- The paper presents a novel method, HARoPE, which integrates head-specific adaptive rotary positional encoding to dynamically reallocate frequencies, enhancing spatial modeling in images.
- HARoPE employs lightweight SVD-based linear transformations to align semantic positions and mix cross-axis features, yielding improved compositional understanding.
- Empirical results demonstrate HARoPE’s superior performance, achieving higher accuracy, lower FID, and better text-to-image adherence compared to standard RoPE and APE.
Head-wise Adaptive Rotary Positional Encoding for Fine-Grained Image Generation
Introduction and Motivation
Transformer-based architectures have become the de facto standard for both image understanding and generative modeling. However, their inherent permutation invariance necessitates explicit positional encoding to capture spatial structure. Rotary Positional Embedding (RoPE) has been widely adopted due to its relative-position property and strong empirical performance in 1D domains. Yet, when extended to multi-dimensional data such as images, standard RoPE exhibits significant limitations: rigid frequency allocation across axes, axis-wise independence that suppresses cross-dimensional interactions, and uniform treatment across attention heads that precludes specialization. These deficiencies are particularly detrimental for fine-grained image generation tasks, where spatial relations, color fidelity, and object counting are critical.
HARoPE: Methodological Advances
HARoPE (Head-wise Adaptive Rotary Positional Encoding) addresses these limitations by introducing a lightweight, learnable, head-specific linear transformation—parameterized via singular value decomposition (SVD)—immediately before the rotary mapping in the attention mechanism. This adaptation enables:
- Dynamic frequency reallocation across axes, overcoming the rigid partitioning of standard RoPE.
- Semantic alignment of rotary planes and explicit cross-axis mixing, allowing the model to capture complex spatial dependencies.
- Head-specific positional receptive fields, promoting multi-scale and anisotropic specialization across attention heads.
The key design is to insert, for each attention head h, a learnable matrix Ah=UhΣhVh⊤ (with Uh,Vh orthogonal and Σh diagonal and positive) before the rotary map. This preserves RoPE's strict relative-position property, as the same Ah is applied to both queries and keys, and the position dependence remains confined to the rotary maps.
Empirical Evaluation
Fine-Grained Image Generation
HARoPE demonstrates clear qualitative improvements over standard RoPE in fine-grained image generation tasks, particularly in spatial relations, color fidelity, and object counting.

Figure 1: Qualitative comparison of generated images across three fine-grained challenges: spatial relations (left), color fidelity (middle), and object counting (right). HARoPE consistently outperforms RoPE, adhering more faithfully to prompt specifications.
On text-to-image generation benchmarks (e.g., FLUX and MMDiT), HARoPE yields more faithful adherence to prompt instructions, especially for compositional and attribute-specific queries.

Figure 2: Qualitative comparison on wild prompts, evaluating FLUX models with RoPE and HARoPE positional embeddings.
Quantitative Results
Across multiple tasks and architectures, HARoPE consistently outperforms both absolute and relative positional encoding baselines:
- Image Understanding (ViT-B, ImageNet): HARoPE achieves 82.76% Top-1 accuracy, surpassing APE and all RoPE variants.
- Class-Conditional ImageNet Generation (DiT-B/2): HARoPE attains the lowest FID-50K (8.90) and highest IS (127.01), with improved recall and precision.
- Text-to-Image Generation (FLUX, MMDiT): HARoPE improves GenEval and DPG-Bench scores, and reduces FID compared to RoPE and APE.
Matrix Parameterization and Head-wise Specialization
Ablation studies confirm that SVD-based parameterization and head-wise specialization are both critical for optimal performance. Multi-head SVD adaptation yields the best FID and IS, and heatmap visualizations of learned matrices reveal distinct, specialized patterns across heads and layers.

Figure 3: Qualitative comparison of different matrix settings. NM'' denotes normal matrix,OM'' denotes orthogonal matrix.
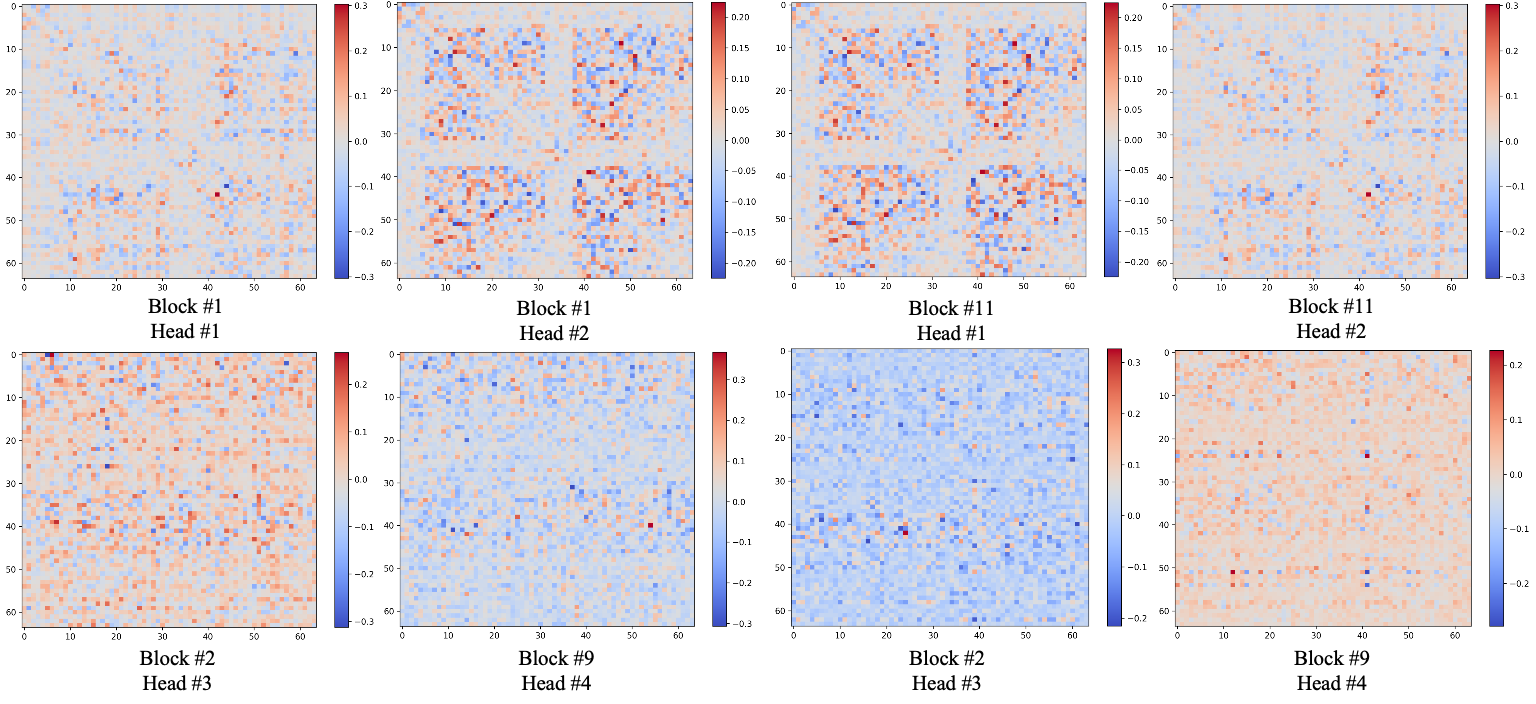
Figure 4: Model weight in heatmap of different learned matrices in different attention heads and different blocks.
Robustness and Extrapolation
HARoPE maintains superior performance across a range of image resolutions, including strong extrapolation to resolutions unseen during training. For example, in ViT-B, HARoPE achieves 82.88% Top-1 accuracy at 512×512 resolution, outperforming all baselines.
Training Stability and Efficiency
The additional computational overhead of HARoPE is negligible relative to the overall model, and training remains stable, as evidenced by smooth convergence curves. The method is compatible with large-scale models and can be integrated as a drop-in replacement for RoPE.
Qualitative Analysis
HARoPE's improvements are visually apparent in both controlled and open-domain prompts. Generated images exhibit more accurate spatial arrangements, color matching, and object counts, reflecting the enhanced positional awareness and specialization enabled by the head-wise adaptation.

Figure 5: Qualitative Comparison on the GenEval Benchmark, evaluating FLUX models with RoPE and HARoPE positional embeddings.

Figure 6: Text-to-image generation on MS-COCO. evaluating MMDiT models with RoPE and HARoPE positional embeddings.

Figure 7: Visualization comparison of HARoPE with and with head-wise specialization, tested using Flux on the text-to-image generation task.
Theoretical and Practical Implications
HARoPE demonstrates that strict axis-wise and head-wise uniformity in positional encoding is suboptimal for high-dimensional, structured data. By learning head-specific, semantically aligned coordinate systems, transformers can better capture the compositional and fine-grained structure required for advanced image generation. The SVD-based parameterization ensures stable optimization and compatibility with pretrained models.
Practically, HARoPE is a modular, efficient enhancement that can be adopted in existing transformer-based generative models with minimal code changes. Its benefits are most pronounced in tasks requiring precise spatial reasoning and compositionality, such as text-to-image synthesis and high-resolution image generation.
Limitations and Future Directions
While HARoPE is validated extensively in the image domain, its generalizability to other modalities (e.g., video, audio, 3D) remains to be established. The current adaptation is static post-training; future work could explore input-conditional or dynamic transformations to further enhance flexibility. Additionally, the impact of HARoPE on extremely large-scale models and in low-data regimes warrants further investigation.
Conclusion
HARoPE provides a principled, efficient, and empirically validated solution to the limitations of standard multi-dimensional RoPE in transformer-based image generation. By enabling head-wise adaptive rotary positional encoding via SVD-parameterized linear transformations, HARoPE achieves superior fine-grained spatial modeling, compositionality, and extrapolation. Its modularity and negligible computational overhead make it a practical choice for advancing the positional reasoning capabilities of modern generative models.