- The paper introduces a latent variable framework that captures LLM scaling laws by linking latent skills to benchmark performance.
- The methodology employs beta distribution modeling and likelihood estimation with anchor benchmarks to ensure robust statistical inference.
- Empirical validation demonstrates distinct latent skills across benchmarks, offering insights for performance prediction and resource allocation.
A Latent Variable Framework for Scaling Laws in LLMs
Introduction
The paper introduces a latent variable framework designed to model the scaling laws of LLMs. These models are characterized by their capacity to deliver state-of-the-art performance across various benchmarks, such as instruction following, common-sense reasoning, and logical reasoning. Traditional scaling laws tend to focus on metrics such as validation loss, neglecting the nuanced interdependencies across different model architectures and benchmarks. The proposed framework aims to capture these complexities using a latent variable approach, offering a more holistic view of how LLMs scale across different dimensions of performance.
Methodology
The core of the framework lies in representing each LLM family by a latent variable that encapsulates its innate capabilities. These latent variables, together with observable features of the models, drive the performance outcomes across various benchmarks. The model assumes a beta distribution for the benchmark responses, with parameters linked to these latent skills. Estimation of these latent variables and their impact on scaling laws is accomplished through a likelihood-based estimator, complemented with statistical guarantees for consistency and asymptotic distribution.
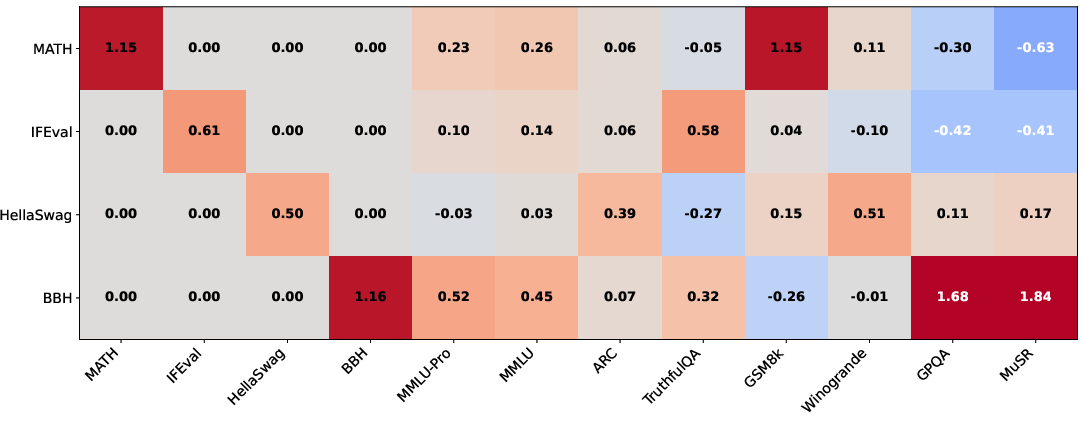
Figure 1: Estimated loadings for the K=4 model. In the vertical axis, our K skills correspond to mathematical skills (MATH), instruction following (IFEval), common-sense reasoning (HellaSwag), and logical/linguistic reasoning (BBH).
Theoretical Foundations
The theoretical framework is supported by assumptions typical of latent variable modeling, ensuring that the estimation process converges to true parameter values as the number of LLM families increases. The model's identifiability is enhanced through the selection of anchor benchmarks that uniquely correspond to specific latent skills, thereby enabling meaningful interpretation of latent variables. Statistical inference is facilitated by deriving the asymptotic distribution of the estimator, which is crucial for constructing prediction intervals for LLM performance.
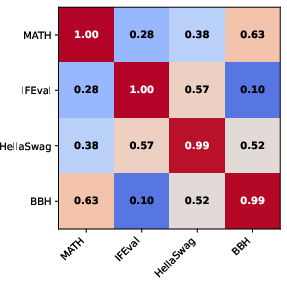
Figure 2: Correlation matrix of the latent random effects.
Empirical Validation
Empirical validation is conducted on data from the Open LLM Leaderboard using benchmarks such as MATH, IFEval, HellaSwag, and BBH. The framework successfully detects distinct latent skills associated with different benchmarks, revealing intricate correlations between them. For instance, the BBH dimension shows strong correlations with both MATH and HellaSwag, highlighting overlaps in underlying cognitive skills.
Applications and Implications
The proposed framework offers significant implications for both theoretical advancements and practical applications in AI research. It allows researchers to predict the performance of untested LLM configurations effectively and guides the optimal allocation of computational resources. Additionally, it provides insights into how LLMs can be scaled optimally for specific skills, accommodating diverse model architectures and training paradigms.
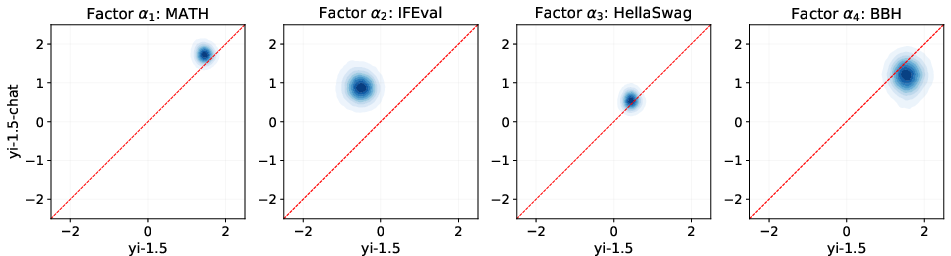
Figure 3: Joint density plot comparing the skills random intercepts (αl) of Yi-1.5 and Yi-1.5-chat models, highlighting the enhanced instruction following capability of the chat variants.
Prediction and Optimization
A noteworthy application is the construction of prediction intervals, offering a robust measure of uncertainty around predicted performance on unseen benchmarks. This is complemented by the development of skill-specific scaling strategies, allowing for precision in the expansion of model capabilities under fixed computational budgets. Through this framework, practitioners can derive optimal model configurations to maximize specific skills, such as mathematical reasoning or instruction following, within computational constraints.
Conclusion
The introduction of a latent variable framework for LLM scaling laws marks a significant methodological advance, supporting nuanced analyses of how LLM capabilities evolve with scale. By embedding statistical rigor within a flexible modeling structure, this framework provides a comprehensive toolset for understanding and optimizing the performance of LLMs across diverse benchmarks. Future research directions include extending the method to accommodate additional modalities and further refining the latent structure to capture more complex dependencies among LLM families.