BulletTime: Decoupled Control of Time and Camera Pose for Video Generation (2512.05076v1)
Abstract: Emerging video diffusion models achieve high visual fidelity but fundamentally couple scene dynamics with camera motion, limiting their ability to provide precise spatial and temporal control. We introduce a 4D-controllable video diffusion framework that explicitly decouples scene dynamics from camera pose, enabling fine-grained manipulation of both scene dynamics and camera viewpoint. Our framework takes continuous world-time sequences and camera trajectories as conditioning inputs, injecting them into the video diffusion model through a 4D positional encoding in the attention layer and adaptive normalizations for feature modulation. To train this model, we curate a unique dataset in which temporal and camera variations are independently parameterized; this dataset will be made public. Experiments show that our model achieves robust real-world 4D control across diverse timing patterns and camera trajectories, while preserving high generation quality and outperforming prior work in controllability. See our website for video results: https://19reborn.github.io/Bullet4D/
Sponsor








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces BulletTime, a method for making AI-generated videos where you can separately control two things:
- the “world time” (how fast or slow events in the scene happen), and
- the camera’s position and direction (where you look from).
Think of it like filming an action scene where you can freeze the moment while flying the camera around the subject (the “bullet time” effect), or slow down the action while the camera keeps moving smoothly—without the usual glitches. The goal is to create videos that feel like real 3D worlds over time (that’s the “4D”: 3D space + time).
What questions did the researchers ask?
Here are the main questions they wanted to solve:
- Can we stop video models from mixing up “what is happening” (the scene’s action) with “where we’re looking from” (the camera motion)?
- Can we let users precisely control time in the scene (pause, slow down, speed up, reverse) independently from camera movement?
- Can we do this inside one video-generating model, without extra steps like rebuilding a full 3D scene after generation?
How did they do it?
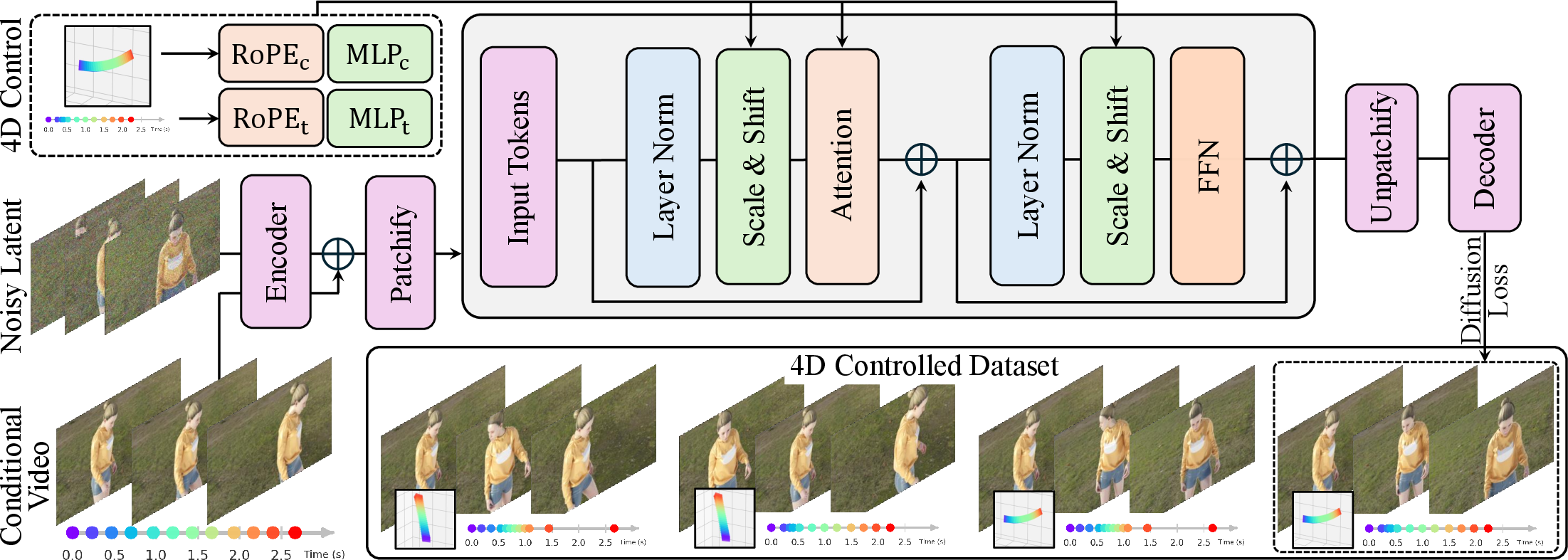
The researchers started with a powerful video diffusion model (a type of AI that turns random noise into a realistic video through many tiny improvements) and added two control signals:
- World time (like a clock that says when each frame happens in the scene).
- Camera pose (like where your phone is in space and which direction it points).
They used two main ideas to inject these signals into the model in ways the model understands:
- Time-aware positional encoding (called Time-RoPE): Imagine the model needs a label that says “this frame happened at 1.2 seconds, and the next one at 2.0 seconds.” Time-RoPE is a clever way of encoding continuous (smooth) time differences directly inside the model’s attention mechanism (the part that decides which parts of the video should influence each other). This helps the model handle non-uniform timing—like pausing, slowing down, or speeding up—in a natural way.
- Time-conditioned adaptive normalization (called Time-AdaLN): Think of this as a set of “dimmer switches” that gently adjust the model’s internal features based on the world time. Instead of pushing a lot of extra tokens into the model (which can cause messy results), this method smoothly scales and shifts the features so the timing feels stable and consistent.
To fully control both time and camera, they extended these ideas:
- 4D positional encoding (4D-RoPE): This combines time information with camera geometry, so the attention mechanism understands both when an event happens and where the camera is. It helps the model generate frames that look correct from any viewpoint at any time.
- Camera-conditioned adaptive normalization (Camera-AdaLN): Similar to Time-AdaLN, but for the camera. It uses simple learned adjustments so the model follows the desired camera path cleanly.
Finally, they built a special training dataset: synthetic (computer-generated) scenes where time changes (like slow-motion or pauses) and camera paths vary independently. This gives the model clean examples for learning how to keep time and camera control separate.
What did they find?
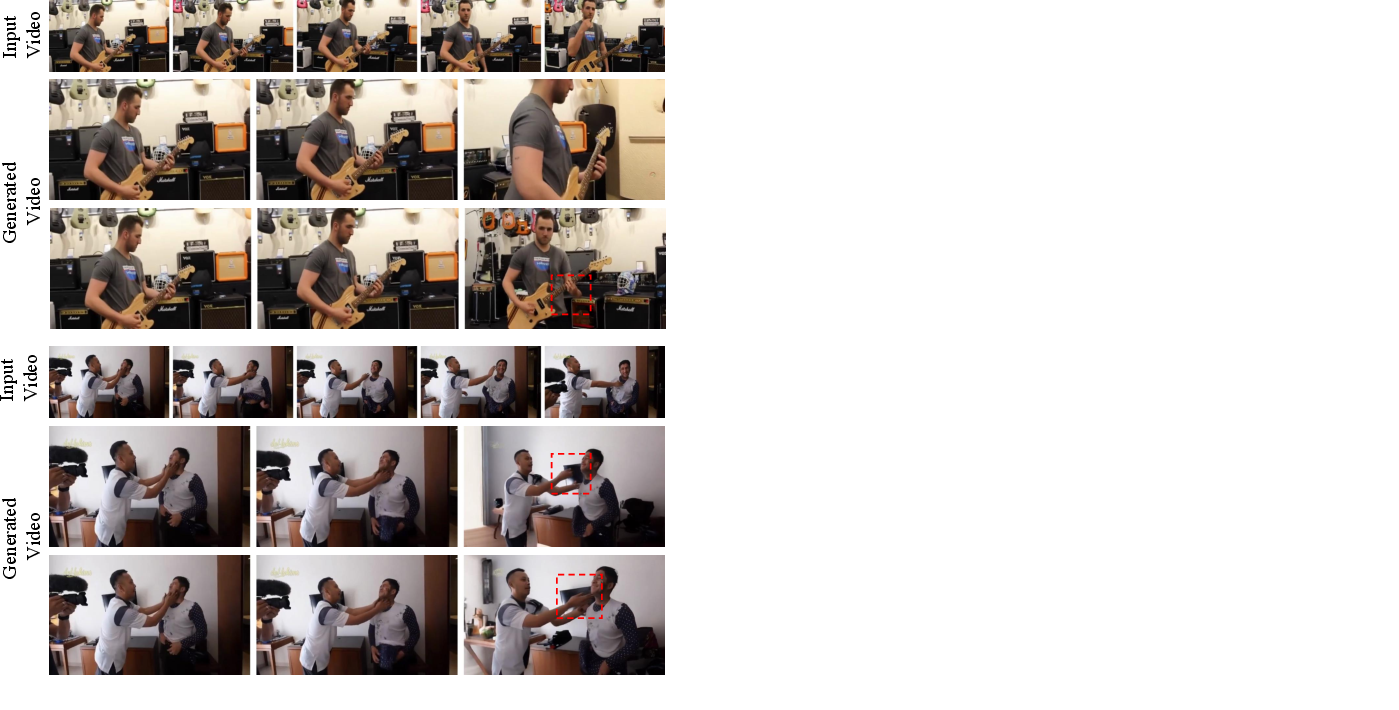
The method worked well in both synthetic and real videos:
- Better control: The model follows camera paths more accurately and handles time changes (pause, slow, speed) smoothly—at the same time.
- Higher quality: Videos look sharper, flicker less, and keep the subject and background consistent across frames.
- Bullet-time effect: The model can freeze a moment and move the camera around it cleanly, showing strong separation between “when” and “where.”
- No extra reconstruction: It doesn’t need a heavy second step to build a full 3D scene; the control happens inside the video model directly.
In tests, BulletTime outperformed methods that only controlled the camera (and tried to fake time control by pre-editing the input video). Those older methods tended to produce artifacts or lose consistency when time was changed.
Why does this matter?
This research makes video generation more like directing a real scene:
- Filmmakers and creators can produce dramatic effects (like bullet time) more easily.
- Game and XR (VR/AR) developers can let players move around a moment in time, explore scenes, or replay events from new angles.
- Robotics and simulation can benefit from precise control over both viewpoint and timing to analyze actions safely.
- Future “world models” (AI that understands and simulates the physical world) can use this technique to model dynamic scenes more realistically.
Overall, BulletTime is a step toward video tools where you decide both when events happen and how you view them, with clean, high-quality results.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to be concrete and actionable for future work.
- Real-world disentangled supervision: The model is trained only on a synthetic dataset with independently parameterized time and camera. There is no real-world dataset with independently varying world time and camera pose, calibrated intrinsics/extrinsics, and accurate world-time labels. Capture protocols, annotation standards, and release of a real dataset for disentangled 4D control are open.
- Domain gap quantification and mitigation: The paper claims generalization from synthetic to real videos, but lacks a systematic analysis of domain shift (e.g., lighting, materials, physics, occlusions). Study domain adaptation strategies (e.g., test-time adaptation, synthetic-to-real fine-tuning, weakly supervised disentanglement) and quantify performance across diverse real distributions.
- Long-horizon and persistent worlds: Inference remains parallel (non-autoregressive), limiting sequence length (81 frames) and memory of persistent states. Evaluate scalability to minutes-long videos, propose streaming or recurrent/autoregressive 4D diffusion, and measure temporal drift, identity consistency, and scene state persistence beyond hundreds/thousands of frames.
- Robustness to large camera baselines and extreme trajectories: The method’s behavior under large viewpoint changes, strong parallax, fast rotations, rolling shutter, and motion blur is not characterized. Provide stress tests across camera baselines and trajectory shapes (e.g., spirals, high-speed orbits) and analyze failure modes.
- Reliability of camera-control evaluation in real videos: Camera accuracy is assessed by estimating poses from generated outputs (MegaSAM) and comparing to target controls; this assumes the estimator is accurate and unbiased. Validate with ground-truth cameras (e.g., controlled captures), quantify estimator error, and explore alternative direct measures (e.g., 2D-3D reprojection consistency with recovered geometry).
- Continuous-time control limits and extrapolation: Time-RoPE uses continuous rotations that can wrap and alias for large time offsets. There is no analysis of frequency scales (b), aliasing, or stability for extreme slow/fast motion, time reversal, or long pauses. Provide theoretical and empirical characterizations and guidelines for parameterization under large temporal ranges.
- Object- and region-level time control: World time is modeled as a single global scalar per frame, which cannot freeze, slow, or reverse different objects independently. Explore segmentation-conditioned, per-object, or layered time controls and evaluate multi-actor scenes with distinct temporal remappings.
- Physics-aware temporal reasoning: The model does not ensure physically consistent dynamics under time remapping (e.g., collisions, momentum, fluids, cloth). Integrate physics priors/simulators or consistency losses and assess on physics benchmarks (e.g., dynamics plausibility, conservation laws).
- Lighting and appearance control over time: World time does not explicitly control illumination, shadows, or weather/time-of-day changes. Add disentangled photometric/lighting control signals and evaluate whether temporal changes in appearance remain coherent across camera viewpoints.
- Multi-view and 4D grid consistency without reconstruction: While the method avoids explicit 4D reconstruction, it lacks a quantitative evaluation of consistency across a dense camera-time grid. Design metrics and protocols (e.g., dycheck-style masked consistency, cycle-consistency across view/time loops) to measure 4D coherence.
- Cross-architecture generality: The approach is fine-tuned on CogVideoX-5B only. Validate portability across other large video diffusion backbones (e.g., HunyuanVideo, Wan, SVD variants) and identify architecture-dependent components of Time-/4D-RoPE and AdaLN.
- Camera geometry encoding choices: Camera-AdaLN uses Plücker ray embeddings aggregated via 2D convolutions. The paper lacks ablations comparing geometry encodings (rays vs extrinsics-only vs monocular depth vs learned camera tokens) and their impact on control fidelity, stability, and efficiency.
- Sensitivity to control-input noise and calibration errors: Robustness to inaccurate camera intrinsics/extrinsics, timestamp jitter, or dropped frames is not studied. Add controlled noise to camera/time inputs and quantify degradation and recovery strategies (e.g., robust encodings, uncertainty-aware conditioning).
- Efficiency and latency: No training/inference time, memory, or throughput numbers are provided for 384×640×81. Profile cost, optimize attention (e.g., windowed/sparse/rank-reduced), and explore distillation to faster decoders (e.g., Gaussian-based Lyra-style) for interactive XR/robotics use cases.
- Trade-offs between control fidelity and visual quality: VBench shows slight aesthetic quality gaps vs some baselines. Characterize and optimize the Pareto frontier between strict 4D control adherence and perceptual quality, including loss balancing and training curricula.
- Generalization beyond human-centric scenes: Although some non-human examples are shown, there is no systematic test set for animals, vehicles, crowds, and complex environments. Build diverse evaluation suites and quantify performance across content classes and motion types.
- Handling scene cuts and compositional edits: The method assumes temporally coherent single shots. Explore robustness to shot boundaries, scene transitions, and editing operations (e.g., object insertion/removal) while maintaining 4D control.
- Interface and control specification: The paper conditions on per-frame world time scalars and camera trajectories but does not define standardized control APIs or parameterizations (e.g., spline-based trajectories, piecewise time functions). Propose interfaces, unit tests, and validation tools for user-specified controls.
- Identifiability and disentanglement guarantees: There is no theoretical analysis of whether Time-/4D-RoPE plus AdaLN yield identifiable separation of time and camera under realistic data. Provide formal conditions or empirical counterexamples, and paper regularizers or training designs that strengthen identifiability.
- 4D representation distillation: The method does not explore distilling to explicit 3D/4D scene representations (e.g., Gaussians, NeRFs) to enable fast re-rendering across arbitrary camera/time queries. Investigate hybrid pipelines that maintain control fidelity while enabling interactive exploration.
Glossary
- 3D full attention: Transformer attention operating jointly across time, height, and width to capture spatiotemporal coherence in videos. "adopt transformer architectures~\cite{esser2024scaling, peebles2023scalable} with 3D full attention for improved spatiotemporal coherence and visual quality."
- 3D VAE: A variational autoencoder that encodes video into a compact spatiotemporal latent space. "a compact latent space encoded by a pretrained 3D VAE."
- 4D Gaussian Splatting: An explicit dynamic-scene representation using Gaussians in 3D plus time for rendering across viewpoints and time. "e.g., 4D Gaussian Splatting~\cite{wu20244dgs}"
- 4D world modeling: Representing dynamic environments as 3D space evolving over time to enable controllable observation and simulation. "paving the way toward 4D world modeling~\cite{genie3,feng2024matrix, WorldLabs} and simulation."
- 4D-RoPE: A unified 4D rotary positional encoding that combines time- and camera-aware transformations for attention. "a unified 4D positional encoding (4D-RoPE)"
- AdaLN (Adaptive Layer Normalization): A conditioning mechanism that modulates normalized features via learned scale and shift parameters. "Adaptive Layer Normalization (AdaLN) module via a learned affine transformation:"
- Cat4D: A multi-view video diffusion approach that models camera and time jointly, often paired with a reconstruction stage. "Cat4D~\cite{wu2025cat4d} and 4DiM~\cite{watson20244dim} propose unified 4D formulations"
- Cross-Attention: An attention mechanism where condition tokens attend to visual tokens to inject guidance. "Cross-Attention, where temporal conditions are treated as additional tokens that interact with visual tokens through a cross-attention layer"
- DiT (Diffusion Transformer): A transformer-based denoiser architecture used in diffusion models for video synthesis. "Diffusion Transformers (DiTs)~\cite{peebles2023scalable} have become the standard denoiser architecture in recent video diffusion models."
- FVD (Fréchet Video Distance): A perceptual video quality metric measuring distributional distance between generated and reference videos. "We evaluate visual quality using VBench~\cite{huang2024vbench} metrics as well as FVD and KVD~\cite{ge2022long}."
- KVD (Kernel Video Distance): A video similarity metric leveraging kernel methods to assess generation fidelity. "We evaluate visual quality using VBench~\cite{huang2024vbench} metrics as well as FVD and KVD~\cite{ge2022long}."
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual metric for visual similarity between frames or images. "we report PSNR, SSIM, and LPIPS to assess reconstruction quality under joint camera and time control."
- MegaSAM: A system used to estimate camera poses from generated videos for evaluation. "camera poses estimated using MegaSAM~\cite{li2025megasam} from generated videos."
- mMAE: Masked Mean Absolute Error; MAE computed within a specified mask (e.g., background regions). "masked image metrics~\cite{gao2022dycheck} (mPSNR, mMAE, mSSIM, mLPIPS)"
- mLPIPS: Masked LPIPS; perceptual similarity computed only over masked regions. "masked image metrics~\cite{gao2022dycheck} (mPSNR, mMAE, mSSIM, mLPIPS)"
- mPSNR: Masked Peak Signal-to-Noise Ratio; PSNR computed within a mask to assess consistency. "masked image metrics~\cite{gao2022dycheck} (mPSNR, mMAE, mSSIM, mLPIPS)"
- mSSIM: Masked Structural Similarity Index; SSIM computed over masked areas. "masked image metrics~\cite{gao2022dycheck} (mPSNR, mMAE, mSSIM, mLPIPS)"
- Monocular-depth-based point-cloud projections: Constructing point clouds from single-view depth to reproject scenes for novel views. "TrajectoryCrafter’s reliance on monocular-depth-based point-cloud projections often results in geometric distortions and inaccurate camera trajectories."
- Plücker ray embeddings: A representation of camera rays in projective geometry used to encode per-pixel camera geometry. "encode per-pixel camera geometry using Plücker ray~\cite{plucker1865xvii} embeddings"
- PointOdyssey: A synthetic data generation framework for dynamic scenes with controllable cameras and annotations. "PointOdyssey framework~\cite{zheng2023pointodyssey} within Blender"
- PSNR: Peak Signal-to-Noise Ratio; a reconstruction quality metric sensitive to pixel-level errors. "we report PSNR, SSIM, and LPIPS to assess reconstruction quality under joint camera and time control."
- RoPE (Rotary Positional Embeddings): Positional encoding that applies rotations to token features to encode relative positions for attention. "rotary positional embeddings (RoPE)~\cite{shaw2018relPE,su2024roformer}"
- Time-AdaLN: An AdaLN branch that injects continuous world-time conditioning via feature-wise modulation. "a time-conditioned adaptive normalization module (Time-AdaLN)"
- Time remapping: Altering the temporal sampling of a video to slow, speed up, or pause dynamics. "time remapping~\cite{huang2022rife}"
- Time-RoPE: A continuous-time extension of RoPE that encodes temporal offsets directly in attention logits. "we extend RoPE~\cite{su2024roformer} to operate directly on continuous time and refer to this extension as Time-RoPE."
- U-Net: An encoder–decoder convolutional architecture commonly used in diffusion-based image/video generators. "extended U-Net--based image generators~\cite{ronneberger2015unet} with temporal modules across frames"
- VBench: A benchmark and metric suite for automated evaluation of video quality and consistency. "We evaluate visual quality using VBench~\cite{huang2024vbench} metrics"
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, leveraging the paper’s decoupled control of world time and camera pose (Time-RoPE, Time-AdaLN, 4D-RoPE, Camera-AdaLN) and the curated 4D-controlled synthetic dataset.
- Cinematic post-production: single-camera bullet-time and replays
- Sector: media/entertainment, advertising
- What: Apply bullet-time, time-freeze, slow/fast motion independently of camera movement; orbit or dolly a “frozen” moment from a single video.
- Tools/products/workflows: NLE/VFX plugins for Premiere/Resolve/After Effects/Nuke; keyframe-based UI to draw camera trajectory and a world-time curve; batch/offline GPU inference.
- Assumptions/dependencies: GPU inference time; best results on short clips (e.g., ~81 frames); quality depends on scene type and camera baseline; content licensing for edited footage.
- Sports highlights and coaching replays from monocular footage
- Sector: sports broadcasting, coaching analytics
- What: Generate free-viewpoint slow-motion replays and “around-the-play” bullet-time sequences from a single sideline or overhead camera.
- Tools/products/workflows: Operator console for replay generation; integration into existing broadcast pipelines; presets for standard trajectories (orbit, crane, push-in).
- Assumptions/dependencies: Offline processing; accuracy of camera trajectory inputs; potential artifacts for large occlusions or extreme parallax.
- XR/VR experiences generated from consumer videos
- Sector: XR/VR, gaming
- What: Turn a monocular video into a short interactive “time-scrubbable, view-navigable” experience; users pause time and move viewpoint.
- Tools/products/workflows: Creator apps offering trajectory presets and time scrubbing; offline precompute with interactive playback; cloud inference options.
- Assumptions/dependencies: Non-real-time generation; limited clip duration; geometry consistency is learned (not reconstructed), so extreme baselines can degrade realism.
- Social media video editing with “freeze-and-orbit”
- Sector: consumer apps
- What: Mobile/desktop apps that let users freeze action and “orbit” the subject, or slow/accelerate time independently of camera motion on dance, action, and product clips.
- Tools/products/workflows: Simple UI with time-curves (pause/slow/reverse) and camera-path templates; cloud GPU-backed rendering; shareable presets.
- Assumptions/dependencies: Latency and cost of cloud rendering; artifact risks in crowded or highly reflective scenes.
- Product marketing and e-commerce visuals
- Sector: retail/marketing
- What: Create dynamic product shots from one video—freeze splash moments, pivot around a product, or present multiple viewpoints at one time index.
- Tools/products/workflows: Studio pipeline plugins; campaign templates for bullet-time product reveals; batch processing for catalog content.
- Assumptions/dependencies: Controlled lighting/backgrounds yield best results; complex transparent/reflective materials may challenge consistency.
- Academic benchmarking for 4D controllability
- Sector: academia (computer vision, graphics)
- What: Use the released 4D-controlled synthetic dataset to train/evaluate disentangled time/camera conditioning; reproduce ablations for Time-RoPE vs. RoPE and AdaLN vs. alternatives.
- Tools/products/workflows: Public dataset, training scripts, metrics (PSNR/SSIM/LPIPS, background consistency, camera pose errors); baselines in camera-only models extended with time remapping.
- Assumptions/dependencies: Synthetic domain bias; need to add real-world corpora for broader generalization; dataset licensing.
- Generative data augmentation for multi-view/multi-time supervision
- Sector: software/ML, robotics perception
- What: Generate synchronized multi-time, multi-view sequences from single videos to augment training of segmentation, tracking, or reconstruction models.
- Tools/products/workflows: Data pipelines that vary time-curves and camera trajectories; automatic mask generation (e.g., SAM/SAM2) for supervised training.
- Assumptions/dependencies: Domain gap between generated and real data; careful curation to avoid learning artifacts.
- Cost-effective “virtual multi-camera” production
- Sector: indie filmmaking, events
- What: Reduce reliance on multi-camera rigs by synthesizing alternative viewpoints post hoc from single-camera captures for stylized inserts (not ground-truth geometry).
- Tools/products/workflows: On-set workflows capturing high-resolution reference passes; post-production synthesis with standardized camera path presets.
- Assumptions/dependencies: Not a replacement for true multi-view capture when physical accuracy is required; works best with moderate camera motion and limited occlusion.
- Visualization for training and education
- Sector: education (STEM labs, demos)
- What: Pause and inspect dynamic phenomena (e.g., a mechanical motion or fluid splash) from multiple viewpoints to aid conceptual understanding.
- Tools/products/workflows: Interactive lesson modules with teacher-controlled time-curves and camera paths; exportable clips for LMS use.
- Assumptions/dependencies: Visual plausibility prioritized over physics accuracy; communicate generative nature to avoid misinterpretation.
- Developer integration: 4D control API
- Sector: software
- What: Provide a simple API to specify per-frame world-time sequences and camera trajectories, wrapping CogVideoX fine-tuned with 4D-RoPE/AdaLN.
- Tools/products/workflows: SDKs (Python/REST) with trajectory and time-curve utilities; containerized inference; presets for common effects.
- Assumptions/dependencies: GPU memory for long clips; model license; monitoring to prevent misuse.
Long-Term Applications
These use cases require further research and engineering (scaling, speed, robustness, physics-awareness, longer horizons, real-world training) before mainstream deployment.
- Real-time 4D replays in live broadcasts
- Sector: media/sports
- What: Low-latency generation of free-viewpoint, time-controlled replays during live events.
- Tools/products/workflows: Distilled/accelerated models; hardware acceleration; streaming inference stacks.
- Assumptions/dependencies: Significant speedups over diffusion; robust geometry/time consistency under fast motion; operator-friendly reliability standards.
- Telepresence with time-scrubbing and free viewpoint from monocular capture
- Sector: communications/XR
- What: Viewers can join a live session and pause/review moments from different viewpoints in near real time.
- Tools/products/workflows: Edge/cloud inference with session-level caching; low-latency streaming; user-driven trajectories.
- Assumptions/dependencies: Strong temporal coherence across long videos; privacy and consent management; bandwidth and compute constraints.
- Physics-aware world models for robotics simulation and planning
- Sector: robotics/autonomy
- What: 4D-controllable generative simulators that preserve physical constraints while allowing time manipulation for what-if analysis and planning.
- Tools/products/workflows: Autoregressive or recurrent 4D diffusion; sensor-conditioned models (IMU/LiDAR/RGBD); integration with planning stacks.
- Assumptions/dependencies: Learning from real-world corpora; calibrated physics; safety validation.
- Digital twins and training at scale with controllable time and viewpoint
- Sector: manufacturing, smart cities
- What: Generate synthetic multi-view sequences with time scrubbing to test perception/control systems over long horizons.
- Tools/products/workflows: Twin orchestration platforms; large-scale scenario generation; automated trajectory/time schedule synthesis.
- Assumptions/dependencies: Domain adaptation; long-duration temporal stability; provenance and audit trails.
- Clinical training and procedure review
- Sector: healthcare
- What: Pause complex procedures and navigate viewpoints to teach or review steps (e.g., laparoscopic or robotic surgery).
- Tools/products/workflows: Curriculum platforms with controlled replays; secure data pipelines; regulatory-compliant storage.
- Assumptions/dependencies: Clinical validation; patient privacy; rigorous bias and artifact assessment to prevent misleading visuals.
- Heritage and film restoration with novel viewpoints
- Sector: culture/archiving
- What: Re-render historical footage from new viewpoints and stabilized time for educational exhibits.
- Tools/products/workflows: Restoration pipelines combining super-resolution, de-flicker, and 4D control; curator tools to annotate uncertainties.
- Assumptions/dependencies: Ethical guidelines; disclosure of generative transformations; adaptation to varied film artifacts.
- Interactive textbooks and MOOCs with 4D labs
- Sector: education
- What: Students explore experiments by pausing and changing viewpoints; instructors author time-camera trajectories for explanations.
- Tools/products/workflows: Authoring tools, standardized trajectory libraries, LMS integration.
- Assumptions/dependencies: Scalable content generation; accessibility; pedagogical studies to measure learning impact.
- Previsualization and virtual scouting
- Sector: film/TV, commercials
- What: Directors explore timing and camera paths on rehearsal footage, experimenting with bullet-time and free-view sequences before shooting.
- Tools/products/workflows: On-set capture + rapid 4D previews; storyboard integration; path-to-shot handoff.
- Assumptions/dependencies: Robustness to varied lighting/sets; long-scene continuity; clear provenance management.
- Trust, provenance, and policy frameworks for 4D generative video
- Sector: policy/regulation, media integrity
- What: Standards for watermarking, disclosure, and provenance tracking of time/camera-manipulated generative content.
- Tools/products/workflows: Cryptographic signatures, metadata standards (C2PA-like), detection tools tuned for 4D manipulations.
- Assumptions/dependencies: Cross-industry adoption; regulatory guidance; balancing creative freedom with misinformation risk.
- Consumer-grade 4D capture devices and pipelines
- Sector: hardware/software
- What: Cameras coupled with onboard/in-cloud 4D generation that deliver editable time-camera layers for post-production.
- Tools/products/workflows: Camera firmware with trajectory sensing; seamless cloud pipelines; companion apps.
- Assumptions/dependencies: Edge acceleration; power constraints; privacy-preserving compute.
Notes on feasibility and dependencies common across applications
- Model performance is strongest on short-to-medium clips; very long, high-baseline, highly occluded or reflective scenes remain challenging.
- Inference is currently offline and compute-intensive; real-time applications require distillation, caching, or dedicated hardware.
- The training/fine-tuning in the paper relies on a synthetic human-centric dataset; broader generalization benefits from mixed real-world corpora and domain adaptation.
- Geometry is learned implicitly; for safety-critical or measurement-accurate use, traditional multi-view capture or explicit 3D reconstruction may still be required.
- Ethical use and disclosure are essential: 4D viewpoint/time edits can alter perception of events; provenance and watermarking should accompany distribution.
Collections
Sign up for free to add this paper to one or more collections.