Distribution Matching Variational AutoEncoder
Abstract: Most visual generative models compress images into a latent space before applying diffusion or autoregressive modelling. Yet, existing approaches such as VAEs and foundation model aligned encoders implicitly constrain the latent space without explicitly shaping its distribution, making it unclear which types of distributions are optimal for modeling. We introduce \textbf{Distribution-Matching VAE} (\textbf{DMVAE}), which explicitly aligns the encoder's latent distribution with an arbitrary reference distribution via a distribution matching constraint. This generalizes beyond the Gaussian prior of conventional VAEs, enabling alignment with distributions derived from self-supervised features, diffusion noise, or other prior distributions. With DMVAE, we can systematically investigate which latent distributions are more conducive to modeling, and we find that SSL-derived distributions provide an excellent balance between reconstruction fidelity and modeling efficiency, reaching gFID equals 3.2 on ImageNet with only 64 training epochs. Our results suggest that choosing a suitable latent distribution structure (achieved via distribution-level alignment), rather than relying on fixed priors, is key to bridging the gap between easy-to-model latents and high-fidelity image synthesis. Code is avaliable at https://github.com/sen-ye/dmvae.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Distribution Matching Variational AutoEncoder (DMVAE)”
Overview: What is this paper about?
This paper is about making computer programs better at creating realistic images. Most modern image generators don’t work directly with full-size pictures because that’s too complicated. Instead, they first compress the picture into a smaller “code” (called a latent) and then learn to generate these codes. The quality of the final images depends a lot on how this compressed “latent space” is shaped.
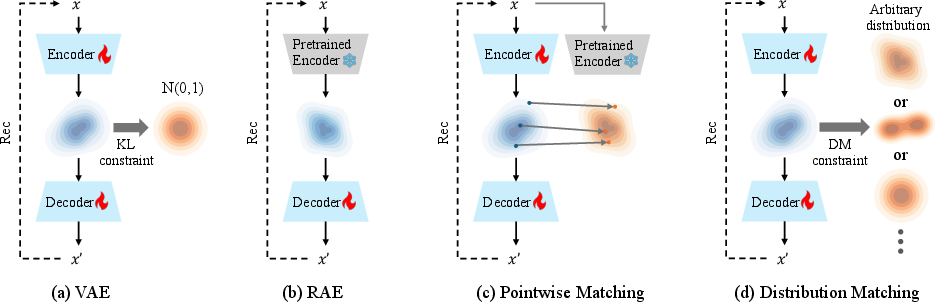
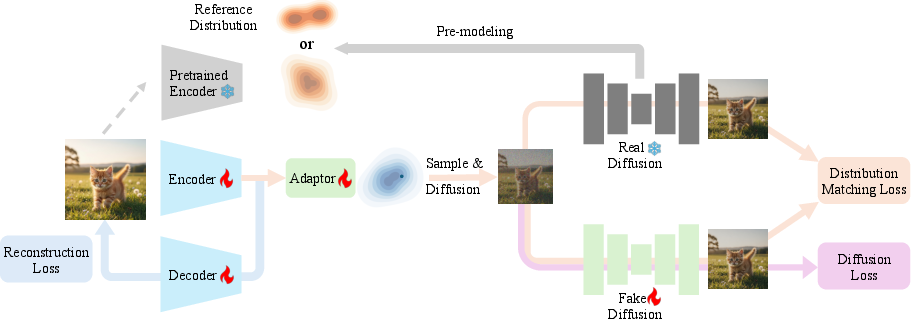
The authors introduce a new way to design this latent space, called Distribution Matching VAE (DMVAE). Instead of forcing the latent space into a simple shape (like a basic Gaussian blob), DMVAE learns to match the entire shape of the latent space to any chosen “reference distribution,” like features from a powerful vision model. This lets them pick a latent shape that’s both easy to model and good for reconstructing detailed images.
Objectives: What questions are they trying to answer?
The paper focuses on two simple questions:
- How can we create a latent space that is both easy for a model to learn and still holds enough detail to rebuild high-quality images?
- Which kind of “target shape” (reference distribution) should the latent space match to get the best results?
The authors test several options and want to find out which one gives the best balance between:
- Modeling simplicity (easy for the generator to learn)
- Reconstruction fidelity (images come out sharp and detailed)
Methods: How do they do it? (Explained with everyday ideas)
First, some quick definitions in everyday language:
- An encoder is like a compressor: it turns a picture into a small code called a latent.
- A decoder is like a decompressor: it turns the small code back into a picture.
- The latent space is the world where all these compressed codes live. Its “shape” (distribution) matters a lot.
- A VAE (Variational AutoEncoder) is a standard encoder–decoder system with a rule that tries to keep the latent space simple (usually like a Gaussian blob).
- A diffusion model can estimate how data is spread out by learning a “score,” which is like an arrow pointing toward denser areas in the cloud of points.
- The aggregate posterior is the overall cloud of all latents produced by the encoder across the whole dataset—this is the full shape we care about, not just one point at a time.
What DMVAE does:
- Imagine the latent space as a cloud of points. DMVAE wants this cloud to have a specific shape that we choose (the “reference distribution”), like the shape of features from a strong vision model (e.g., DINO).
- It trains a “teacher” diffusion model on that reference distribution so the teacher knows the exact shape and direction (“score”) of the cloud we want.
- It also trains a “student” diffusion model to understand the shape of the current latent space produced by the VAE’s encoder.
- Then, it adjusts the encoder so that the student’s directions match the teacher’s directions. Think of it as nudging all points in the encoder’s cloud to line up with the target cloud’s shape.
Why this matters:
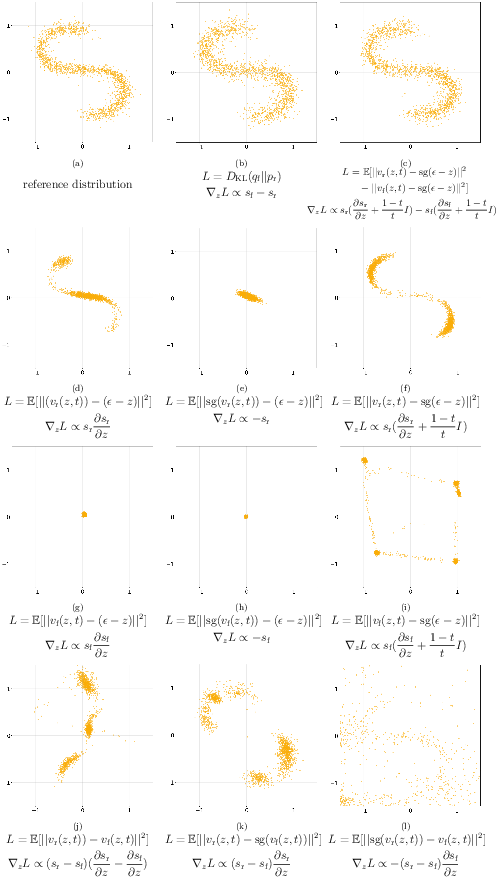
- Older methods align each data point separately to some target (like “make this latent close to that feature”). That can produce “Swiss cheese” latents—holes and disconnected clumps—making the generator struggle.
- DMVAE aligns the entire distribution (the whole cloud’s structure), avoiding holes and producing a smooth, well-shaped latent space that’s both easy to model and good for reconstruction.
To make things stable and practical:
- If the current latent space and the target are very different, training can be shaky. The authors stabilize it by starting from pre-trained models, training in alternating steps, using a small latent dimension (like 32), and adding a small projection head to match sizes when needed.
Main findings: What did they discover and why does it matter?
They tried several choices for the reference distribution—the target shape for the latent space—including:
- Self-supervised features (DINO)
- Supervised features (ResNet classifier)
- Text features (SigLIP)
- Noise from a diffusion model’s middle steps
- Gaussian and Gaussian mixtures
- Sub-sampled (partial) DINO features
Key result:
- Self-supervised features (like DINO) gave the best balance: they are semantically meaningful (they cluster by what’s in the image) and still hold enough detail. This made both modeling and reconstruction work well.
What the numbers mean:
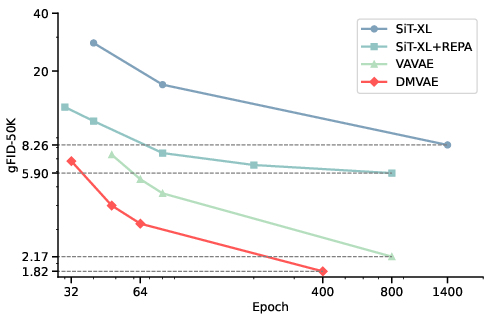
- They report gFID (a measure of how realistic and diverse generated images are; lower is better). Using DMVAE with an SSL prior (DINO), they achieved:
- gFID ≈ 3.22 on ImageNet after only 64 training epochs
- gFID ≈ 1.82 after 400 epochs
- That’s very strong performance and fast training compared to other methods.
Why it’s important:
- The “shape” of the latent space really matters. Picking the right reference distribution and matching to it at the distribution level leads to better image generation and faster training.
- DMVAE acts like a powerful “tokenizer” (the first stage compressor) that sets up the generator for success.
Implications: What could this change in the future?
- Choosing the right latent distribution is key. Instead of sticking to a fixed Gaussian prior, we can match to smarter, semantically rich distributions (like SSL features) and get better results.
- This approach can improve not just images, but potentially audio, video, and 3D generation—any task that benefits from compressing data into a good latent space first.
- DMVAE helps bridge the gap between “easy-to-model latents” and “high-quality image synthesis,” which could make future generative models both faster and more realistic.
In short: The paper shows that shaping the whole latent space to match the right target distribution—rather than forcing a simple shape or aligning point-by-point—produces better, more efficient image generators.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to be directly actionable for future research.
- Lack of theoretical guarantees for the DMVAE objective: provide a formal analysis that the proposed score-difference gradient approximates minimizing , including convergence conditions, stability regions, and bias introduced by an imperfect student score .
- Quantitative alignment measurement: implement tractable proxies (e.g., sliced Wasserstein, MMD, kernel two-sample tests, Stein discrepancy) to measure and track the divergence between and throughout training rather than relying on qualitative t-SNE.
- Stability when is far from : develop principled optimization strategies beyond heuristics (adaptive noise schedules tied to SNR, trust-region updates, curriculum matching, two-time-scale theory for joint training, variance reduction for explosive gradients) and quantify their impact on collapse/dropping.
- High-dimensional latent scalability: the method currently relies on low latent dimensionality (e.g., ) to stabilize distribution matching; systematically study behavior at higher dimensions (64–512), including reconstruction fidelity, generative performance, and training stability.
- Accuracy and capacity requirements of teacher/student score networks: rigorously ablate how teacher and student model capacity, architecture, and training errors propagate to DMVAE performance; quantify sensitivity to teacher mis-specification and model mismatch.
- Effect of classifier-free guidance (CFG) on the “reference distribution”: analyze and quantify how applying CFG to the teacher diffusion model alters (potentially distorting density) and its downstream impact on DMVAE alignment and generative performance.
- Reference distribution selection criteria: move beyond heuristic weighting to define principled, data-driven criteria for choosing (e.g., structural measures of semantic clustering, intra-class variance, modeling complexity) and validate across diverse priors.
- Conditional vs. unconditional alignment: investigate matching conditional aggregates to class-conditional priors for class-conditional generation, and assess whether conditional alignment improves modeling efficiency or harms reconstruction.
- Generalization beyond ImageNet-256: evaluate DMVAE on varied domains (COCO, FFHQ, LSUN, domain-shifted datasets, small-data regimes) to test robustness of SSL-derived priors and the method’s sensitivity to the data manifold.
- Reconstruction–generation trade-off: DMVAE lags on PSNR/rFID relative to other tokenizers; quantify the trade-off curve (distortion vs. perception) and propose mechanisms (adaptive , multi-objective optimization, Pareto front tracking) to tune fidelity without sacrificing modeling simplicity.
- Model-dependence of generative outcomes: isolate the contribution of latents vs. the generative prior by repeating evaluations across different prior models (U-Nets, Transformers, flows, AR) under matched budgets; verify that gains are due to latent distribution, not prior-specific effects.
- Metrics for “modeling simplicity”: replace or complement gFID with direct measures (negative log-likelihood estimates, bits-per-dimension, training speed vs. compute curves, sample complexity) to substantively characterize the ease of modeling .
- Projection head design: systematically study projector architectures (MLP vs. transformer, query count, normalization, orthogonality/whitening constraints), their training solely via , and interactions with decoder training; assess leakage or bottlenecks.
- Deterministic vs. stochastic encoders: DMVAE largely treats as deterministic; analyze the impact of stochastic (e.g., reparameterized Gaussian) on aggregate posterior alignment and downstream modeling, including variance calibration.
- Measuring “holey manifold” claims: provide quantitative manifold-density/coverage diagnostics (e.g., occupancy, local intrinsic dimension, nearest-neighbor graph connectivity, mixture-of-Gaussians fitting residuals) to verify DMVAE reduces holes/multimodal fragmentation vs. baselines.
- Effect of diffusion noise reference choice: for “diffusion noise states,” explore -dependent references beyond ; characterize how different noise levels shape and affect alignment and generation.
- Hyperparameter sensitivity and reproducibility: report sensitivity analyses (seed variance, schedules, weighting choices, learning rates, alternating update cadence), and publish standardized training recipes with compute budgets/time.
- Compute and memory costs: quantify end-to-end training cost for pretraining teacher diffusion, jointly training student diffusion + VAE, and decoder refinement; propose efficiency improvements (distillation, low-rank adapters, parameter sharing) and compare to competing tokenizers.
- Robustness to teacher errors and drift: monitor and bound the tracking error between and during training; test whether DMVAE degrades gracefully when teacher scores are noisy, biased, or out-of-distribution.
- Downstream utility of latents: assess whether DMVAE latents (especially with SSL priors) retain discriminative power for downstream tasks (classification/segmentation) and whether distribution alignment harms or helps transfer.
- Extension to audio/video/3D: concretely define suitable reference distributions in these modalities (e.g., self-supervised temporal embeddings, 3D shape priors), and investigate spatiotemporal alignment, temporal coherence, and scalability constraints.
- Alternative priors not explored: evaluate hierarchical, multi-scale, discrete, flow-based, or VampPrior-style learned priors as ; study mixtures-of-experts and class-conditional mixtures to balance structure and coverage.
- Better principled timestep and weighting strategies: replace uniform sampling with theoretically grounded schedules (e.g., SNR-based, importance sampling) and analyze their effect on gradient variance, stability, and convergence speed.
- Trustworthy evaluation beyond t-SNE: avoid qualitative reliance on t-SNE; adopt robust visualization/intrinsic dimension metrics and rank-based neighborhood preservation scores to characterize latent geometry.
- Decoder refinement protocol: specify when refinement helps vs. hurts alignment; study joint vs. sequential refinement strategies and their impact on both reconstruction fidelity and latent distribution preservation.
- Data requirements and domain bias of SSL priors: quantify how the choice and training corpus of the SSL encoder (e.g., DINO variants, dataset biases) affect and the generality of DMVAE; explore domain-adapted SSL priors.
Practical Applications
Immediate Applications
The following applications can be deployed now by integrating DMVAE into existing generative modeling workflows or adapting the paper’s released code and recipes.
- DMVAE tokenizers for latent diffusion pipelines
- Sector: software, creative industries, entertainment, advertising
- What: Replace standard VAE/VQ-VAE tokenizers with DMVAE (using SSL-based priors like DINO) to achieve faster convergence and improved generative quality at lower compute budgets.
- Tools/Workflows:
- Pre-train a teacher score model on DINO features; jointly train DMVAE encoder–decoder with a student score model.
- Train DiT/UNet prior on DMVAE latents; deploy in text-to-image or class-conditional pipelines.
- Use default recipe: λ_DM ≈ 10, low-dimensional latents (e.g., d=32), uniform timestep sampling, optional decoder refinement.
- Assumptions/Dependencies: Access to high-quality SSL features (DINOv2), GPU capacity for joint teacher–student training, tuning to avoid instability when reference and encoder distributions are far apart.
- Domain-adapted tokenizers for specialized image generation and augmentation
- Sector: healthcare (radiology, pathology), manufacturing (visual inspection), geospatial (satellite, aerial), retail (product imagery)
- What: Swap the reference distribution from generic DINO to domain-specific SSL or supervised features to tailor latents to domain semantics for better synthesis and augmentation.
- Tools/Workflows:
- Collect domain images; extract features via domain SSL (e.g., MAE/SimCLR trained on domain data) or supervised models.
- Train DMVAE to match these features; then train a diffusion prior on the latents for synthetic data generation and augmentation.
- Assumptions/Dependencies: Availability of domain-pretrained feature encoders; compliance with regulations (e.g., HIPAA for medical data); careful monitoring for data drift and hallucinations.
- Semantic compression for storage and streaming
- Sector: cloud/storage/CDN, mobile apps, social media
- What: Use DMVAE encoder–decoder as a “semantic compressor” where latents aligned to SSL distributions retain semantic structure and enable high-quality generative reconstruction at lower bitrates.
- Tools/Workflows:
- Encode images to low-dimension latents; store/transmit latents; reconstruct via DMVAE decoder.
- Add content-aware compression profiles (e.g., higher λ_DM for semantic-rich content; lower for texture-heavy content).
- Assumptions/Dependencies: Acceptable reconstruction fidelity tradeoffs; compatibility with existing codec infrastructure; latency constraints for real-time decoding.
- Latent space editing and controllable synthesis
- Sector: photo/video editing, design, marketing
- What: Exploit semantically clustered latents (aligned to SSL distributions) for intuitive edits—moving along latent directions for style, content, and class changes.
- Tools/Workflows:
- t-SNE/UMAP exploration of latents; identify semantic directions; implement sliders for users to navigate latent clusters.
- Assumptions/Dependencies: Calibration of semantic directions; user interface design; guardrails to avoid unwanted bias amplification.
- Multi-modal alignment via text priors
- Sector: search/retrieval, e-commerce, media asset management
- What: Use text embeddings (e.g., SigLIP/CLIP) as DMVAE reference distributions to align image latents to language semantics, improving cross-modal retrieval and zero-shot tagging.
- Tools/Workflows:
- Train DMVAE with text embedding priors; index images by DMVAE latents; perform nearest-neighbor retrieval with text queries.
- Assumptions/Dependencies: Text embeddings quality; domain mismatch risks; potential reconstruction quality drop compared to SSL priors.
- Faster generative model training and prototyping
- Sector: MLOps, research labs
- What: Reduce training epochs and compute for image generators by choosing modeling-friendly latents (SSL-derived priors), enabling rapid experiments and iteration.
- Tools/Workflows:
- DMVAE tokenizer + Lightning-DiT/DiT prior; early stopping based on gFID; hyperparameter sweep of λ_DM, CFG, score net size.
- Assumptions/Dependencies: Reliable metrics (gFID, IS) for model selection; reproducibility and dataset coverage.
- Synthetic dataset creation for downstream tasks
- Sector: computer vision (classification, detection, segmentation)
- What: Generate class-conditional images with semantically structured latents to augment datasets, address class imbalance, or bootstrap new tasks.
- Tools/Workflows:
- Train DMVAE on labeled domains; generate samples via class-conditioned diffusion; validate improvements via downstream task metrics.
- Assumptions/Dependencies: Synthetic-to-real generalization; careful curation to avoid artifacts; license and consent for base data.
- Research tools for representation analysis
- Sector: academia
- What: Use DMVAE to probe how different reference distributions shape latent manifolds and downstream modeling difficulty.
- Tools/Workflows:
- Ablate priors (SSL, supervised, text, Gaussian/GMM, diffusion noise); visualize with t-SNE; correlate structure with reconstruction and generative metrics.
- Assumptions/Dependencies: Compute and expertise; study design to separate confounders (latent dimension, decoder capacity).
- Privacy-preserving image sharing via generative latents
- Sector: policy and privacy tech
- What: Replace raw images with latents for sharing/analysis; reconstruct only when permitted; optionally degrade personal attributes through latent editing.
- Tools/Workflows:
- DMVAE encoding pipeline with configurable semantic suppression; audit via reconstruction fidelity and re-identification tests.
- Assumptions/Dependencies: Legal frameworks; risk of re-identification from generated reconstructions; robust auditing needed.
- Stability/robustness improvements for training
- Sector: platform ML
- What: Adopt DMVAE’s stabilizing strategies (teacher initialization for student score, alternated training, low-d latent spaces) in other teacher–student or distillation tasks.
- Tools/Workflows:
- Port joint score alignment to model distillation; reuse noise scheduling and CFG tuning practices.
- Assumptions/Dependencies: Transferability beyond image tokenizers; careful tuning to avoid mode collapse.
Long-Term Applications
These applications require further research, scaling, engineering, or cross-domain adaptation before broad deployment.
- Unified tokenizers for audio, video, and 3D generation
- Sector: media, AR/VR, gaming, simulation
- What: Extend DMVAE to construct semantically meaningful latents for non-image modalities, accelerating generative modeling across media.
- Tools/Workflows:
- Choose modality-specific reference distributions (e.g., SSL audio features, video transformers, 3D point-cloud encoders); adapt score networks; build cross-modal priors.
- Assumptions/Dependencies: Mature SSL models in each modality; scalable teacher–student diffusion; alignment across temporal/spatial structures.
- Domain-specific generative twins and simulation
- Sector: robotics, autonomous driving, industrial IoT
- What: Use DMVAE latents aligned to domain semantics to generate realistic simulated environments, aiding training and testing (domain randomization and sim-to-real).
- Tools/Workflows:
- Train DMVAE on sensor data; generate scenario variations via latent traversal; integrate with simulator pipelines.
- Assumptions/Dependencies: High-fidelity decoders; validation against real-world performance; safety-critical evaluation.
- Generative compression standards and codecs
- Sector: standards bodies, telecom, streaming
- What: Formalize semantic latents and distribution matching as part of next-gen codecs, enabling interoperable generative reconstruction.
- Tools/Workflows:
- Propose bitstream formats for DMVAE latents; define reconstruction profiles; certify perceptual quality and bias/safety criteria.
- Assumptions/Dependencies: Industry consensus; hardware acceleration; content authenticity and watermarking mechanisms.
- Latent distribution design services and marketplaces
- Sector: platform ML, cloud providers
- What: Offer “prior-as-a-service” where clients select or learn bespoke reference distributions for their domain to optimize training efficiency and generation fidelity.
- Tools/Workflows:
- Catalog priors (SSL, supervised, text, multi-modal); provide benchmarking dashboards (rFID, PSNR, gFID); automated DMVAE training pipelines.
- Assumptions/Dependencies: IP/licensing for pretrained features; robust evaluation across domains; responsible AI governance.
- Personalized generative models with user-level priors
- Sector: consumer apps, creators, gaming
- What: Learn user-specific reference distributions (e.g., personal style/brand features) so latents encode personal semantics for tailored generation while retaining privacy.
- Tools/Workflows:
- On-device DMVAE fine-tuning; federated training of priors; editors for semantic controls.
- Assumptions/Dependencies: Efficient on-device training; privacy guarantees; UI/UX to manage semantic personalization.
- Cross-modal retrieval and reasoning
- Sector: search, knowledge management
- What: Combine image/text/audio priors to create joint latent spaces that enable robust cross-modal retrieval and multimodal reasoning.
- Tools/Workflows:
- DMVAE with multi-prior matching (e.g., DINO + CLIP + audio SSL), joint training of score networks; retrieval APIs.
- Assumptions/Dependencies: Stable multi-prior optimization; conflict resolution among priors; scaling teacher–student diffusion.
- Safety and watermarking via latent constraints
- Sector: policy/regulation, trust & safety
- What: Embed watermarking or provenance signals in the latent distribution structure; enforce safety constraints through reference priors designed to suppress harmful content.
- Tools/Workflows:
- Watermarked priors; audits using score-comparison tools; policy-compliant DMVAE training templates.
- Assumptions/Dependencies: Robustness against removal attacks; measurable provenance; alignment with legal and ethical norms.
- Energy- and cost-efficient training at scale
- Sector: cloud ML, sustainability
- What: Reduce training epochs and compute via modeling-friendly latents, contributing to greener and cheaper large-scale generative model development.
- Tools/Workflows:
- Auto-selection of priors based on downstream efficiency; dynamic λ_DM scheduling; adaptive score net sizing.
- Assumptions/Dependencies: Generalization of efficiency gains beyond ImageNet; standardized reporting of energy savings.
- Medical and scientific simulation
- Sector: healthcare, biotech, materials science
- What: Use DMVAE to construct latents that preserve clinically or physically relevant semantics for synthetic data, hypothesis generation, and simulation.
- Tools/Workflows:
- Reference distributions from domain encoders (e.g., histopathology SSL); pipelines for synthetic cohorts; validation studies.
- Assumptions/Dependencies: Regulatory approval; rigorous clinical validation; bias evaluation and mitigation.
- Content authenticity and provenance ecosystems
- Sector: media platforms, regulators
- What: Leverage structured latents to tag generative outputs with verifiable provenance signals tied to reference distributions and training configurations.
- Tools/Workflows:
- Latent-level signatures; verification APIs; dashboards for content moderation and transparency reporting.
- Assumptions/Dependencies: Cross-platform adoption; resilience to adversarial manipulation; user privacy considerations.
- Education and curriculum content generation
- Sector: education technology
- What: Generate high-quality, semantically consistent visual content aligned to curricular concepts by matching latents to concept-specific feature distributions.
- Tools/Workflows:
- Build priors for curricular taxonomies; DMVAE-based generators; teacher dashboards for quality control.
- Assumptions/Dependencies: Alignment of priors to learning goals; safeguards against bias/misinformation; accessibility requirements.
- General-purpose distribution alignment frameworks
- Sector: ML research
- What: Extend DMVAE’s teacher–student score-based distribution matching to broader representation learning and model distillation problems.
- Tools/Workflows:
- Libraries for score alignment; objective variants and stability tricks; benchmarks beyond images (graphs, time-series).
- Assumptions/Dependencies: Availability of suitable score models; theoretical advances for distant distribution matching; reproducible evaluation.
Notes on Feasibility and Risks
- Stability and convergence are sensitive to the distance between q(z) and p_r(z). The paper’s stabilizing strategies (teacher initialization, alternating updates, low-d latents) should be adopted and further tested.
- Choice of reference distribution is critical. SSL (DINO) priors offer the best balance observed; text priors may reduce reconstruction fidelity; synthetic priors (Gaussian/GMM) can simplify modeling but harm semantics.
- Metrics like gFID/IS do not fully capture downstream utility or safety. Domain-specific validation is needed.
- Legal and ethical constraints (privacy, consent, bias) apply to synthetic data and compression scenarios.
- Engineering effort is required to integrate teacher–student diffusion and DMVAE into production pipelines; hardware acceleration may be necessary for real-time applications.
Glossary
- Adversarial Autoencoders (AAE): A VAE-like model that uses adversarial training to match the latent distribution to a chosen prior. "Adversarial Autoencoders (AAE)~\cite{makhzani2015adversarial} uses a GAN-based objective to shape the latent distribution."
- Adversarial loss: A GAN-style objective added to improve perceptual quality in reconstruction or synthesis. "VQGAN~\cite{esser2021taming} further improved performance by integrating an adversarial loss into the VAE training objective"
- Aggregate posterior: The overall latent distribution induced by the encoder over the entire data, typically written as q(z). "DMVAE explicitly constrains the encoder's aggregate posterior to match an arbitrary, pre-defined reference distribution ."
- Autoregressive transformer: A generative model that predicts tokens sequentially using a transformer architecture. "or an autoregressive transformer~\cite{esser2021taming,ramesh2021zero}"
- β-VAE: A VAE variant that scales the KL term by β to control the strength of regularization. "The standard -VAE~\cite{kingma2013auto} framework trains the encoder "
- Classifier-free Guidance (CFG): A technique to improve diffusion sampling quality by guiding with unconditional and conditional scores. "do not employ guidance strategies such as Classifier-free Guidance~\cite{ho2022classifier}."
- Codebook: A discrete set of latent vectors used in vector-quantized models to represent inputs. "constraining the latent space to a finite, discrete codebook"
- Curse of dimensionality: The phenomenon where high-dimensional spaces make modeling and computation difficult. "thereby mitigating the curse of dimensionality."
- Diffusion model: A generative model that learns to denoise data from noise through a stochastic process. "such as a diffusion model~\cite{ho2020denoising,song2020score}"
- Diffusion Prior: Using a pre-trained diffusion model’s distribution as the prior over latents. "Diffusion Priors~\cite{li2025aligning} attempts to directly use a pre-trained diffusion model as the prior ."
- Distribution Matching Distillation (DMD): A method that aligns two implicit distributions by matching their score functions via diffusion. "we leverage Distribution Matching Distillation (DMD)~\cite{yin2024one}"
- Distribution Matching VAE (DMVAE): A VAE framework that matches the encoder’s aggregate posterior to any chosen reference distribution. "we propose Distribution Matching VAE (DMVAE), a novel generative framework"
- Discriminator: The adversarial network trained to distinguish between real prior samples and encoder latents in AAE. "An auxiliary discriminator is trained to distinguish between samples from the aggregate posterior and a reference prior ."
- ELBO (Evidence Lower Bound): The objective optimized by VAEs balancing reconstruction and KL divergence to a prior. "optimizing the Evidence Lower Bound (ELBO):"
- Flow matching objective: A training objective for diffusion/flow models that matches a prescribed velocity field to transport distributions. "using the flow matching objective~\cite{lipman2022flow}:"
- Gaussian Mixture Model (GMM): A probabilistic model representing a distribution as a mixture of Gaussian components. "Gaussian Mixture Model (GMM): A 10-component GMM"
- Generative prior: The distribution modeled over latent variables from which new samples are generated. "which is notoriously difficult for a generative prior to model."
- gFID: A generative Fréchet Inception Distance metric assessing sample quality of a generative model. "reaching gFID equals 3.2 on ImageNet with only 64 training epochs."
- Jacobian: The matrix of partial derivatives of a vector-valued function; computing it can be expensive in high dimensions. "the gradient computation involves the Jacobian of the score network"
- KL-constraint: A regularization that enforces closeness (via KL divergence) between posterior and prior distributions. "enforce a KL-constraint with a simple Gaussian"
- KL-divergence: A measure of difference between two probability distributions used to regularize VAEs. "The KL-divergence term acts as a regularizer"
- Latent diffusion model: A diffusion model trained in a learned latent space rather than pixel space for efficiency. "The latent diffusion model~\cite{rombach2022high}, built upon a VAE framework"
- Latent space: A lower-dimensional representation where data is compressed for modeling or reconstruction. "Most visual generative models compress images into a latent space"
- Lightning-DiT: A diffusion transformer architecture used for modeling latents and evaluating generative performance. "we then trained a Lightning-DiT~\cite{yao2025reconstruction} diffusion model"
- Manifold: A structured, possibly multi-modal latent geometry that models data; can become “holey” and hard to learn. "becomes a complex, multi-modal, and ``holey'' manifold"
- Mode collapse: A failure mode where a generative model produces limited diversity by collapsing to few outputs. "mode collapse, which is more severe than real score maximization."
- Mode dropping: A failure mode where some modes of the target distribution are not covered by the learned model. "Consequently, it suffers from mode dropping"
- Posterior collapse: A VAE pathology where the encoder’s outputs ignore inputs, collapsing to the prior. "can lead to posterior collapse\cite{sds}."
- Projection head: A small learnable module mapping encoder latents to the dimensionality of the reference distribution. "we introduce a light-weight, learnable projection head "
- PSNR: Peak Signal-to-Noise Ratio; a reconstruction metric measuring fidelity to original images. "evaluated its reconstruction quality on the validation set using PSNR and rFID."
- rFID: Reconstruction Fréchet Inception Distance; measures perceptual quality of reconstructions. "evaluated its reconstruction quality on the validation set using PSNR and rFID."
- Score function: The gradient of the log-density of a distribution, often learned by diffusion models. "to learn its score function ."
- Self-supervised learning (SSL): Learning representations without labeled data, often used as feature priors. "fixed self-supervised learning (SSL) features (e.g. DINO~\cite{caron2021emerging,oquab2023dinov2})"
- SigLIP: A text-embedding model used to provide a reference latent distribution. "text-embedding (SigLIP~\cite{zhai2023sigmoid}) distribution"
- SDE formulations: Stochastic differential equation formulations used to relate velocity and score in diffusion. "using SDE formulations~\cite{ma2024sit}"
- Stop-gradient: An operator that blocks gradient flow through a tensor during optimization. "where denotes a stop-gradient operator."
- t-SNE: A visualization technique for high-dimensional data to reveal clustering in 2D. "we performed a t-SNE visualization."
- Tokenizer: An autoencoder compressing images into a latent code for downstream generative modeling. "This approach first employs a powerful autoencoder, or ``tokenizer,'' to compress a high-dimensional image"
- Vector quantization: Mapping continuous features to discrete codebook entries for latent representations. "employ vector quantization, constraining the latent space to a finite, discrete codebook"
- VQ-GAN: A vector-quantized GAN-regularized autoencoder for high-quality image synthesis. "VQ-GAN~\cite{esser2021taming} employ vector quantization"
- VQ-VAE: A vector-quantized variational autoencoder that uses a discrete codebook for latents. "VQ-VAE~\cite{van2017neural} and VQ-GAN~\cite{esser2021taming} employ vector quantization"
Collections
Sign up for free to add this paper to one or more collections.

