Distributional Random Forests for Complex Survey Designs on Reproducing Kernel Hilbert Spaces
Published 9 Dec 2025 in stat.ME and stat.ML | (2512.08179v1)
Abstract: We study estimation of the conditional law $P(Y|X=\mathbf{x})$ and continuous functionals $Ψ(P(Y|X=\mathbf{x}))$ when $Y$ takes values in a locally compact Polish space, $X \in \mathbb{R}p$, and the observations arise from a complex survey design. We propose a survey-calibrated distributional random forest (SDRF) that incorporates complex-design features via a pseudo-population bootstrap, PSU-level honesty, and a Maximum Mean Discrepancy (MMD) split criterion computed from kernel mean embeddings of Hájek-type (design-weighted) node distributions. We provide a framework for analyzing forest-style estimators under survey designs; establish design consistency for the finite-population target and model consistency for the super-population target under explicit conditions on the design, kernel, resampling multipliers, and tree partitions. As far as we are aware, these are the first results on model-free estimation of conditional distributions under survey designs. Simulations under a stratified two-stage cluster design provide finite sample performance and demonstrate the statistical error price of ignoring the survey design. The broad applicability of SDRF is demonstrated using NHANES: We estimate the tolerance regions of the conditional joint distribution of two diabetes biomarkers, illustrating how distributional heterogeneity can support subgroup-specific risk profiling for diabetes mellitus in the U.S. population.
The paper introduces SDRF, integrating survey-calibrated tree ensembles with RKHS embeddings to estimate conditional distributions under complex survey designs.
It employs design-aware resampling and PSU-level honesty to achieve consistent, bias-reduced estimates with provable variance decay.
Simulation studies and NHANES case analyses demonstrate SDRF's capacity to capture high-dimensional heterogeneity, guiding more accurate inference in public health research.
Distributional Random Forests for Complex Survey Designs via Kernel Mean Embeddings
Introduction and Problem Significance
This work provides a comprehensive treatment of nonparametric conditional distribution estimation under complex survey designs, combining survey-calibrated tree ensembles with reproducing kernel Hilbert space (RKHS) embeddings. The motivation centers on the increasing demand for predictive and distributional machine learning tools that provide valid inference in population-based studies—settings rife with sampling dependencies, stratification, and heterogeneous inclusion probabilities. Standard random forests and deep learning models, which assume independent and identically distributed data, misrepresent uncertainty and bias statistical functionals when naively applied to survey data. Traditional survey estimators, conversely, focus narrowly on means or low-complexity summaries and are ill-suited for joint, high-dimensional, or non-Euclidean targets.
The authors define estimation targets as general functionals Ψ(P(Y∣X=x))—including conditional distribution functionals, cross-moments, and tolerance regions—where Y may reside in a general Polish metric space.
Pseudo-population Design-aware Bagging: Bootstrap resampling aligns with the finite-population structure, preserving first and higher order inclusion probability properties. The resampling weights (multipliers) enforce design regularity and stability across resampled sets.
PSU-level Honesty and Node Estimation: Splitting/estimation separation is enforced at the primary sampling unit (PSU) level, mitigating intra-cluster dependence in both partitioning and prediction.
Kernel Mean Embedding (KME) Split Criterion: Node-wise splitting decisions maximize the empirical Maximum Mean Discrepancy (MMD) between design-weighted, kernel-embedded empirical distributions in child nodes. The MMD, under characteristic and universal kernels, metrizes weak distribution convergence and enables distributional learning tasks beyond mean regression.
Algorithmic regularization—via minimal node sizes, effective sample size controls, and geometric constraints on leaf cells—enforces consistency and precludes degeneracies in highly stratified or weighted samples.
Theoretical Results
The main theoretical contributions include:
Uniform Design Consistency in RKHS Metrics: Under regularity on the design, kernel, and tree partitions, it is shown that the SDRF estimator of the conditional law converges uniformly (in MMD) to the finite-population and super-population (model-based) targets. The corresponding plug-in estimator for a smooth functional Ψ inherits this consistency.
Variance Reduction via Structured Resampling: The variance of the forest predictor decays at rate O(M−1/2) in the number of bootstrap replicates, with explicit decomposition into design, algorithmic, and resampling terms. The analysis precisely quantifies the diminishing returns of resampling depth versus effective sample size at deep or highly weighted leaves.
Split Criterion Stability and Tree Consistency: The local design consistency of split selection (empirical MMD criterion) is demonstrated, elucidating how partition regularity and multiplier behavior lead to asymptotically optimal splits relative to the finite population.
Simulation Results
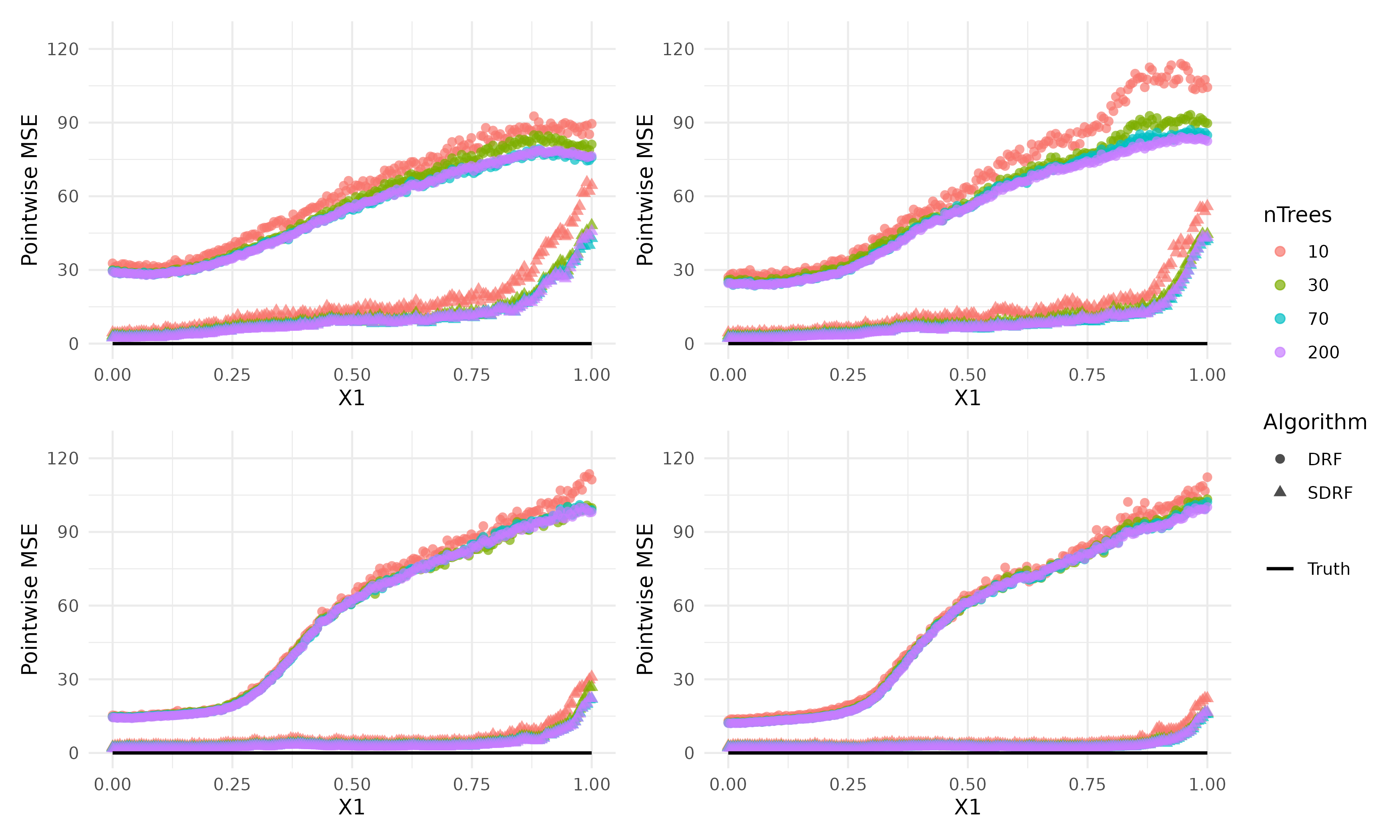
Simulations mimic multistage, stratified survey designs, evaluating finite-sample MMD convergence and prediction error properties. Comparisons are made to an unweighted Distributional Random Forest (DRF; which ignores the survey design), with key numerical findings:
SDRF MSE and RMSE decrease strictly with both the population/sample size N and the number of trees B, manifesting uniform convergence and negligible bias in the estimate of E[Y1∣X1].
The DRF (design-ignorant baseline) exhibits a pronounced MSE floor, driven by persistent bias that does not attenuate with N or B, highlighting the statistical error and bias cost of ignoring survey design.
Figure 1: Pointwise mean square error (MSE) of E[Y1∣X1=x1] from SDRF and DRF, visualizing uniform MSE decay only for SDRF.
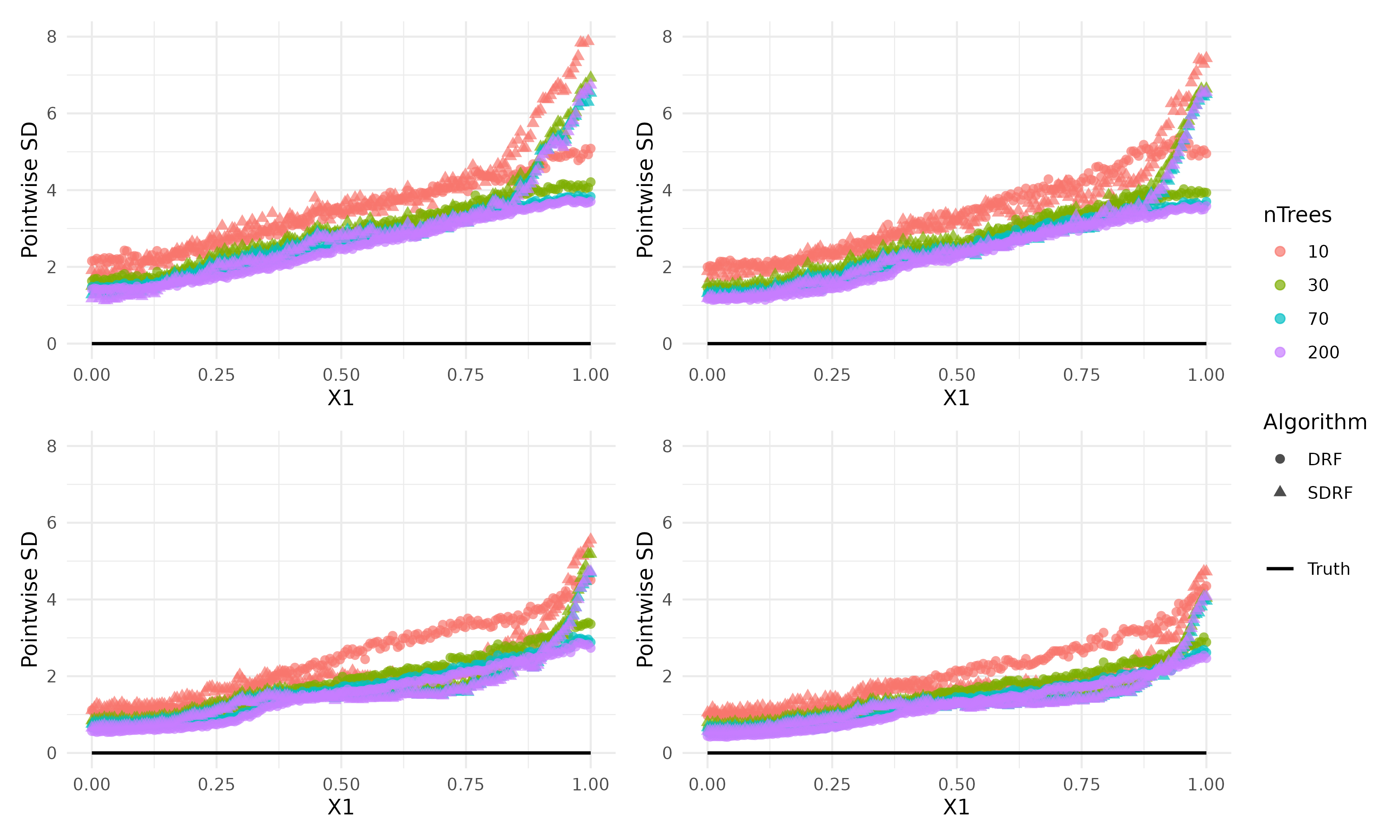
The variance of SDRF predictions is comparable to DRF and does not inflate due to the design-aware resampling (Figure 2), emphasizing the algorithm’s statistical efficiency.
Figure 2: Pointwise standard error (SD) of the estimator E[Y1∣X1] for SDRF and DRF, illustrating comparable variability.
Case Study: NHANES and Multivariate Tolerance Regions
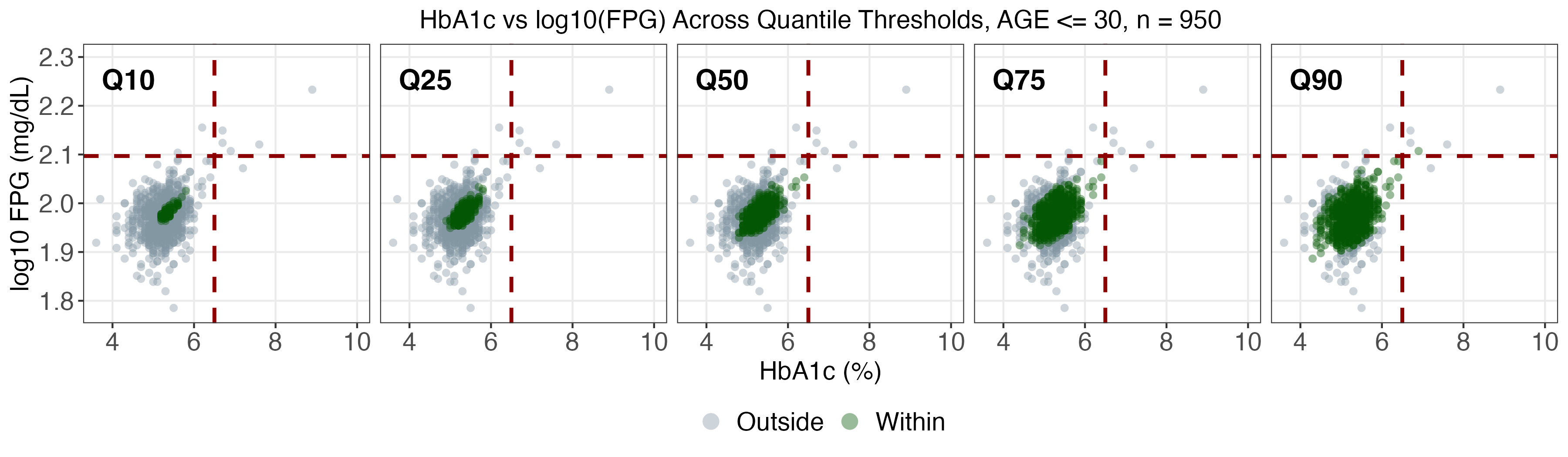
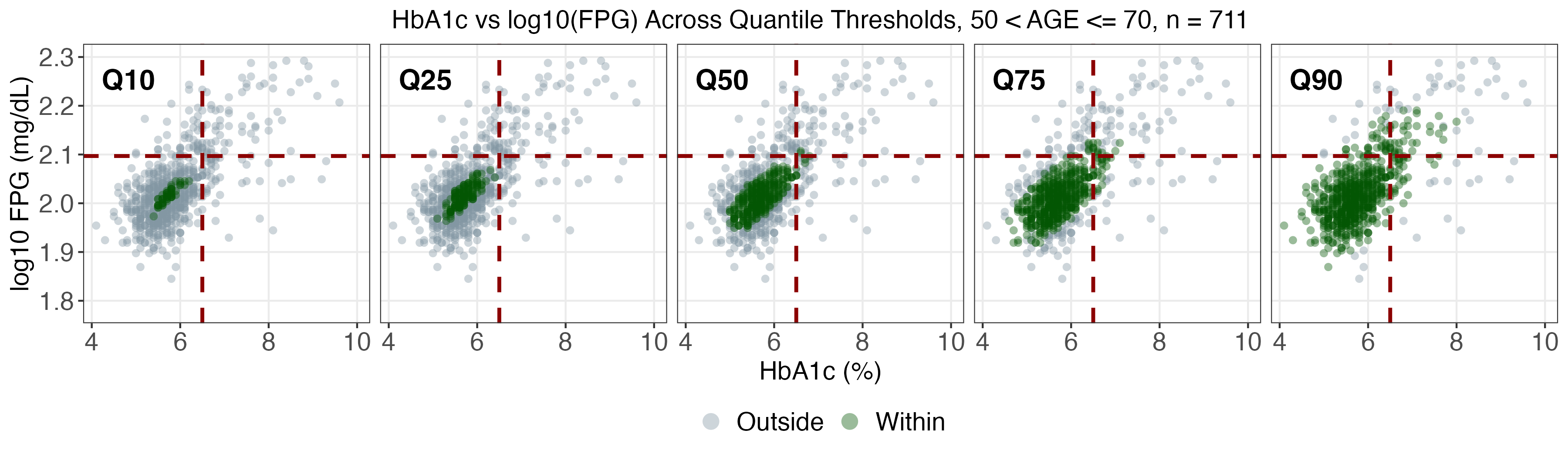
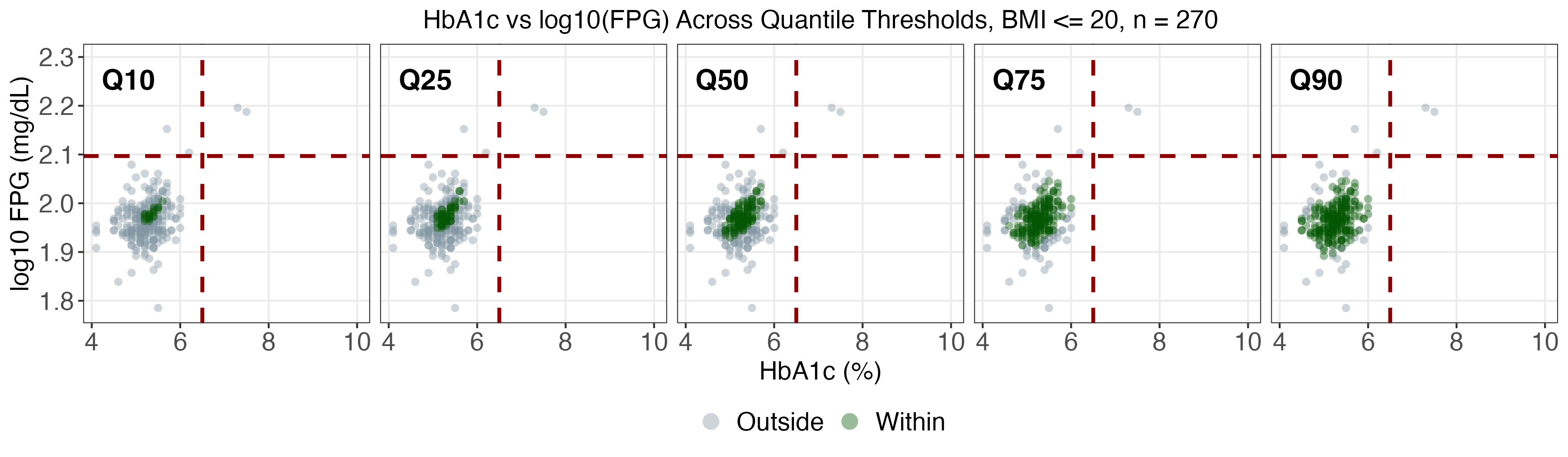
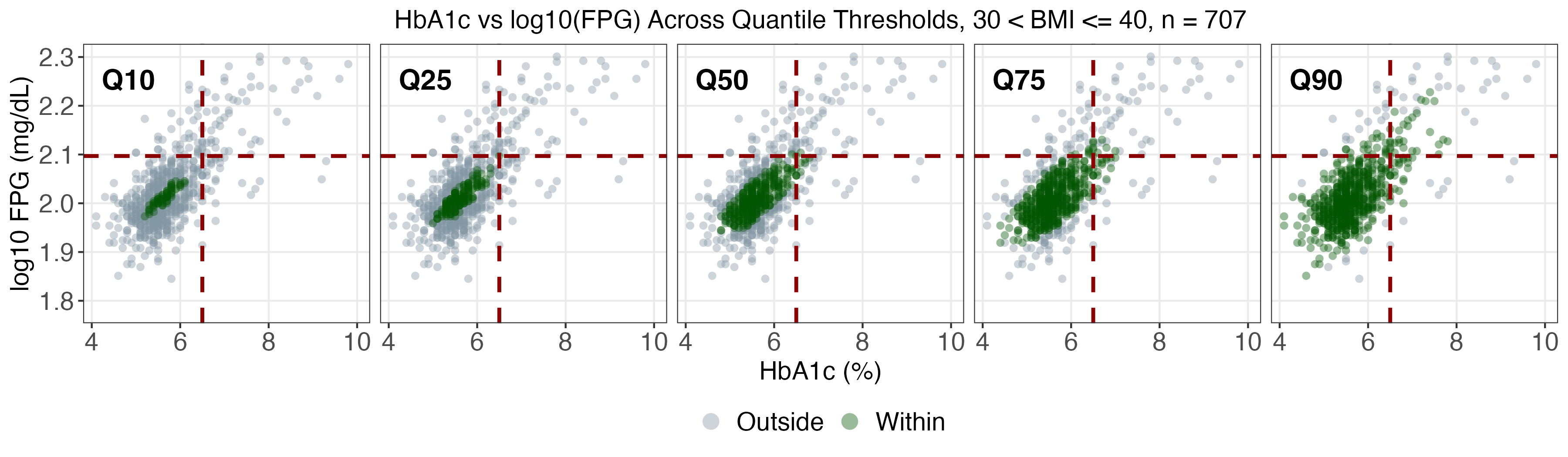
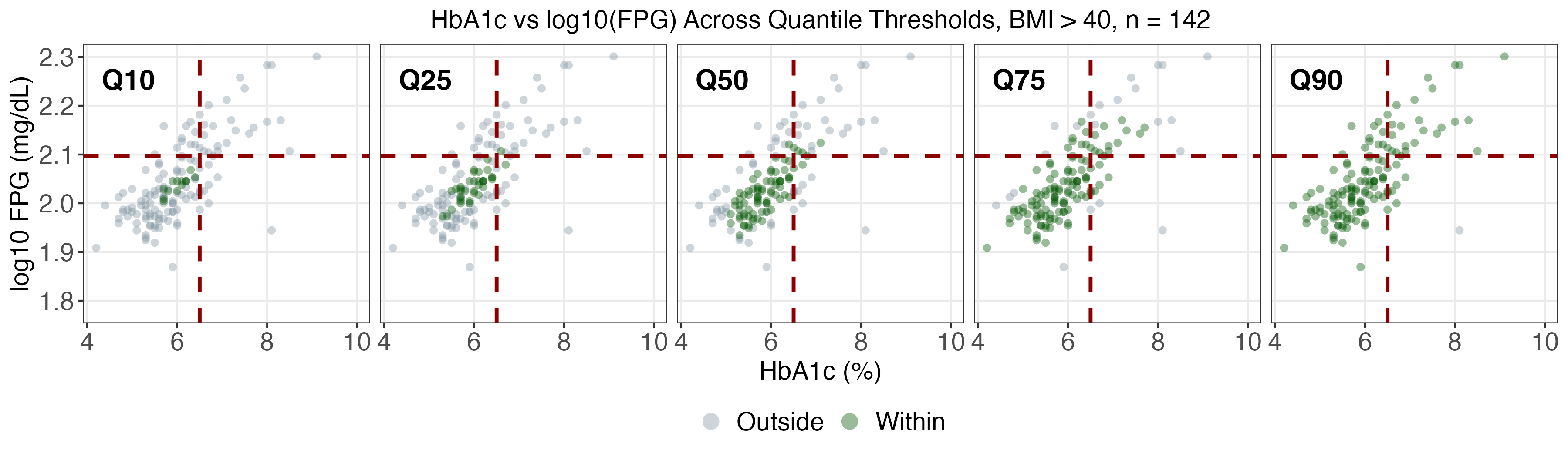
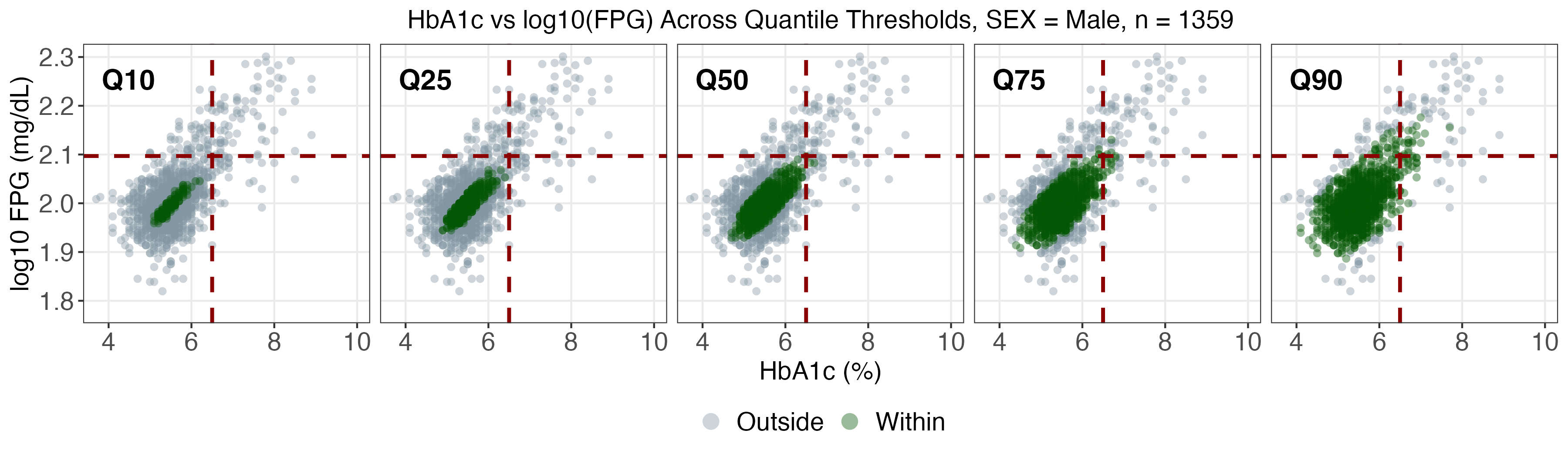
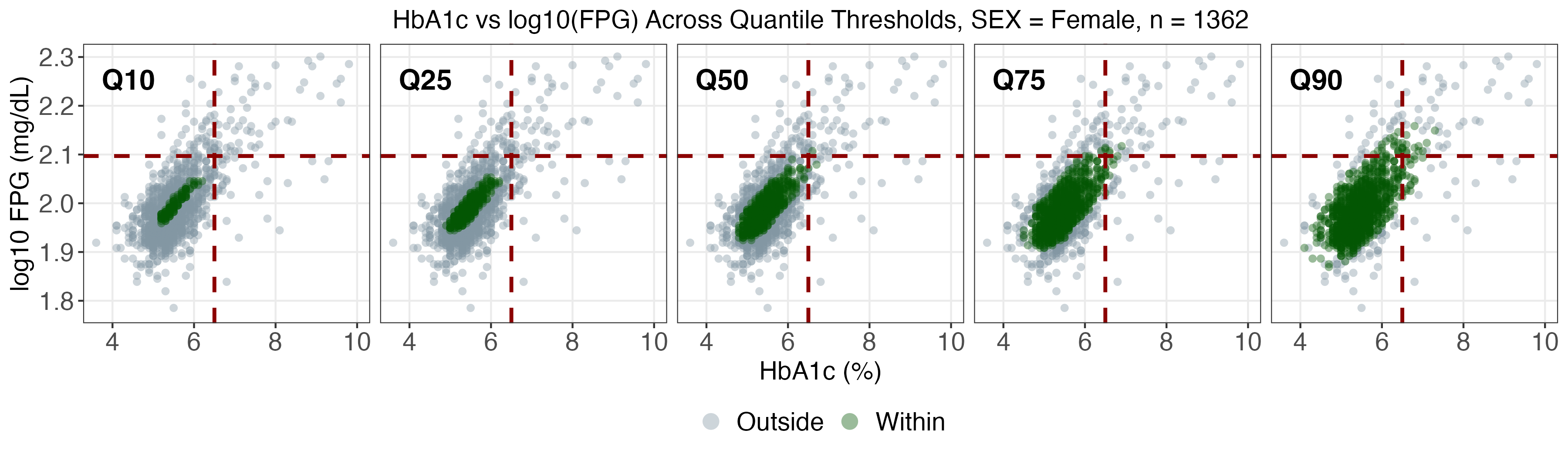
A real data application leverages NHANES, a prominent US national health survey, to estimate conditional joint tolerance regions for two key diabetes biomarkers (fasting plasma glucose and HbA1c), stratified by age, BMI, and sex. The SDRF framework enables computation of weighted conditional Mahalanobis distances and flexible multivariate tolerance regions, revealing population heterogeneity otherwise missed by mean regression.
As age and BMI increase, both the localization and spread of the biomarkers shift markedly, especially for upper quantiles (α>0.75), with women exhibiting more extreme profiles at high risk.
SDRF tolerance contours provide reference ranges tailored to demographic and anthropometric subgroups and indicate that static diagnostic cutoffs are not uniformly optimal across the population.
Figure 3: SDRF-estimated tolerance regions for log(FPG) vs HbA1c, stratified by age and BMI.
Figure 4: SDRF-estimated tolerance regions for log(FPG) vs HbA1c by sex, contextualizing subgroup-specific heterogeneity.
Practical and Theoretical Implications
SDRF establishes a robust, design-aware framework for conditional law estimation in finite population settings, with the following critical implications:
Statistical Calibration: Preserving representativeness and quantifiable uncertainty for high-dimensional or non-Euclidean regression targets, critical for policy and healthcare inference.
Generalizability: The method encompasses arbitrary survey designs, multivariate/regression functionals, and can be extended to non-Euclidean outcome spaces.
Methodological Foundations: The RKHS-MMD approach substantiates the extension of kernel and forest-based methods from i.i.d. to survey data, with rigorous conditional and unconditional limit theory.
Potential extensions include handling outcome-dependent sampling, functional response data, uncertainty quantification beyond point prediction (e.g., confidence bands), and applications to digital health modalities characterized by manifold- or network-valued responses.
Conclusion
This work delivers a mathematically rigorous and practically deployable framework for distributional estimation under complex survey designs, synthesizing design-aware resampling, RKHS embeddings, and random forest prediction. The SDRF approach closes a fundamental methodological gap, providing valid and efficient tools for conditional law inference and functionals in nationally representative health studies and analogous domains. The demonstration of stark bias when ignoring survey design underscores the necessity of these methodological advancements for both applied and theoretical research in contemporary data science and public health analytics.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.