- The paper presents a novel wavelet-based positional encoding method that overcomes limitations of conventional RoPE and ALiBi approaches.
- It leverages multi-scale Ricker wavelets for dynamic signal capture, significantly reducing perplexity in extended sequence contexts.
- Experimental results demonstrate robust improvements in long-range dependency modeling without imposing constraints on the attention mechanism.
Wavelet-based Positional Representation for Long Context
This essay examines a novel approach to positional representation in large-scale LLMs, focusing on the implementation and implications of wavelet-based methods for handling long contexts. The study reinterprets conventional positional encoding mechanisms, probing their limitations and proposing enhancements through wavelet transforms.
Positional Encoding Challenges
In LLMs based on Transformer architectures, positional encoding is crucial for accurately representing token sequences. Challenges arise when extending the sequence length beyond the maximum allowable length, Ltrain, encountered during pre-training. Traditional encoding methods such as RoPE and ALiBi exhibit specific limitations in extrapolation capabilities. RoPE, which uses a rotation matrix for absolute position embedding, is constrained by its fixed scale parameter and performs sub-optimally beyond $L_{\rm train$. On the other hand, ALiBi, relying on windowed attention with varying sizes, limits the receptive field and fails to capture extensive dependencies.
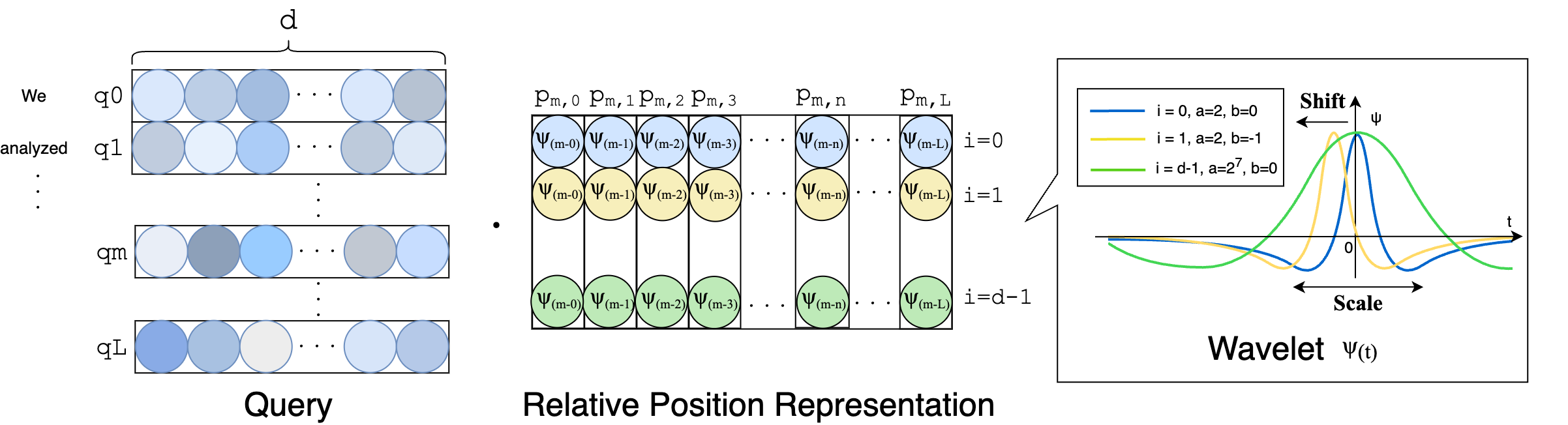
Figure 1: Overview of Wavelet-based Relative Positional Representation As in RPE.
Theoretical Analysis of RoPE and ALiBi
RoPE can be viewed as a wavelet-like transform but restricted to Haar-like wavelets with a fixed scale, limiting its ability to model dynamic changes in signals. Mathematically, RoPE processes can be expressed as a wavelet transformation across the head dimension using Haar wavelets with an invariant scale of 2. In contrast, ALiBi facilitates multiple window sizes, analogous to the varying scales in wavelet transforms, providing adaptability but within a limited receptive field due to linear biases.
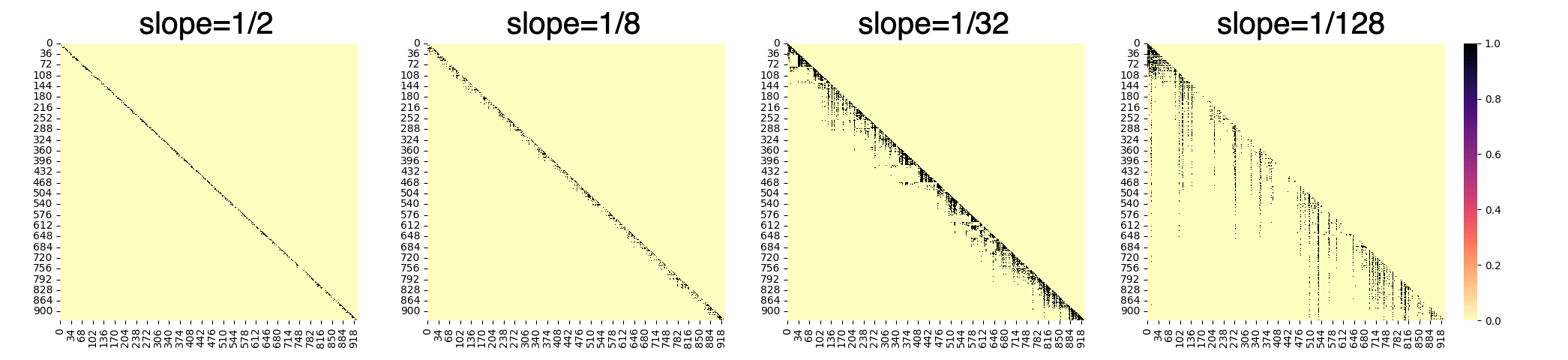
Figure 2: Heatmap of scaled attention scores via softmax normalization in ALiBi without non-overlapping inference.
Proposed Wavelet-based Positional Representation
This study proposes a wavelet-based method leveraging multiple window sizes (scale parameters) and flexible shift parameters, drawing inspiration from Relative Position Representation (RPE) methodologies. Unlike RoPE, this approach utilizes wavelet transforms across d dimensions, enabling dynamic signal capture akin to time-frequency analysis. By incorporating diversification in wavelet functions and scale parameters, the method offers resilience to varying sentence lengths and context shifts.
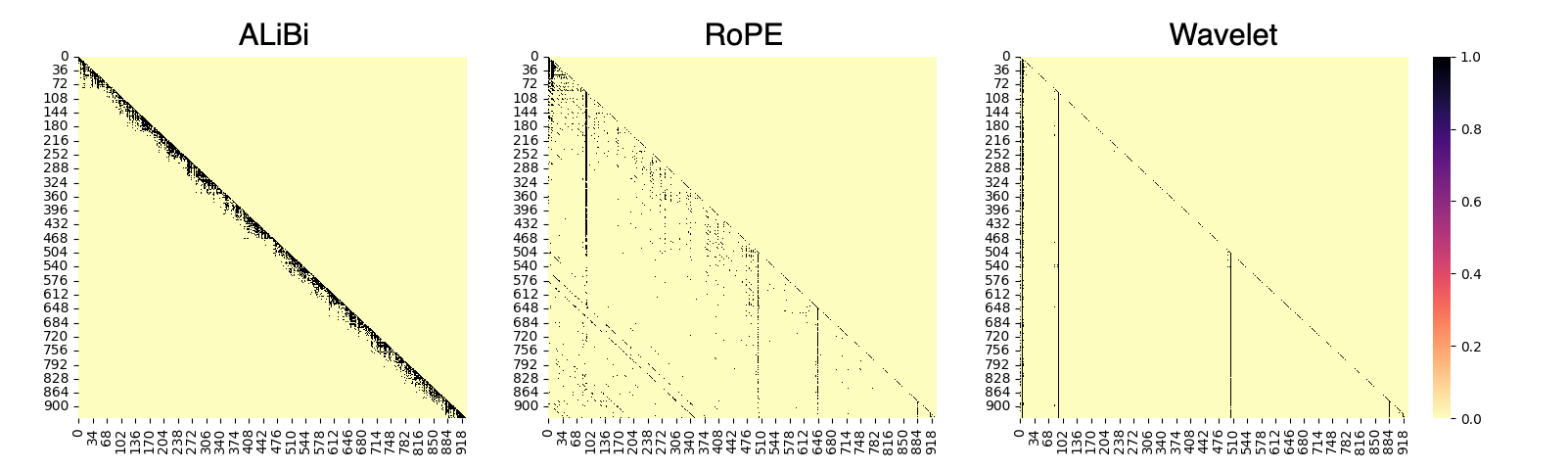
Figure 3: Heatmap of scaled attention scores via softmax normalization in 4th head after softmax operation without non-overlapping inference.
Implementation Details
The implementation utilizes Ricker wavelets instead of Haar wavelets, deploying varying scales for enhanced context adaptability. The query and key vectors undergo wavelet transformation based on relative positional shifts, facilitating robust signal parsing, critical for extrapolation. The position representation is expressed using the wavelet function transformed across multiple scales, a={20,21,...,2s}, and shift parameters b={0,1,2,...,sd−1}.
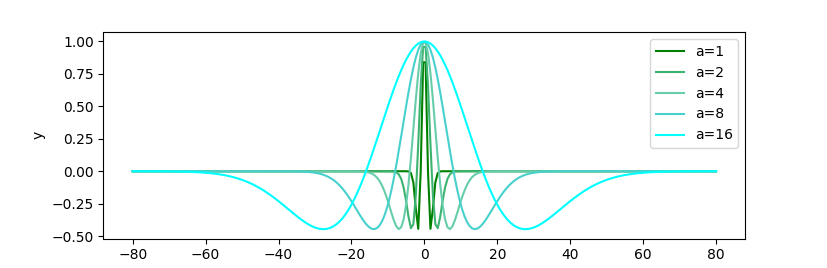
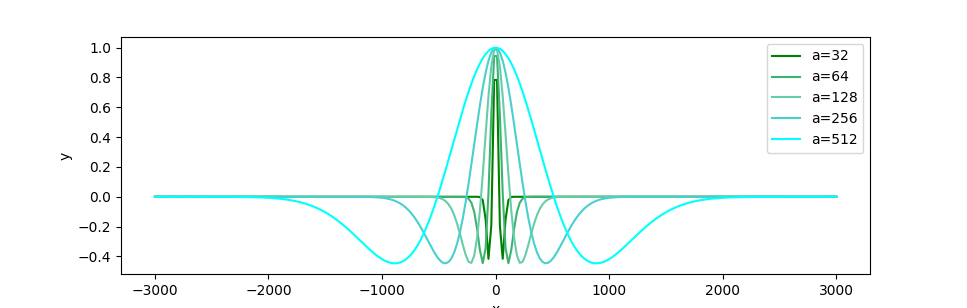
Figure 4: Graph of compared Ricker wavelet functions with a = [20,21,22,23,24].
Experimental Results
Evaluations on datasets demonstrate that the wavelet-based approach outperforms conventional methods in perplexity metrics, especially for contexts extending beyond Ltrain. The use of wavelets significantly reduces perplexity, showcasing superiority in capturing long-range dependencies without restricting the attention field. Figures illustrate that even as sentence length increases, the proposed approach maintains low perplexity, contrasting sharply with RoPE’s escalation in perplexity due to new positional values in longer sequences.
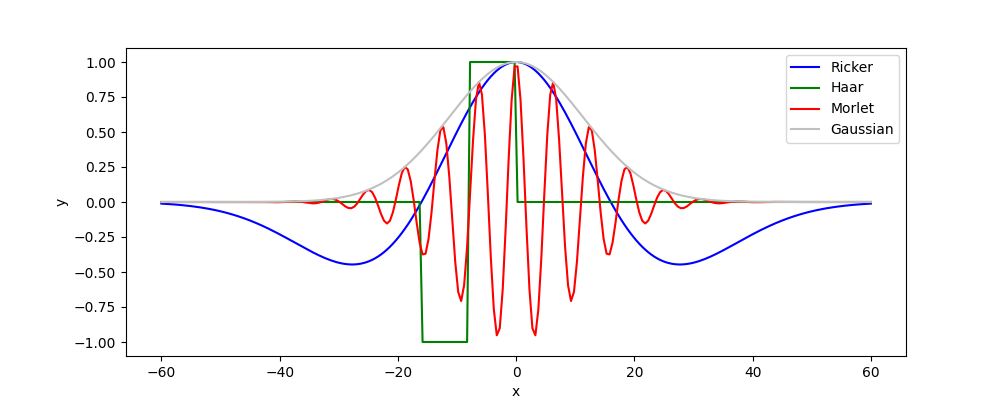
Figure 5: Graph of compared wavelet functions. The case with scale parameter a=24 and shift parameter b=0 is shown.
Conclusion
The wavelet-based positional representation presents a significant advancement in handling long-context sequences in LLMs. By facilitating dynamic adaptation through diversified scale and shift parameters, this approach transcends conventional limitations, enabling effective extrapolation and comprehensive signal analysis without imposing constraints on the attention mechanism's receptive field. This research marks a pivotal step toward enabling more robust and scalable language modeling, opening avenues for further exploration in adaptive positional encoding strategies.