- The paper presents a novel framework that integrates monocular 3D detection and tracking using quasi-dense similarity learning and LSTM-based velocity prediction.
- It leverages motion-aware data association with depth-ordering heuristics to manage occlusions and maintain robust tracking in urban driving scenarios.
- Evaluation on KITTI, nuScenes, and Waymo Open demonstrates significant accuracy improvements over traditional vision-only tracking methods.
Monocular Quasi-Dense 3D Object Tracking
The paper "Monocular Quasi-Dense 3D Object Tracking" (2103.07351) explores a sophisticated framework for 3D object tracking using monocular vision data. It aims to enhance 3D tracking in autonomous driving scenarios by leveraging quasi-dense similarity learning and motion-based trajectory prediction to robustly track object instances over time. The pipeline integrates monocular 3D detection with tracking, refining object associations using depth-ordering heuristics and an LSTM-based velocity learning module. The performance of the proposed technique is evaluated on industry-standard datasets such as KITTI, nuScenes, and Waymo Open.
Introduction and Key Concepts
Monocular vision systems offer cost-effective and scalable solutions for autonomous driving, but they lack depth information which is crucial for 3D tracking. The paper addresses this by generating quasi-dense object proposals and learning instance similarities in a high-dimensional feature space, as seen in (Figure 1). This approach extends conventional sparse learning methods by utilizing a broader set of object proposals to enhance the discriminative power of feature embeddings.
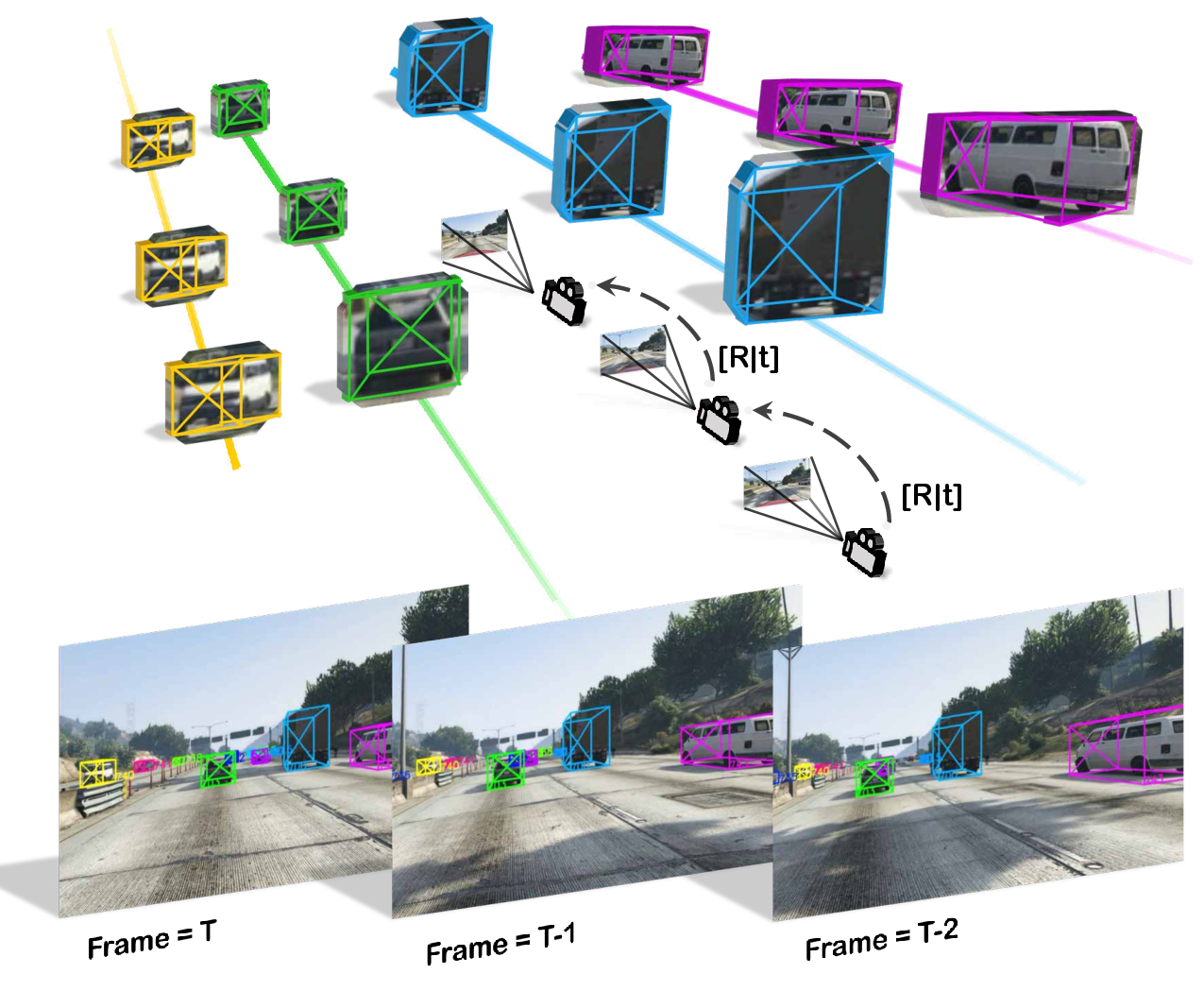
Figure 1: Monocular quasi-dense detection and tracking in 3D. Our dynamic 3D tracking pipeline predicts 3D bounding box association of observed target from quasi-dense object proposals in image sequences captured by a monocular camera with an ego-motion sensor.
The method uses instance-level feature embeddings combined with motion-aware association and depth-ordering matching to handle occlusions and reappearances of tracked objects. This is particularly useful in urban driving scenarios where objects frequently move out of the camera's field of view.
Framework Architecture
The proposed framework processes each monocular frame to estimate and track regions of interest (RoIs) in 3D using an online approach (Figure 2). For each RoI, the framework estimates the depth, orientation, dimensions, and projects the 3D center using a multi-head network. It then associates the features across frames using motion-aware data association and depth-ordering matching.
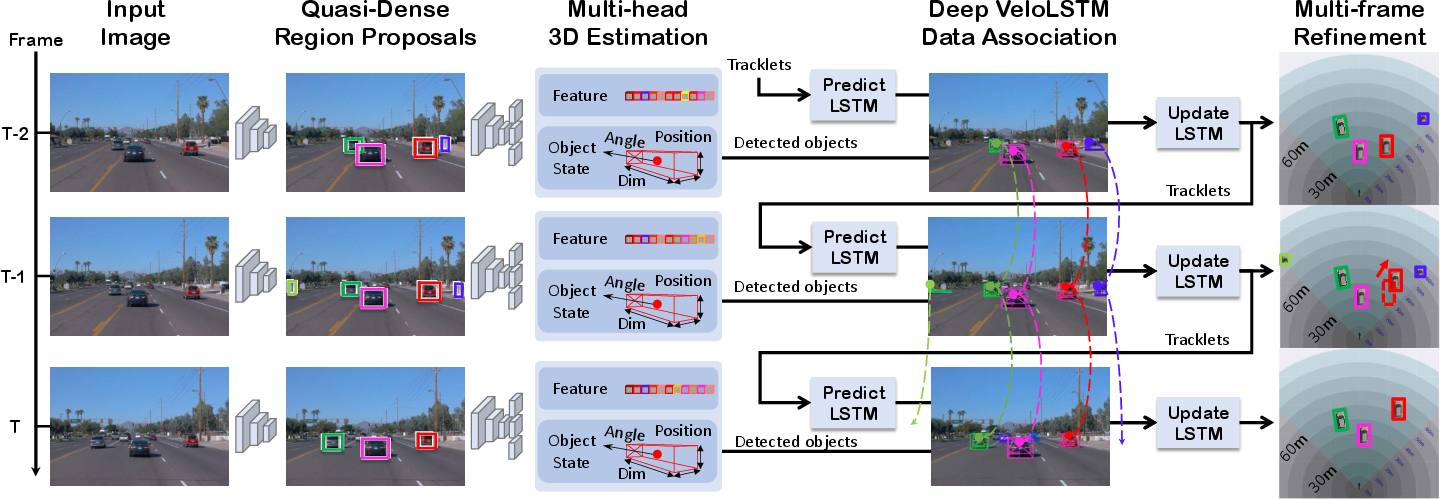
Figure 2: Overview of our monocular quasi-dense 3D tracking framework. Our online approach processes monocular frames to estimate and track RoIs in 3D (a). For each RoI, we learn the 3D layout estimation and instance-level feature embedding (b). With the 3D layout, our VeloLSTM helps to predict object states, and our 3D tracker produces robust linking across frames leveraging motion-aware association and depth-ordering matching (c). VeloLSTM further refines the 3D estimation by fusing object motion features of the previous frames (d).
Motion-Based Data Association
The data association problem is addressed using a weighted bipartite matching algorithm, which balances appearance, location, and velocity correlations to associate detected object states across frames. This approach is robust to occlusions and overlaps, leveraging the learned instance features along with 3D spatial data to improve tracking accuracy.
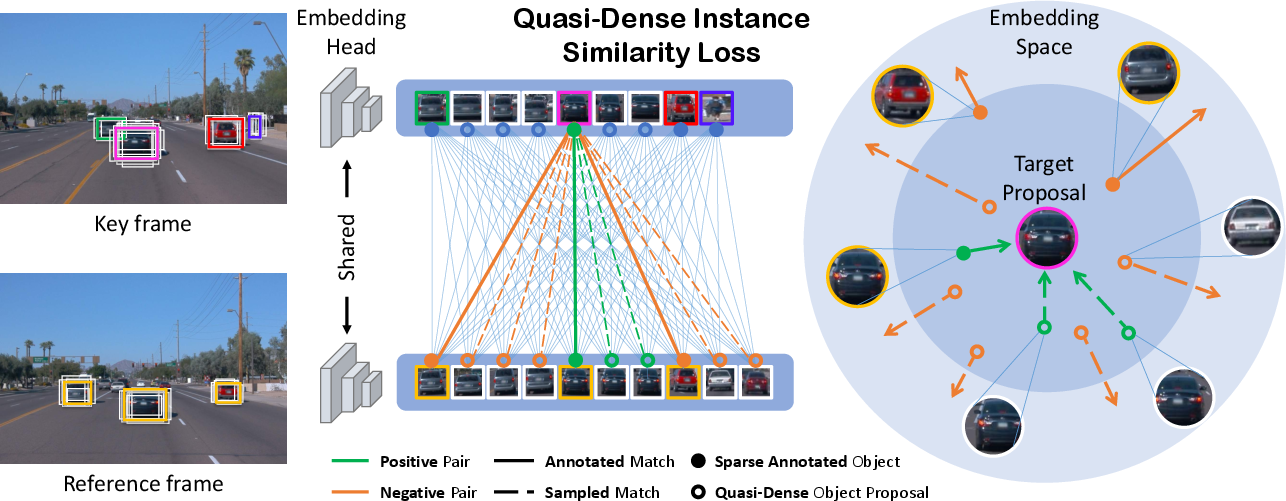
Figure 3: The illustration of the quasi-dense similarity learning. We leverage quasi-dense object proposals to train a discriminative feature space by comparing the region proposal pairs between key frames and reference frames.
Additionally, a motion-aware association scheme (Figure 4) enables the system to maintain object trajectories even through periods of occlusion, capitalizing on the LSTM-based module to predict velocity, orientation, and dimension updates.
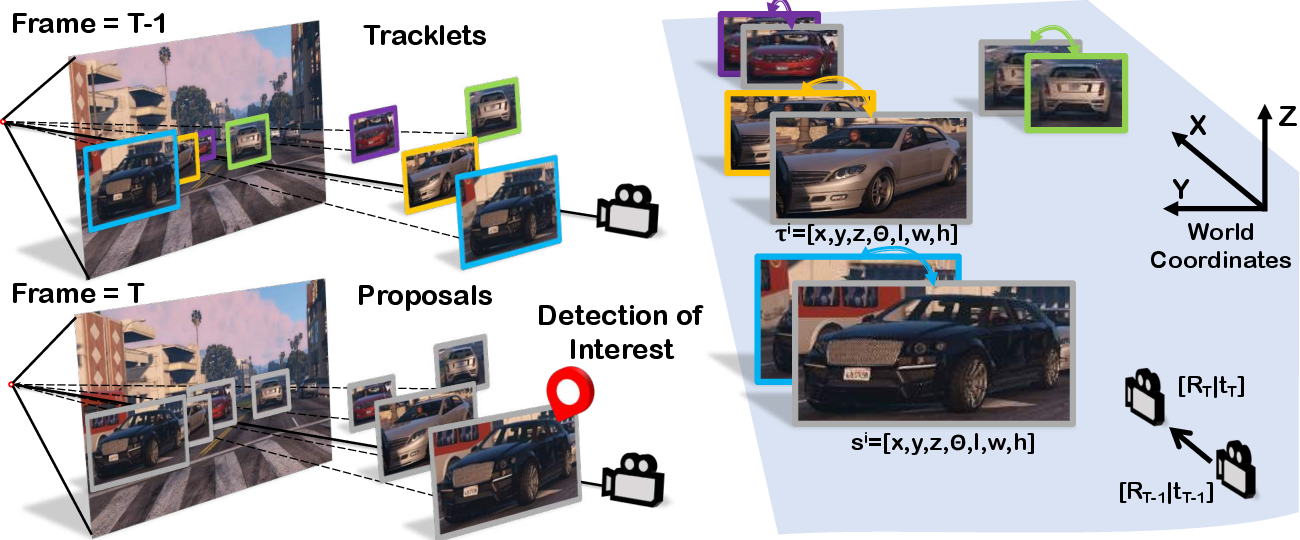
Figure 4: Illustration of depth-ordering matching. Given the tracklets and detections, we sort them into a list by depth order.
Evaluation and Results
The framework is tested on synthetic datasets and real-world benchmarks, demonstrating robustness in urban-driving scenarios. Notably, it provides substantial improvements over other vision-only methods in the nuScenes tracking challenge, establishing a baseline with significant accuracy improvements.
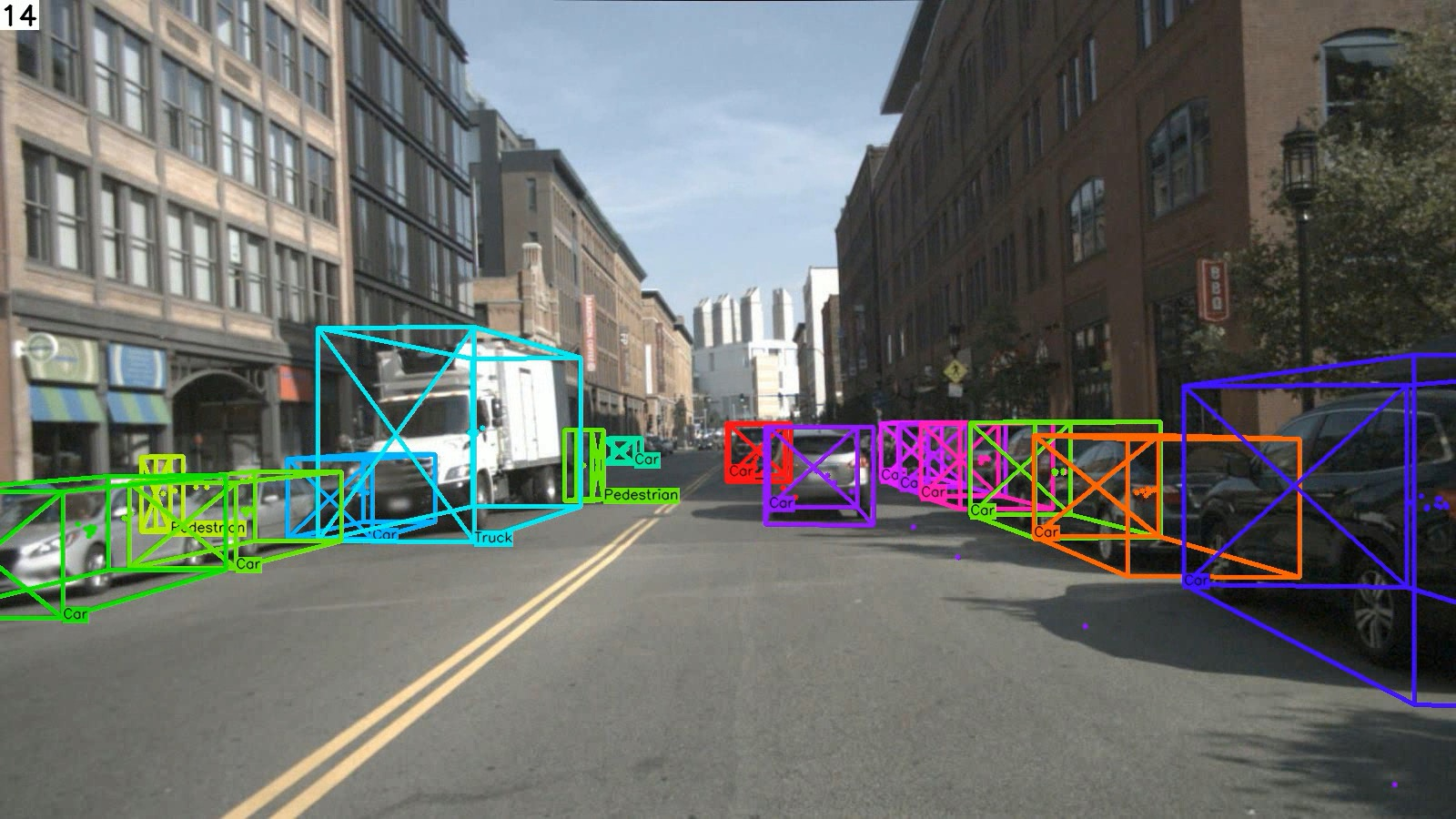
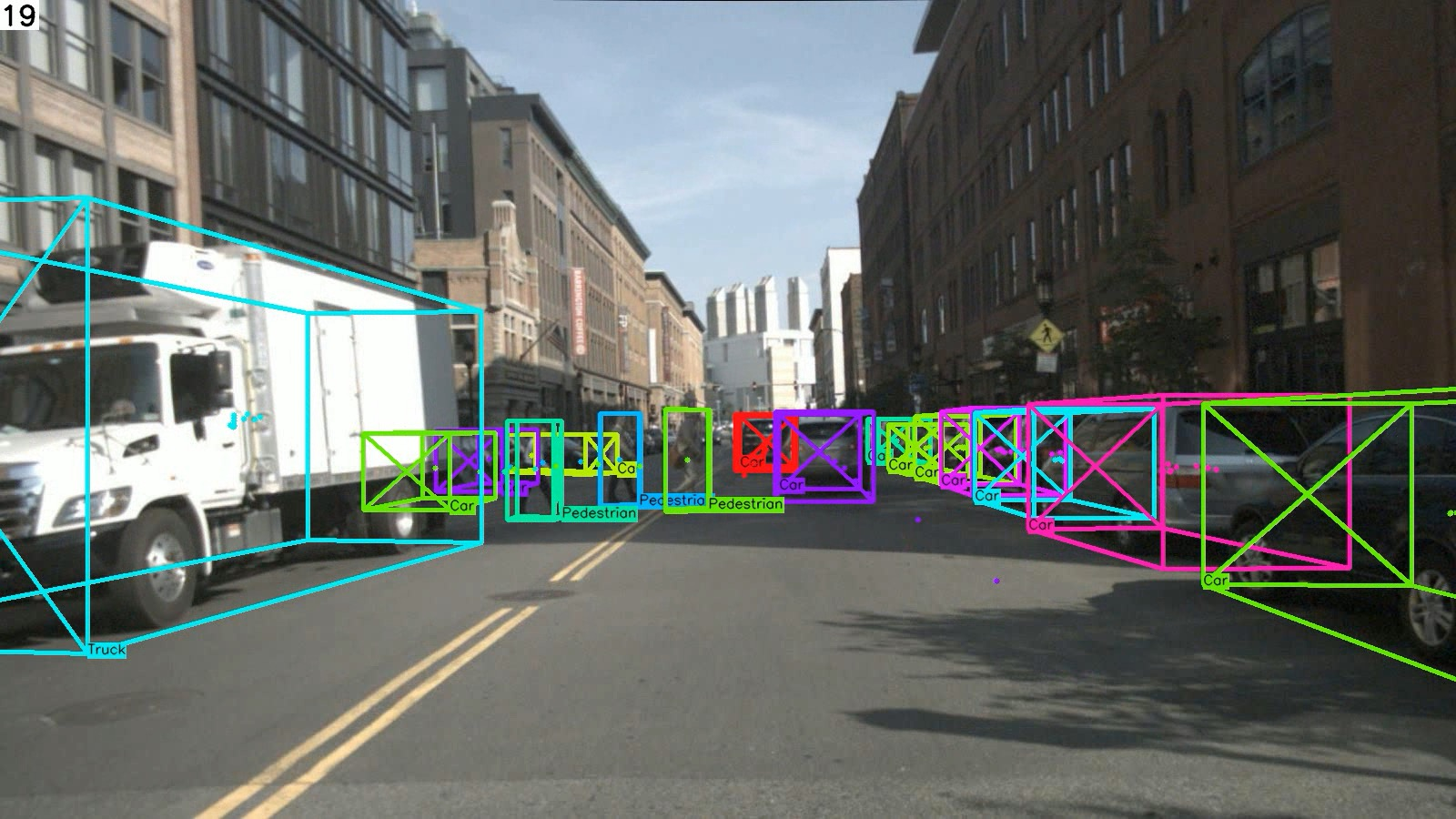
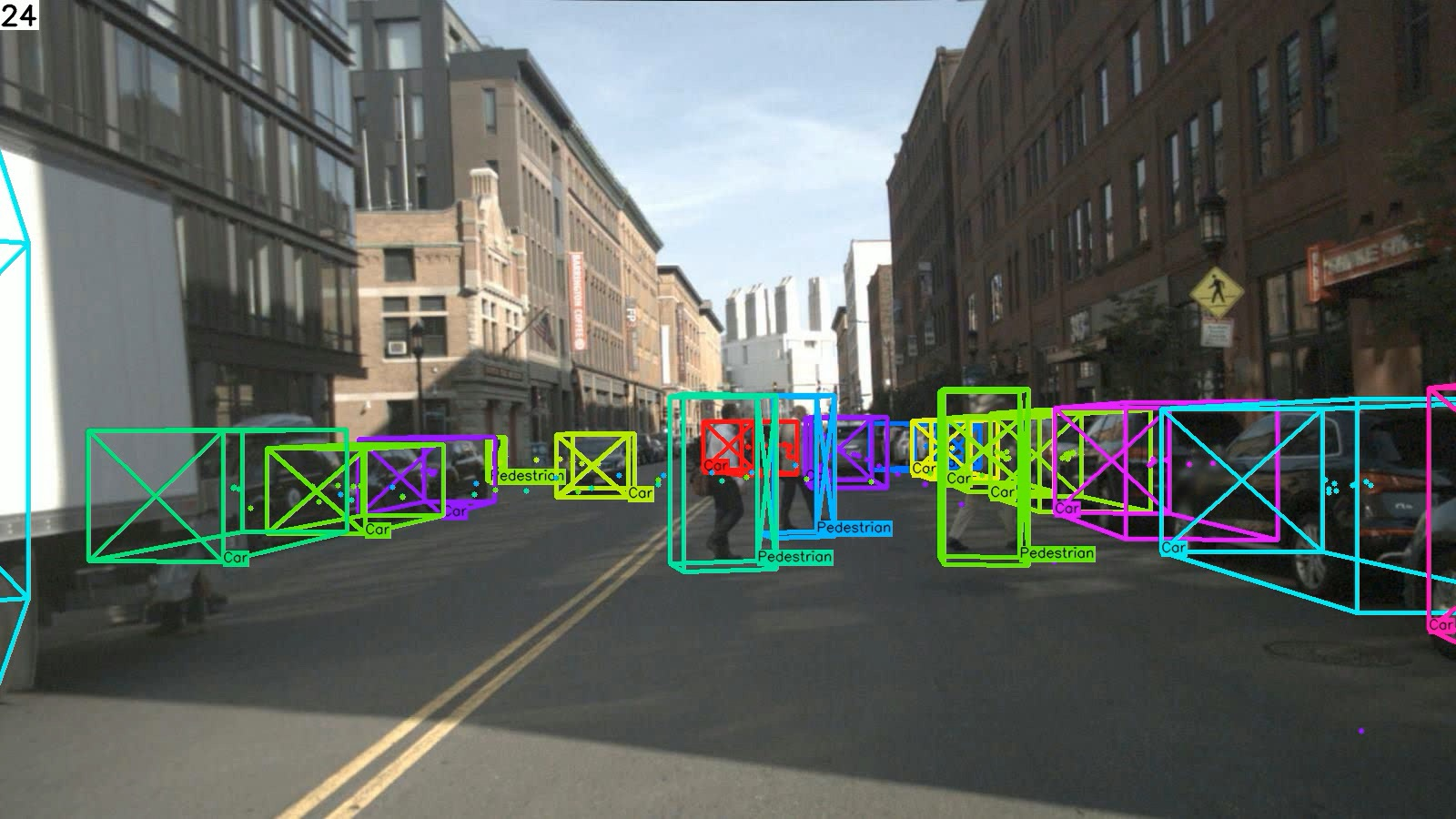

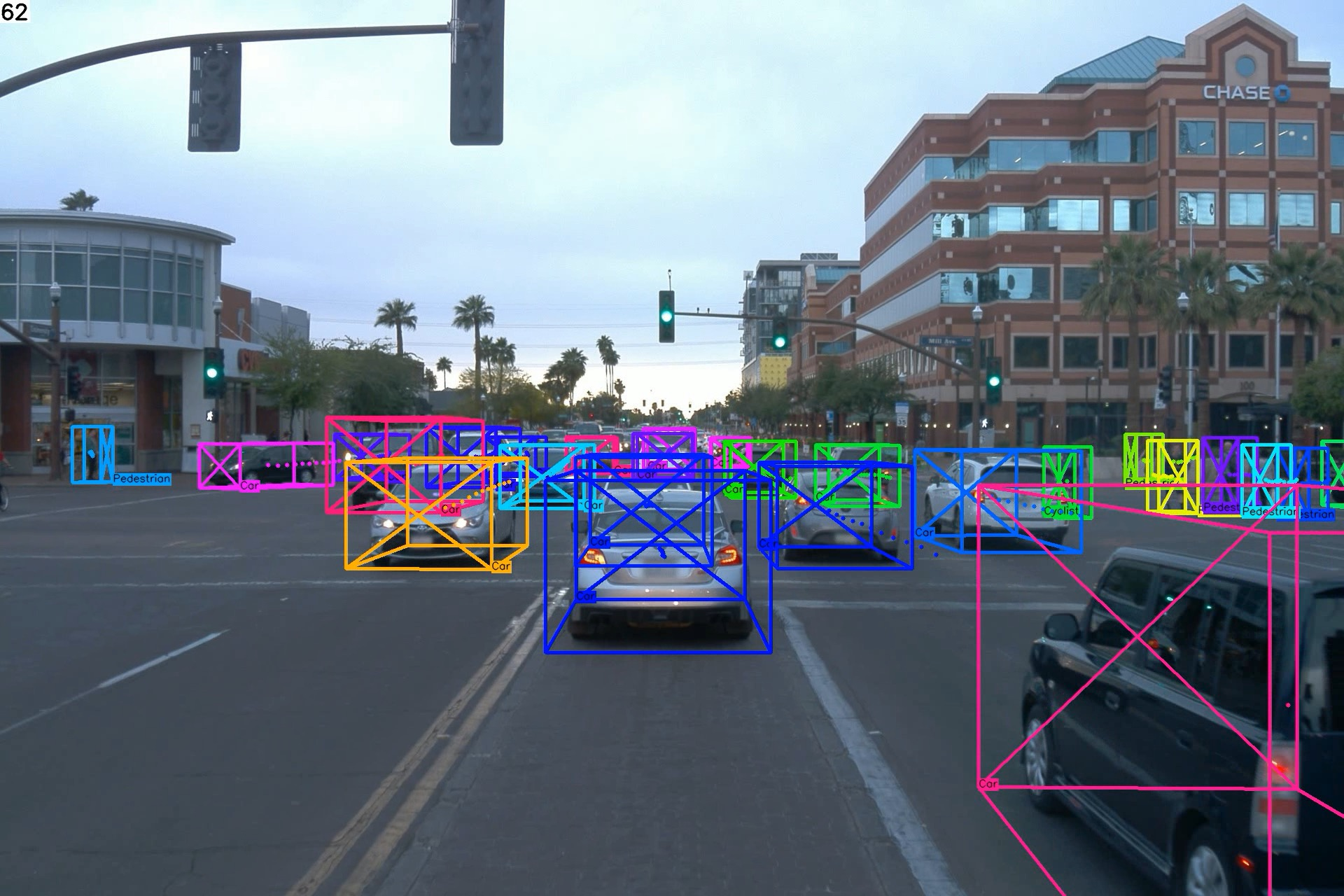
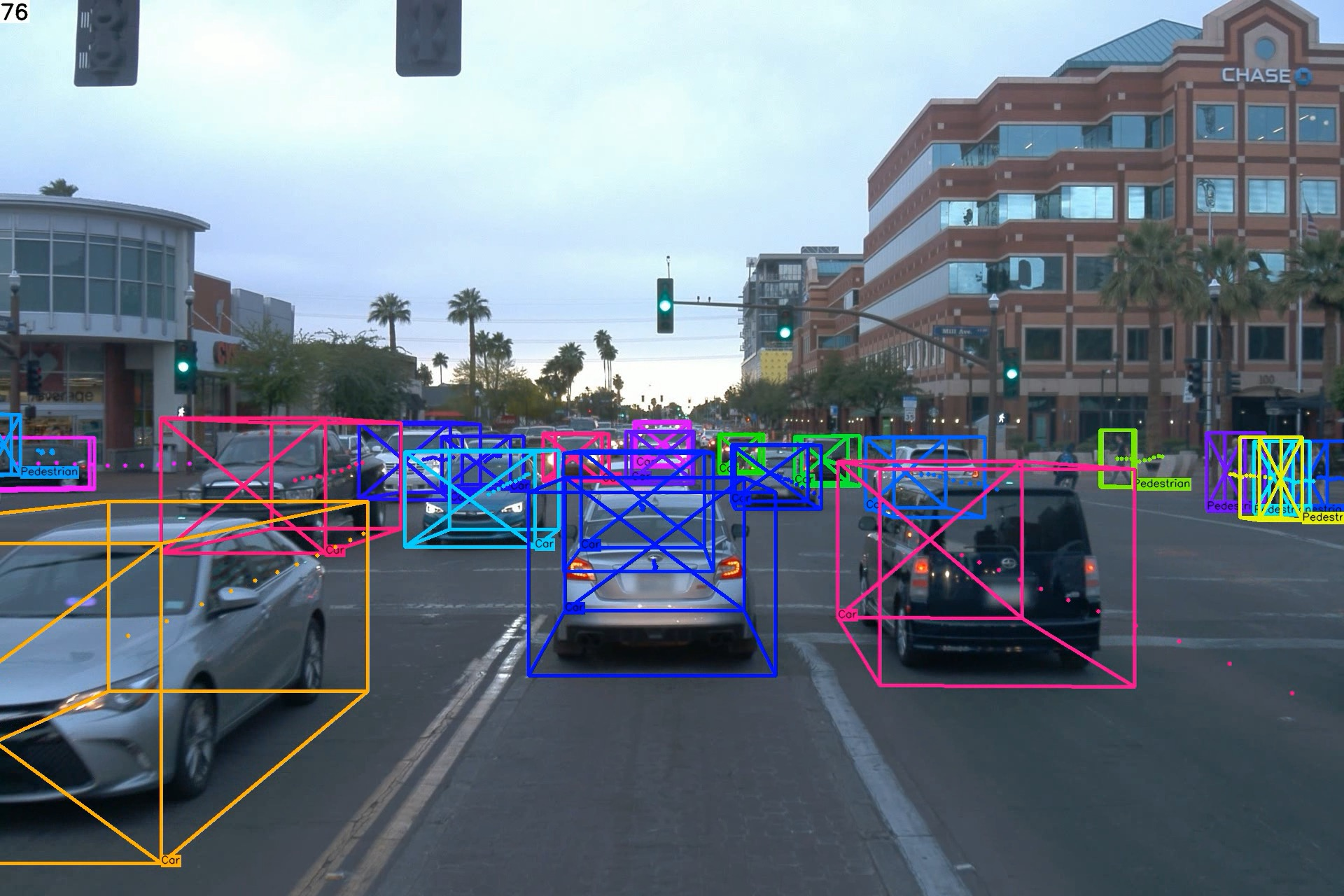
Figure 5: Qualitative results on testing set of nuScenes and Waymo Open datasets. Our proposed quasi-dense 3D tracking pipeline estimates accurate 3D extent and robustly associates tracking trajectories from a monocular image.
Implications and Future Directions
The integration of quasi-dense similarity learning into 3D tracking presents a promising direction for autonomous driving technologies, providing insights into how monocular vision can be effectively utilized for real-time object tracking. Future research could explore enhancements that incorporate additional sensor modalities or refine the deep learning models to further improve tracking accuracy and computational efficiency.
Conclusion
The "Monocular Quasi-Dense 3D Object Tracking" paper delivers a robust framework to tackle the complexities of 3D tracking using monocular vision, achieving impressive results across challenging benchmarks. By leveraging quasi-dense similarity learning and motion models, it sets a valuable foundation for further exploration in the field of autonomous driving and object tracking.

