- The paper introduces the GRAPE framework, unifying multiplicative rotations from SO(d) and additive logit biases to improve positional encoding.
- It presents closed-form expressions that enable efficient computation and precise capture of relative positional information.
- Experimental results demonstrate that GRAPE outperforms methods like RoPE, offering enhanced training stability and improved long-context performance.
Abstract
The paper introduces the Group Representational Position Encoding (GRAPE) framework, a unified approach to positional encoding for sequence modeling. GRAPE combines two mechanisms: multiplicative rotations, termed Multiplicative GRAPE, and additive logit biases, termed Additive GRAPE. Multiplicative GRAPE employs rotations in the special orthogonal group $\SO(d)$, while Additive GRAPE arises from unipotent actions in the general linear group GL(d). GRAPE captures the essential geometric properties required for positional encoding in long-context models, extending the capabilities of previously established methods like Rotary Position Embedding (RoPE) and ALiBi.
Introduction
Positional information is crucial in the transformer architecture, addressing the limitation of permutation-invariant self-attention mechanisms. Classical approaches injected absolute positional codes, while subsequent innovations embraced relative encodings and linear biases, optimizing length extrapolation without computational overhead. RoPE exemplifies relative positional encoding through orthogonal rotations that are norm-preserving and origin invariant. GRAPE aims to unify these approaches, providing a comprehensive framework that encapsulates both multiplicative and additive mechanisms.
GRAPE Framework
Multiplicative GRAPE
Multiplicative GRAPE models positional encodings through rotations in $\SO(d)$, specifically using rank-2 skew generators. This approach preserves norms and supports efficient computation via closed-form matrix exponentials.
Implementation Details: Positions are encoded as: $\Gb(n) = \exp(n \omega \Lb) \in \SO(d)$
with $\Lb$ being a skew-symmetric generator defined by vectors $\ab$ and $\bbb$.
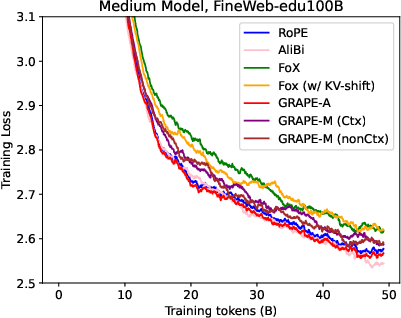
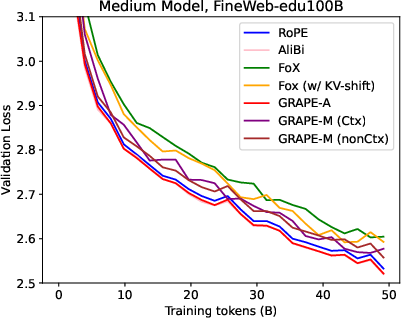
Figure 1: Training Loss
Additive GRAPE
Additive GRAPE employs unipotent actions within GL(d) to achieve additive logit biases, supporting streaming cacheability and preserving relative scoring.
Implementation Details: The additive positional encoding is realized through: $\Gb_{\text{add}}(n) = \exp(n \omega \Ab)$
resulting in low-rank transformations that introduce linear-in-offset biases.
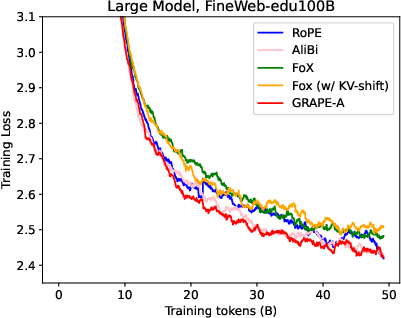
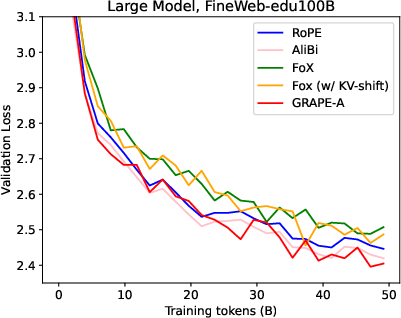
Figure 2: Training Loss
Contributions
- Unified Framework: GRAPE offers a group-theoretic unification of positional encodings, enabling comprehensive extensions.
- Closed-form Expressions: Derivation of closed-form matrix exponentials for efficient computation in multiplicative GRAPE.
- Exact Logit Projection: Implementation of rank-1 unipotent actions to capture ALiBi and Forgetting Transformer extensions precisely.
- Experimental Analysis: Demonstrates GRAPE's persistent edge over existing methods, including RoPE and FoX, in both training stability and performance.
Conclusion
GRAPE provides a principled design space for positional encoding mechanisms, enhancing the capabilities of transformer architectures in long-context scenarios. By subsuming existing approaches under a unified framework, GRAPE facilitates further research and development of efficient, scalable models.
The implications of this work extend across both practical and theoretical domains, promising advancements in AI's ability to model complex sequences with intricate positional requirements. Future research may explore adaptive, context-sensitive frequency modulation and its integration into the broader GRAPE framework.


