- The paper introduces a novel CADE framework that merges continual learning with weakly-supervised anomaly detection to address catastrophic forgetting.
- It employs dual-generator modeling and multi-discriminator ensembles to effectively capture rare anomaly distributions and maintain past knowledge.
- CADE achieves superior AUC performance on multi-scene datasets, nearly matching multitask learning oracles while ensuring memory efficiency.
Continual Weakly-supervised Video Anomaly Detection: The CADE Framework
Introduction
The paper "CADE: Continual Weakly-supervised Video Anomaly Detection with Ensembles" (2512.06840) systematically addresses the intersection of continual learning (CL) and weakly-supervised video anomaly detection (WVAD), a junction that has been largely ignored in prior research. Classical WVAD methods focus on static datasets, neglecting practical scenarios where video domains change due to scene, time, or environmental shift. In these dynamic contexts, catastrophic forgetting critically degrades model performance on previously encountered domains when models are fine-tuned with new domains. Addressing this, CADE introduces a novel architecture that merges generative replay, dual-generator modeling, and ensemble-based discrimination, offering significant improvements in detection accuracy and retention of past knowledge under continual domain shifts.
VAD in surveillance settings typically requires domain adaptation as scenes and environmental conditions evolve. While weak supervision reduces annotation cost, its practical deployment is challenged by catastrophic forgetting when sequentially learning from multi-domain streams. Existing methods either neglect this regime or use straightforward fine-tuning, resulting in severe performance decay for past domains, as illustrated by rapid degradation of anomaly scores in legacy methods under continual retraining.
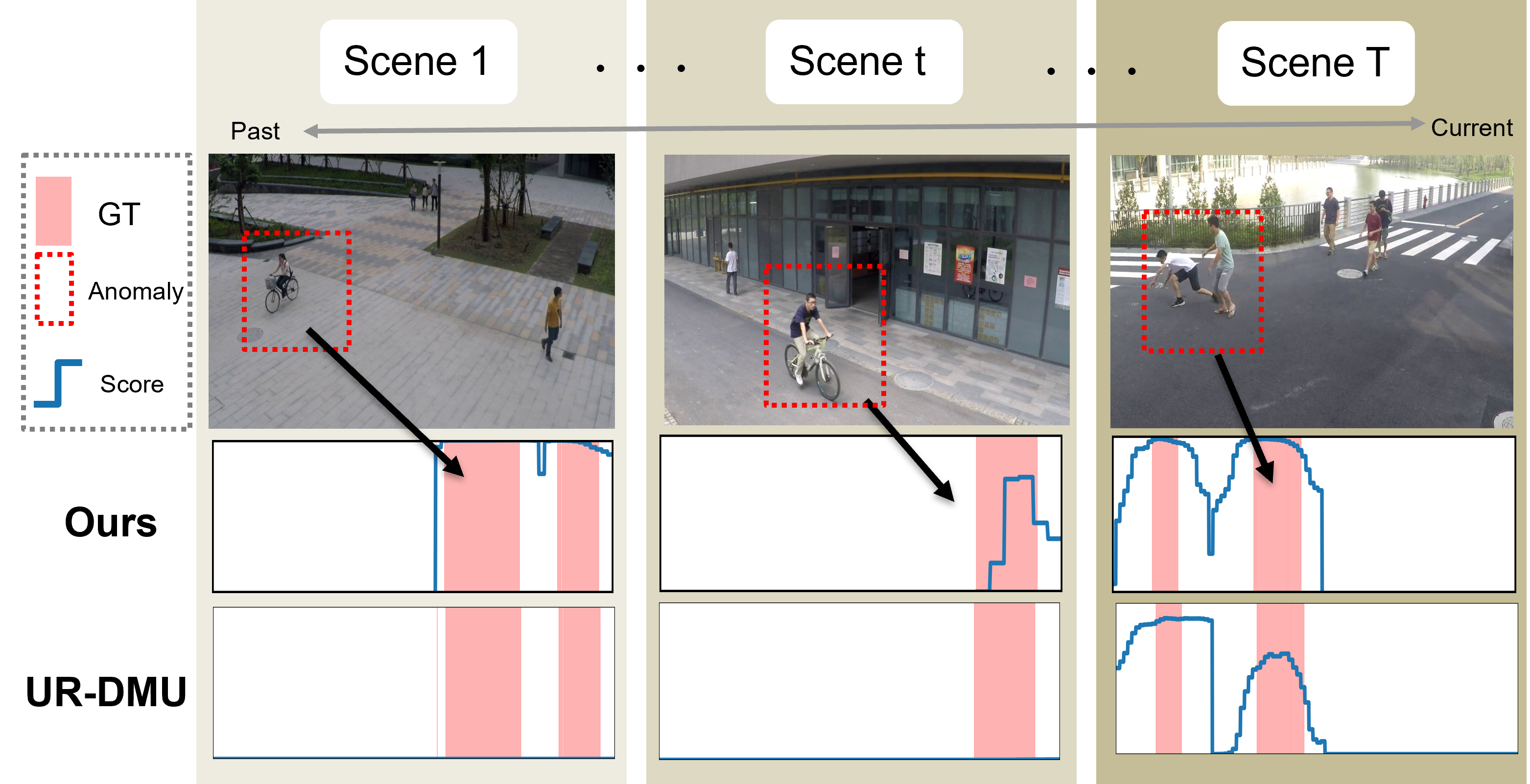
Figure 1: CADE maintains robust anomaly scoring across sequential multi-scene training, whereas conventional UR-DMU rapidly forgets past domains due to catastrophic interference.
CADE’s methodological core is situated in the domain incremental learning (DIL) regime, where data arrives in domainwise increments and data from outdated domains becomes inaccessible. Common continual learning approaches such as regularization (EWC, SI) and rehearsal (iCaRL) either impose severe memory demands or insufficiently address the unique class-imbalance and annotation-noise present in WVAD. CADE proposes a generative replay (GR) paradigm but critically augments this with architecture- and ensemble-level innovations specifically tailored for WVAD.
CADE Architecture
CADE comprises three integral modules: Dual-Generator (DG), Multi-Discriminator (MD), and an inference-time ensemble framework. The architecture is designed to be modular, allowing integration into any WVAD method based on a classification pipeline.
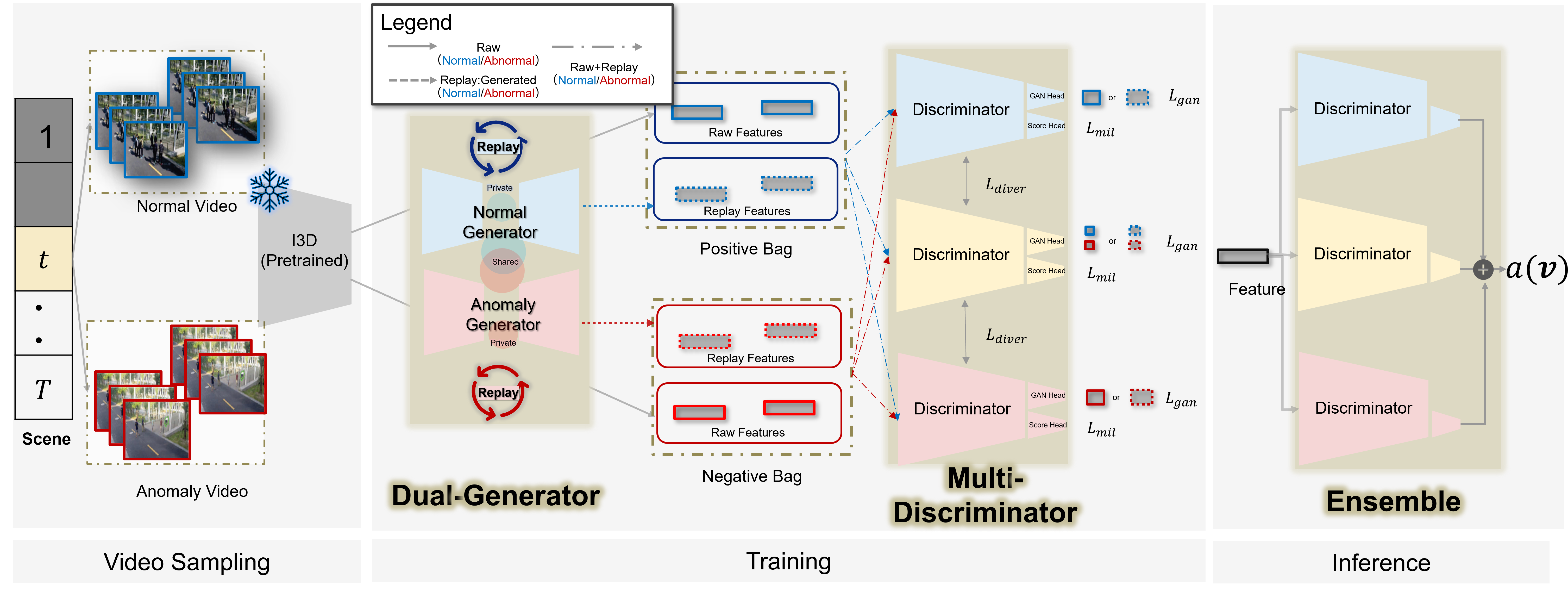
Figure 2: CADE’s architecture consists of a Dual-Generator for disjoint modeling of normal/anomaly classes, a Multi-Discriminator ensemble, and efficient inference-time ensembling, enabling native adaptation to domain-incremental learning.
Dual-Generator and Generative Replay
Unlike classical GR that utilizes a single generator (typically GAN-based) to approximate the historical data distribution, DG splits the generative process into separate normal and anomaly components. This approach more effectively learns rare anomaly distributions and accommodates the profound imbalance present in real-world WVAD datasets. By exploiting private and shared latent spaces—following DMVAE principles—the model achieves better disentanglement, thus enhancing replay fidelity.
Each generator is paired with an adversarially trained discriminator, and replayed pseudo-features from these generators are continually supplied to the discriminators during training, mitigating representation drift and supporting the retention of past domain knowledge without persistent storage of real data samples.
Multi-Discriminator Ensemble
Generative replay alone is insufficient since the incompleteness issue—where classifiers become biased toward recent anomaly modes—remains prominent under CL. To address this, CADE ensembles multiple discriminators (MD), each adversarially trained alongside the generators. Intermediate feature diversity is promoted via an orthogonality-inducing loss, ensuring that the discriminators capture distinct anomaly subspaces. During inference, the system aggregates anomaly scores from all discriminators, improving the recall of rare or forgotten anomaly modes.
Inference-Time Ensembling
At inference, anomaly scores over candidate video segments are averaged across all discriminators to yield the final prediction. This ensemble strategy, rather than employing independently trained models, re-uses discriminators already present in the generative replay mechanism—amortizing the computational cost of ensemble learning. This yields considerable gains in prediction robustness, especially in domains with sparse anomaly labels and distribution shifts.
Experimental Analysis
CADE is rigorously evaluated on three canonical multi-scene datasets: ShanghaiTech (SHT), Charlotte Anomaly Dataset (CHAD), and UCF-Crime, each partitioned according to authentic scene/domain boundaries. Metrics follow prior work, namely the area under the ROC curve (AUC), assessed frame-wise across all domains after sequential learning.
Comparison with Baselines
CADE is instantiated atop several recent WVAD backbones (MIST, Sultani et al., RTFM, UR-DMU) and compared with fine-tuning (FT), regularization-based CL (EWC, SI), and rehearsal-based CL (iCaRL), as well as a multitask learning (MTL) oracle.
CADE consistently achieves the highest post-training AUC among all CL-compatible regularization and replay approaches, attaining—when combined with MIST on SHT—an AUC of 0.849 (vs. FT: 0.564), nearly matching the upper-limit multitask oracle at 0.852. Notably, CADE’s benefit is accentuated as number of scene transitions increases, illustrating its resilience in long-horizon continual regimes and its suppression of catastrophic forgetting.
Visualization and Qualitative Impact
CADE’s preservation of anomaly detection in prior domains is vividly revealed in qualitative score profiles.
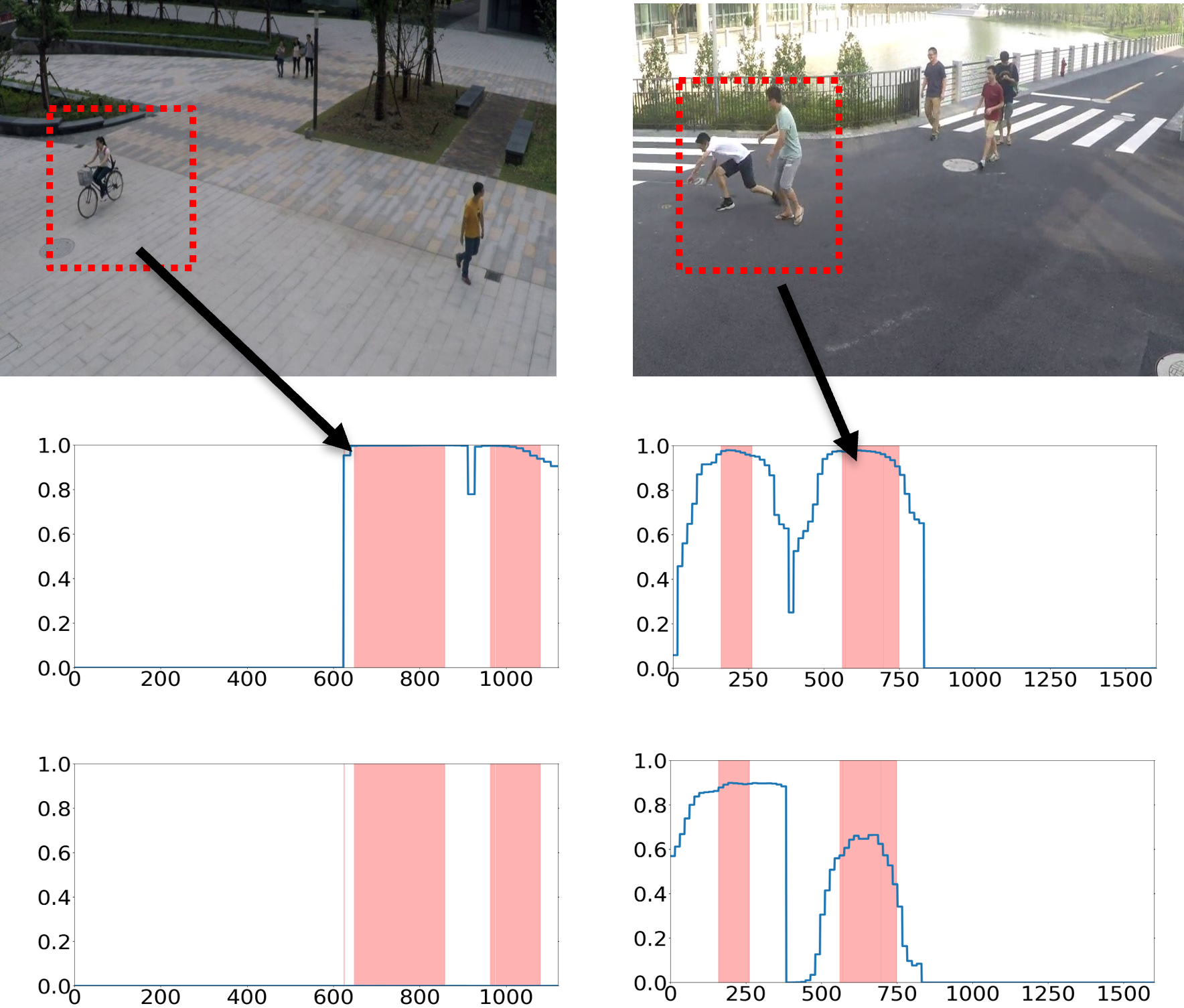
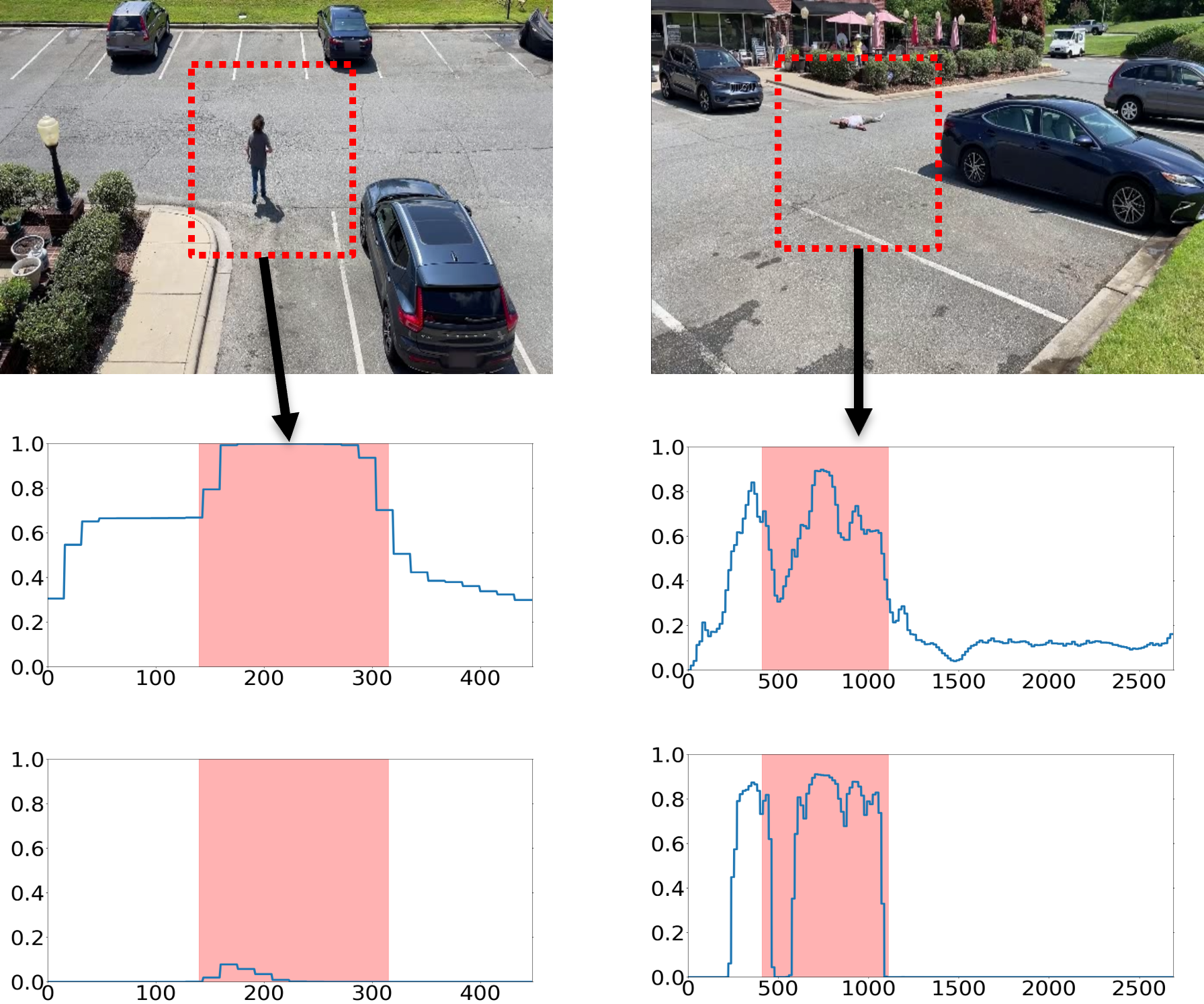
Figure 3: Visualized anomaly detection scores on SHT (left) and CHAD (right); CADE (upper) persistently detects anomalies from early (left column) and late (right column) scenes, while FT-UR-DMU (lower) erases previous anomaly detection capabilities as new domains are assimilated.
Such visual evidence underscores the preservation of knowledge about rare events, a crucial capability for operational VAD systems deployed in non-stationary environments.
Ablation Studies
Systematic removal of CADE’s components demonstrates that both the DG and MD ensembles are essential for optimal performance. Adding DG alone yields AUC improvements exceeding 0.10 on SHT; combining with MD and a latent-space distance loss further increases robustness to label noise and mode incompleteness. Replay ratio sensitivity studies show that even moderate ratios suffice, attesting to the memory efficiency of the approach. Performance scales positively with the number of sequential domains, indicating efficient knowledge transfer.
Implications and Future Directions
CADE’s innovations have significant implications for real-world video surveillance, enabling retention of broad anomaly vocabularies in continuously evolving environments without persistent storage of raw footage—a key privacy and infrastructure requirement. Architecturally, CADE’s modular discriminators and ensemble-friendly design suggest compatibility with broader families of WVAD and MIL systems. Moreover, the dual-generator approach opens avenues for replay and generative modeling in imbalanced and weak-label settings beyond VAD.
Potential future directions include:
- Integration with multi-modal architectures (e.g., audio-visual LLMs) to address even more subtle anomaly cues.
- Exploration of more efficient discriminators for edge deployment scenarios.
- Application of CADE-style ensembles to other domains such as medical anomaly detection and industrial quality control.
Conclusion
CADE provides a unified continual learning and weakly-supervised anomaly detection framework that robustly mitigates catastrophic forgetting in realistic, domain-variant video environments. By combinatorially leveraging dual-generative replay and modular discriminator ensembles, CADE delivers state-of-the-art detection accuracy and theoretical advancements in both VAD-specific and broader continual learning contexts. Substantial empirical gains across standard benchmarks highlight the architectural and methodological contributions, positioning CADE as a foundation for further research in deployable, privacy-compatible anomaly detection in dynamic settings.