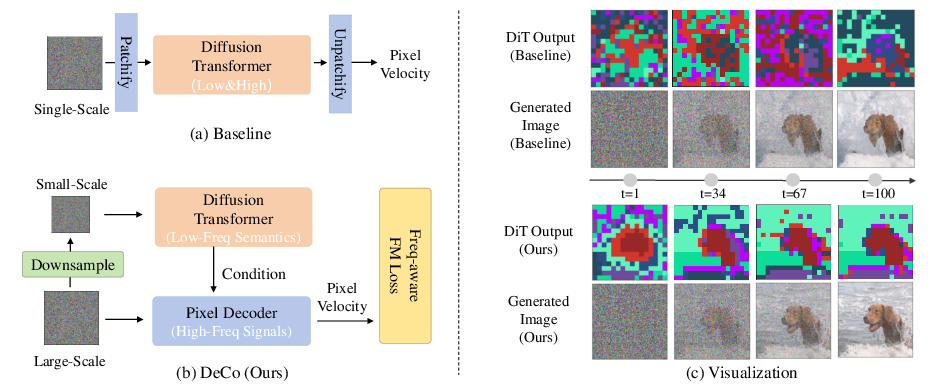
DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation
Abstract: Pixel diffusion aims to generate images directly in pixel space in an end-to-end fashion. This approach avoids the limitations of VAE in the two-stage latent diffusion, offering higher model capacity. Existing pixel diffusion models suffer from slow training and inference, as they usually model both high-frequency signals and low-frequency semantics within a single diffusion transformer (DiT). To pursue a more efficient pixel diffusion paradigm, we propose the frequency-DeCoupled pixel diffusion framework. With the intuition to decouple the generation of high and low frequency components, we leverage a lightweight pixel decoder to generate high-frequency details conditioned on semantic guidance from the DiT. This thus frees the DiT to specialize in modeling low-frequency semantics. In addition, we introduce a frequency-aware flow-matching loss that emphasizes visually salient frequencies while suppressing insignificant ones. Extensive experiments show that DeCo achieves superior performance among pixel diffusion models, attaining FID of 1.62 (256x256) and 2.22 (512x512) on ImageNet, closing the gap with latent diffusion methods. Furthermore, our pretrained text-to-image model achieves a leading overall score of 0.86 on GenEval in system-level comparison. Codes are publicly available at https://github.com/Zehong-Ma/DeCo.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces DeCo, a new way to generate images directly from pixels (end-to-end). The main idea is to split the image-making job into two parts:
- One part focuses on the “big picture” (overall shapes, colors, and meaning).
- The other part adds the fine details (textures, edges, and small patterns).
By separating these two, the authors make the model faster, simpler, and able to produce higher-quality images.
Goals and Questions
The paper tries to solve three easy-to-understand problems:
- Can we make pixel-based image generators as good as popular two-stage methods, but without using extra parts like VAEs (which compress and decompress images)?
- Can we stop the model from getting distracted by noisy, tiny details while it’s trying to learn the overall scene and meaning?
- Can we teach the model to pay more attention to the parts of an image that people actually notice (the important frequencies), rather than treating all details equally?
How DeCo Works (Explained Simply)
Imagine two artists working together:
- Artist A (the “planner”) decides what the picture shows: the objects, their positions, and the main colors.
- Artist B (the “detail painter”) fills in sharp edges, texture, and small patterns.
DeCo works like this team:
- The “planner” is a transformer model (called DiT) that looks at a smaller, downsampled version of the image. This helps it focus on low-frequency information: big shapes, smooth color areas, and overall meaning (called “semantics”).
- The “detail painter” is a lightweight pixel decoder. It looks at the full-resolution image and adds high-frequency information: crisp lines, textures, and fine details.
They communicate through a simple mechanism (AdaLN) where the planner’s output guides how the detail painter fills in the final image.
What are “frequencies” in an image?
- Low frequency: broad areas of color and big shapes (think of the “background music” in a song — the bass and melody).
- High frequency: tiny changes, like sharp edges and texture (think of the “treble” and sparkly sounds). DeCo splits these into two specialists so each part can do its job better.
What is “flow matching”?
- Generating an image starts from noise (random pixels) and gradually turns it into a clear picture.
- Flow matching teaches the model to predict the “velocity” — which means how each pixel should change over time to move from noise to the final image.
- In everyday terms: it’s like giving step-by-step instructions on how to morph TV static into a beautiful photo.
Frequency-aware loss (paying attention to what matters most)
- Not all details are equally important to human eyes.
- DeCo uses a trick inspired by JPEG (a common image format): it converts pixel changes into frequency patterns (using DCT, which is like breaking an image into building blocks of patterns).
- It then gives bigger weights to frequencies people care about more, and smaller weights to noisy, less-visible ones.
- This makes learning simpler and helps the model produce images that look better.
Main Findings and Why They Matter
DeCo shows strong results in both speed and quality:
- On ImageNet (a standard dataset for images):
- At 256×256 resolution: DeCo achieved a very low FID of 1.62 (lower is better).
- At 512×512 resolution: DeCo achieved FID 2.22.
- These numbers are excellent for end-to-end pixel methods and close to the best two-stage methods, but DeCo doesn’t need a VAE.
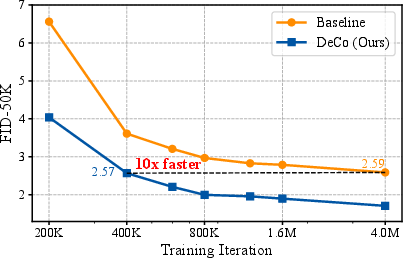
- Training speed:
- DeCo reaches good quality around 10× faster than a strong baseline model. Faster training means saving money and time.
- Text-to-image (turning words into pictures):
- On GenEval (a benchmark that checks things like object counts, colors, positions, and relationships): DeCo scored 0.86 overall, beating well-known systems (including much larger models).
- On DPG-Bench: DeCo scored 81.4, competitive with top methods.
- Compared to other pixel-based methods (like PixelFlow, PixNerd, and JiT):
- DeCo is more efficient, simpler, and better at balancing big-picture meaning with fine details.
Why this matters: It shows that end-to-end, pixel-only image generation can be both fast and high-quality without relying on extra stages and complex parts. Splitting the job by frequency is an effective design choice.
Implications and Impact
- Simpler systems: DeCo removes the need for a VAE, making the pipeline easier to build and maintain.
- Better images: By letting the “planner” focus on meaning and the “detail painter” focus on texture, the final images are cleaner and more realistic.
- Faster training: Reaching high quality faster reduces costs, helpful for research labs and companies.
- Strong text-to-image performance: This approach can power creative tools, design assistants, and content generation with better alignment to prompts.
In short, DeCo’s “two specialists” approach — one for the big picture, one for the details — is a smart, practical way to generate images. It pushes end-to-end pixel diffusion closer to (and sometimes past) the quality of two-stage methods, while being efficient and easier to train.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, phrased to guide future research.
- Generalization beyond ImageNet and two T2I benchmarks: performance, robustness, and failure modes on diverse domains (e.g., medical, satellite, line-art, synthetic data, indoor scenes, rare categories) and across different data distributions are not evaluated.
- Scaling to higher resolutions and native aspect ratios: training/inference at 1024×1024+ and native aspect resolutions is explicitly left for future work; memory, speed, and quality trade-offs (especially for a dense full-resolution decoder) remain unknown.
- Sensitivity to DiT downsampling/patch size and multi-scale choices: the DiT patch size is fixed at 16 and not ablated; the optimal downsampling ratio, number of resolution scales, and their effect on semantic fidelity vs detail retention are unstudied.
- Placement and proportion of the pixel decoder: DeCo replaces the final two DiT blocks, but the optimal insertion point(s) and number of replaced blocks (earlier vs later stages) for quality and efficiency are not explored.
- Decoder capacity/design limits: the attention-free local decoder (small hidden size and depth) may cap detail modeling on complex scenes; scaling laws (depth/width, residual connections, sparse attention, or convolutional hybrids) are not characterized.
- Conditioning mechanism alternatives: AdaLN is compared only to simple addition; other conditioning (cross-attention, FiLM, gating, mixture-of-experts, or content-adaptive modulation) and their impact on semantics–details fusion remain untested.
- Learned vs fixed frequency weighting: the frequency-aware FM loss uses fixed JPEG quantization priors (YCbCr, 8×8 DCT, quality=85); whether learned, content-aware, time-dependent, or task-specific frequency weights outperform JPEG priors is unknown.
- Transform choices and block artifacts: the reliance on block-wise 8×8 DCT may introduce block boundary artifacts or suboptimal weighting; alternatives (e.g., wavelets, MDCT, steerable pyramids, FFT, learned spectral bases) are not examined.
- Channel weighting strategy: loss is applied in YCbCr without analysis of how chroma vs luminance weighting affects color fidelity or saturation; possible color shifts or biases and mitigation are not studied.
- Time-dependent frequency emphasis: weighting is static across diffusion time; strategies that vary frequency emphasis across timesteps (early semantics vs late details) could help but are not evaluated.
- Interaction with REPA and other representation alignment: REPA is included, but the contribution of REPA vs DeCo is not disentangled; ablation without REPA (and with alternatives like CLIP/DINO alignment or no alignment) is missing.
- Objective function robustness: DeCo is built around flow matching; comparative performance with standard ε-prediction, x0-prediction, score-based objectives, or hybrid losses is not assessed.
- Noise and corruption robustness: claims about alleviating camera/high-frequency noise are not supported by controlled evaluations (e.g., different noise types/levels, blur, compression artifacts, sensor noise, JPEG/WebP compression).
- Sampler and NFE sensitivity: limited exploration of samplers (Euler vs Heun) and step counts; systematic study of NFE–quality–latency curves, adaptive schedulers, or higher-order solvers is absent.
- Fairness and comparability of baselines: training regimes, epochs, and NFE differ across methods; controlled, matched-setup comparisons (same data, steps, schedulers, CFG) to isolate architectural benefits are lacking.
- Text alignment and instruction-following depth: T2I evaluation relies on GenEval and DPG-Bench; broader alignment tests (e.g., compositionality, long prompts, fine-grained attributes, typography/text rendering) and human preference studies are missing.
- Editability and conditional controls: support for image editing, inpainting, and conditioning via control signals (depth, segmentation, canny edges) is not explored; the decoupling’s compatibility with ControlNet-like modules is unknown.
- Interpretability of semantic features: the DiT’s low-frequency “semantic” output c is not analyzed for what it encodes (objectness, layout, global color); probing and visualization could validate the semantic vs detail split.
- Long-range detail dependencies: a local attention-free decoder might struggle with globally consistent fine patterns (e.g., repeating textures, long edges); whether the DiT’s conditioning suffices, or global mechanisms are needed, remains unclear.
- Failure mode taxonomy: systematic error analysis (e.g., oversmoothing, edge ringing, color bleeding, texture repetition, small-object fidelity, detail hallucination) and mitigation strategies are not provided.
- Data scale and quality limits for T2I: the reported 36M + 60k data regime works well, but scaling behavior with larger datasets, noisy captions, multilingual prompts, and data quality variations is not characterized.
- Safety, bias, and fairness: societal biases, toxic content risks, and safety constraints in end-to-end pixel diffusion systems are not assessed; mechanisms for bias reduction or safety filtering are absent.
- Energy and hardware efficiency: memory/latency are measured on A800/H800; portability to consumer GPUs/edge devices, mixed precision effects, quantization, and throughput under constrained hardware are open.
- Extensibility to other modalities: applicability of frequency decoupling to video (temporal frequency), audio/speech, or 3D generative tasks is an open question; cross-modal conditioning designs are not discussed.
- Training stability and collapse risks: while FM offers stable targets, stability under deeper decoders, larger models, different optimizers, and learning-rate schedules is not reported; gradient pathology and normalization choices could matter.
- Theoretical justification and bounds: empirical evidence supports decoupling, but formal analysis (e.g., capacity allocation, optimization landscape simplification, convergence guarantees) is absent.
- Code-level reproducibility: exact hyperparameters for some baselines, random seeds, and data preprocessing (e.g., YCbCr conversion specifics) are not fully standardized; reproducibility across frameworks remains to be demonstrated.
Practical Applications
Overview
The paper introduces DeCo, a frequency-decoupled pixel diffusion framework that separates low-frequency semantic modeling (handled by a Diffusion Transformer, DiT) from high-frequency detail generation (handled by a lightweight, attention-free pixel decoder). A frequency-aware flow-matching loss, inspired by JPEG’s DCT quantization, reweights errors to prioritize perceptually salient frequencies. These innovations yield faster training, competitive inference speeds, and state-of-the-art image quality among pixel diffusion models, with strong results in both class-to-image and text-to-image generation.
Below are practical applications that leverage these findings, methods, and innovations, organized into immediate and long-term opportunities.
Immediate Applications
The following applications are deployable now with available code, standard GPU infrastructure, and conventional finetuning workflows.
- High-quality text-to-image content generation for creative industries
- Sector: software, media/entertainment, marketing/advertising, e-commerce
- Use DeCo as a backend for content production (ads, banners, hero images, product lifestyle scenes), benefiting from its superior quality and efficiency. Integrate with existing creative suites (e.g., internal CMS or design tools) via an inference API.
- Tools/workflows: “Semantic-first” generation pipeline—cache the DiT’s low-frequency semantic output and vary the pixel decoder to produce multiple detail variants for A/B testing and personalization.
- Assumptions/Dependencies: Adequate GPUs (e.g., A800/H800), high-quality prompts/datasets, governance for brand-safe outputs.
- Domain-specific image generation for product catalogues and fashion
- Sector: retail/e-commerce, marketing
- Finetune DeCo on domain images to maintain consistent semantic layouts (e.g., object count, composition) while generating diverse textures and materials through the pixel decoder.
- Tools/workflows: Managed finetuning service; CFG tuning; semantic caching to mass-produce variants from one approved semantic layout.
- Assumptions/Dependencies: Labeled domain datasets, prompt libraries, human-in-the-loop QC.
- Detail enhancement for existing images (“Detail Booster”)
- Sector: software, media/creative tools
- Apply the pixel decoder to improve textures and perceptual details of existing images (e.g., upscaling, artifact cleanup, camera noise mitigation), conditioned on coarse semantic guidance.
- Tools/products: Plugin for design tools or a REST microservice; batch processing of archives.
- Assumptions/Dependencies: Proper conditioning inputs; quality control for preserving intent.
- Synthetic dataset generation for computer vision and robotics
- Sector: robotics, autonomous systems, industrial vision
- Generate semantically controlled datasets while varying high-frequency details for domain randomization (lighting, textures, fine-grain noise) to improve model robustness.
- Tools/workflows: “Semantic specification → detail randomization” loops to stress-test detectors/segmenters; reproducible seeds.
- Assumptions/Dependencies: Scenario taxonomies, evaluation protocols, and alignment with target deployment domains.
- Compression-aware content generation for web and mobile delivery
- Sector: media delivery/CDN, energy/IT ops
- Train with frequency-aware loss to reduce visually irrelevant high-frequency noise and improve JPEG-friendliness, potentially lowering bandwidth and storage while preserving quality.
- Tools/workflows: A/B experiments measuring CDN bandwidth, page load times, and user engagement.
- Assumptions/Dependencies: Measurable correlation between frequency prioritization and compression gains in your pipeline.
- Faster prototyping and iteration for ML teams
- Sector: software/ML engineering, energy/IT ops
- Exploit DeCo’s improved training efficiency (fewer epochs to reach strong FID) to accelerate model development cycles and reduce compute costs.
- Tools/workflows: Continuous training pipelines with early stopping informed by FID/sFID; hyperparameter sweeps for CFG and loss weights.
- Assumptions/Dependencies: Availability of GPUs and MLOps tooling; datasets representative of production needs.
- Educational content creation and visualization
- Sector: education
- Generate high-quality illustrations and diagrams rapidly, controlling semantics (composition, object count) while adjusting styles and details for different curricula.
- Tools/workflows: Prompt libraries, style presets; semantic caching for consistency across versions.
- Assumptions/Dependencies: Content guidelines and accessibility checks.
- Synthetic document imagery for OCR/receipt/invoice models
- Sector: finance, enterprise software
- Use DeCo to produce realistic, semantically structured documents while varying fine-grained noise, fonts, and printing artifacts to improve OCR robustness.
- Tools/workflows: Templates for document semantics; controlled noise generation via pixel decoder.
- Assumptions/Dependencies: Template coverage, compliance with data privacy and synthetic data policies.
- Trust & safety gating at the semantic stage
- Sector: policy, platform moderation
- Insert content filters at the low-frequency semantic modeling phase to detect and block disallowed compositions before high-frequency detail synthesis.
- Tools/workflows: Semantic validators (object count, classes, relationships) integrated with the DiT output.
- Assumptions/Dependencies: Reliable semantic detectors; governance frameworks; human review for edge cases.
Long-Term Applications
These applications require further research, scaling, or productization (e.g., model compression, multimodal extension, regulatory validation).
- Real-time, on-device AR/VR generative experiences
- Sector: software, hardware, AR/VR
- Target mobile SoCs with a compressed DiT and lightweight pixel decoder for interactive scene generation and texture synthesis.
- Assumptions/Dependencies: Quantization/distillation, memory- and energy-aware architecture changes, on-device safety.
- Medical imaging synthesis and augmentation (with strong controls)
- Sector: healthcare
- Generate anatomically consistent, high-detail synthetic scans for training and anonymization while preserving clinical semantics.
- Assumptions/Dependencies: Clinical validation, bias assessment, regulatory approval (e.g., FDA/EMA), domain expert oversight.
- Video generation with spatiotemporal frequency decoupling
- Sector: media, robotics simulation
- Extend DeCo to temporal modeling (low-frequency scene dynamics vs. high-frequency frame details), enabling controllable, coherent video synthesis.
- Assumptions/Dependencies: Temporal consistency modules, efficient video DiT variants, large-scale training data.
- CAD/CAM and digital twin texture generation
- Sector: industrial design, manufacturing
- Use DeCo to generate high-detail, physically plausible textures and surface finishes for digital twins and CAD assets while controlling semantic layout.
- Assumptions/Dependencies: Integration with 3D pipelines and PBR standards; validation in simulation-to-real workflows.
- Semantic provenance and watermarking at the decoupled stage
- Sector: policy, content authenticity
- Embed provenance signals in the low-frequency semantic representation for robust origin tracking across downstream image variations.
- Assumptions/Dependencies: Standardization of watermark channels, resilience testing, stakeholder adoption.
- Eco-efficient generative infrastructure
- Sector: energy/IT ops, sustainability
- Leverage DeCo’s efficiency gains to reduce energy per image at scale; establish sustainability KPIs for generative workloads.
- Assumptions/Dependencies: Transparent reporting, LCA metrics, cross-vendor benchmarking.
- Multimodal, constraint-driven semantics for enterprise content
- Sector: enterprise software, compliance
- Combine structured inputs (scene graphs, product SKUs, layout constraints) with the DiT’s semantic stage to guarantee compliance (e.g., object counts, brand assets) before detail synthesis.
- Assumptions/Dependencies: Reliable constraint satisfaction, integration with DAM/PIM systems.
- Multi-tenant “semantic server” architecture
- Sector: software infrastructure
- Share a centralized DiT for semantic generation across teams, each attaching domain-specific pixel decoders to customize details (e.g., fashion vs. automotive).
- Assumptions/Dependencies: Model orchestration, resource isolation, cross-team governance.
- Robotics sim-to-real transfer improvements
- Sector: robotics
- Use decoupled detail generation to systematically vary textures, lighting, and noise—bridging perception models from simulation to real environments.
- Assumptions/Dependencies: Task-specific validation, closed-loop evaluation in real deployments.
- Interactive education on frequency components and perception
- Sector: education
- Build learning tools that visualize how low- and high-frequency components affect perception and compression, teaching signal processing through hands-on generative examples.
- Assumptions/Dependencies: Curriculum development, accessibility and assessment standards.
Glossary
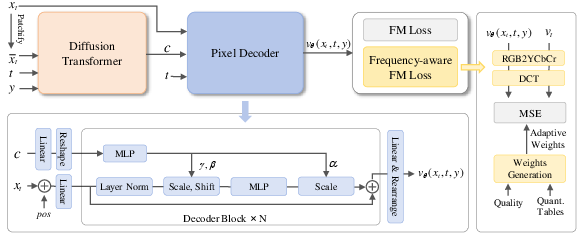
- AdaLN: Adaptive Layer Normalization technique that conditions features using learned parameters. "Adaptive layer norm (AdaLN) provides a powerful interaction mechanism between DiT and pixel decoder."
- AdaLN-Zero: A variant of AdaLN where modulation starts at zero to stabilize conditioning. "We utilize the AdaLN-Zero~\cite{dit} to modulate the dense decoder queries in each block as follows:"
- AdamW: An optimization algorithm that decouples weight decay from the gradient update. "we use a global batch size of 256 and the AdamW optimizer with a constant learning rate of 1e-4."
- Adams-2nd solver: A multistep ODE solver used for sampling in continuous-time generative models. "We use the Adams-2nd solver with 25 steps as the default choice for sampling."
- Classifier-free guidance (CFG): A sampling technique that improves conditioning without a classifier by interpolating conditional and unconditional predictions. "For inference, we use 50 Euler steps without classifier-free guidance~\cite{cfg} (CFG)."
- Conditional Flow Matching: A framework that learns a velocity field to transport a prior distribution to the data distribution conditioned on labels and time. "The conditional flow matching~\citep{lipman2023flow, luo2024latent} provides a continuous-time generative modeling framework that learns a velocity field to transport samples from a simple prior distribution (e.g., Gaussian) to a data distribution conditioned on the label and time ."
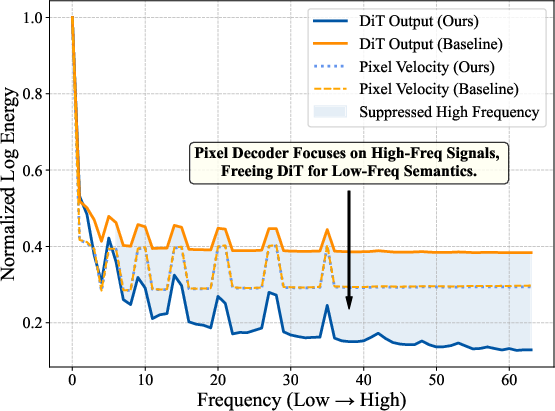
- DCT energy distribution: The frequency energy profile obtained from DCT, used to analyze frequency content. "DCT energy distribution of DiT outputs and predicted pixel velocities."
- DINOv2: A self-supervised vision transformer model used for representation alignment. "REPA~\cite{repa} aligns intermediate features with a pretrained DINOv2~\cite{dinov2} model to learn better low-frequency semantics."
- Diffusion Transformer (DiT): A transformer architecture tailored for diffusion models to operate on image tokens. "traditional methods~\cite{adm, simple_diffusion, vdm, rdm, pixelflow} typically rely on a single model like diffusion transformer (DiT) to learn these two components from a single-scale input for each timestep."
- Discrete Cosine Transform (DCT): A transform that represents signals in cosine basis, commonly used in compression. "our frequency-aware variant transforms the pixel velocity into the frequency domain using a Discrete Cosine Transform (DCT) and assigns adaptive weights to each frequency band."
- DPG-Bench: A benchmark for system-level evaluation of text-to-image models. "On DPG-Bench~\cite{dpg}, DeCo delivers a competitive average score comparable to two-stage latent diffusion methods."
- Euler steps: A first-order numerical integration method used for sampling trajectories. "For inference, we use 50 Euler steps without classifier-free guidance~\cite{cfg} (CFG)."
- FID (Fréchet Inception Distance): A metric that measures the quality and diversity of generated images by comparing feature distributions. "attaining FID of 1.62 (256256) and 2.22 (512512) on ImageNet, closing the gap with latent diffusion methods."
- Flow-Matching (FM) loss: A training objective that matches predicted and ground-truth velocities in continuous-time generative models. "Combined with the standard pixel-level flow-matching loss and the REPA~\cite{repa} alignment loss from the baseline, the final objective can be represented as:"
- Frequency-aware Flow-Matching (FM) loss: A variant of FM loss that reweights frequency components based on perceptual importance. "we introduce a frequency-aware Flow-Matching (FM) loss that emphasizes visually salient frequencies while suppressing insignificant ones."
- GenEval: A benchmark evaluating compositional and semantic fidelity in text-to-image generation. "our pretrained text-to-image model achieves a leading overall score of 0.86 on GenEval in system-level comparison."
- Guidance interval: A scheduling technique that applies guidance intermittently during sampling. "During inference, we use 100 Euler steps with CFG and guidance interval~\cite{interval_guidance}."
- Heun sampler: A second-order numerical method (improved Euler) for more accurate sampling. "inference with Heun sampler~\cite{heun1900neue} and 50 sampling steps."
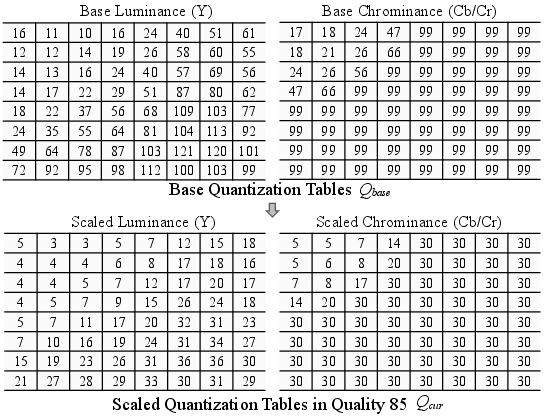
- JPEG: A widely used image compression standard that informs perceptual frequency weighting. "To further emphasize visually salient frequencies and suppress perceptually insignificant high-frequency components, we introduce a frequency-aware Flow-Matching (FM) loss inspired by the JPEG~\cite{JPEG}."
- JPEG quantization tables: Tables defining quantization strength per DCT coefficient, encoding perceptual importance. "The adaptive weights are derived from JPEG quantization tables, which encode robust priors about the visual importance of different frequencies~\cite{JPEG}."
- Latent diffusion: A two-stage approach that generates in a compressed latent space produced by a VAE. "Latent diffusion models~\cite{ldm, dit, sit, flux2024} split generation into two stages."
- Multi-scale cascaded methods: Approaches that generate low frequencies first and refine high-frequency details later across scales. "Multi-scale cascaded methods~\cite{pixelflow, rdm} can be approximately regarded as a form of temporal frequency decoupling, i.e., early steps generate low-frequency semantics, and later steps refine high-frequency details."
- Normalizing flow: A class of invertible generative models enabling exact density modeling. "TarFlow~\cite{tarflow} introduces a transformer-based normalizing flow to directly model and generate pixels."
- Patch embedding layer: A layer that tokenizes images by dividing them into patches and projecting to embeddings. "the trajectory is usually first patchified into tokens by a patch embedding layer~\cite{pixelflow, dit} instead of a VAE to downsample the image."
- Pixel decoder: A lightweight, attention-free network that reconstructs high-frequency details from full-resolution inputs. "a lightweight pixel decoder then takes the low-frequency semantics from DiT as a condition to generate additional high-frequency details with a full-resolution dense input "
- Pixel diffusion: End-to-end image generation directly in pixel space without a latent compressor. "Pixel diffusion aims to generate images directly in pixel space in an end-to-end fashion."
- Positional embeddings: Encodings added to inputs to convey spatial position information to the model. "All noised pixels are concatenated with their corresponding positional embeddings and linearly projected by $W_{\text{in}$ to form dense query vectors :"
- REPA: A representation alignment method that guides diffusion with pretrained visual features. "Combined with the standard pixel-level flow-matching loss and the REPA~\cite{repa} alignment loss from the baseline, the final objective can be represented as:"
- RMSNorm: A normalization technique using root mean square statistics instead of mean/variance. "Both baseline and DeCo adopt SwiGLU~\cite{llama2, llama1}, RoPE2d~\cite{rope}, and RMSNorm, and are trained with lognorm sampling and REPA~\cite{repa}."
- RoPE2d: Two-dimensional Rotary Positional Embeddings used for capturing spatial relationships. "Both baseline and DeCo adopt SwiGLU~\cite{llama2, llama1}, RoPE2d~\cite{rope}, and RMSNorm, and are trained with lognorm sampling and REPA~\cite{repa}."
- SiLU: A smooth activation function also known as Swish. "where the is the SiLU activation function."
- SwiGLU: A gated linear unit variant used in transformer feed-forward layers. "Both baseline and DeCo adopt SwiGLU~\cite{llama2, llama1}, RoPE2d~\cite{rope}, and RMSNorm, and are trained with lognorm sampling and REPA~\cite{repa}."
- Unpatchify layer: The inverse of patch embedding that reconstructs pixels from tokens. "In baseline, the patchified trajectory ${\bar{x}_t$ is then fed into the DiT to predict the pixel velocity with an unpatchify layer."
- Velocity field: A vector field specifying instantaneous motion for transporting distributions over time. "The conditional flow matching~\citep{lipman2023flow, luo2024latent} provides a continuous-time generative modeling framework that learns a velocity field "
- YCbCr: A color space separating luminance (Y) from chroma components (Cb, Cr). "This is done by converting the color space to YCbCr and applying a block-wise discrete cosine transform (DCT), following JPEG~\cite{JPEG}."
Collections
Sign up for free to add this paper to one or more collections.

