- The paper introduces GEN3D, a novel approach that generates high-fidelity, domain-free 3D scenes from a single 2D image using diffusion-based segmentation and Gaussian Splatting.
- The method overcomes traditional multi-view limitations by iteratively enhancing point clouds with advanced depth estimation and inpainting to maintain geometric consistency.
- Experimental evaluations, including the WorldScore benchmark, demonstrate that GEN3D outperforms competing models in camera control and texture fidelity.
Overview of GEN3D: Generating Domain-Free 3D Scenes from a Single Image
The paper entitled "GEN3D: Generating Domain-Free 3D Scenes from a Single Image" (2511.14291) introduces Gen3d, a novel approach to generate 3D scenes of high fidelity from a single 2D image input. The method addresses key limitations in traditional neural 3D reconstruction techniques, which typically require dense multi-view data, by utilizing advanced techniques like Stable Diffusion and Gaussian Splatting. The Gen3d model not only demonstrates superior performance in creating high-quality and geometrically consistent 3D scenes but also supports various input types, including text prompts and different image formats.
Methodology
Gen3d leverages a sophisticated pipeline to produce 3D scenes that are both visually compelling and geometrically accurate. The pipeline begins with the segmentation of a 2D image into foreground and background components, enhancing point cloud coverage through Stable Diffusion and monocular depth estimation (Figure 1).
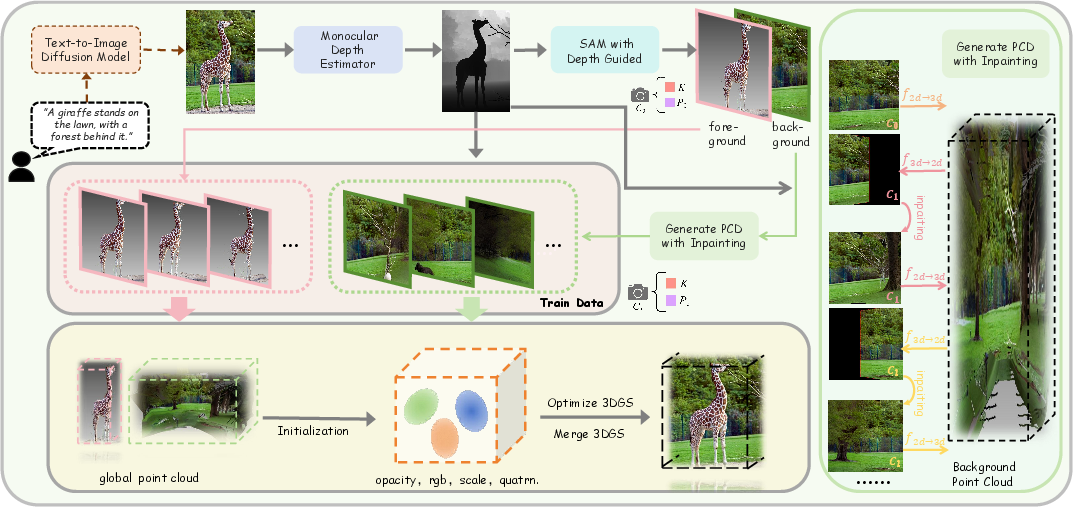
Figure 1: Gen3d pipeline.Initially, the input 2D image is segmented into two distinct components: the foreground objects and the background. We adopt methodologies such as the Stable Diffusion model and monocular depth estimation to enhance point cloud coverage and facilitate the construction of larger-scale scenes.Subsequently, we employ the point cloud alongside the reprojected images to optimize a set of Gaussian splats, further refining the resulting 3D scene.
Single-View Layer Generation
The generation process begins by decomposing the scene into layered representations. Using depth-aware models, the scene is segmented into foreground and background masks, which are then refined through diffusion-based inpainting to address occlusions. This segmentation allows Gen3d to manage geometric inconsistencies and ensure that the subsequent point cloud captures every detail of the input image.
World Generation and Rendering
The methodology's core includes an iterative process where an initial point cloud is augmented with new points generated as the camera navigates a predefined trajectory. This real-time augmentation ensures a unified world coordinate system is achieved, enabling seamless integration of new visual data into the existing scene structure. The point cloud is subsequently optimized using 3D Gaussian Splatting, which allows for the high-fidelity rendering of the scene without the common artifacts seen in traditional methods.
Experimental Evaluation
Gen3d was extensively evaluated across a series of benchmarks, with particularly strong performance noted in the WorldScore benchmark, which assesses both the controllability of the scene generation and the quality of output (Table). Noteworthy is Gen3d's top ranking in metrics such as camera control and photometric consistency, underscoring the utility of Stable Diffusion and the robustness of the Gaussian Splatting framework.















Figure 2: Comparisons of multi-view generation results across different methods.The images are sourced from the COCO dataset, the WorldScore Benchmark, and web-sourced images.
In comparative analyses with existing models, including WonderWorld and LucidDreamer, Gen3d demonstrated significant advancements, particularly in multi-view consistency and mitigating geometric artifacts under complex camera maneuvers (Figure 2). While competitors struggled with maintaining visual coherence across different scenes, Gen3d's approach preserved both the texture and structural integrity of generated environments, making it better suited for both indoor and outdoor scene generation tasks.
Implications and Future Work
The Gen3d method offers substantial advancements for fields requiring high-quality 3D scene reconstructions such as AI-driven robotics, immersive media, and virtual simulations. By overcoming the limitations associated with dense multi-view dependencies, Gen3d paves the way for more adaptive and versatile 3D generation methodologies.
Future research directions as suggested by the authors include the potential acceleration of the point cloud expansion process and extending Gen3d's capabilities to dynamic scene generation, which would greatly enhance real-time applications in rapidly changing environments.
Conclusion
In conclusion, "GEN3D: Generating Domain-Free 3D Scenes from a Single Image" significantly contributes to the domain of 3D scene generation through its innovative approach that combines depth-inspired segmentation, diffusion processes, and 3D splatting. This research not only highlights improvements in efficiency and quality over existing models but also sets a new benchmark for future developments in domain-free and single-image-based 3D scene synthesis.