- The paper introduces Semantic-First Diffusion, which prioritizes semantic denoising over texture processing to enhance convergence and fidelity.
- It employs a composite latent space combining a Transformer-based Semantic VAE for semantics with a standard VAE for textures, ensuring efficient generation.
- Empirical results on ImageNet demonstrate up to 100× faster convergence and superior FID scores compared to legacy latent diffusion models.
Semantics-First Diffusion: Asynchronous Latent Denoising in Generative Modeling
Introduction
"Semantics Lead the Way: Harmonizing Semantic and Texture Modeling with Asynchronous Latent Diffusion" (2512.04926) introduces Semantic-First Diffusion (SFD), a novel latent diffusion framework that resolves intrinsic conflicts in the joint modeling of semantics and textures by explicitly prioritizing semantic denoising. Legacy latent diffusion models (LDMs) utilize VAEs to encode visual data into latent spaces, but their texture-oriented latent representations and joint denoising often result in suboptimal semantic structure and slow convergence. SFD decouples semantic and texture latents, harmonizes their evolution through asynchronous denoising schedules, and demonstrates both superior convergence rates and generation fidelity on ImageNet.
Composite Semantic-Texture Latent Representation
SFD introduces a composite latent space integrating two specialized components: a semantic latent, compacted via a dedicated Transformer-based Semantic VAE (SemVAE), and a texture latent encoded by a standard VAE.
SemVAE ingests high-dimensional patch-level representations from frozen vision foundation models (VFMs, specifically DINOv2-B-reg) and employs Transformer blocks to encode them into low-dimensional semantic latents. This approach ensures preservation of spatial and semantic information, mitigating losses typically introduced by simpler methods like PCA. Latent variables are sampled via the reparameterization trick and optimized with a blend of MSE, cosine similarity, and KL regularization losses. The composite latent is constructed by channel-wise concatenation of the semantic and texture latents, serving as input to the downstream diffusion transformer.
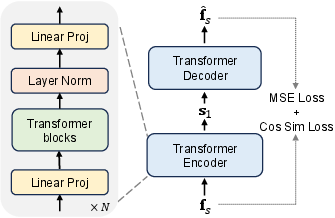
Figure 1: Architecture of the Semantic VAE (SemVAE). A Transformer-based VAE compresses high-dimensional VFM features into compact semantic latents.
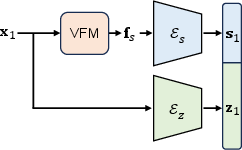
Figure 2: Composite Latent Construction. Input images are mapped into semantic and texture latents by distinct VAEs, then concatenated for subsequent asynchronous diffusion.
Asynchronous Denoising and the Three-Phase Generation Process
The core innovation is the asynchronous denoising schedule, which injects a temporal offset Δt between the semantic and texture denoising processes. The three-stage procedure is as follows:
- Semantic Initialization: Only semantic latents are denoised, establishing high-level spatial organization.
- Asynchronous Generation: Semantics and textures are denoised in parallel but at different noise levels, with semantic latents always less noisy, providing global supervision for texture synthesis.
- Texture Completion: Once semantics are fully denoised, textures continue refining, focusing on high-frequency details.
The diffusion backbone, based on a DiT architecture, receives noisy composite latents with independent timesteps for semantics and textures and class labels as input, and predicts their respective velocities. Training objectives comprise both velocity prediction and auxiliary representation alignment (REPA) losses.
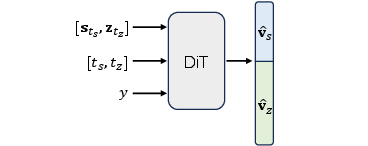
Figure 3: Input and output of Diffusion Transformer. The DiT backbone jointly denoises the composite latent (noisy semantics and textures, individualized timesteps, class label) and outputs their velocity fields.
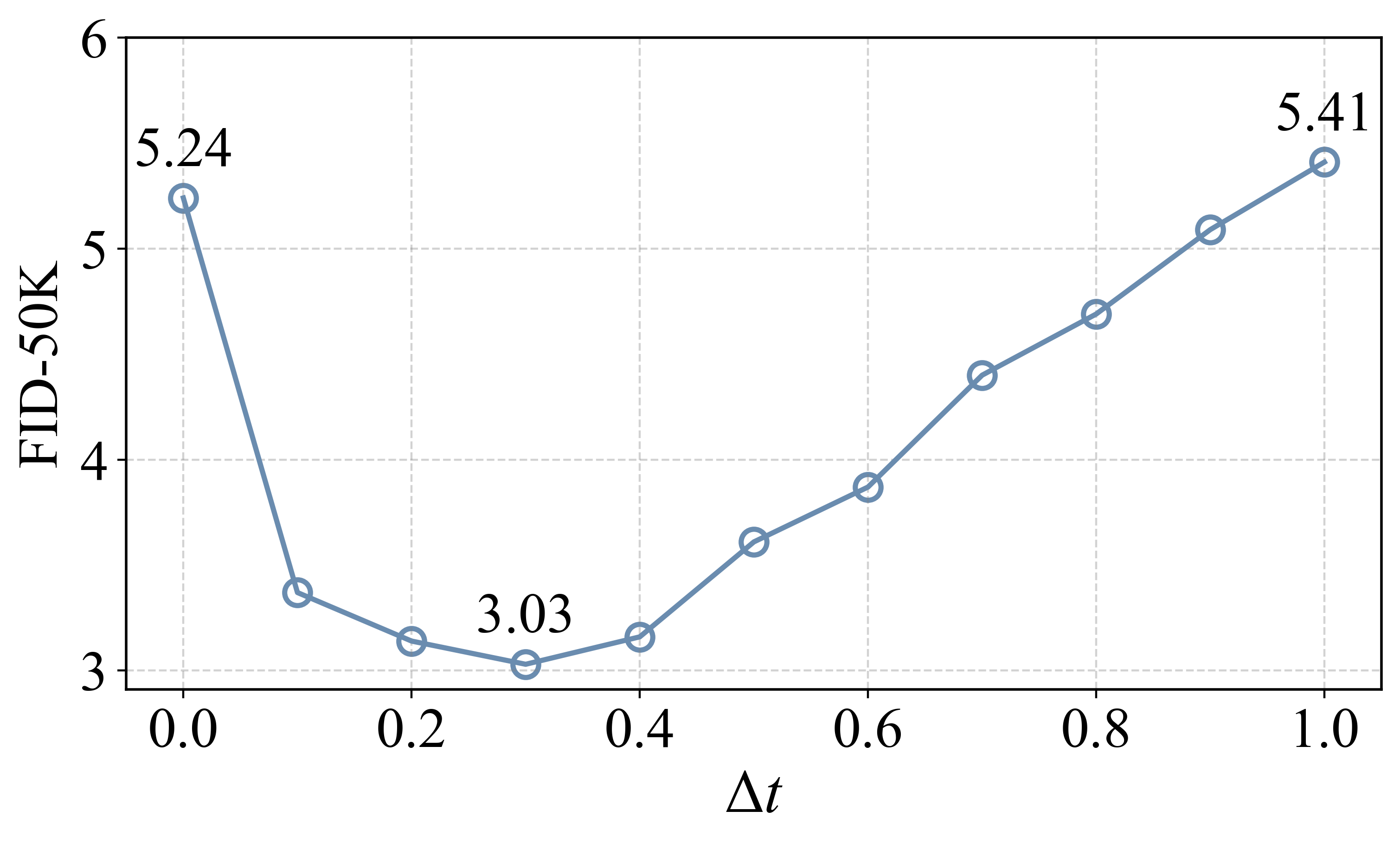
Figure 4: Effect of the temporal offset Δt in asynchronous denoising. A moderate offset (Δt=0.3) minimizes FID, suggesting optimal semantic–texture cooperation.
The authors empirically show, via an ablation on Δt, that a moderate offset (Δt=0.3) yields optimal FID, while either pure sequence or full synchronous denoising is suboptimal due to inference-train mismatches or lack of semantic prominence, respectively.
Quantitative and Qualitative Results
On ImageNet 256×256, SFD achieves FID 1.06 (LightningDiT-XL) and FID 1.04 (1.0B LightningDiT-XXL) with guidance, surpassing prior LDM and autoregressive approaches. Notably, SFD achieves up to 100× faster convergence versus DiT and 33.3× versus LightningDiT at similar parameter scales. The performance gain is robust to varying the underlying backbone and persists when retrofitted into other latent-diffusion architectures like ReDi and VA-VAE.

Figure 5: Qualitative samples from SFD at 256×256 resolution, illustrating high fidelity and realism.
Ablation studies confirm three critical elements: (i) explicit semantic representation (SemVAE); (ii) REPA auxiliary loss; (iii) the semantic-first asynchronous scheduling. Replacement of SemVAE by PCA for semantic compression results in nontrivial performance degradation.
For reconstruction fidelity, SFD’s adoption of an SD-VAE for the texture path achieves rFID 0.26 and LPIPS 0.089, outperforming VA-VAE and RAE. This demonstrates that SFD’s disentangled latent strategy sustains strong reconstruction quality while enabling rapid, semantically grounded synthesis.

Figure 6: Qualitative reconstruction comparison: SD-VAE-based reconstruction retains the highest fidelity, especially in text and fine texture details, relative to VA-VAE and RAE-based spaces.

Figure 7: Visualization of training at various iterations. SFD displays clear structures and high-fidelity details much earlier in training, demonstrating rapid convergence versus other models.
Further visualizations for diverse ImageNet classes show detailed, semantically coherent synthesis (Figures 8–16).
Theoretical and Practical Implications
The SFD paradigm provides strong evidence that explicit semantic–texture disentanglement, coupled with asynchronous denoising, is a critical factor for efficient generative modeling with diffusion transformers. By aligning the generative process with the coarse-to-fine nature of image synthesis—semantics as prior, textures as refinement—SFD achieves both superior generative quality (state-of-the-art FID, sFID) and computational efficiency (fast convergence, minimal FLOPs overhead).
The framework is generally extensible to other modalities or tasks where hierarchical signal formation is present. Its disentanglement facilitates future research on compositionality, editability, conditional controls, and interpretable inference. Potential work includes dynamic scheduling for Δt, applications to text-to-image/video, or elimination of the auxiliary alignment loss for even cleaner optimization.
Conclusion
Semantic-First Diffusion (SFD) implements an asynchronous latent diffusion scheme that prioritizes explicit semantic denoising for rapid, high-fidelity generative modeling. The evidence substantiates that coarse semantic scaffolding is critical for sample quality and that asynchronous evolution of semantics and textures harmonizes optimization and generation. This approach establishes a promising avenue for further research into hierarchical, representation-level asynchronous denoising in generative modeling.

