WonderZoom: Multi-Scale 3D World Generation
Abstract: We present WonderZoom, a novel approach to generating 3D scenes with contents across multiple spatial scales from a single image. Existing 3D world generation models remain limited to single-scale synthesis and cannot produce coherent scene contents at varying granularities. The fundamental challenge is the lack of a scale-aware 3D representation capable of generating and rendering content with largely different spatial sizes. WonderZoom addresses this through two key innovations: (1) scale-adaptive Gaussian surfels for generating and real-time rendering of multi-scale 3D scenes, and (2) a progressive detail synthesizer that iteratively generates finer-scale 3D contents. Our approach enables users to "zoom into" a 3D region and auto-regressively synthesize previously non-existent fine details from landscapes to microscopic features. Experiments demonstrate that WonderZoom significantly outperforms state-of-the-art video and 3D models in both quality and alignment, enabling multi-scale 3D world creation from a single image. We show video results and an interactive viewer of generated multi-scale 3D worlds in https://wonderzoom.github.io/







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
WonderZoom: Multi-Scale 3D World Generation — explained for teens
1) What is this paper about?
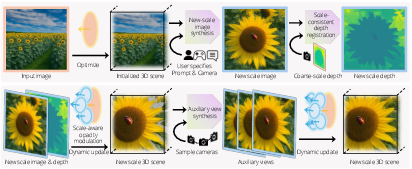
This paper introduces WonderZoom, a new way to build 3D worlds from just one picture, and then “zoom in” to add smaller and smaller details—like going from a wide view of a field, to a single flower, to a tiny ladybug on a petal. Unlike most methods that only work at one size level (just a room, or just a city), WonderZoom creates and renders content across many scales, smoothly and in real time.
2) What questions does it try to answer?
Put simply, the paper asks:
- How can we turn a single image into a 3D world that you can explore by zooming in, revealing new details that weren’t there before?
- How can we represent 3D scenes so they can grow with more detail over time without breaking or needing to rebuild everything?
- How can we make sure the new, zoomed-in details match the bigger scene and follow the user’s ideas or prompts?
3) How does WonderZoom work? (Explained with simple analogies)
Think of building a world like using layered, transparent stickers on a window:
- The big, faraway view uses large stickers.
- As you zoom in, you add smaller stickers on top to show finer details.
WonderZoom has two main parts:
- Scale-adaptive Gaussian surfels (the sticker layers)
- Imagine every tiny piece of the 3D scene is a small, flat, semi-transparent “sticker” placed in 3D space with a position, size, angle, color, and transparency.
- Each sticker remembers the scale (zoom level) it was made for. When you zoom in or out, WonderZoom gently fades the right stickers in and out. This prevents visual “popping” and keeps everything smooth.
- Because new details are added as new stickers (instead of redoing old ones), the scene can grow over time without heavy re-optimization. That keeps rendering fast, so you can explore in real time.
- Progressive detail synthesizer (the artist adding new detail) When you decide to zoom into a region and provide a prompt (for example: “add a ladybug on the sunflower”), WonderZoom runs a careful, step-by-step process:
- Start from the current 3D scene and render a zoomed-in image of that area. It’s a coarse view, like a blurry close-up.
- Super-resolution: sharpen and enhance this zoomed image using context from a vision-LLM (like a smart AI that understands both pictures and text). This adds realistic fine details that fit the scene.
- Prompt-based editing: if you asked for something new (like the ladybug), the system edits the image to insert it in a believable way.
- Depth registration: the system estimates how far each pixel is from the camera (depth), and aligns these depths with the existing 3D geometry so new details sit correctly in the 3D world.
- Auxiliary views: to make the new content truly 3D (not just a single picture), WonderZoom generates nearby viewpoints (like short camera moves) and estimates their depth too. These extra views help create a complete 3D structure that looks right from different angles.
- Finally, it turns these images and depths into new “stickers” (surfels) and adds them to the scene—no need to rebuild what you already had.
In everyday terms: it starts with a rough 3D model from your photo, then each time you zoom and prompt it, WonderZoom paints in sharper details and builds the 3D around them so you can move the camera and still see those details properly.
4) What did they find, and why is it important?
The authors compared WonderZoom to state-of-the-art 3D scene generators and camera-controlled video models. Key takeaways:
- Better prompt following: WonderZoom’s results matched user prompts more closely than other methods.
- Higher visual quality: zoomed-in views looked sharper and more consistent, without the blur or mismatches common in other systems.
- Smoother scale transitions: details fade in and out smoothly as you zoom, avoiding harsh changes or flicker.
- Faster and more efficient rendering: their scale-aware fading greatly reduces memory use and boosts frame rate, enabling real-time exploration.
- Human preferences: in user studies, people preferred WonderZoom’s zoom accuracy, visual quality, and prompt match over baselines most of the time.
This matters because it shows a practical way to create rich 3D worlds from a single image that you can keep digging into, discovering or adding tiny details on demand.
5) What’s the impact? Where could this be useful?
By allowing creative, on-demand zooming with new content at each level, WonderZoom could help:
- Game development and virtual worlds: rapidly build explorable scenes with fine details without hand-crafting everything.
- Education and storytelling: make interactive “powers of ten” experiences—from galaxies down to microbes.
- Film and animation: quickly prototype scenes and zoom shots with coherent detail.
- Design and art: experiment with layered scenes, adding new objects and textures as inspiration strikes.
Limitations: WonderZoom can struggle when zooming into areas with no recognizable structure (just texture), because it relies on semantic cues to decide what details to invent next. Future work could add special rules for textures to keep zooming convincingly.
In short: WonderZoom shows how to grow a 3D world from one picture, scale by scale, smoothly and intelligently—opening the door to rich, interactive, infinite-zoom experiences.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of what the paper leaves unresolved. Each item is formulated to be concrete and actionable for future work.
- Formal analysis of the scale-aware opacity modulation: beyond Proposition 1 (which assumes co-located adjacent-scale surfels), provide proofs and bounds for general cases with non-coincident surfels, varying normals, heterogeneous colors, and mixed occlusions; assess whether log-space interpolation is optimal and under what conditions partition-of-unity holds.
- Ambiguity in the scale definition equations: several equations for native/render/parent/child scales appear syntactically broken in the paper (missing braces/superscripts), preventing exact reproduction; the precise functional form and its derivation need clarification and ablation against alternate scale proxies (e.g., projected footprint, screen-space area).
- View-independent appearance modeling: surfels store a single RGB color without view dependence; develop multi-scale, view-dependent radiance/BRDF, shading, and global illumination models to avoid appearance inconsistencies when zooming or changing viewpoints, and quantify gains versus the current INR-harmonization post-process.
- Cross-scale geometric consistency when coarse geometry is wrong: the method never re-optimizes earlier scales; establish strategies (e.g., constrained joint optimization, multi-scale regularizers, or local retrofitting) to reconcile fine-scale additions with inaccurate coarse geometry and prevent contradictions across scales.
- Memory growth and scalability: additive surfel accumulation across scales has no pruning/decimation policy; characterize memory/time scaling with the number of zoom levels and scene size, propose merging/compaction policies (e.g., adaptive coalescing, scale-aware culling), and evaluate their impact on quality and FPS.
- Accumulation of depth errors across scales: depth registration fine-tunes monocular estimators against sparse targets, but error could compound through repeated zooms; quantify drift across long zoom chains, define stopping criteria, and develop calibration/consistency checks (e.g., multi-view reprojection error metrics).
- Dependence on segmentation quality: SAM/Grounded SAM segmentations drive segment-wise depth alignment and new-object isolation; analyze failure modes on thin structures, occlusions, and clutter, and propose robustness strategies (e.g., uncertainty-aware alignment, multi-model ensembling).
- Auxiliary view synthesis geometry fidelity: camera-controlled video diffusion plus video-depth estimation can introduce geometry/pose inaccuracies; measure geometric consistency (e.g., scale-accurate depth distributions, epipolar constraints, reprojection PSNR) and compare against physically grounded multi-view synthesis baselines.
- Multi-scale coherence metrics and benchmarks: current evaluation relies on CLIP/CLIP-IQA/Q-align and 2AFC; create datasets and metrics for scale-consistency (e.g., size ratio preservation across zooms, inter-scale silhouette consistency, occlusion coherence, continuity of textures/structures) with controlled ground truth.
- Scope of scene types and materials: assess performance on reflective/transparent surfaces, volumetric media (fog, water caustics), thin geometry, and highly specular scenes where view-dependent effects matter; quantify degradation and extend the representation/synthesizer accordingly.
- Extreme zoom into texture-only regions: the paper notes failure in texture-only areas; develop texture-specific priors/procedural microstructure models and define detectors that forecast under-constrained regions to adapt generation (e.g., switch to stochastic microgeometry synthesis with physical plausibility constraints).
- Path-dependence and conflict resolution: zooming into the same region via different camera paths/prompts may yield divergent micro-details; devise mechanisms for conflict detection and reconciliation (e.g., surfel provenance tracking, consensus rules, or user-guided arbitration) to maintain a consistent world state.
- Camera calibration from a single image: the initial camera and intrinsics/focal lengths are set heuristically; clarify how C0 is estimated from a single image, quantify sensitivity to miscalibration, and explore joint calibration during initial reconstruction.
- Physical plausibility of scale relations: inserted objects (e.g., ladybug sizes) may violate correct real-world scale ratios; introduce priors/constraints for object size, contact, and placement consistent with scene context and measured geometry.
- Temporal dynamics and moving objects: the method targets static 3D worlds; extend to dynamic, non-rigid scenes with multi-scale generation over time, ensuring temporal and cross-scale coherence under camera motion.
- Occlusion handling across scales: adding fine-scale surfels behind/in front of coarse ones can cause occlusion conflicts; formalize z-ordering/visibility policies across scales, and measure occlusion-consistency during zoom transitions and wide-baseline novel views.
- Hardware and energy cost of the pipeline: quantify the compute footprint of the progressive synthesizer (VLM, SR, video diffusion, depth models) and end-to-end energy costs per new scale; study trade-offs and lightweight alternatives to enable broader deployment.
- Reproducibility and dependency on proprietary models: reliance on GPT-4V and closed-source diffusion/depth models challenges reproducibility; report performance with open-source substitutes and define standardized configurations for fair comparison.
- Fairness of baseline comparisons: baselines are not designed for multi-scale 3D generation; design controlled evaluations that isolate multi-scale capabilities (e.g., forcing baselines to generate per-scale content with post-hoc alignment) to disentangle representation benefits from task mismatch.
- Number and placement of auxiliary views: the choice of K neighboring views and their distribution is not studied; analyze the trade-off between auxiliary view count, coverage, geometry completeness, and compute, and propose adaptive sampling strategies.
- Optimization constraints on surfel parameters: positions/colors/native scales are fixed during new-scale optimization; evaluate benefits/risks of allowing limited position updates or color refinement under cross-scale constraints to correct local depth/color errors.
- Robustness to large viewpoint changes beyond zoom: test performance for wide-baseline novel views (e.g., 90–180° azimuth changes) after deep zoom, quantify artifacts, and extend auxiliary synthesis/registration to support broader camera motions.
- Security/safety and misuse: hallucinated microstructures may imply false details in scientific or forensic contexts; define safeguards (e.g., provenance metadata, uncertainty visualization, disclaimers) and detection tools for synthetic micro-detail generation.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging WonderZoom’s scale-adaptive Gaussian surfels, progressive detail synthesizer, and real-time rendering capabilities demonstrated in the paper and accompanying viewer.
- Entertainment and game development (Software, Media)
- Use case: Rapid prototyping of explorable environments from concept art or single mood-board images; create infinite zoom sequences for trailers and cutscenes.
- Tools/products/workflows: Unity/Unreal/Blender plugin that imports an image, generates a navigable 3D scene, and lets designers “zoom-to-generate” prompted micro-details; export splats/meshes for engine LoD.
- Assumptions/dependencies: Requires GPU acceleration and availability of third-party models (VLM, super-resolution, camera-controlled video diffusion). Generated microstructures are plausible rather than physically or metrically accurate.
- Advertising, marketing, and e-commerce (Media, Retail)
- Use case: Interactive product pages and brand experiences where users zoom from hero imagery to micro-level details (e.g., finishes, stitching) or storytelling elements.
- Tools/products/workflows: Web viewer embedding; “Zoom campaigns” asset pipeline that turns a single image into an explorable 3D narrative with prompt-driven micro-content.
- Assumptions/dependencies: Content rights for the source image; cloud GPU for live rendering; ensure disclosure that micro-details are synthetic and may not reflect authentic product specs.
- Education and public engagement (Education)
- Use case: Classroom demos of multi-scale phenomena (e.g., “from forest to leaf to insect”), virtual museum exhibits, and interactive science outreach materials.
- Tools/products/workflows: Teacher-facing “Zoom-to-Explore” lesson builder; museum kiosk viewer displaying authored zoom paths and prompts; curated prompt libraries.
- Assumptions/dependencies: Pedagogical review for factual accuracy; clear labeling that fine details are generative rather than measured data.
- Architecture and interior concept visualization (Architecture)
- Use case: Present mood/atmosphere boards as navigable 3D concepts; zoom into materials and décor details for early stakeholder buy-in.
- Tools/products/workflows: “Concept-to-Scene” workflow in design studios—import reference photos, generate multi-scale scenes, annotate with prompts for materials and accessories.
- Assumptions/dependencies: Not suitable for dimensionally precise work; relies on high-quality input imagery and prompt curation; generative micro-details are illustrative.
- Cultural heritage and museums (Culture/Education)
- Use case: Transform archives or single exhibit photos into explorable environments; zoom into artifacts to reveal interpretive micro-stories.
- Tools/products/workflows: Curator interface to define zoom paths, attach textual narration, and author prompts for fine detail generation; on-prem rendering kiosk.
- Assumptions/dependencies: Strict provenance and interpretive disclaimers; generative content must be clearly distinguished from documented details.
- Human–computer interaction research (Academia/HCI)
- Use case: Study “zoom-to-generate” interaction paradigms, user agency in mixed-initiative content creation, and perceptual continuity across scales.
- Tools/products/workflows: Experiment prototyping with the open viewer and code; metrics for continuity, prompt alignment, and user preference (as in the paper’s 2AFC setup).
- Assumptions/dependencies: Access to the released code/models; IRB considerations for user studies.
- Computer vision/graphics research (Academia/Software)
- Use case: Benchmarking multi-scale generative representations; ablating opacity modulation, depth registration, and auxiliary view synthesis; extending to new domains.
- Tools/products/workflows: Reuse of the scale-adaptive surfels as a general-purpose real-time canvas for hierarchical generation; dataset creation of zoom trajectories and prompts.
- Assumptions/dependencies: Compatibility with existing CV/graphics toolchains; GPU/VRAM budgets; licensing for dependent models (e.g., GPT-4V, Gen3C).
- Social media and creator tools (Media)
- Use case: Author infinite zoom videos and interactive posts; livestream 3D exploration with on-demand detail generation tied to audience prompts.
- Tools/products/workflows: Creator app that records zoom paths, applies prompts, and exports sequences; integrations with streaming overlays.
- Assumptions/dependencies: Moderation of prompted content; compute budgets; platform policies on synthetic media.
Long-Term Applications
These use cases require further research, scaling, integration, or validation—particularly around physical realism, provenance, and multi-modal data fusion.
- Dynamic LoD for game engines and XR platforms (Software, Robotics, Media)
- Use case: Replace static LoD assets with generative, scale-adaptive content that streams or materializes as users zoom or move.
- Tools/products/workflows: “Generative LoD” subsystem in engines that blends authored coarse worlds with on-demand fine details; caching and streaming infrastructure.
- Assumptions/dependencies: Determinism, memory/latency controls, content safety, and consistent world state across clients; deeper integration with asset pipelines.
- Simulation for robotics training across scales (Robotics)
- Use case: Train agents on tasks that span macro navigation and micro manipulation (e.g., from warehouse traversal to screw-thread inspection) in rich generative environments.
- Tools/products/workflows: Domain randomization across scales; physics + perception coupling; synthetic-to-real transfer studies.
- Assumptions/dependencies: Physically accurate geometry and materials, reliable scale calibration, physics engines that operate coherently across scale tiers.
- Scientific visualization and multi-scale digital twins (Energy, Geospatial, Urban Planning, Biology)
- Use case: Exploratory visualizations that bridge satellite views, city blocks, buildings, rooms, and microscopic structures for planning and education.
- Tools/products/workflows: Fusion of GIS/BIM/remote sensing/cadastre data with generative fill for missing scales; knowledge-graph conditioning for factual constraints.
- Assumptions/dependencies: Verified data sources, strong constraints to avoid hallucinations, governance for how generative infill is marked and audited.
- Healthcare and medical training (Healthcare/Education)
- Use case: Macro-to-micro anatomy exploration and procedure walkthroughs that zoom from organ systems to tissue-level views.
- Tools/products/workflows: Regulated content pipelines with clinical validation; integration with medical imaging (CT/MRI/ultrasound) and atlas data for conditioning.
- Assumptions/dependencies: Regulatory approvals, factual accuracy, and clear separation of synthetic content from clinical evidence; robust scale calibration.
- E-commerce “true detail” inspectors (Retail/Manufacturing)
- Use case: Accurate macro-to-micro product inspection experiences for buyers (e.g., fabric weave, surface finish, tolerances).
- Tools/products/workflows: Hybrid pipeline combining multi-view capture/metrology with WonderZoom’s representation; prompts limited to enhancement, not fabrication.
- Assumptions/dependencies: Multi-view or depth capture to ensure geometric truth; industry standards for disclosure and liability.
- Urban planning and infrastructure communication (Policy/Public Sector/Geospatial)
- Use case: Public engagement platforms where citizens can explore plans from regional scale down to street furniture and materials.
- Tools/products/workflows: Authoring tools for planners to define zoom narratives; overlays of verified datasets and generative placeholders.
- Assumptions/dependencies: Data governance, accessibility compliance, strict labeling of synthetic vs. authoritative layers.
- Provenance, labeling, and standards for multi-scale synthetic environments (Policy)
- Use case: Develop guidelines/standards for provenance, watermarking, and disclosure in multi-scale generative 3D content used in commerce, education, and media.
- Tools/products/workflows: Content authenticity pipelines (watermarks, cryptographic signatures); audit trails that record prompts and generation steps.
- Assumptions/dependencies: Cross-industry consensus, legal harmonization, and technical support in engines/viewers; alignment with emerging synthetic media policies.
- Virtual tourism and cultural storytelling (Media/Culture)
- Use case: Persistent multi-scale worlds that let audiences traverse from landscapes to artifact details and micro narratives in XR.
- Tools/products/workflows: Narrative engines that script zoom sequences and prompt-driven micro-scenes; multi-user synchronization for shared experiences.
- Assumptions/dependencies: Performance scaling for concurrent users, IP/provenance management, and editorial safeguards.
- Enterprise SaaS for multi-scale authoring (“WonderZoom Studio”) (Software)
- Use case: End-to-end platform offering image-to-world authoring, zoom-path scripting, prompt libraries, and asset export for teams.
- Tools/products/workflows: Role-based content moderation, compute orchestration, model management, and integrations with DCC tools.
- Assumptions/dependencies: Cost-efficient GPU orchestration, licensing for foundation models, and enterprise security/compliance.
Cross-cutting assumptions and dependencies
- Compute and tooling: Real-time performance depends on GPU acceleration, memory management, and efficient opacity modulation; auxiliary models (VLM, super-resolution, video diffusion, depth) must be available and licensed.
- Data fidelity: Fine-scale content is generative and may be semantically plausible but not metrically or physically accurate; clear disclosure is needed in regulated domains.
- Content governance: Prompted insertions can introduce inappropriate or misleading details; moderation and provenance tracking are recommended.
- Domain limits: Failure modes occur in texture-only regions with weak semantics; reliance on semantic cues implies domain-specific priors may be needed for certain microstructures.
- Integration: To move beyond demos, workflows must integrate with existing asset pipelines, CAD/BIM/GIS stacks, or physics simulators depending on sector.
Glossary
- Auxiliary view synthesis: Generating additional nearby-viewpoint images to complete 3D reconstruction beyond a single view. "Auxiliary view synthesis."
- Autoregressive synthesis: Iterative generation where each step conditions on previously produced content to add finer details. "triggering autoregressive synthesis of previously non-existent details"
- Camera-controlled video diffusion model: A diffusion-based generator that produces video frames conditioned by specified camera motions or viewpoints. "a camera-controlled video diffusion model"
- CLIP score: A text–image alignment metric computed from CLIP that measures how well images match prompts. "compute the CLIP~\citep{radford2021learning} scores"
- CLIP-IQA+: A CLIP-based no-reference image quality assessment metric. "CLIP-IQA+~\citep{wang2022exploring}"
- D-SSIM: A differentiable Structural Similarity (SSIM) loss variant used for photometric optimization in rendering pipelines. "L_{\text{D-SSIM}~\citep{kerbl20233d}"
- Gaussian surfels: Oriented 3D Gaussian surface elements used as primitives for point-based scene representation and rendering. "scale-adaptive Gaussian surfels"
- Gaussian splatting: A rendering technique that projects 3D Gaussian primitives onto the image plane for efficient view synthesis. "3D Gaussian splatting representations of urban environments."
- Grounded SAM: A segmentation approach combining Segment Anything with grounding to isolate text-specified regions. "Grounded SAM~\citep{ren2024grounded}"
- Hierarchical 3D Gaussian Splatting: A multi-scale Gaussian splatting framework with explicit LoD hierarchies for efficient rendering. "Hierarchical 3D Gaussian Splatting~\citep{hierarchicalgaussians24}"
- Integrated positional encoding: A NeRF encoding that integrates features over ray footprints to handle scale and anti-aliasing. "introduces integrated positional encoding to handle scale ambiguity"
- Layered depth images: Image-based representations that store multiple depth layers per pixel for novel view synthesis. "layered depth images~\citep{lsiTulsiani18,Shih3DP20}"
- Level-of-Detail (LoD): A graphics technique that varies model complexity with viewing distance to balance quality and performance. "Level-of-Detail (LoD) representations"
- Mip-NeRF: A NeRF variant that uses integrated positional encoding to address aliasing and scale ambiguity. "Mip-NeRF~\citep{barron2021mip}"
- Mip-NeRF 360: An extension of Mip-NeRF for representing unbounded 360-degree scenes. "Mip-NeRF 360~\citep{barron2022mip}"
- Mip-Splatting: An anti-aliasing approach for Gaussian splatting that applies 3D smoothing filters across scales. "Mip-Splatting~\citep{yu2023mip}"
- Mipmapping: A texture anti-aliasing technique that precomputes texture pyramids at multiple resolutions. "and mipmapping, which precomputes texture pyramids for efficient anti-aliased rendering."
- Monocular depth estimator: A model that predicts depth from a single image without stereo or multi-view input. "fine-tune a monocular depth estimator"
- Multi-plane images: A layered representation using stacks of fronto-parallel planes with alpha textures for view synthesis. "multi-plane images~\citep{tucker2020single,zhou2018stereo}"
- NIQE: A no-reference image quality metric based on natural scene statistics. "NIQE~\citep{niqe}"
- Nyquist sampling theorem: The sampling criterion that specifies the minimum rate needed to avoid aliasing. "according to the Nyquist sampling theorem"
- Octree-GS: An octree-based organization of Gaussian splats to manage primitives across spatial scales. "Octree-GS~\citep{ren2024octree}"
- Orientation quaternion: A quaternion parameterization representing 3D rotation for surfel orientation. "orientation quaternion"
- Partition of unity: A set of weights that sum to one over a domain, used here to ensure seamless blending across scales. "This partition of unity is fundamental"
- Perpetual view generation: A technique for continuously generating forward-moving views in an environment. "perpetual view generation"
- Progressive detail synthesizer: A pipeline component that iteratively generates finer-scale 3D content conditioned on coarser scales and prompts. "a progressive detail synthesizer"
- Q-align IAA: A learned aesthetic assessment metric derived from Q-align that scores image aesthetics. "Q-align IAA~\citep{wu2023qalign}"
- Q-align IQA: A learned image quality assessment metric from Q-align reflecting perceptual quality. "Q-align IQA~\citep{wu2023qalign}"
- Radiance field: A continuous function representing scene appearance as color and opacity across 3D space (and view). "We model the scenes as a radiance field"
- SAM-generated masks: Segmentation masks produced by the Segment Anything Model for region-wise processing. "SAM-generated masks"
- Scale-adaptive Gaussian surfels: A dynamically updatable multi-scale surfel representation with native scale tracking for generation. "scale-adaptive Gaussian surfels"
- Scale-aware opacity modulation: A method that adjusts surfel opacity based on native and render scales to avoid aliasing and ensure smooth transitions. "scale-aware opacity modulation"
- Scale-consistent depth registration: A procedure to align depths of newly generated views with geometry from previous scales. "Scale-consistent depth registration."
- Super-resolution: Upsampling and detail enhancement of images to synthesize high-frequency content beyond the input. "extreme super-resolution"
- Vision-LLM (VLM): A model that jointly processes images and text to provide semantic context for generation. "vision-LLM (VLM)"
- Zip-NeRF: A NeRF variant improving representation and rendering of unbounded scenes. "Zip-NeRF~\citep{barron2023zip}"
Collections
Sign up for free to add this paper to one or more collections.