- The paper presents a novel end-to-end method that unifies monocular depth and camera pose estimation for scalable 3D point tracking.
- It demonstrates significant improvements by outperforming previous methods by 61.8% in Average Jaccard and 50.5% in 3D position accuracy.
- The fully differentiable pipeline and joint training strategy enable rapid optimization, running 50× faster than many existing techniques.
SpatialTrackerV2: End-to-End 3D Point Tracking from Monocular Videos
SpatialTrackerV2 introduces a feed-forward method for 3D point tracking from monocular videos by unifying monocular depth estimation and camera pose estimation within an end-to-end architecture (2507.12462). This approach decomposes world-space 3D motion into scene geometry, camera ego-motion, and pixel-wise object motion, enabling scalable training across diverse datasets and achieving state-of-the-art performance in 3D tracking and dynamic 3D reconstruction. The method's fully differentiable pipeline and joint training strategy across heterogeneous data allow it to outperform existing 3D tracking methods by 30% and match the accuracy of leading dynamic 3D reconstruction approaches while running 50× faster.
Method Overview
SpatialTrackerV2 adopts a front-end and back-end architecture (Figure 1). The front-end estimates scale-aligned depth and camera poses from the input video, utilizing an attention-based temporal information encoding. The back-end iteratively refines both tracks and poses via joint motion optimization, incorporating a novel SyncFormer module to model 2D and 3D correlations separately.
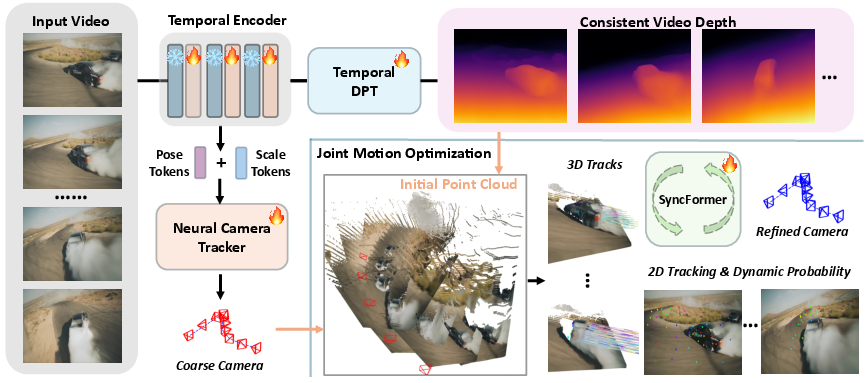
Figure 1: The pipeline architecture, which decomposes 3D point tracking into video depth, ego (camera) motion, and object motion, integrated within a fully differentiable pipeline.
The method decomposes 3D point tracking into video depth, ego (camera) motion, and object motion. The front end leverages a video depth estimator and camera pose initializer, adapted from monocular depth prediction frameworks. A scale-shift estimation module ensures consistency between depth and motion predictions. The back end consists of a Joint Motion Optimization Module, which takes the video depth and coarse camera trajectories as input and iteratively estimates 2D and 3D trajectories, along with trajectory-wise dynamics and visibility scores. This enables an efficient bundle adjustment process for optimizing camera poses in the loop.
The core of the back-end processing lies in the SyncFormer module (Figure 2), which separately models 2D and 3D correlations in two distinct branches connected by cross-attention layers. This design mitigates mutual interference between 2D and 3D embeddings, allowing the model to update representations in the image (UV) space and the camera coordinate space independently. The SyncFormer module takes 2D embeddings, 3D embeddings, and camera poses as input, and updates the 2D trajectories T2d, 3D trajectories T3d, dynamic probabilities pdyn, and visibility scores pvis in every iteration.
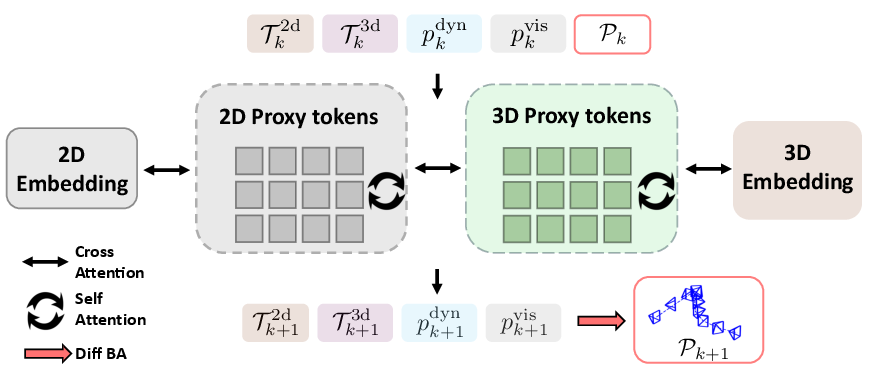
Figure 2: The SyncFormer architecture, which takes previous estimates and their corresponding embeddings as input, iteratively updating them with separate branches for 2D and 3D embeddings that interact via cross-attention.
The iterative process of SyncFormer (Figure 3) demonstrates rapid reprojection error reduction and progressive alignment between 2D tracking results and projections of 3D tracking transformed by camera poses. Bundle adjustment is applied to jointly optimize camera poses as well as the 2D and 3D trajectories.
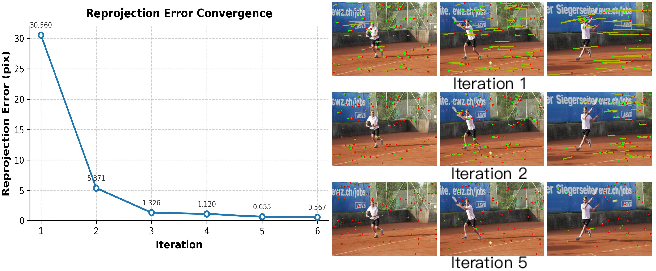
Figure 3: Convergence curve of reprojection error (left) and progressive alignment between 2D tracking results and projections of 3D tracking transformed by camera poses (right).
Training and Evaluation
SpatialTrackerV2 is trained on a large collection of 17 datasets, encompassing posed RGB-D data with and without tracking annotations, as well as pose-only and unlabeled data. This diverse training data enables the model to generalize across various scenarios and improve the robustness of 3D tracking. Evaluations on the TAPVid-3D benchmark show that the method achieves state-of-the-art results in 3D point tracking, surpassing DELTA by 61.8% in Average Jaccard (AJ) and 50.5% in Average 3D Position Accuracy (APD3D). Additionally, the method demonstrates superior performance in dynamic reconstruction, outperforming MegaSAM on most video depth datasets and achieving comparable results on camera pose benchmarks while running 50× faster (Figure 4).


Figure 4: Fused point clouds, camera poses, and 3D point trajectories, showcasing the reconstructed scene geometry and long-term 3D point trajectories in world space.
Results
The TAPVid-3D benchmark results show that SpatialTrackerV2 achieves state-of-the-art performance across various settings, with significant improvements in AJ and APD3D compared to existing methods (Table 1). Ablation studies validate the importance of camera motion decomposition and joint training for improving 3D tracking accuracy.
Video depth evaluation demonstrates that SpatialTrackerV2 outperforms existing approaches on multiple datasets, achieving lower AbsRel and higher δ1.25 compared to other state-of-the-art methods (Table 2). Qualitative comparisons on Internet videos (Figure 5) further showcase the method's ability to achieve more consistent depth and accurate camera poses, indicating superior generalization.

Figure 5: Qualitative comparisons with VGGT on diverse Internet videos, showcasing improved depth consistency and camera pose accuracy.
Ablation Studies
Ablation studies demonstrate that scaling up 3D point tracking to a wider range of data improves performance. Joint training on VKITTI, Kubric, and PointOdyssey datasets contributes to minimizing 3D tracking drifts when the model is trained on new patterns of data. The SyncFormer design effectively lifts tracking into 3D while preserving or improving accuracy in 2D. Ablation of training datasets and loss functions highlights the importance of balancing performance across synthetic and real data to improve the generalizability of video depth prediction (Figure 6).

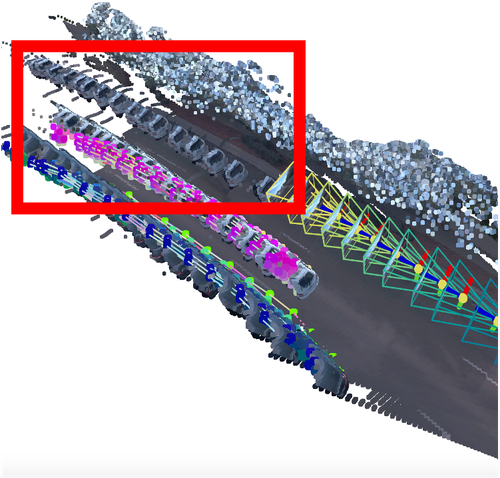



Figure 6: Visual comparison illustrating the influence of joint training on minimizing 3D tracking drifts.
Conclusion
SpatialTrackerV2 presents a scalable and high-performance approach for 3D point tracking in monocular videos. By unifying scene geometry, camera motion, and pixel-wise 3D motion within a differentiable pipeline, the method achieves state-of-the-art results on public benchmarks and demonstrates robust performance on casually captured Internet videos. This research advances real-world motion understanding and contributes to the development of physical intelligence.

