- The paper presents a polynomial-time algorithm that uses low logit rank to offer formal learning guarantees for modern language models.
- It employs adaptive sampling of futures and LP-based coefficient updates to effectively reconstruct linear dependencies in the logit space.
- The method scales polynomially with key parameters, supporting reliable applications in model distillation and extraction.
Provably Learning from Modern LLMs via Low Logit Rank: An Expert Analysis
Introduction and Motivation
This paper addresses the critical challenge of obtaining robust theoretical guarantees for learning LMs that reflect the empirical properties observed in large neural architectures such as transformers. With the complexity and opacity of modern LMs hindering principled analyses, the study focuses on the "low logit rank" property—a structural phenomenon where logit matrices, defined via conditional log-probabilities of next tokens, display empirical approximability by matrices of low rank. As shown in previous studies, this property is pervasive among high-performance LLMs and offers a tractable, architecture-agnostic lens through which model behavior can be analyzed.
The authors' central question concerns the algorithmic exploitation of (approximate) low logit rank to yield formal, end-to-end learning guarantees for generative models that genuinely approximate the observable behavior of state-of-the-art LMs. The scope naturally extends to settings relevant for practical ML pipelines: query-access via logits, which resembles available model APIs used for distillation and "model stealing" attacks.
For an LM M producing distributions over sequences of tokens of length T, the logit matrix for sets of histories H and futures F (with suitable length constraints) is defined with entries given by mean-centered log-probabilities LM(z∣h∘f). Low logit rank denotes the case where, for all relevant H,F, this matrix has rank at most d. A crucial operational intuition is that, under low logit rank, the future continuation of any history can be linearly reconstructed from a set of basis histories in logit space.
This property connects tightly to "Input-Switched Affine Networks" (ISANs), a family of latent-variable autoregressive generative models equivalent (in representational power) to LMs with low logit rank. This equivalence justifies the focus on logit space rather than probability space: modern LMs exhibit significant overlap and linear structure in logits, even when their associated output probabilities are essentially orthogonal (a property not shared by low rank models in probability space).
The authors empirically validate approximate low logit rank for OLMo2-1b—a state-of-the-art LM—using sampled histories and futures. They demonstrate that average L1 error of the best rank-d approximation decays as a mild power-law (∼d−0.1), and that this behavior is robust to subsampling size. This supports the use of approximate low logit rank as a faithful, scalable abstraction for real LMs.
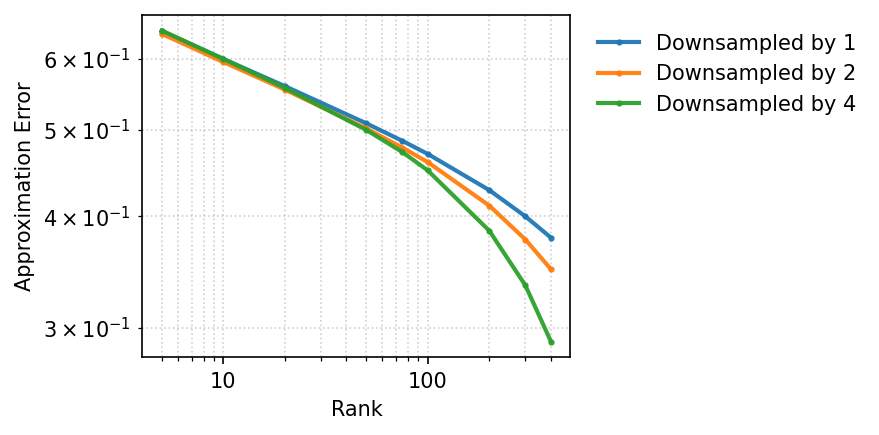
Figure 1: Low-rank approximation error (average L1) for the extended logit matrix of OLMo2-1b, confirming empirical low logit rank across different matrix subsamplings.
Main Results and Algorithms
End-to-End Learning Guarantee
The paper presents the first polynomial-time algorithm that, given query access to the logits of any model with approximate low logit rank, outputs an efficiently sampleable model M^ such that the total variation distance $\tvd{\hat{M}}{M}$ is polynomially controlled by the rank, approximation error, token set size, and sequence length. The logit query model required is naturally aligned with the API functionalities of deployed LMs, significantly extending prior results limited to excessive architectural or distributional simplifications.
Numerics: For target accuracy ϵ and logit rank d, their query and runtime complexity is O~(T13d4∣Σ∣/ϵ4) (up to polylogarithmic factors and boundedness parameters), with error scaling as ϵ≳poly(d,T,∣Σ∣,1/α,1/δ)⋅ϵapprox, where ϵapprox is the average entrywise logit approximation error.
Technical Innovations
- Adaptive Sampling of Futures: Standard techniques for learning with low-rank structure in the probability space (as in HMMs) fail in this setting due to the high orthogonality of output distributions. To address this, the algorithm samples "futures" adaptively using the elliptical potential method: new query directions are only introduced if the current set does not adequately capture the logit linear structure, with the number of necessary additional directions tightly controlled by the logit rank.
- Linear Program-Based Coefficient Updates: Past work often suffers from exponential blowup in the linear combination coefficients when propagating updates through token positions. Here, the sequence of mixing coefficients is globally optimized via a single linear program across the entire sequence, exploiting observed linear dependencies in empirical logit vectors and bounding possible error accumulation.
- Strong Robustness to Oracle Misspecification: The method's learning guarantees hold whenever oracles are approximately consistent with bounded low-rank structure on the polynomially many queries made by the algorithm. This robustness means that provable learning is unaffected by worst-case aberrations on vanishing-probability query sequences.
Theoretical and Practical Implications
The theoretical significance lies in demonstrating efficient and robust learning even when the underlying generative process admits worst-case complexity barriers (e.g., can encode noisy parity problems). By utilizing logit queries—effectively, a form of "model distillation"—these limitations can be circumvented in full generality for models satisfying approximate low logit rank.
Practical consequences are substantial. Given the observed pervasiveness of low logit rank, knowledge distillation, model compression, or even model extraction from deployed APIs can be supported by formal end-to-end guarantees. The theoretical insight is that the sample complexity and computational cost are polynomial in all relevant quantities, matching empirical scaling trends of deployed LM systems. Additionally, the connection to ISANs develops a precise latent variable account of LM expressivity, supporting future work in interpretability and mechanistic analysis.
Algorithmic Foundations
The learning algorithm consists of the following high-level stages:
- Initialization with small sets of sampled "futures".
- Construction of basis sets (spanners) for histories/futures via distributional spanner algorithms, leveraging polynomially-sampled logit vectors.
- Iterative logit-coefficient fitting using linear programs, adaptively expanding the handler set of futures only when violation of linear structure is detected.
- Final extraction of a sampleable autoregressive LM, whose next-token conditionals closely approximate the target model in total variation.
The key to sample efficiency and termination is the elliptical potential lemma, which guarantees at most $O(\logit\ \textrm{rank})$ adaptions per position, up to polylogarithmic factors.
The approach is fundamentally distinct from low-rank models defined in the probability space, which are incapable of capturing the support structure or linear dependencies empirically present in high-performing transformers. As shown in prior work, such models would require exponential rank to account for moderate-length contexts. The present methodology thereby captures, for the first time, LM behaviors (such as in-context learning and recall) with provable guarantees, advancing both learning theory and realistic modeling.
Open Problems and Future Directions
- Polynomial Constant Optimization: The current dependence on logit rank d in the error exponent (e.g., requiring ϵ≲d−9.5) is likely far from optimal; empirical evidence suggests the true scaling is much milder. Improved analysis could narrow this gap.
- Extension to Conditional Sampling Oracles: While logit queries reflect many API functionalities, some APIs only permit conditional sampling. Adapting the theoretical guarantees to this weaker access remains open for the full generality of low logit rank.
- Control-Theoretic and Latent-Variable Perspectives: The ISAN equivalence invites development of interpretability and control-theoretic tools for LMs via linear dynamical systems theory, potentially impacting safety and mechanistic analysis.
- Implications for Boolean Function Learning: The guarantees yield a weak form of the Kushilevitz-Mansour algorithm for efficiently learning sparse Boolean functions given query access, further connecting LM learning to classical questions in computational learning theory.
Conclusion
This paper establishes that modern LMs, when abstracted through the empirically validated lens of (approximate) low logit rank, are amenable to formal, sample-efficient, and computationally tractable learning from logit queries. The resulting framework sets a rigorous foundation for both theoretical analysis and practical distillation/extraction of LMs closely mirroring the observable behaviors of state-of-the-art transformers, thereby aligning learning theory with current engineering reality.