- The paper demonstrates DiFFPO's ability to enhance diffusion LLM reasoning accuracy and sample efficiency through advanced RL methods.
- It introduces a Two Times Mean-Field approximation to reduce likelihood estimation errors across sequential unmasking steps.
- Joint training of the model and adaptive sampler improves the accuracy/compute trade-off, validated on benchmarks like GSM8K and Countdown.
DiFFPO: Reinforcement Learning for Efficient Reasoning in Diffusion LLMs
Overview
The paper introduces DiFFPO (Diffusion Fast and Furious Policy Optimization), a unified RL framework for post-training masked diffusion LLMs (dLLMs) to achieve both improved reasoning accuracy and reduced inference latency. The approach leverages off-policy RL, advanced likelihood approximations, and joint training of model and sampler policies. The empirical results demonstrate substantial improvements in both sample efficiency and the accuracy/compute trade-off on math and planning benchmarks.
Background: Masked Diffusion LLMs and RL
Masked dLLMs operate by iteratively unmasking tokens in any order, enabling multi-token predictions and parallel decoding, in contrast to the left-to-right autoregressive (AR) paradigm. The forward process interpolates between the data distribution and a categorical mask, while the backward process reconstructs the original sequence by unmasking positions based on learned predictive distributions.
Efficient sampling in dLLMs is critical for practical deployment. The Entropy-Bounded (EB) sampler, which unmaskes positions with predictive entropy below a threshold γ, provides a tunable trade-off between accuracy and compute. RL post-training, specifically RLVR and GRPO variants, has been effective for AR LLMs but is underexplored for dLLMs due to the complexity of likelihood estimation and the unique structure of masked diffusion.
DiFFPO Algorithmic Innovations
Surrogate Policy and Likelihood Approximation
The paper identifies the limitations of the mean-field likelihood approximation used in prior work (d1), which conditions only on the prompt and ignores the latent trajectory. Empirical analysis shows that the KL divergence between the true conditional likelihood and the mean-field approximation increases with decoding steps, leading to suboptimal RL updates.
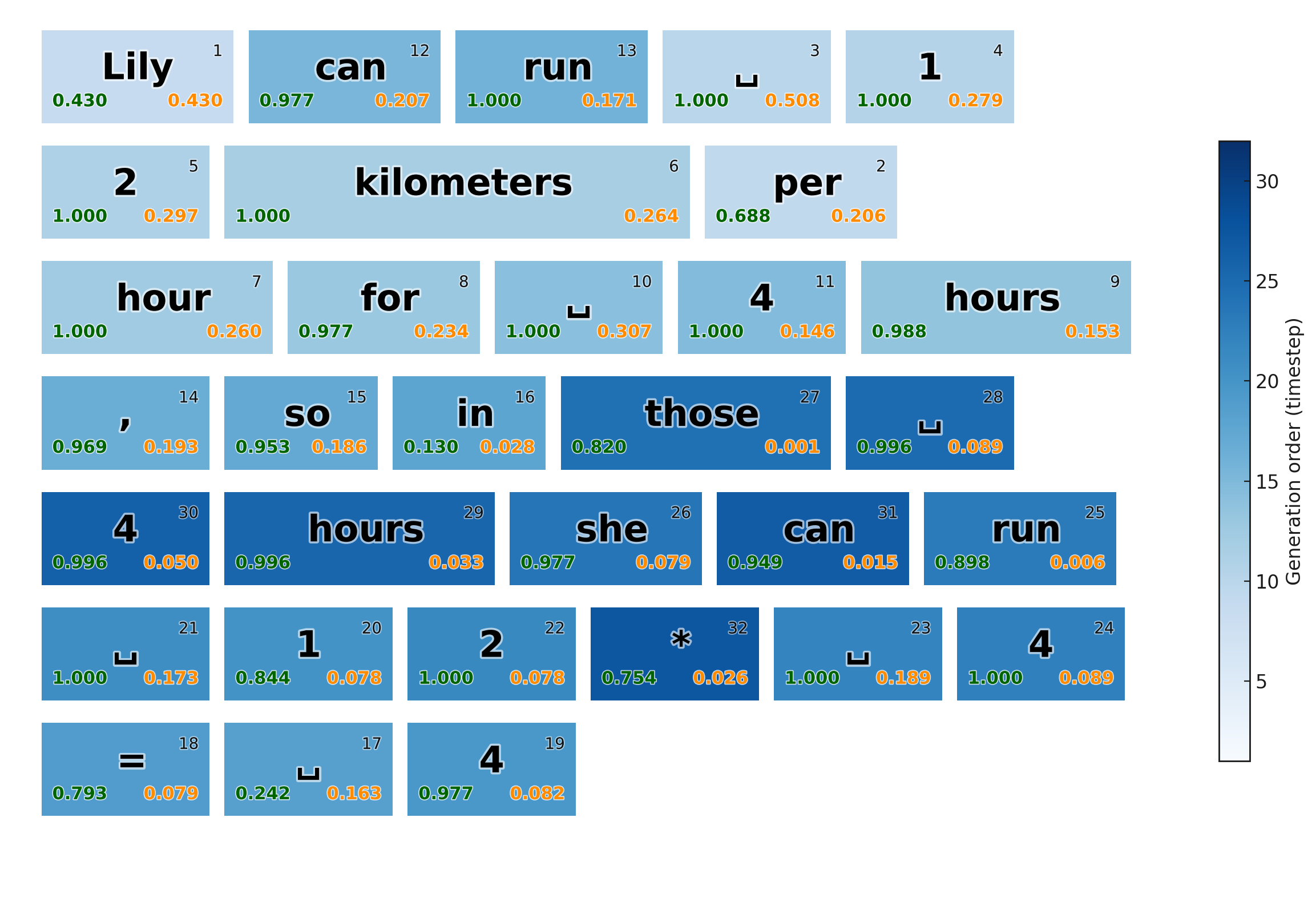
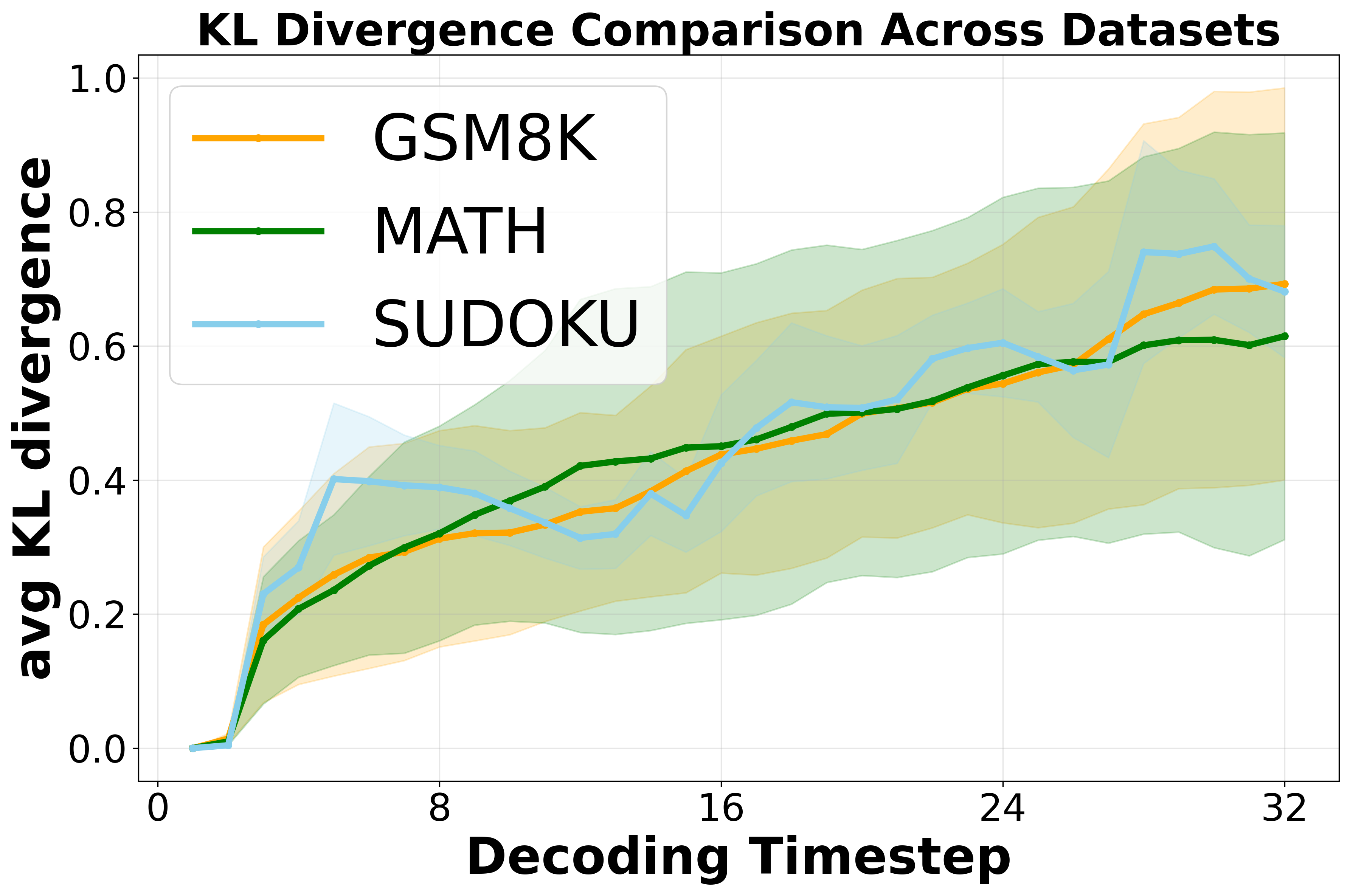
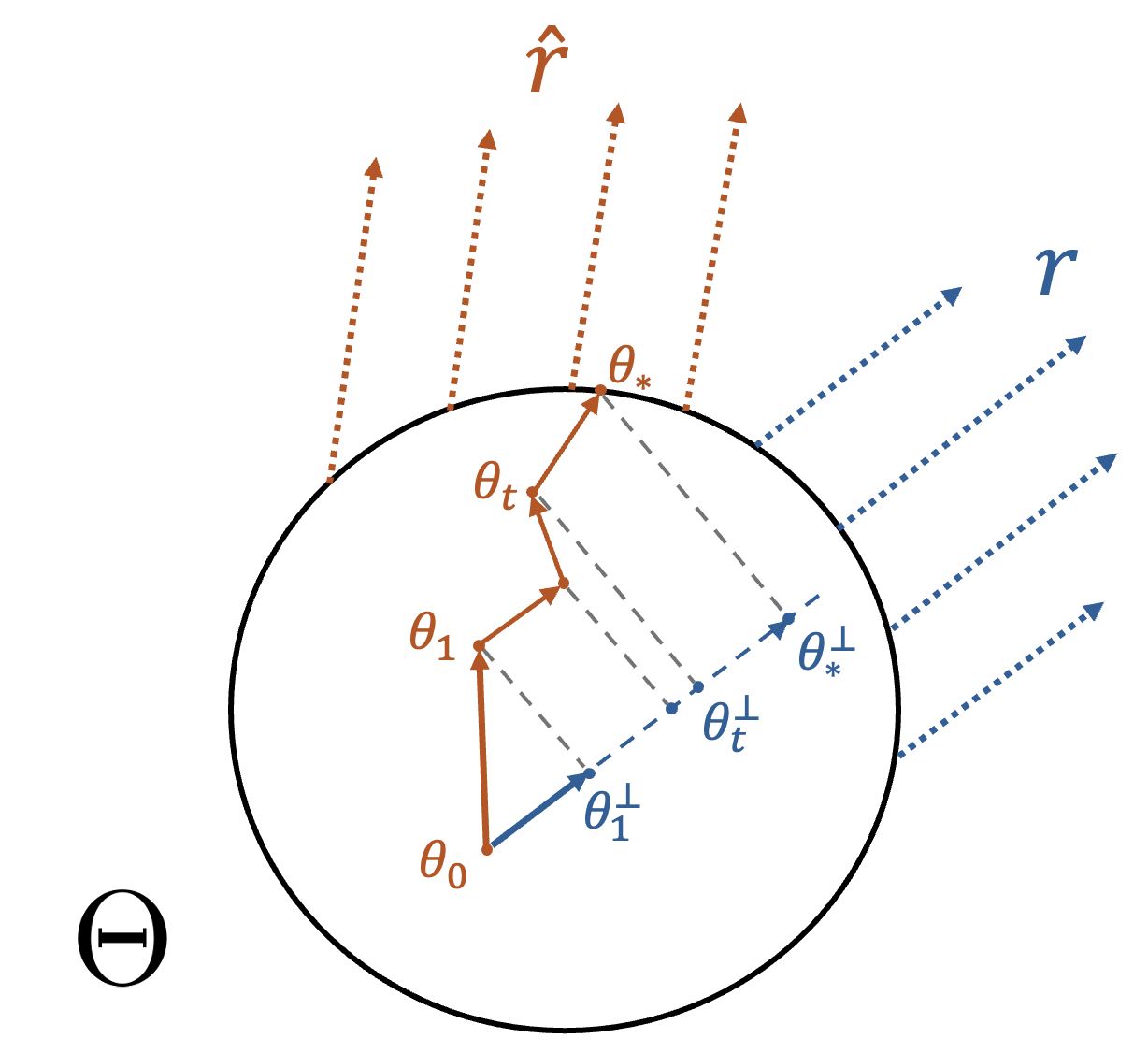
Figure 1: Sample generation and computed likelihoods, illustrating the discrepancy between true and mean-field likelihoods at each unmasking step.
To address this, DiFFPO introduces the Two Times Mean-Field (2MF) approximation, which conditions on both the prompt and a randomly sampled latent at timestep τ. This surrogate policy is provably closer to the true dLLM policy under reasonable monotonicity assumptions. Theoretical guarantees are provided via Pinsker's inequality, bounding the performance gap between the surrogate and true policies.
Off-Policy RL with Importance Sampling
DiFFPO formulates RL post-training as off-policy optimization, using importance sampling to correct for the distribution mismatch between the surrogate and base policies. The final loss objective incorporates the likelihood ratio between the surrogate and base policies, clipped for numerical stability. This enables efficient and theoretically sound RL updates without the need to compute intractable true likelihoods.
Joint Model and Sampler Training
A key contribution is the joint training of the model and the sampler. Instead of using a fixed inference threshold in the EB sampler, DiFFPO parameterizes the threshold as a prompt-dependent function, implemented as a linear head over prompt embeddings. The threshold is treated as an additional token in the RL objective, allowing seamless integration with the model's training dynamics. Gaussian exploration is used for threshold perturbation during training.
Empirical Results
DiFFPO is evaluated on LLaDA-8B-Instruct across GSM8K, Math, Sudoku, and Countdown. The 2MF approximation and importance sampling yield significant improvements over the d1 baseline in both accuracy and effective token usage (NFEs). The gains are most pronounced in planning tasks, where the mismatch in likelihood approximation is more detrimental.
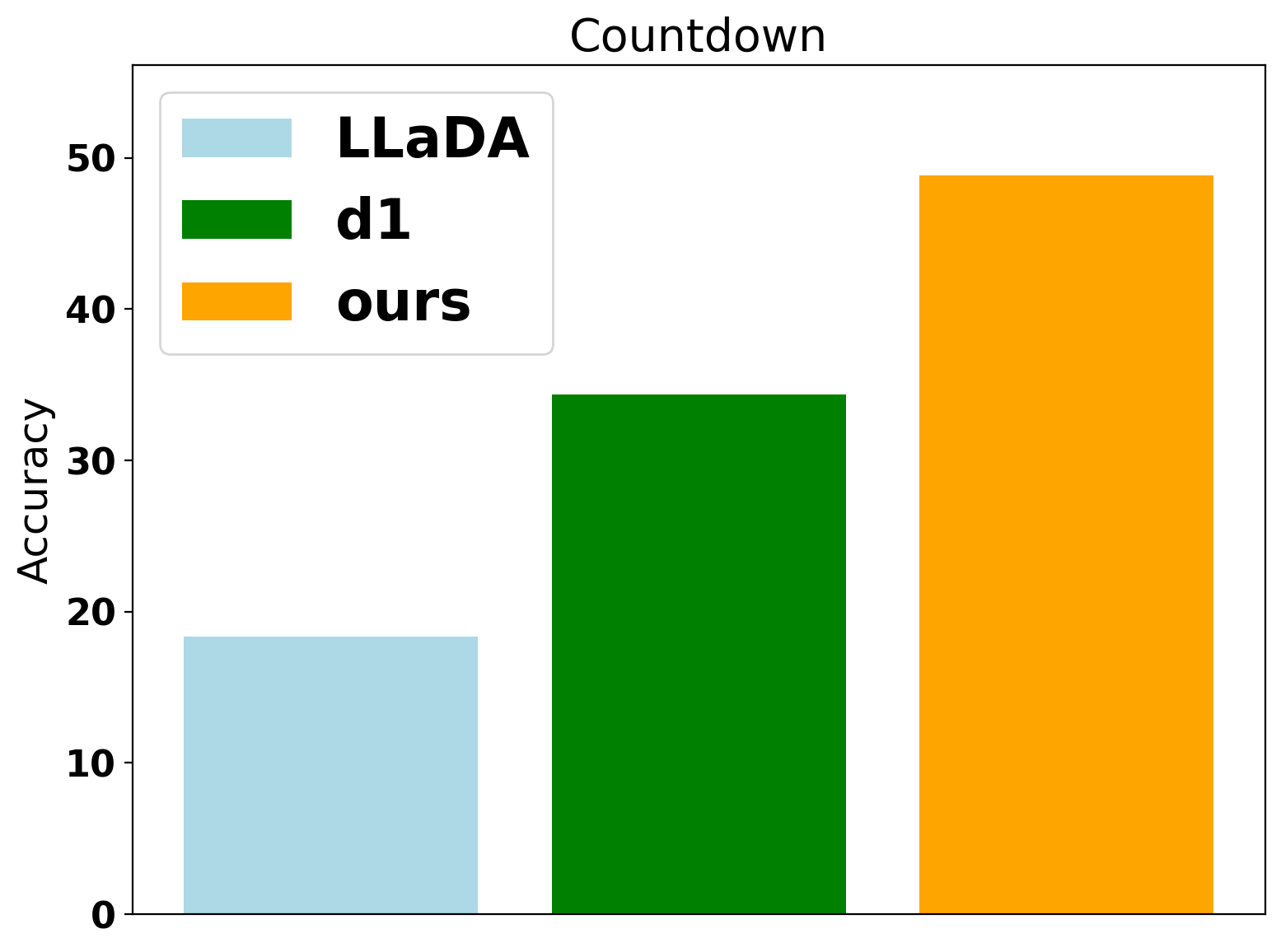
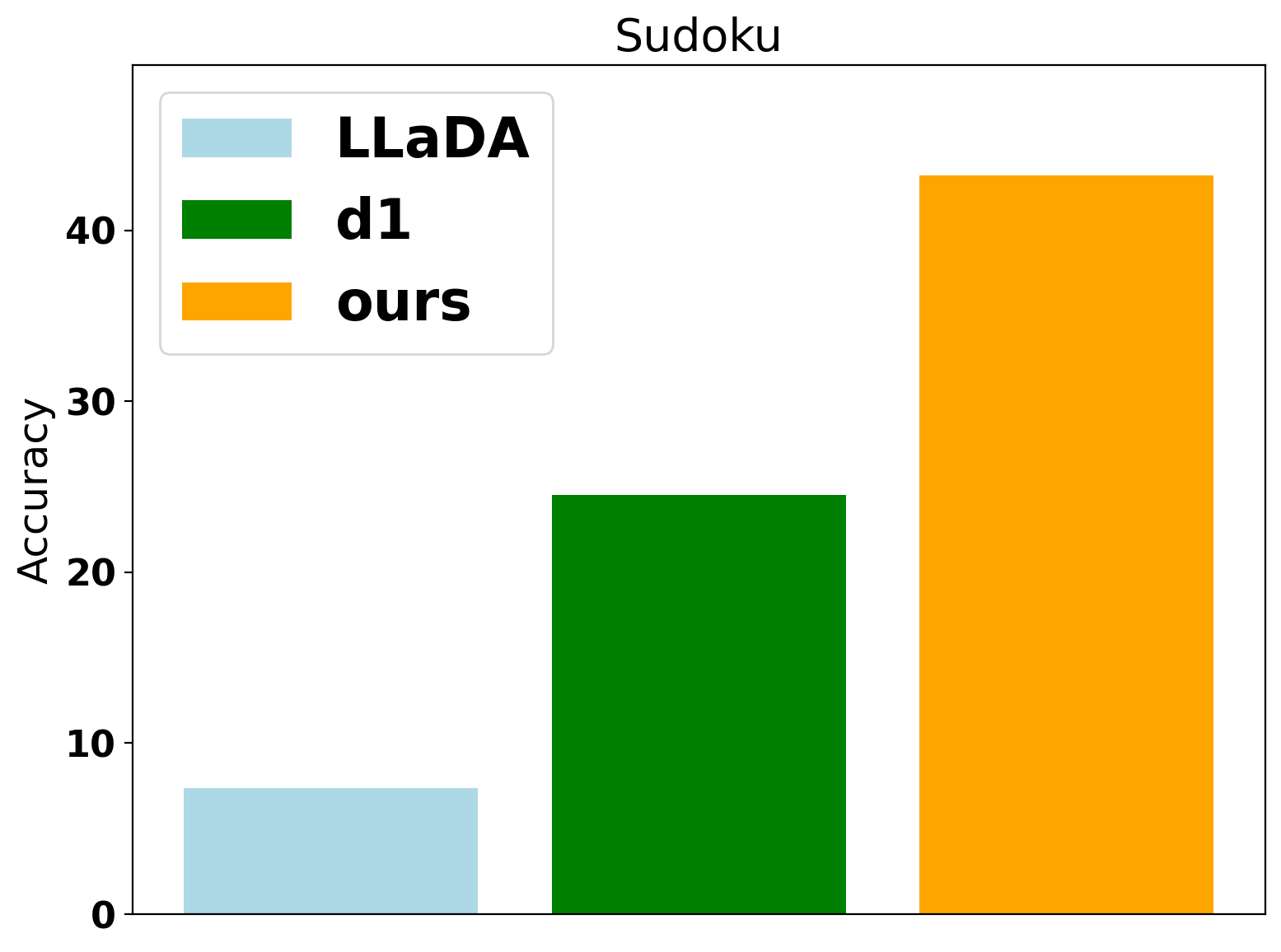
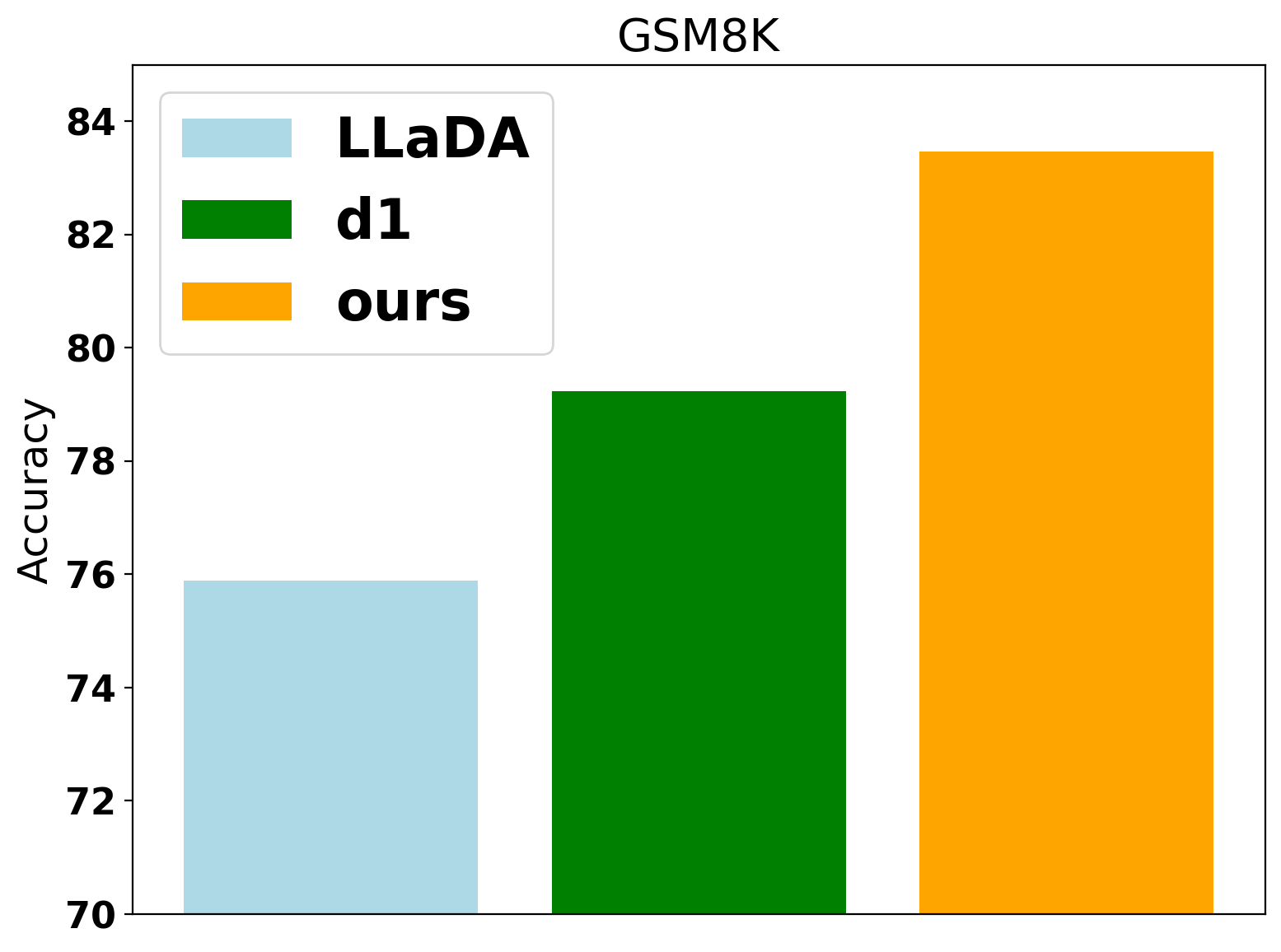
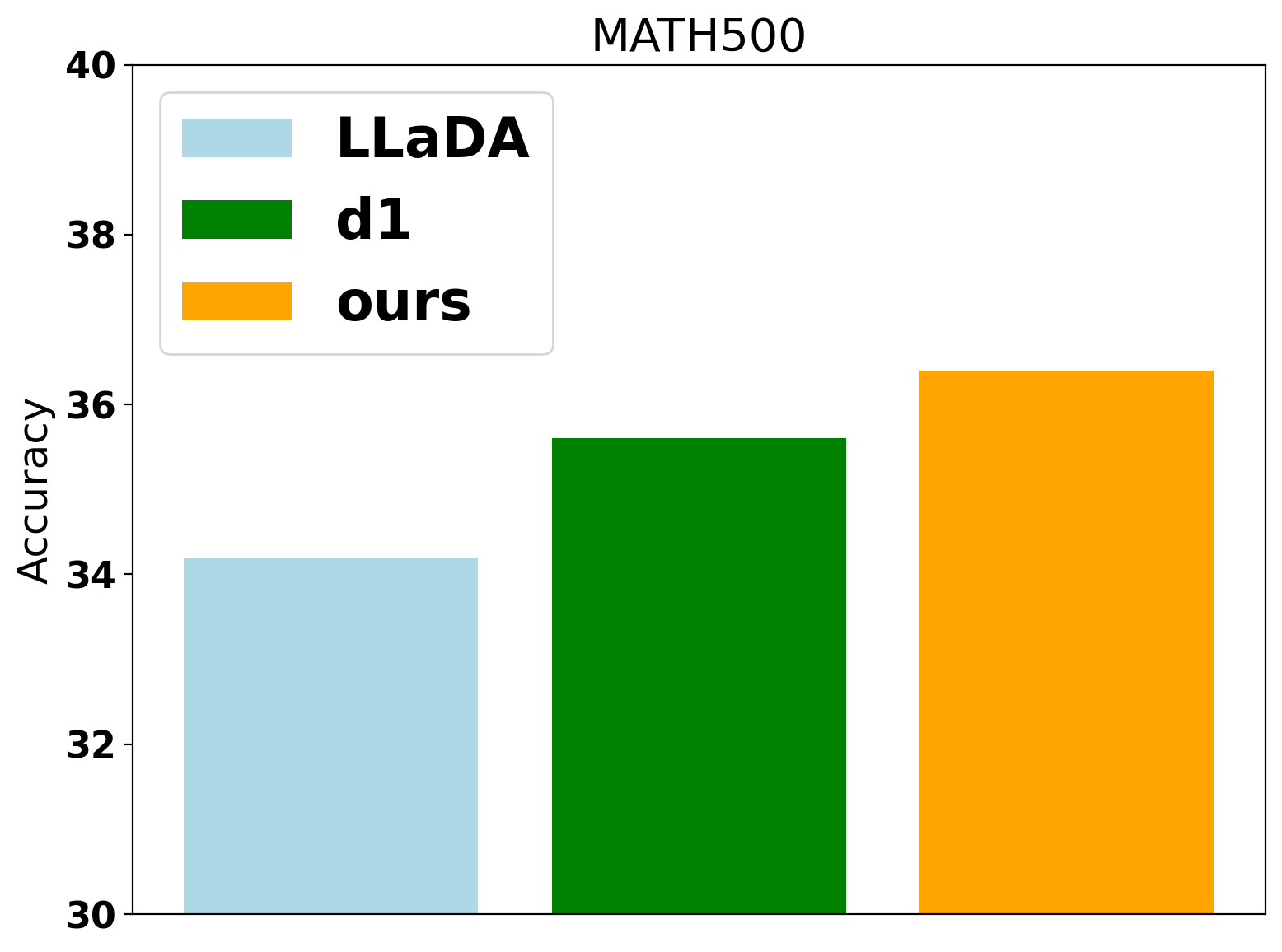
Figure 2: Benchmark results on Countdown, showing DiFFPO's superior accuracy and efficiency compared to baselines.
Inference-Time Compute Frontier
Joint training of the model and sampler further enhances the accuracy/compute Pareto frontier. DiFFPO-trained models achieve higher correctness with fewer NFEs than both fixed-sampler baselines and models trained without sampler adaptation.
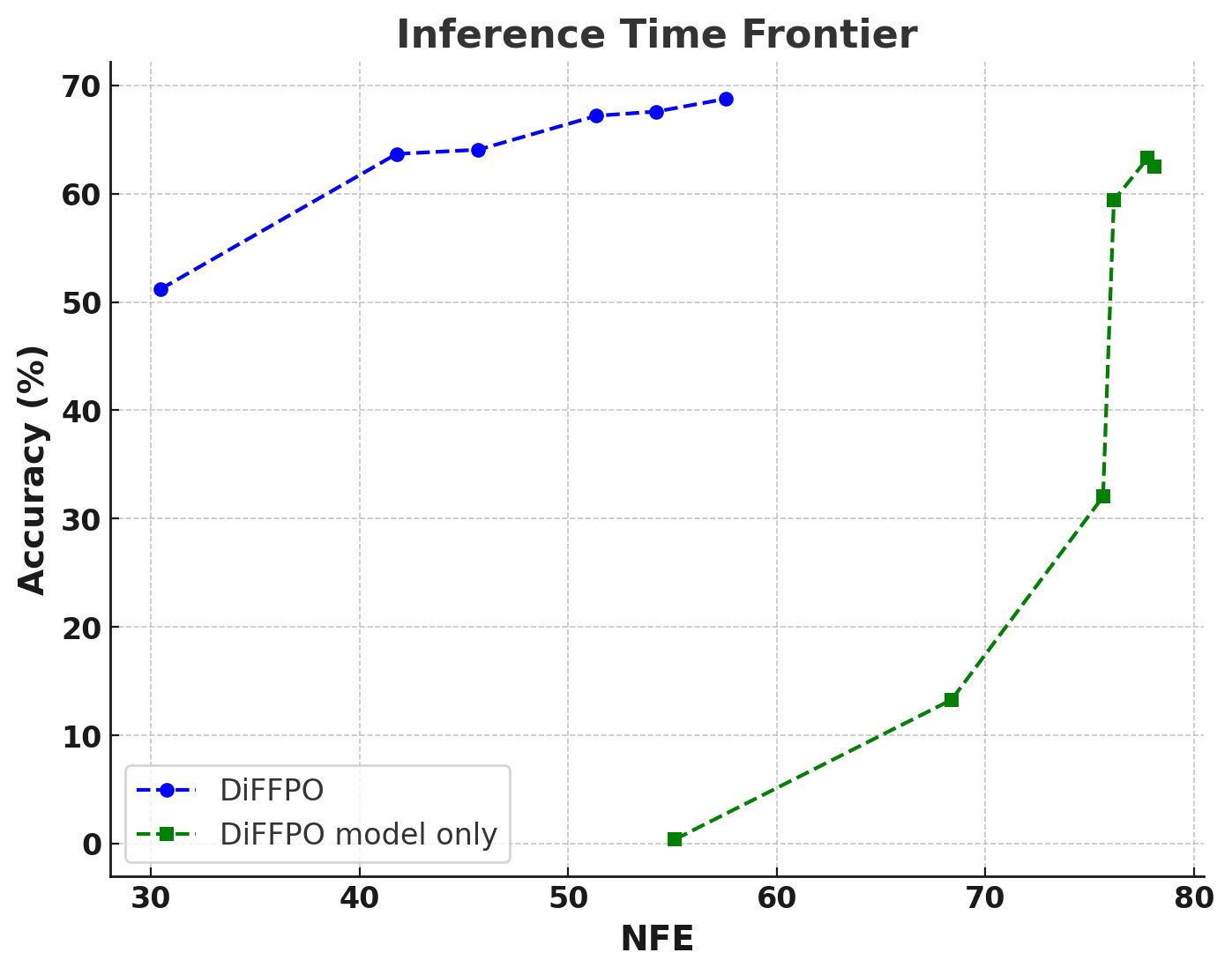
Figure 3: Inference-time frontier for Countdown, comparing DiFFPO with and without sampler training and EB sampler variants.
Ablations and Scaling
Ablation studies on sequence length and sampler configurations confirm the robustness of DiFFPO's improvements. The framework generalizes across different maximum generation lengths and sampler hyperparameters.
Implementation Considerations
- Computational Requirements: DiFFPO leverages LoRA for parameter-efficient fine-tuning, making it feasible to train large dLLMs with moderate GPU resources.
- Likelihood Computation: The surrogate policy enables tractable likelihood estimation, avoiding the memory bottlenecks of full trajectory conditioning.
- Sampler Integration: The prompt-aware threshold head is lightweight and can be implemented as a single linear layer, with exploration noise injected during training.
- Deployment: DiFFPO-trained models can be deployed with adaptive inference thresholds, allowing dynamic trade-offs between accuracy and latency in production.
Theoretical and Practical Implications
DiFFPO advances RL for dLLMs by providing a principled framework for surrogate policy optimization and sampler adaptation. The approach bridges the gap between efficient sampling and high-quality reasoning, making dLLMs more suitable for latency-sensitive applications. The theoretical guarantees on surrogate policy performance offer a foundation for further research on RL in non-autoregressive generative models.
Future Directions
Potential extensions include:
- Generalizing the inference threshold to state- or group-dependent functions for finer control.
- Applying DiFFPO to other open-source dLLMs (e.g., Dream, Mercury) and multimodal diffusion models.
- Integrating recent advances in KV cache acceleration and predictor-corrector sampling for further efficiency gains.
- Investigating the generalization behavior of the learned sampler policies across diverse prompt distributions.
Conclusion
DiFFPO establishes a unified RL framework for post-training masked diffusion LLMs, combining advanced likelihood approximation, off-policy optimization, and joint sampler adaptation. The empirical and theoretical results demonstrate substantial improvements in reasoning accuracy and inference efficiency, pushing the boundaries of scalable RL for dLLMs. The methodology is broadly applicable and sets the stage for future research in efficient, high-performance generative modeling.