning modalities will further assess the universality and limits of current LLMs’ dry-running capacities.
Conclusion
PACIFIC advances the methodology for evaluating LLMs’ core instruction-following and code simulation competencies via principled, deterministic benchmarks. It provides strong difficulty control, intrinsic contamination resistance, and modular extensibility, enabling rigorous isolation of compositional failures in contemporary models. Experimental results demonstrate a severe and persistent gap in dry-running and multi-step instruction adherence, motivating future algorithmic and architectural innovations. PACIFIC will serve as a critical evaluation resource for the development of robust, transparent, and trustworthy LLM-based software engineering assistants.
Reference:
PACIFIC: a framework for generating benchmarks to check Precise Automatically Checked Instruction Following In Code (2512.10713)