- The paper introduces a meta-training framework that uses context-target pairs from human play videos for few-shot humanoid manipulation.
- The methodology employs similarity-based context retrieval and visual masking to bridge the human-robot visual gap and enhance action prediction.
- Experimental results show significant improvements in success rates and reduced grasping errors across simulation benchmarks and real-world evaluations.
MimicDroid: In-Context Learning for Humanoid Robot Manipulation from Human Play Videos
Introduction and Motivation
MimicDroid addresses the challenge of enabling humanoid robots to perform few-shot learning for manipulation tasks by leveraging in-context learning (ICL) from human play videos. The method is motivated by the need for scalable, diverse training data and rapid adaptation to novel objects and environments, which are not feasible with traditional teleoperated robot demonstrations due to their high cost and limited diversity. Human play videos, consisting of continuous, unscripted interactions, provide a rich source of task-agnostic data, capturing a wide range of manipulation behaviors and object configurations.
Methodology
MimicDroid's core innovation is the use of meta-training for ICL, where context-target pairs are constructed from human play videos. For each target segment, the method retrieves the top-$k$ most similar trajectory segments based on observation-action similarity, forming the context for in-context learning. The policy is trained to predict the actions of the target segment conditioned on the context, instilling the ability to exploit recurring observation-action patterns for rapid adaptation.
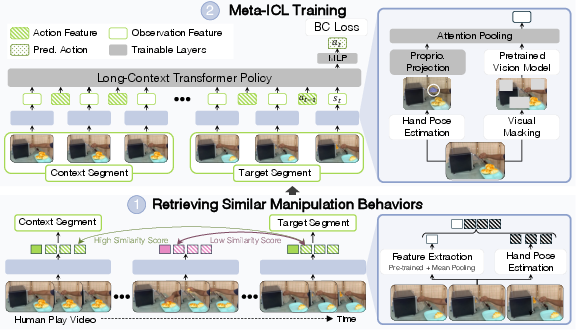
Figure 1: MimicDroid's meta-training pipeline constructs context-target pairs from human play videos, applies visual masking to bridge the human-robot visual gap, and enables in-context learning for humanoid manipulation.
To overcome the embodiment gap, MimicDroid retargets human wrist poses estimated from RGB videos to the humanoid robot, leveraging kinematic similarity. Visual masking is applied during training to reduce overfitting to human-specific cues, improving transferability to robot embodiments.
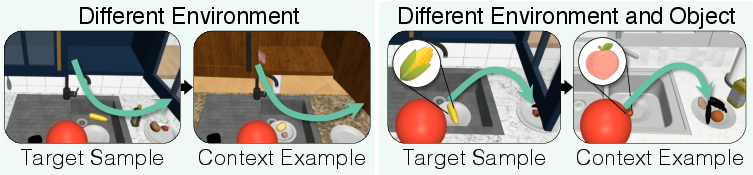
Figure 2: Examples of target and retrieved context segments, illustrating the similarity-based retrieval mechanism for constructing in-context learning samples.
Simulation Benchmark and Evaluation Protocol
A novel simulation benchmark is introduced to systematically evaluate few-shot learning for humanoid manipulation. The benchmark comprises 8 hours of play data across 30 objects and 8 kitchen environments, with evaluation structured into three levels of increasing difficulty:
- L1: Seen objects and environments
- L2: Unseen objects, seen environments
- L3: Unseen objects and environments
This structure enables rigorous assessment of generalization capabilities across both abstract (free-floating hand) and humanoid (GR1) embodiments.
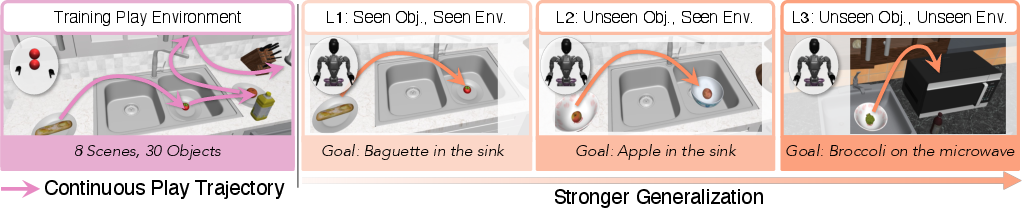
Figure 3: Simulation benchmark overview, showing the diversity of objects, environments, and the systematic evaluation protocol for generalization.
Implementation Details
The policy model is built on a long-context transformer backbone with modality-specific encoders for vision and proprioception. Training samples consist of three context trajectories and one target trajectory, with each trajectory processed into observation-action pairs using hand pose estimation (WiLoR) and visual feature extraction (DinoV2). Random patch masking is applied to input images with high probability, and the policy predicts action chunks to model the multimodal nature of human play data.
Key implementation parameters include:
- Context retrieval: Top-$k$ similar segments ($k=10$ for training, $k$ varied for ablation)
- Action prediction: 32-step action chunks per timestep
- Visual masking: 1–16 random patches per image, $p=0.8$
- Training hardware: 8×A5000 GPUs, 200 epochs
Experimental Results
Generalization and Few-Shot Learning
MimicDroid demonstrates superior generalization through ICL compared to task-conditioned baselines (Vid2Robot, H2R) and parameter-efficient fine-tuning (PEFT). In simulation, MimicDroid achieves up to 0.73 success rate in L1 (abstract), 0.44 in L2 (humanoid), and 0.27 in L3 (abstract), outperforming all baselines. In real-world evaluations, MimicDroid attains a twofold improvement over Vid2Robot, with success rates of 0.53 (L1), 0.23 (L2), and 0.08 (L3).
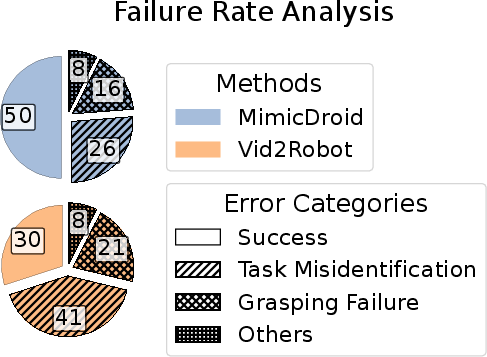
Figure 4: MimicDroid achieves higher success rates and reduces task misidentification and grasping errors compared to baselines, highlighting the efficacy of in-context learning.
Ablation Studies
- Number of in-context examples: Performance increases with more context examples, plateauing beyond three due to training-time context length constraints.
- Context retrieval ($k$): Performance benefits from more retrieved segments but degrades with excessive noise at high $k$.
- Training data scaling: Consistent improvements are observed as training data increases, with L1 and L2 showing +24% absolute gains when scaling from 128k to 320k frames.
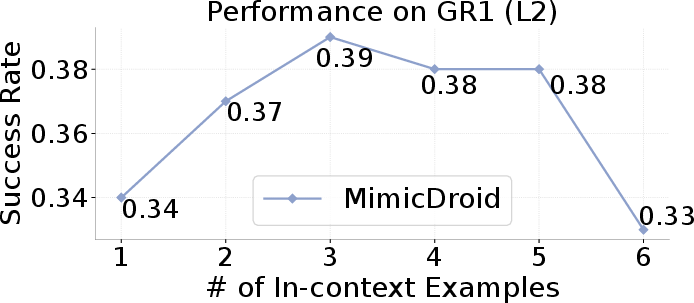
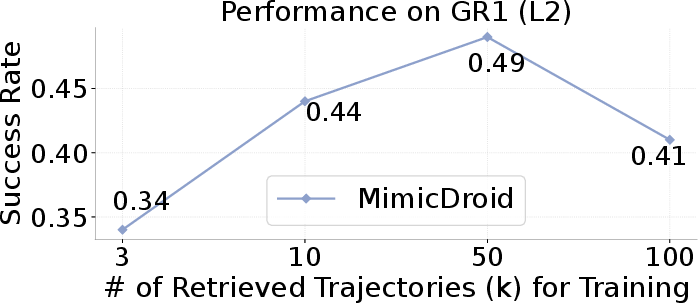
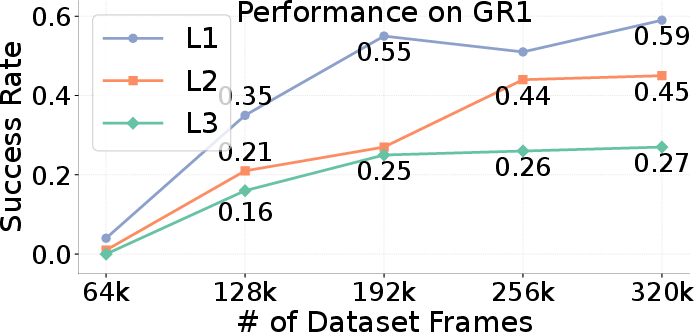
Figure 5: Performance trends with number of in-context examples, context retrieval size, and training data scaling, demonstrating the importance of data diversity and context selection.
Visual Gap Bridging
Visual masking is critical for transferability. Removing masking results in a sharp drop in performance ($-17\%$) when transferring to the humanoid embodiment, compared to only $-3\%$ with masking. Random patch masking matches the performance of hand-specific masking strategies (EgoMimic) without requiring external segmentation modules.
Failure Analysis
Failure cases are dominated by task misidentification (26%), missed grasps (16%), and other errors (8%). MimicDroid reduces both misidentification and grasping errors compared to Vid2Robot, but struggles with novel motion sequences in L3 and overfits to specific hand sizes in cluttered environments.
Real-World Generalization
MimicDroid generalizes to both seen and unseen objects and environments in real-world evaluations, performing pick-and-place and articulated object manipulation tasks with high data efficiency.

Figure 6: Real-world evaluation examples, showing MimicDroid's ability to generalize to novel objects and environments using few-shot in-context learning.
Limitations and Future Directions
Current limitations include reliance on high-quality human play videos, action extraction via hand pose estimation (which fails under occlusion), and lack of semantic generalization across task variants. Future work should explore augmentation with web-scale human videos, integration of full-body motion estimation, and meta-training with language-trajectory pairs to enable semantic generalization.
Conclusion
MimicDroid establishes a scalable framework for few-shot humanoid manipulation via in-context learning from human play videos. By leveraging meta-training on context-target pairs, retargeting human wrist poses, and applying visual masking, MimicDroid achieves strong generalization and data efficiency in both simulation and real-world settings. The method sets a foundation for future research in adaptive robot assistants capable of learning from diverse, unscripted human interactions.

