- The paper demonstrates that separately processing body and background cues through a brain-inspired two-stream architecture significantly enhances action recognition.
- The methodology integrates YOLO v8 for segmentation and MotionNet for optical flow, validated using the Human Atomic Actions 500 dataset.
- Results show that the DomainNet model achieves near-human accuracy, particularly with body-only inputs, suggesting new avenues for neural network design.
Improving Action Classification with Brain-Inspired Deep Networks
Abstract
The paper "Improving action classification with brain-inspired deep networks" (2512.07729) investigates action recognition from visual input by exploring the potential for leveraging brain-inspired deep network architectures. The authors highlight the cognitive importance of perceiving others' actions, which is essential for understanding goals, emotions, and traits, and for applications such as robotics and healthcare monitoring. This study challenges the prevalent paradigms in deep learning by assessing how humans and artificial systems utilize body and background information for action recognition, proposing a novel architecture inspired by human brain selectivity for processing body and scene information separately.
Introduction
Humans inherently possess the ability to recognize actions amidst varied visual contexts, guided by specialized brain regions. While deep neural networks also perform action recognition, they often jointly process body and background information, potentially neglecting body-specific cues due to background correlation within training datasets. This paper probes the distinct effectiveness of humans in extracting both body and background information and introduces brain-inspired architectures to mimic this selective processing.
The authors demonstrate that traditional deep networks trained on datasets like the Human Atomic Actions 500 can perform adequately when both body and background are preserved but fail substantially when either is isolated. Humans, conversely, maintain recognition accuracy regardless of the presence of both cues, showing a preference for body-specific information. The paper implements a two-stream network architecture, inspired by the domain-specific pathways in the brain, to enhance action classification performance.
The domain-specific neural architecture builds upon established methodologies such as Dropout, which mitigates redundancy in network processing, albeit lacking the specific segmentation of body and background streams. Dropout ensures generalization through varied sub-network processing, yet fails to represent body and scene information effectively across separate channels. The paper also addresses advances in pose-estimation models that leverage body kinematics for action recognition, while asserting that simpler architectures can achieve similar improvements by integrating brain-inspired selectivity.
Additionally, the authors connect their work with foundations laid by vision-related neural network architectures, such as two-stream convolutional networks, inspired by the ventral and dorsal differentiation observed in human vision. This paper extends the concept by introducing category-selective processing that mirrors neural functionalities for object and scene categorizations in humans.
Methods
The study employs the Human-centric Atomic Actions 500 dataset, segmented into three categories: original, body-only, and background-only frames. Utilizing YOLO v8 for segmentation and MotionNet for optical flow computation, the authors facilitate a comparative analysis between human subjects and artificial networks. Their methodology involves training conventional neural networks alongside their proposed architecture, DomainNet, which separately processes body and background information.
Both Baseline and DomainNet models were evaluated on both static and dynamic features, using ResNet-50 architecture for frame processing. The DomainNet model incorporated cross-entropy loss terms across body, background, and combined stream outputs, ensuring optimized learning across all modalities of input.
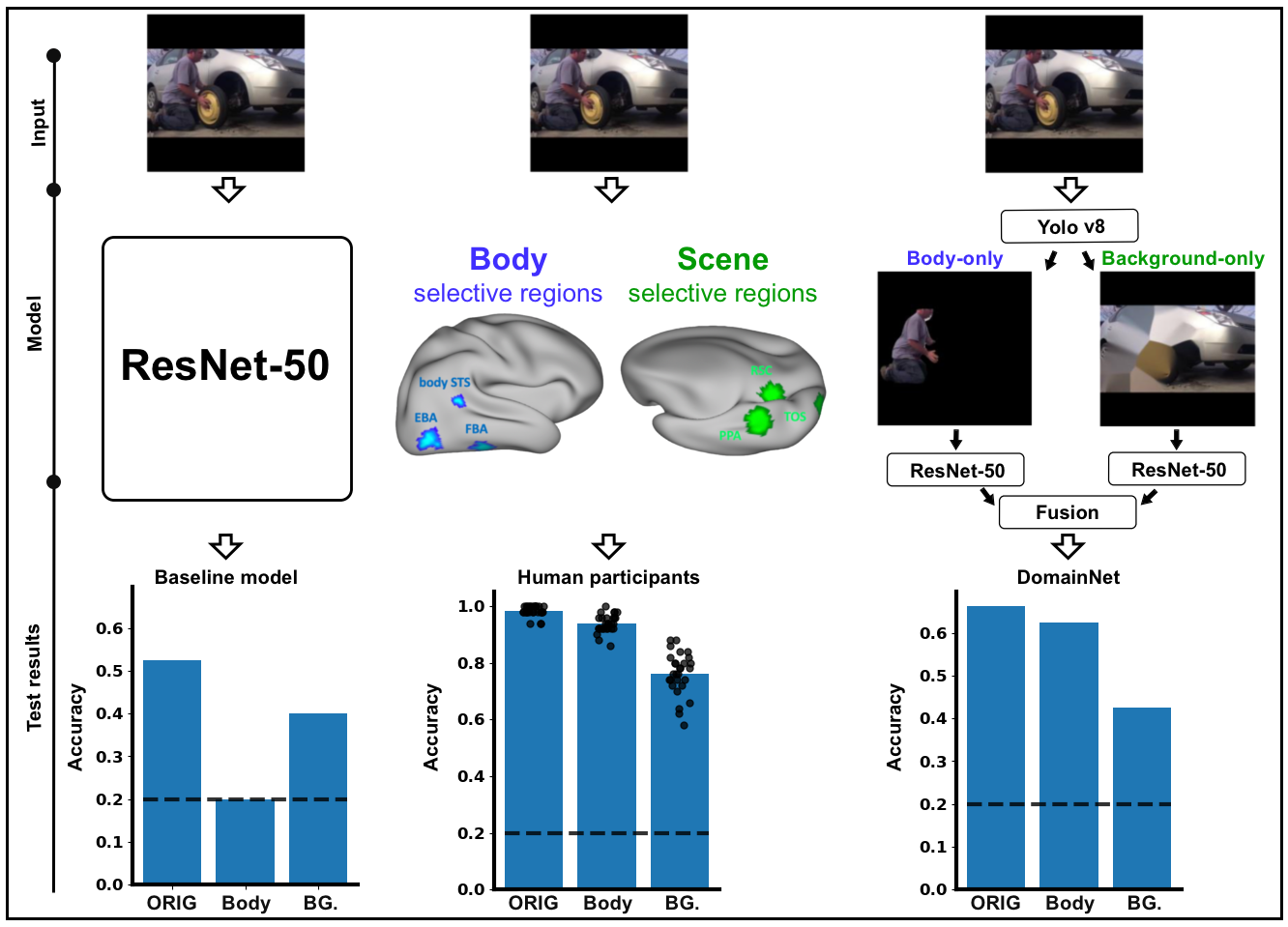
Figure 1: Comparison between network trained using original frames (Baseline:frames model), human results and brain-inspired two stream network (DomainNet:frames).
Results
Behavioral Results
Human participants displayed near-perfect accuracy in recognizing actions from original video inputs and maintained substantial accuracy even when restricted to body-only inputs. Conversely, recognition accuracy dropped when limited to background-only stimuli. These findings suggest a predominant reliance on body cues for action inference, aligning with the hypothesis of domain-specific processing pathways in the brain.
Modeling Results
Baseline Models: Traditional Baseline networks exhibited poor performance on body-only stimuli, indicating a bias towards learning background-specific features, exacerbated by optic flow addition which offered mild improvements but did not resolve the recognition deficiency.
Domain-Specific Models: The novel brain-inspired architecture achieved higher accuracies across all stimuli types, notably enhancing body-only recognition performance, thereby presenting more human-like accuracy patterns. Optic flow integration further amplified the model's proficiency in discerning body-centric actions.
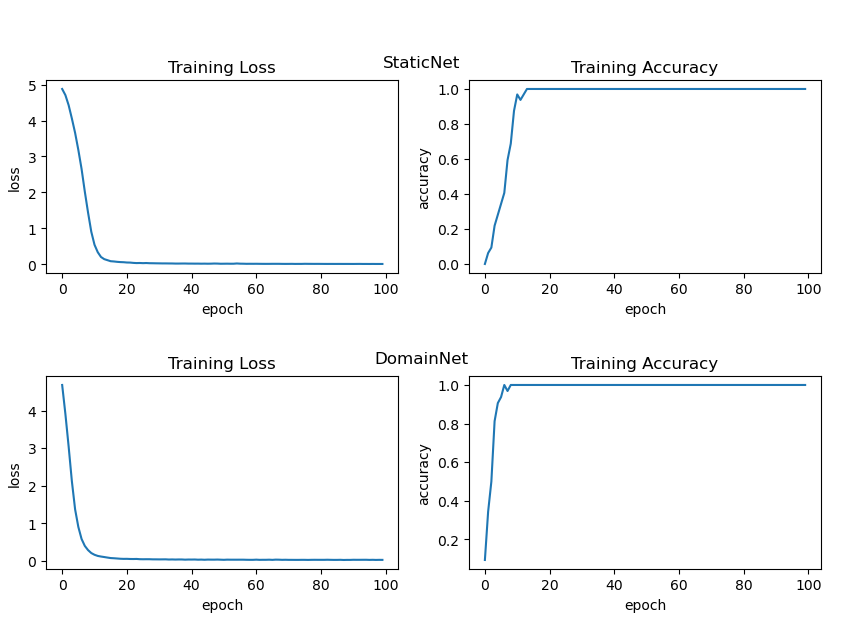
Figure 2: Training dynamics for networks tested, with both Baseline and DomainNet models converging efficiency in fewer than 20 epochs.
Discussion
The authors have confirmed that distinct processing of body and background information in deep networks leads to improved action classification, mirroring human capabilities. This approach not only bridges gaps between neural networks and human perceptual mechanisms but also offers insights into the evolutionary architecture of brain regions responsible for category selectivity. The implications extend to enhancing artificial vision systems and fostering collaborations between cognitive neuroscience and machine learning.
Conclusion
The research lays groundwork for future exploration into brain-inspired network architectures, urging the integration of category-selective pathways into advanced learning models such as transformers and foundation models. By employing cross-disciplinary perspectives, this study advances understanding of perception, both artificial and biological, and proposes paradigms for optimizing action recognition technology.