- The paper introduces PRIS, a framework that enhances text-to-visual generation by adaptively revising prompts to improve attribute adherence.
- It integrates an element-level factual correction verifier with iterative prompt updates to diagnose and repair recurring failures in compositional tasks.
- Empirical results demonstrate significant adherence improvements across T2I and T2V models, outperforming fixed-prompt methods even with increased compute.
Prompt Redesign for Inference-Time Scaling in Text-to-Visual Generation
State-of-the-art text-to-visual (T2V) and text-to-image (T2I) generative models achieve impressive sample quality, but their alignment with complex, compositional user intent is fundamentally bottlenecked by fixed prompts during inference. Current inference-time scaling methods focus on increasing compute—sampling more visuals or lengthier denoising trajectories—while keeping prompts fixed. This strategy quickly plateaus in prompt-adherence, especially on held-out or compositional attributes, because ambiguous or incomplete prompts systematically limit the capacity of inference scaling.
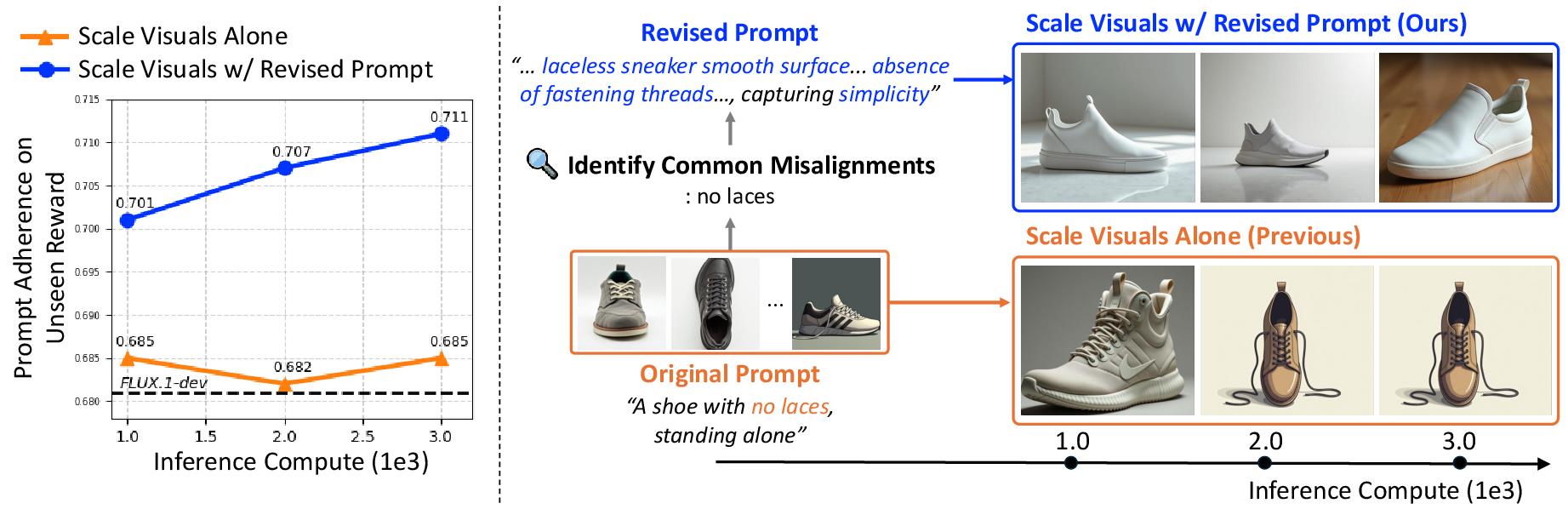
Figure 1: Prompt redesign (blue) enables sustained adherence improvements as compute increases, while fixed prompts (orange) plateau across both seen and unseen reward axes.
The presented work introduces Prompt Redesign for Inference-time Scaling (PRIS), which fundamentally extends the scaling law paradigm by jointly revising the prompt and the sampling process. By integrating prompt adaptation with scaling—actively revising the conditioning prompt in response to observed, recurring failures across sampled outputs—PRIS achieves strictly monotonic improvements in adherence, validated by substantial gains in established T2I and T2V benchmarks.
PRIS Framework and EFC Verifier
PRIS formalizes a four-step, iterative framework:
- Generation and Verification: Generate M samples with the user-provided prompt, then apply fine-grained verification to assess elementwise adherence.
- Top-k Selection: Extract k samples maximizing element coverage, breaking ties via human-aligned reward models.
- Common-failure Analysis and Prompt Redesign: Identify elements with systematic failures (<50% realized in top-k), then rewrite the prompt to explicitly reinforce only under-satisfied attributes, keeping strengths intact.
- Regeneration: Use the revised prompt and top-k seeds to generate (N−M) additional samples and repeat assessment.
A critical enabler is the element-level factual correction (EFC) verifier, which fulfills two essential gaps left by prior holistic or reward-based verifiers:
- Granular Decomposition: Decomposes the prompt into atomic, independently verifiable elements classified as core (objective) or extra (stylistic).
- Text-based Verification: For each output, generates free-form captions, then applies natural language inference (entailment, contradiction, neutral) to match each element. Unresolved (neutral) elements trigger open-ended questions for targeted probing.
This design explicitly mitigates affirmation bias and poor compositional reasoning typical of MLLM-based VQA or reward models, while providing elementwise attribution, supporting targeted and interpretable prompt refinement.
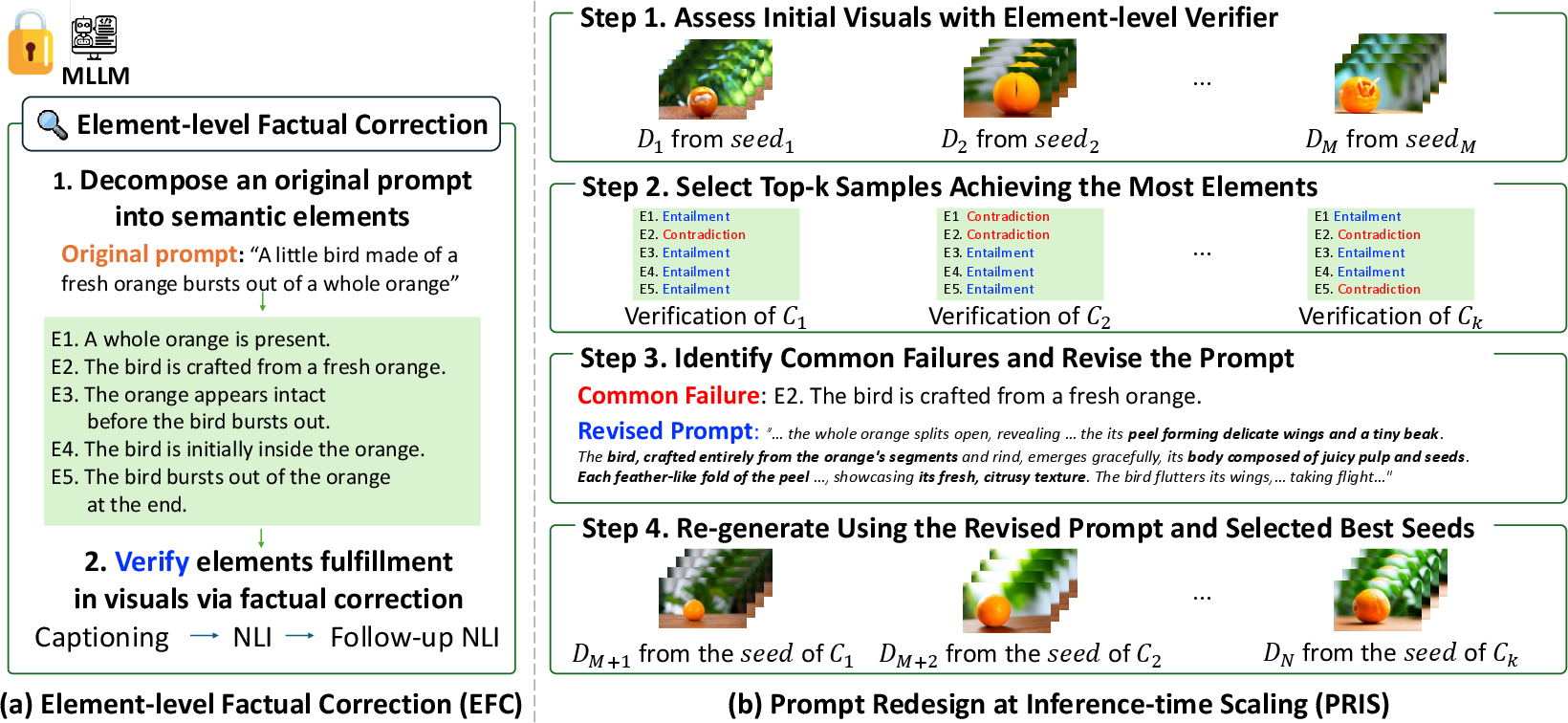
Figure 2: Overview of PRIS. Element-level Factual Correction (EFC) enables prompt decomposition, sample-level diagnostic verification, and cyclic prompt refinement using cross-sample failure patterns.
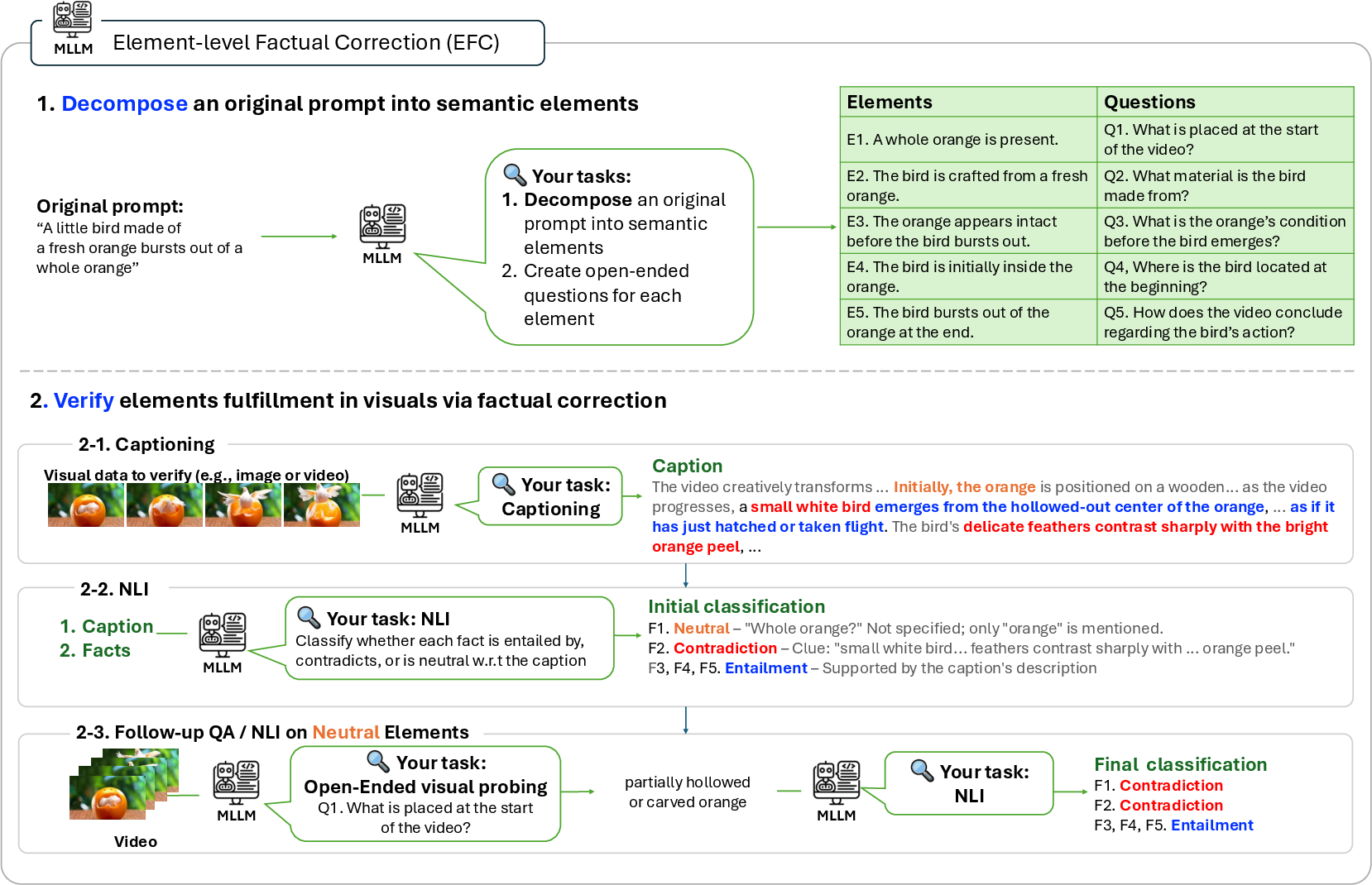
Figure 3: EFC decomposes prompts, performs text-visual entailment using captions and open-ended questions, and outputs fine-grained elementwise verification for prompt adherence.
Empirical Results
Quantitative and qualitative analyses are reported across strong T2I (Flux, SDXL) and T2V (Wan2.1) models, with both standard and challenging compositional prompts from GenAI-Bench and VBench2.0. The core findings are summarized below.
Text-to-Image Generation
Text-to-Video Generation
Integration with Visual Scaling Baselines
PRIS is fully complementary to advanced sampling and search-based visual scaling methods such as RBF and DAS. When integrated:
Ablation and Verification Studies
- Verifier benchmarking: On a new, attribute-level benchmark, EFC (zero-shot, no training) outperforms all existing reward models and decomposed VQA approaches, with mean accuracy 0.763 vs. 0.693 for VideoAlign.
- Prompt update strategy: Common-failure-based redesign (PRIS) systematically outperforms per-sample or no revision. In T2V, naively correcting every observed error (per-sample update) is actively harmful, as it forces the model to chase irreproducible, low-probability artifacts.
- Compute efficiency: PRIS provides substantial adherence gains even when controlling for total compute/wall-clock time, despite introducing verification overhead.
Broader Implications and Future Directions
This work demonstrates that inference-time prompt design is a critical and previously underexplored axis for scaling visual generative models. Several implications and possible directions emerge:
- Scaling Laws: Joint scaling of prompt and visuals breaks adherence plateaus imposed by fixed-prompt paradigms, calling for new theoretical analysis and practical heuristics in the context of scaling laws for generative AI.
- Verifier-driven Design: Attribute-level, interpretable verifiers are enabling infrastructure for any controlled, human-aligned sample generation; future models may learn to "self-debug" by integrating EFC-like methods in-the-loop.
- Cross-Model Transferability: Empirically, rewritten prompts generalize across T2I/T2V architectures, supporting research into general-purpose prompt rewriting agents or fine-tuning LLMs on naive-to-precise prompt transformations.
- Beyond Visual Modality: The principles extend to multi-modal and agentic settings, where joint scaling of instruction, prompt, and sampling could yield stronger grounding in both natural language and signal-rich modalities.
Conclusion
PRIS provides a formal framework for inference-time scaling that brings the prompt into the scaling loop, using attribute-level feedback, and adaptively repairs recurring model failures. The EFC verifier enables fine-grained, interpretable diagnosis and revision, lifting text-visual alignment beyond what compute-only scaling enables. PRIS achieves strong adherence improvements and generalizes across T2I and T2V, supporting a new class of scaling algorithms and evaluation methodologies for instruction-conditioned generation.
Reference:
"Rethinking Prompt Design for Inference-time Scaling in Text-to-Visual Generation" (2512.03534)


