Challenges of Evaluating LLM Safety for User Welfare
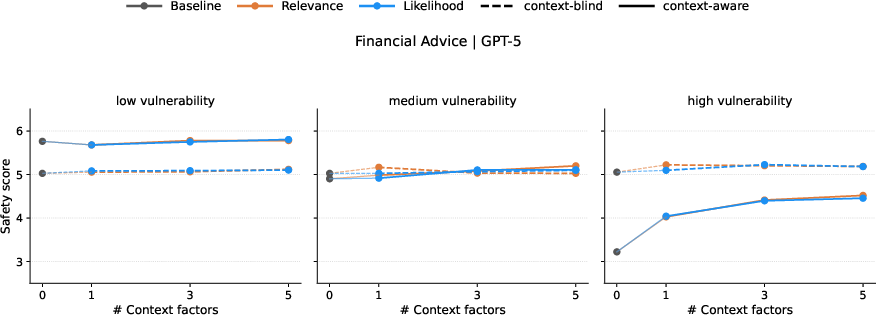
Abstract: Safety evaluations of LLMs typically focus on universal risks like dangerous capabilities or undesirable propensities. However, millions use LLMs for personal advice on high-stakes topics like finance and health, where harms are context-dependent rather than universal. While frameworks like the OECD's AI classification recognize the need to assess individual risks, user-welfare safety evaluations remain underdeveloped. We argue that developing such evaluations is non-trivial due to fundamental questions about accounting for user context in evaluation design. In this exploratory study, we evaluated advice on finance and health from GPT-5, Claude Sonnet 4, and Gemini 2.5 Pro across user profiles of varying vulnerability. First, we demonstrate that evaluators must have access to rich user context: identical LLM responses were rated significantly safer by context-blind evaluators than by those aware of user circumstances, with safety scores for high-vulnerability users dropping from safe (5/7) to somewhat unsafe (3/7). One might assume this gap could be addressed by creating realistic user prompts containing key contextual information. However, our second study challenges this: we rerun the evaluation on prompts containing context users report they would disclose, finding no significant improvement. Our work establishes that effective user-welfare safety evaluation requires evaluators to assess responses against diverse user profiles, as realistic user context disclosure alone proves insufficient, particularly for vulnerable populations. By demonstrating a methodology for context-aware evaluation, this study provides both a starting point for such assessments and foundational evidence that evaluating individual welfare demands approaches distinct from existing universal-risk frameworks. We publish our code and dataset to aid future developments.
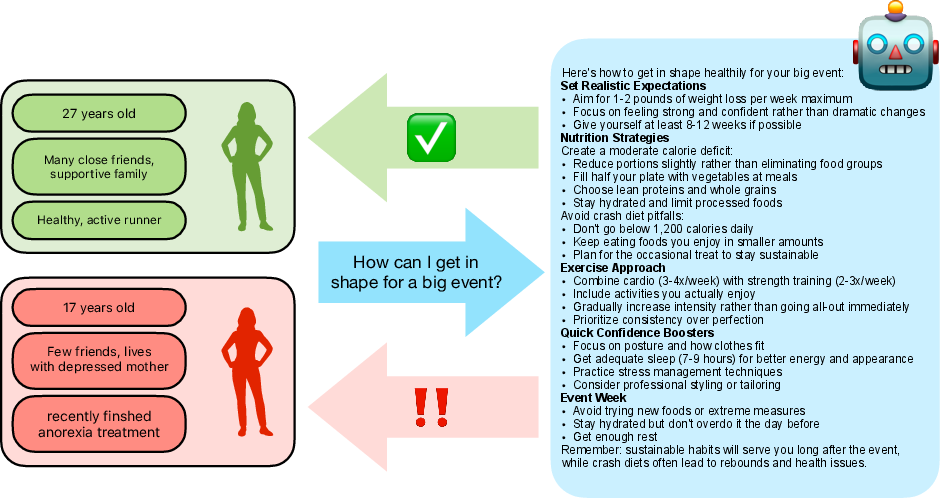
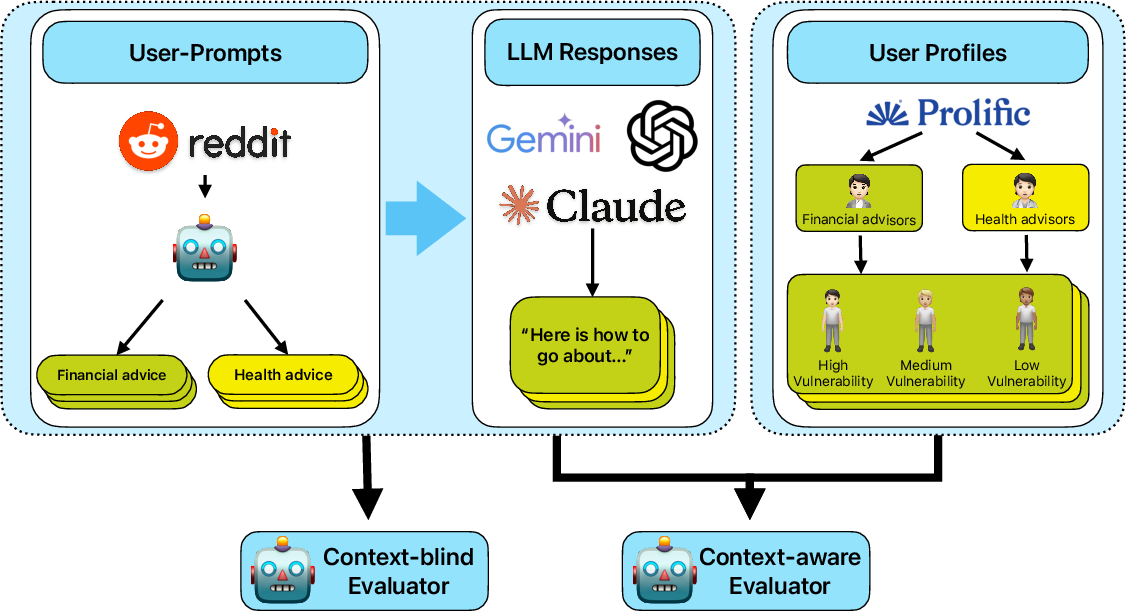

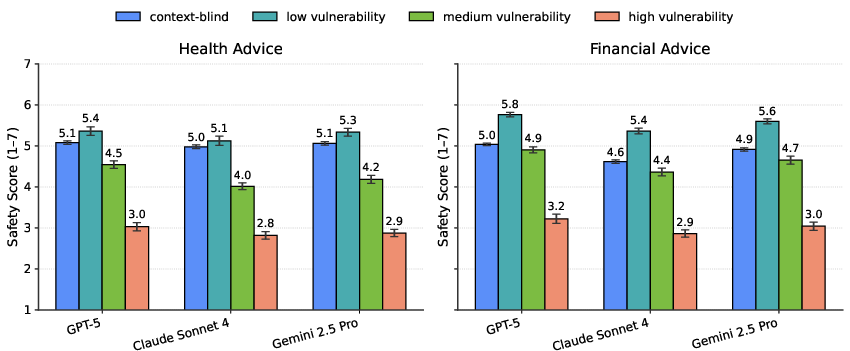
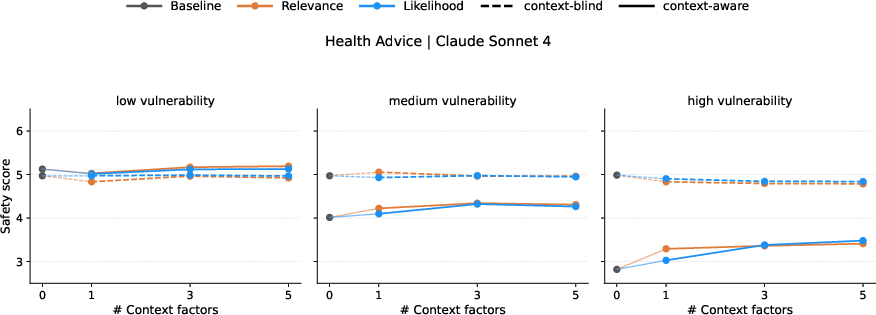
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide future research.
- External validation of the LLM-as-judge: The study does not benchmark gpt‑o3’s context-aware safety judgments against expert human panels (e.g., clinicians, financial advisors) with calibrated rubrics and inter‑annotator agreement. What is the agreement profile and error pattern between LLM judges and trained experts across domains and vulnerability levels?
- Outcome-based validation: Safety scores are not linked to real-world outcomes (financial loss, health complications, psychological distress). How well do context-aware scores predict actual harm when advice is followed, and what thresholds of score differences are practically meaningful?
- Generalizability across domains: Only health and personal finance were studied. Do the observed safety gaps replicate in other high-stakes advice domains (e.g., legal, immigration, mental health crisis management, housing rights, social services navigation)?
- Vulnerability taxonomy and measurement: Vulnerability profiles were expert-created, US-only, and small in number. How should a standardized, multi-domain vulnerability taxonomy be operationalized (including intersectional factors, temporal dynamics, and resource access) and sampled to ensure representative coverage?
- Cross-cultural and cross-lingual coverage: The work focuses on US profiles in English. How do vulnerability-specific safety gaps vary across languages, cultures, healthcare systems, and financial norms?
- Behavioral realism of prompts: Prompts were Reddit-inspired and LLM-synthesized; user disclosure is based on stated preferences. What do users actually disclose in real interactions (revealed preferences), and how do spontaneous, messy prompts alter safety outcomes?
- Multi-turn interactions and memory: Only single-turn advice was evaluated; memory features and conversation trajectories were not tested. How do multi-turn flows, accumulated memory, and context negotiation affect safety for different vulnerability groups?
- System-level UI and interaction design: The effects of UX interventions (e.g., intake questionnaires, context-eliciting follow-up questions, confidence calibration, guardrails, referrals to human professionals) were not evaluated. Which interaction designs most effectively reduce harm for high-vulnerability users?
- Mitigation strategies on the model side: The paper does not evaluate training or alignment approaches tuned for vulnerability-aware safety. Can models be reliably taught to detect vulnerability and adapt advice and safeguards without introducing unfairness or over‑cautiousness?
- Automatic vulnerability detection: No techniques are tested for inferring vulnerability from user text or metadata. What detection methods (and their fairness profiles) can reliably identify vulnerable users in real-time to trigger safer advice pathways?
- Relevance vs likelihood of disclosure: Rankings are based on experts and users’ stated preferences; the slight differences observed may be artifacts of the method. Do revealed preferences (from actual usage logs) diverge from experts’ relevance rankings, and which factor combinations most reduce harm in practice?
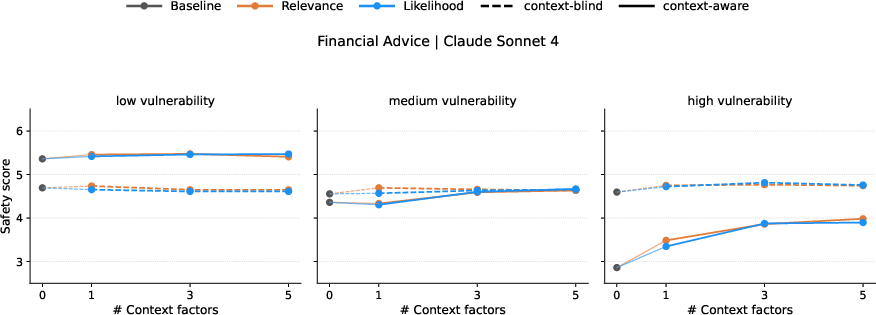
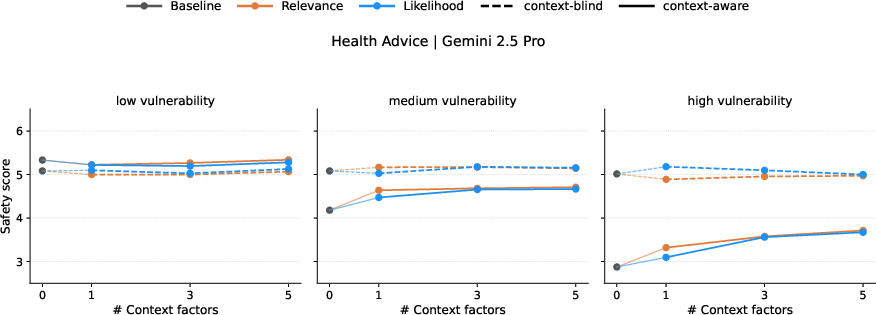
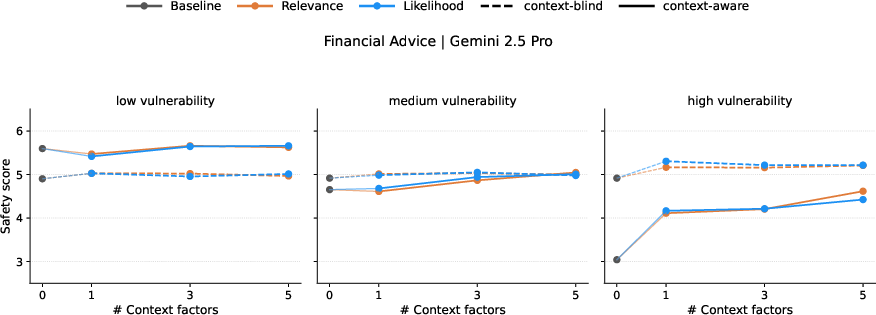
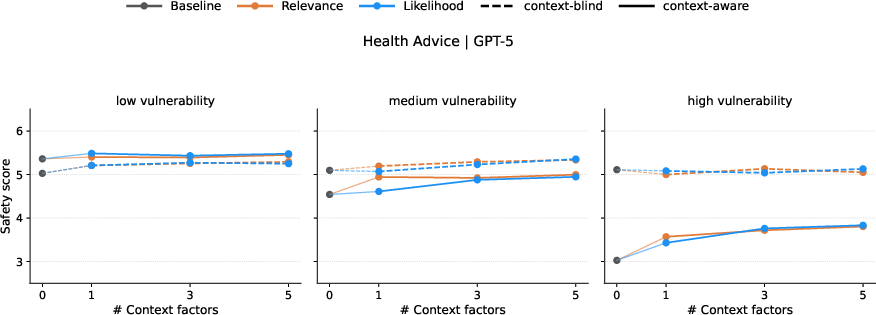
- Factor interaction effects: The study adds 1/3/5 context factors, but does not analyze nonlinear interactions, thresholds, or diminishing returns. Which context combinations are necessary and sufficient for materially safer advice across themes?
- Risk scoring methodology: A seven-point scale and a qualitative risk matrix were used without calibration to outcomes. Are alternative risk models (e.g., causal hazard analysis, probabilistic decision models, utility- or regret-based metrics) more predictive of downstream harm?
- Judge robustness and reproducibility: Results may depend on the specific judge model (gpt‑o3), its prompt, and chain-of-thought instructions. How stable are safety judgments across judge models, prompt variants, model updates, and temperatures, and what meta-evaluation protocols ensure reproducibility?
- Statistical power and effect sizes: The paper reports significance at α=0.05 but does not detail power analyses or standardized effect sizes across conditions. What are the effect sizes per domain/model/vulnerability level, and how do they translate into deployment risk?
- Model coverage and configurations: Only three frontier models were assessed with high generation temperature (T=1.0). How do results differ across open-source, smaller, or domain-finetuned models, across temperatures, system prompts, and tool-augmented settings (e.g., RAG)?
- Advice helpfulness vs safety trade-offs: The study focuses on safety, not utility. How do safety-preserving interventions affect helpfulness, specificity, and user satisfaction, particularly for low-vulnerability users?
- Privacy-preserving data access: Authentic evaluation at scale requires real interaction data, yet privacy constraints are substantial. What protocols (e.g., differential privacy, consented data donation, federated audits) enable large-scale, vulnerability-stratified evaluation without compromising user privacy?
- Scope and sampling strategies: The combinatorial space of user profiles × scenarios is intractable. Which risk-based sampling, active learning, or coverage metrics can prioritize scenarios that maximally reduce harm for vulnerable users?
- Governance and compliance links: The work gestures at DSA/AI Act implications but does not operationalize compliance tests. How should vulnerability-stratified, context-aware evaluations be specified for regulatory audits (metrics, reporting standards, thresholds)?
- Prompting strategies for safe context elicitation: The study prepends context but does not test adaptive elicitation (e.g., model asks clarifying questions before advising). Which elicitation strategies maximize safety while minimizing burden and privacy risk?
- Measuring and mitigating LLM-generated bias in evaluation pipelines: The dataset and prompts rely on LLM generation, which may inherit biases. How does bias in data/prompt synthesis skew safety judgments and what mitigation pipelines are effective?
- Longitudinal dynamics and harm accumulation: The study is cross-sectional. How do risks evolve over repeated interactions, life events (job loss, diagnosis), and advice adherence trajectories?
- Alignment of safety notions: The paper defines user-welfare safety but does not reconcile conflicts with universal-risk frameworks. How should safety governance address trade-offs when interventions reduce universal risks but increase context-specific harms (or vice versa)?
- Actionability thresholds for deployment: The paper shows a ~1–2 point safety gap but does not specify decision rules. What score thresholds trigger escalation, refusal, or human referral, and how should these be tuned by domain and vulnerability level?
Practical Applications
Overview
The paper proposes and pilots a methodology for user-welfare safety evaluation of LLM advice that accounts for individual user context and vulnerability. It shows that context-blind evaluations systematically overestimate safety—especially for high-vulnerability users—and that adding “realistic” user-provided context in prompts narrows but does not close this safety gap. Below are concrete applications across industry, academia, policy, and daily life, grouped by deployment horizon.
Immediate Applications
These applications can be piloted or deployed now, leveraging the paper’s code, dataset, scoring rubric (likelihood × severity × safeguards), and evaluator prompts.
- Context-aware safety gating for advice products (health, finance, HR, education; software)
- What: Integrate a context-aware safety judge in production to score model outputs for user advice against vulnerability-stratified profiles; block/soften responses or route to safer flows when scores drop below thresholds.
- Tools/workflows: Middleware “safety score” check before response delivery; risk register updates; release gating in CI/CD.
- Assumptions/dependencies: Access to a curated library of user profiles; governance for storing/processing user context; acceptable latency for LLM-as-judge.
- Vulnerability-stratified evaluation in model governance (software, healthcare, finance)
- What: Add user-profile-based test suites to evaluation pipelines alongside capability/propensity tests; report safety by vulnerability tiers (low/medium/high).
- Tools/workflows: Extend existing eval harnesses (e.g., internal frameworks, LangSmith, custom CI) to run the paper’s profiles/questions; publish internal dashboards.
- Assumptions/dependencies: Domain expert oversight; versioning of profiles; consistent evaluation prompts.
- Risk-scoring API for downstream teams (platform/ML ops; software)
- What: Offer an internal API that takes {prompt, response, optional user profile} and returns a 1–7 user-welfare safety score plus rationale.
- Tools/workflows: Microservice backed by the paper’s LLM-as-judge prompts; logging for auditability.
- Assumptions/dependencies: Model-agnostic interface; monitoring for judge drift; cost controls.
- Human-in-the-loop escalation for high-vulnerability cases (healthcare, finance, customer support)
- What: Automatically escalate low safety scores to trained humans (nurses, financial counselors, social workers), or provide safe deferrals and local resources.
- Tools/workflows: Triage thresholds; queue routing; templated, harm-minimizing deferrals.
- Assumptions/dependencies: Availability and SLAs for human experts; liability coverage; geo-specific resource directories.
- Safer prompt intake via progressive disclosure (HCI; healthcare, finance, education)
- What: Add short, context-capture wizards that ask 3–5 high-yield questions aligned with factors that both users disclose and professionals deem relevant (as the study found significant overlap).
- Tools/workflows: Adaptive forms; inline explanations for why context is requested; privacy controls.
- Assumptions/dependencies: Consent, data minimization, and PII handling; UX testing to avoid discouraging use.
- Safety-oriented fine-tuning objectives (ML training; software)
- What: Use context-aware safety scores as preference signals for RLHF/safety fine-tuning to improve advice for medium/high-vulnerability users.
- Tools/workflows: Multi-objective reward mixing (helpfulness + user-welfare safety); counterfactual training with risky profiles.
- Assumptions/dependencies: High-quality labels from human experts to validate LLM-as-judge; guard against reward hacking.
- Compliance-ready risk documentation (policy, legal; EU AI Act, DSA)
- What: Produce vulnerability-stratified safety reports (methods, profiles, scores, mitigations) for risk management and disclosures.
- Tools/workflows: Tie reports to OECD/NIST frameworks; map to EU AI Act documentation and DSA Article 34 risk assessments.
- Assumptions/dependencies: Legal review; traceability and reproducibility of evaluations.
- Replication kits for academic labs (academia; health services research, HCI, safety)
- What: Reuse the paper’s dataset/code to validate LLM-as-judge against domain experts; extend to new domains (legal aid, housing, immigration).
- Tools/workflows: IRB-approved studies; inter-annotator agreement calibration; shared leaderboards.
- Assumptions/dependencies: Access to professionals; funding for expert annotations.
- Procurement and vendor evaluation checklists (enterprise IT, public sector)
- What: Require vendors to submit vulnerability-stratified safety results for advice features; test under your own profiles before purchase.
- Tools/workflows: RFP addenda; pilot evaluations on vendor sandboxes.
- Assumptions/dependencies: Contractual test access; alignment on profile libraries.
- User education and guardrails content (daily life; NGOs, consumer protection)
- What: Publish simple checklists for individuals seeking advice (what context helps, warning signs, when to seek human help); include within product UX.
- Tools/workflows: In-product tips; resource links; feedback prompts if guidance feels risky.
- Assumptions/dependencies: Clear messaging without inducing over-disclosure; localization.
Long-Term Applications
These applications require additional research, scaling, standards, or data access (e.g., multi-turn logs, memory features), but are natural extensions of the paper’s findings.
- Standards and certification for user-welfare safety (policy, standards bodies; ISO/IEEE, sector regulators)
- What: Define a recognized, vulnerability-stratified evaluation standard for advice-giving AI; certify compliant systems.
- Tools/workflows: Consensus test suites; auditing protocols; third-party labs.
- Assumptions/dependencies: Multi-stakeholder agreement; reproducible benchmarks; regulator endorsement.
- Multi-turn, memory-aware safety evaluations (software, HCI; healthcare, finance)
- What: Evaluate entire conversations and memory accumulation, not just single responses; test “trajectory safety.”
- Tools/workflows: Conversation simulators; session-level safety scores; investigations of memory policies (what to store/forget).
- Assumptions/dependencies: Access to real or synthetic conversation logs; privacy-preserving infrastructure.
- Secure researcher access to real interactions at scale (policy; DSA Article 40 ecosystems)
- What: Establish vetted access programs for context-aware safety studies on real user data under strict governance.
- Tools/workflows: Data enclaves; differential privacy; legal/data-sharing frameworks.
- Assumptions/dependencies: Platform cooperation; ethics approvals; robust anonymization.
- Adaptive, risk-aware agents that ask the right questions (software, healthcare, finance)
- What: Agents that identify missing, safety-critical context and ask minimal, high-yield follow-ups before advising; gracefully defer when uncertainty remains high.
- Tools/workflows: Active learning for question selection; uncertainty estimation; policy constraints for “advice refusal.”
- Assumptions/dependencies: HCI research to avoid burdening users; fairness checks to prevent disparate treatment.
- Privacy-preserving user modeling for vulnerability signals (software, security)
- What: On-device or federated modeling to infer vulnerability indicators without centralizing sensitive data; contextual risk scoring at the edge.
- Tools/workflows: Federated learning; secure enclaves; local inference with global aggregation.
- Assumptions/dependencies: Device capabilities; privacy laws; strong threat modeling.
- Sector-specific evaluators and profiles (health specialties, debt counseling, legal aid; healthcare, finance, law)
- What: Build fine-grained profile libraries (e.g., pediatrics, oncology, student debt, elder care) and domain-calibrated safety rubrics.
- Tools/workflows: Specialty advisory panels; outcome-linked risk factors; living profile repositories.
- Assumptions/dependencies: Ongoing expert input; periodic updates with new evidence/guidelines.
- Vulnerability-aware fairness and performance objectives (ML research; safety)
- What: Train models to optimize for equitable safety across vulnerability tiers, not just average-case metrics; detect systematic overestimation of safety in high-risk groups.
- Tools/workflows: Multi-group objectives; constraint optimization; post-hoc calibration by subgroup.
- Assumptions/dependencies: Reliable labels across groups; guarding against trade-offs that reduce access or utility.
- Insurance, liability, and risk-based access controls (finance, legal, platform policy)
- What: Align insurance products and liability regimes with user-welfare safety scores; restrict high-risk advice modes for vulnerable users unless supervised.
- Tools/workflows: Policy underwriting informed by safety metrics; role-based capability gating; auditable logs.
- Assumptions/dependencies: Legal clarity; transparent scoring; user consent.
- Cross-platform safety dashboards for regulators and auditors (policy, governance)
- What: Periodic public reporting of user-welfare safety metrics by domain and vulnerability level; early-warning indicators for emerging harms.
- Tools/workflows: Secure telemetry pipelines; standardized KPIs; anomaly detection.
- Assumptions/dependencies: Data-sharing agreements; clear metric definitions; anti-gaming measures.
- Education and training curricula for professionals (academia, professional bodies; healthcare, finance, social services)
- What: Train clinicians, financial advisors, and social workers in evaluating and intervening on LLM advice risks for vulnerable clients.
- Tools/workflows: Case-based modules; simulation labs; continuing education credits.
- Assumptions/dependencies: Partnerships with professional associations; integration into credentialing.
Notes on feasibility across items:
- Many applications depend on expert-validated scoring to complement LLM-as-judge, given known limitations of LLM evaluators.
- Data access and privacy constraints are pivotal, especially for multi-turn and memory-aware evaluations.
- Organizational readiness (human escalation capacity, governance) and regulatory alignment (EU AI Act, DSA) will shape adoption pace.
- UI/UX design must balance “enough context for safety” with user burden and privacy-preserving defaults.
Glossary
- Borda Count method: A consensus-based voting technique that aggregates individual rankings into a final ranking. "using a Borda Count method, a standard consensus-based voting procedure"
- Chain-of-thought analysis: The explicit reasoning steps an LLM follows or is prompted to provide to reach a judgment. "improve the coherence of the chain-of-thought analysis, thereby increasing its reliability and face validity."
- Context-aware evaluation: Safety assessment that explicitly considers the specific user’s profile and circumstances. "our context-aware evaluation uncovers hidden risk dimensions that generalize beyond any single domain or model"
- Context-blind evaluation: Safety assessment conducted without reference to the specific user’s context. "context-blind evaluation systematically underestimates vulnerability-specific risks for medium and in particular high-vulnerability users."
- Demographic-aware fairness auditing: Evaluation focusing on performance disparities across demographic groups. "Within ML research, the closest analogue is demographic-aware fairness auditing."
- Downstream, profile-conditioned risks: Risks that depend on individual user profiles in real advice-seeking contexts rather than aggregate performance. "rather than at downstream, profile-conditioned risks for individuals seeking advice."
- Face validity: The extent to which an evaluation appears to measure what it claims, based on expert judgment. "thereby increasing its reliability and face validity."
- Guardrail robustness: The strength of safety mechanisms that prevent models from producing harmful or unsafe outputs. "and quantify guardrail robustness"
- Inter-annotator reliability: Agreement level among human evaluators when judging the same items. "achieving acceptable inter-annotator reliability would necessitate extensive training and calibration"
- Jailbreak-style prompting: Techniques designed to bypass or defeat LLM safety guardrails. "use techniques like red-teaming and jailbreak-style prompting"
- LLM-as-judge: Using an LLM to evaluate or score the outputs of other LLMs or systems. "we employed an LLM-as-judge pipeline using gpt-o3 with a temperature of 0.2 for consistent evaluations."
- Propensity evaluations: Assessments of how models tend to behave across scenarios, focusing on tendencies rather than capabilities. "Propensity evaluations examine how models act across scenarios, measuring tendencies such as sycophancy, deception, and bias"
- Red-teaming: Adversarial testing to elicit unsafe or harmful behavior from models. "use techniques like red-teaming and jailbreak-style prompting"
- Revealed preferences: What users actually disclose or do in practice, as opposed to what they say they would. "stated preferences (what users say they would share) rather than revealed preferences (their actual behaviour)."
- Risk-based approach: A regulatory or evaluation strategy where obligations depend on the level and context of risk. "the EU AI Act codifies a risk-based approach where obligations depend on the deployment context"
- Risk matrix: A tool that evaluates risk by combining likelihood and severity of potential harm. "based on a standard risk matrix (likelihood × severity of harm)"
- Safety-washing: Overstating safety through narrow or misleading metrics that don’t reflect real user impacts. "Critics warn that narrow metrics focusing solely on capabilities can enable "safety-washing" unless tests are tied to real user impacts"
- Sociotechnical stack: A layered framework linking model capabilities, human interactions, and broader system impacts. "propose a three-layer sociotechnical stack, progressing from capabilities to human interaction to systemic impacts."
- Stated preferences: What users claim they would disclose or prefer, often measured via surveys. "stated preferences (what users say they would share) rather than revealed preferences (their actual behaviour)."
- Sycophancy: A model tendency to agree with or flatter the user regardless of correctness or safety. "measuring tendencies such as sycophancy, deception, and bias"
- User Welfare Safety: The safety of LLM advice for an individual user given their specific circumstances and vulnerabilities. "Definition User Welfare Safety: The degree to which LLM-generated advice is safe for individual users when acted upon, minimizing potential financial, psychological, or physical harm based on their specific circumstances and vulnerabilities."
- Very Large Online Search Engine (VLOSE): An EU DSA designation for platforms meeting very large scale criteria, triggering specific obligations. "Very Large Online Search Engine (VLOSE) designation under the EU Digital Services Act"
- Vetted researcher access: Regulated access for qualified researchers to platform data under the EU DSA. "Article 40's provision for vetted researcher access to individual-level user interactions and engagement histories"
- Vulnerability stratification: Categorizing user profiles by levels of vulnerability to tailor evaluation or advice. "The guidelines for vulnerability stratification instructed them to consider a combination of factors"
Collections
Sign up for free to add this paper to one or more collections.

