- The paper presents a modified survey-weighted pseudo-posterior method that accurately adjusts uncertainty quantification for both global and local parameters in Bayesian multi-level models.
- It leverages prior curvature adjustments and transformations like the Yeo-Johnson to correct variance underestimation caused by complex survey designs.
- Simulation studies and NSDUH data applications demonstrate improved interval estimates and coverage probabilities for depression prevalence models.
Uncertainty Quantification for Multi-level Models Using the Survey-Weighted Pseudo-Posterior
Introduction
The task of parameter estimation and inference from complex survey samples often emphasizes global model parameters with asymptotic properties. This paper introduces a Bayesian inference approach tailored for multi-level or mixed effects models, which necessitate adjustments for both local and global parameters due to complex sampling designs. Traditional survey-weighted pseudo-posterior techniques and existing automated post-processing methods exhibit limitations in addressing such complexities in Bayesian models. This work proposes modifications to these methods, demonstrating improvements via simulation studies and applications, such as the National Survey on Drug Use and Health (NSDUH).
Approaches to Adjusting for Survey Design
The challenge addressed in the paper is twofold: ensuring unbiased estimation through survey weights and achieving correct uncertainty quantification. The naive use of survey weights can correct for biases in parameter estimation but not for sample-induced dependencies affecting uncertainty estimates. To tackle this, the survey-weighted pseudo-posterior is employed, along with modifications for improved variance estimation.
The paper provides a detailed mathematical framework for adjusting the posterior distribution based on survey weights. It explains how informative sampling designs influence parameter estimates and necessitate curvature adjustments to achieve correct asymptotic frequentist coverage. The primary focus is the impact of survey design on hierarchical models, where various levels of parameters, such as global and local, exhibit different asymptotic behaviors.
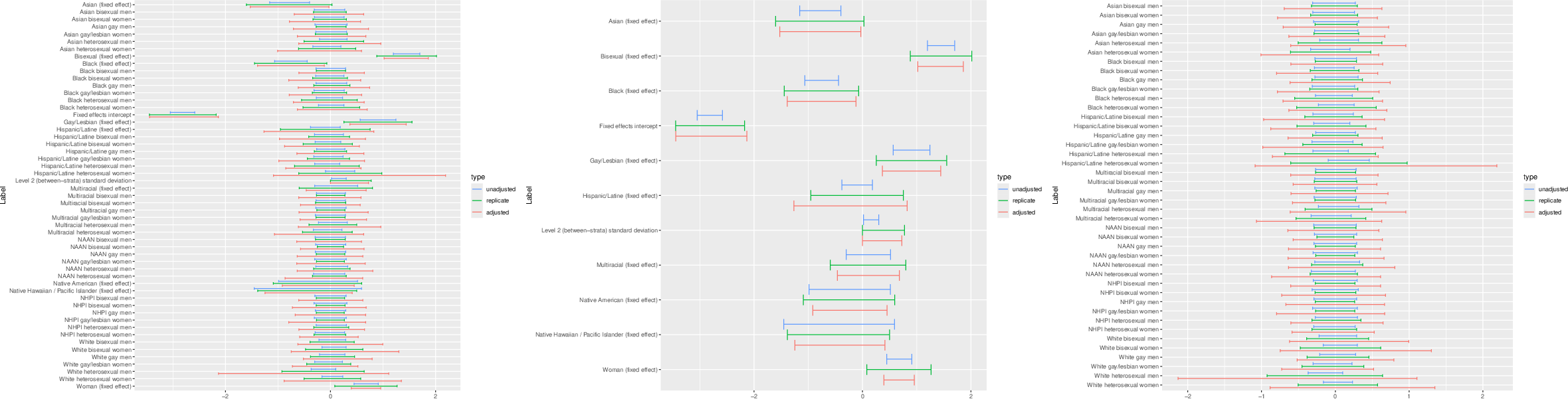
Figure 1: Comparison of 95% intervals for global regression parameters for the multi-level logistic regression for past year depression from NSDUH.
Implementation Options
The practical implementation requires estimating variance matrices for parameters using a hybrid approach, leveraging both MCMC and replication designs. Various methods like half-sample bootstrap and delete-a-group jackknife are discussed for estimating the required variance components. The paper evaluates different strategies to balance computational efficiency and estimation accuracy.
The paper introduces several advanced techniques:
- Naïve Adjustment (Baseline): Relies on posterior samples but often underestimates variance due to ignoring prior curvature.
- Using the Prior Curvature in the Adjustment: Incorporates the effect of prior distribution on parameters, enhancing accuracy for local parameters.
- Using Transformations toward Normality: Applies transformations like the Yeo-Johnson to approximate parameter normality pre-adjustment, improving variance estimates for skewed parameter distributions.
Results
Simulation studies and real-world applications illustrate the practical implications of these adjustments. For simple random samples, unadjusted and adjusted methods performed as expected. However, with probability proportional to size (PPS) sampling, adjusted methods, particularly those involving prior curvature and Yeo-Johnson transformations, improved coverage probabilities and interval estimates compared to unadjusted methods.
Application to NSDUH data revealed significant differences between unadjusted and adjusted methods in estimating depression prevalence. Adjusted methods provided wider and more accurate confidence intervals that accounted for the complex survey structure. Figure 2 displays how local random effects are impacted by these adjustments, highlighting differences between unadjusted, naïve, and Yeo-Johnson methods.
Figure 2: Comparison of 95\% intervals for local random effects for the multi-level logistic regression for past year depression from NSDUH.
Discussion and Conclusions
The study concludes that survey-weighted pseudo-posterior modifications significantly enhance uncertainty quantification in Bayesian multi-level models under complex sampling designs. The integration of prior curvature and parameter transformation techniques corrects variance underestimation, particularly for hierarchical random effects. These findings underline the need for careful adaptation of Bayesian predictive models to adequately reflect sampling design complexities and ensure robust inference.
Future work includes expanding simulation studies across varying sample sizes and levels of sample informativeness. Further validation of the proposed methods, especially against more computationally intensive replicate designs, can solidify their practical applicability and reliability in diverse survey settings.