- The paper introduces a multi-agent system that formulates prompt optimization as a search problem in the input text space.
- It leverages both VQA- and caption-based agents to systematically detect semantic errors and iteratively refine candidate prompts.
- Empirical results show up to 16.9% improvement in text-image alignment on challenging benchmarks across various T2I models.
GenPilot: A Multi-Agent System for Test-Time Prompt Optimization in Image Generation
Motivation and Problem Statement
Text-to-image (T2I) generation models have achieved substantial progress, yet they continue to exhibit significant limitations in faithfully rendering complex, compositional, or lengthy prompts. Semantic misalignment, missing details, and compositionality failures are prevalent, especially as prompt complexity increases. Existing solutions—such as model fine-tuning or manual prompt engineering—are either computationally expensive, model-specific, or lack systematic error analysis and refinement. Recent automatic prompt optimization (APO) and test-time scaling (TTS) methods have improved performance but remain limited by coarse-grained verification, random exploration, and insufficient interpretability.
GenPilot System Overview
GenPilot introduces a model-agnostic, plug-and-play multi-agent system for test-time prompt optimization, formulating prompt refinement as a search problem in the input text space. The system is designed to be interpretable, modular, and effective for both short and long prompts across diverse T2I models. GenPilot operates in two main stages: (1) systematic error analysis and (2) iterative test-time prompt optimization.
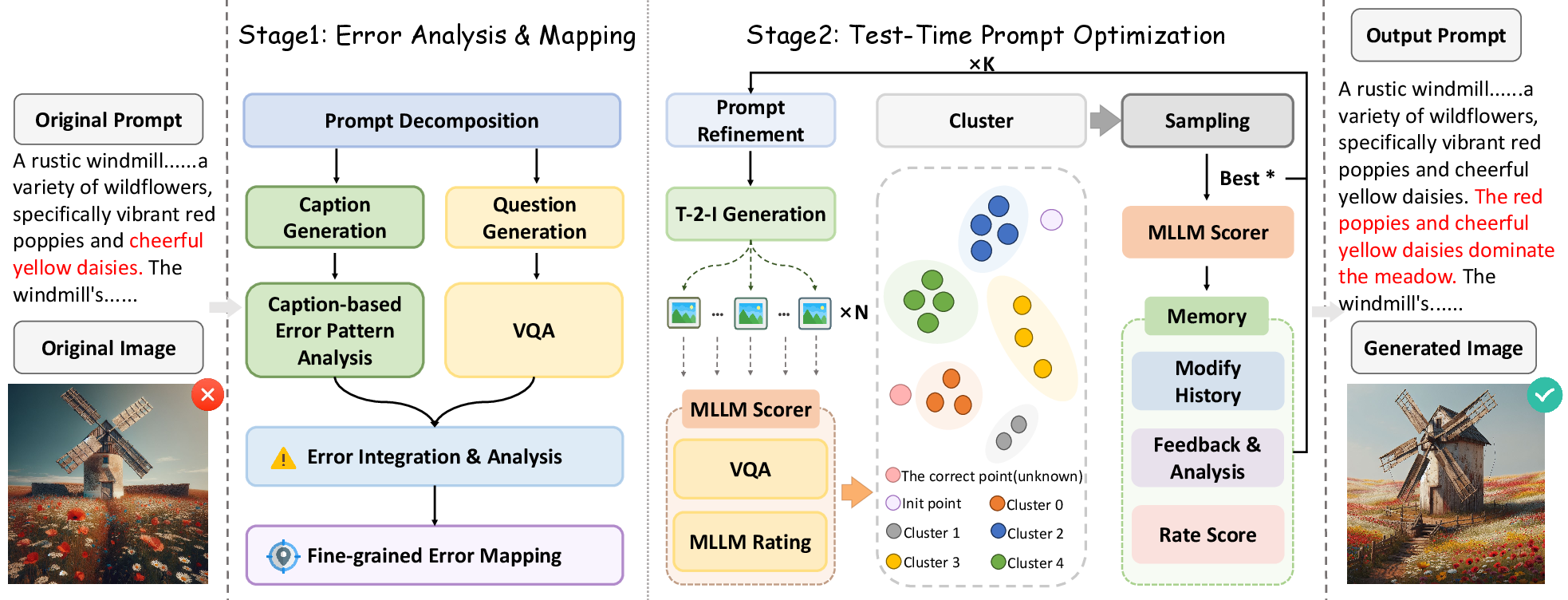
Figure 1: GenPilot system overview, illustrating prompt decomposition, error integration, mapping, and iterative prompt optimization with clustering and memory modules.
Stage 1: Systematic Error Analysis
- Prompt Decomposition: The initial prompt is segmented into meta-sentences capturing objects, relationships, and background.
- Parallel Error Detection: Two branches operate in parallel:
- VQA-based Analysis: An MLLM agent generates object-centric questions and uses VQA to detect object existence, attributes, and relations.
- Caption-based Analysis: An MLLM generates a detailed caption for the generated image, which is compared to the original prompt to identify semantic discrepancies.
- Error Integration and Mapping: An integration agent synthesizes errors from both branches, mapping each error to the corresponding prompt segment for targeted refinement.
Stage 2: Test-Time Prompt Optimization
- Prompt Refinement: For each mapped error, a refinement agent generates multiple candidate modifications, which are merged into the original prompt by a branch-merge agent.
- Candidate Evaluation: Each candidate prompt is used to generate images, which are scored by an MLLM-based scorer using VQA and rating strategies focused on attribute binding, relationships, and background fidelity.
- Clustering and Bayesian Selection: Candidate prompts are clustered (K-Means), and Bayesian updates identify the most promising cluster for further exploration.
- Memory Module: All prompt-image-score tuples and error analyses are stored, providing historical context for iterative optimization and convergence.
Implementation Details
- Agents: All agents are instantiated using state-of-the-art MLLMs (e.g., Qwen2-VL-72B-Instruct), with modularity to swap in alternative models (e.g., MiniCPM-V 2.0, BLIP-2).
- Prompt Candidates: 20 candidates per iteration, 5 clusters, up to 10 modification cycles.
- Parallelization: Error analysis, candidate generation, and scoring are parallelized to mitigate latency.
- Early Stopping: Optimization halts upon convergence or reaching a maximum iteration threshold.
- Metadata Structure: All agents operate on structured metadata, including error lists, mappings, question lists, history, and prompt-image pairs.
Quantitative and Qualitative Results
GenPilot demonstrates consistent improvements in text-image alignment and image quality across multiple T2I models and benchmarks.
- DPG-bench (Challenging Subset): GenPilot yields up to 16.9% improvement in average score over baselines, outperforming PE, TTS, MagicPrompt, and BeautifulPrompt across DALL-E 3, FLUX.1 schnell, SDv1.4, SDv2.1, SD3, and Sana-1.0 1.6B.
- GenEval (Short Prompts): GenPilot achieves up to 5.7% improvement, with notable gains in position, color, and counting subcategories.

Figure 2: Qualitative comparison on DPG-bench; GenPilot consistently produces error-free, semantically faithful images across diverse models and challenging prompts.

Figure 3: GenEval qualitative results; GenPilot enhances position accuracy and handles unrealistic prompts, demonstrating generalization across models.
Ablation studies confirm the critical role of the memory and clustering modules, with performance drops observed when either is removed. The modularity of GenPilot is validated by substituting different MLLMs and captioners, with Qwen2.5-VL-72B yielding the best results.
Error Analysis and Refinement Patterns
GenPilot systematically identifies and addresses a wide range of error patterns, including quantity, spatial positioning, texture, color, shape, proportion, action/pose, scene element omissions, extraneous elements, lighting, shadow, reflection, style, material, composition, interaction, ambiguous states, object fusion, emphasis, atmospheric mismatch, cluttered backgrounds, partial object generation, occlusion, unwanted brand elements, temporal ambiguity, seasonal elements, facial expression, transparency, background inconsistency, contrast, color disharmony, emotional tone, and object boundary errors.

Figure 4: Comparative error analysis; GenPilot integrates VQA- and caption-based methods for comprehensive and accurate error detection.
Clustering and Iterative Optimization
The clustering mechanism enables exploration of diverse prompt modifications, avoiding local optima and facilitating discovery of high-quality prompt regions in the discrete text space.
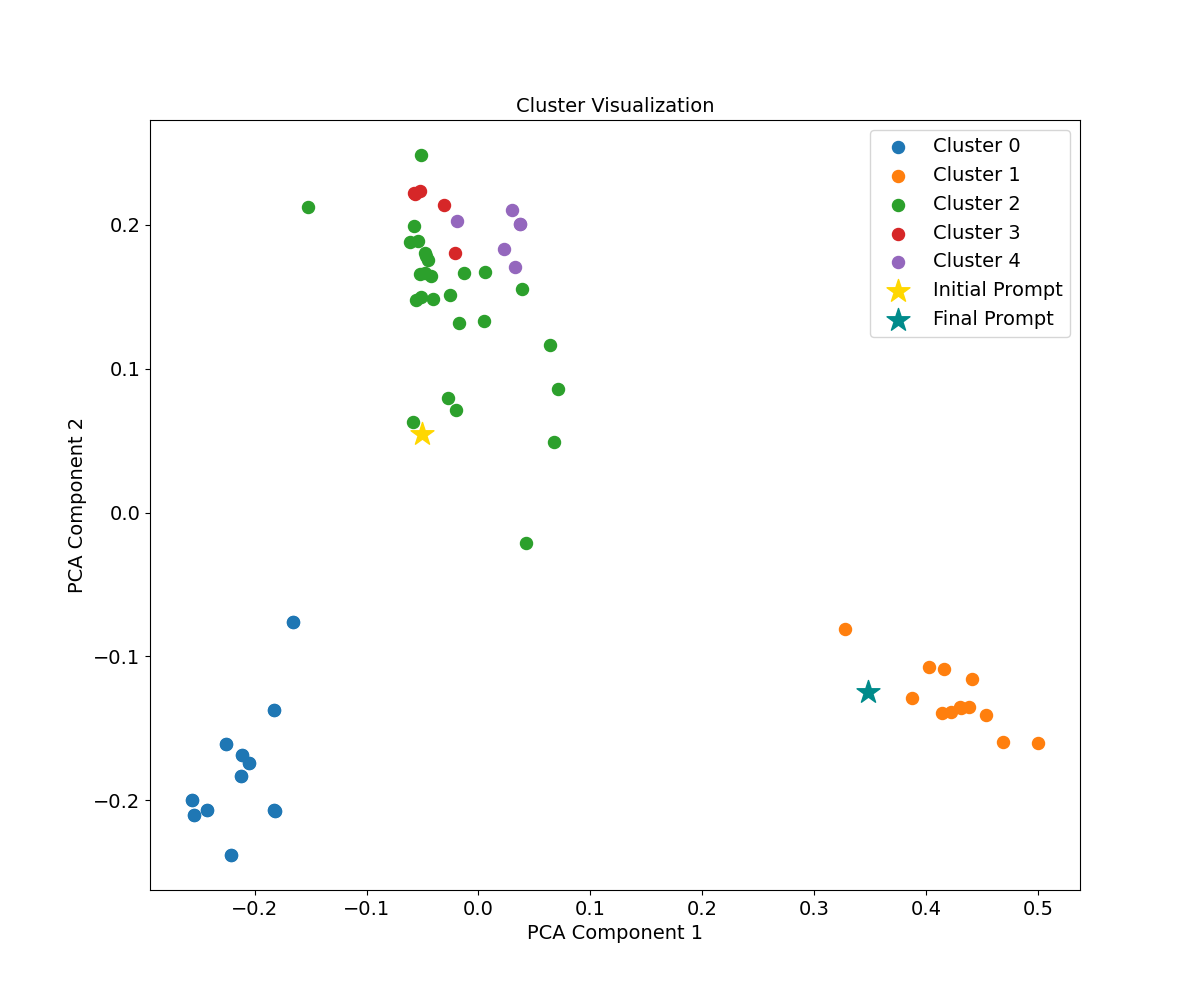
Figure 5: Visualization of clustering results; clusters represent distinct prompt modification directions, with the optimal cluster selected for further refinement.

Figure 6: Iterative optimization example; GenPilot corrects a counting error over four rounds, converging to an accurate synthesis.
Linguistic and Semantic Analysis
GenPilot-optimized prompts exhibit increased use of adjectives and proper nouns, leading to more descriptive and specific instructions for T2I models. Embedding-level semantic similarity analysis shows that GenPilot introduces meaningful details, translating semantic gains into improved visual results, unlike naive prompt expansion.
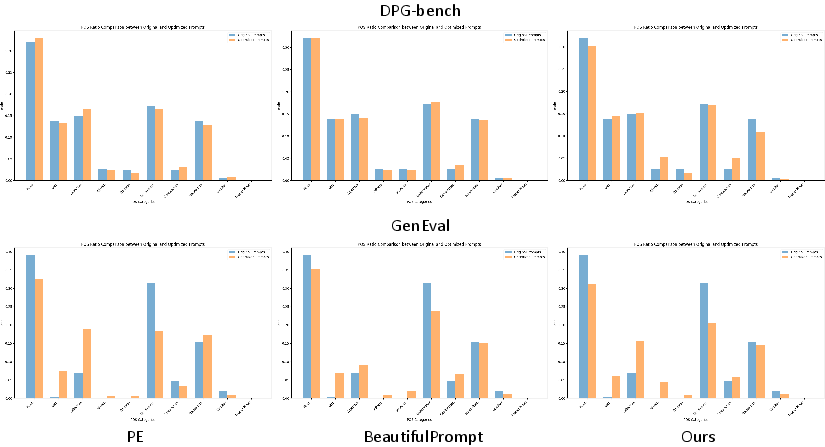
Figure 7: POS distribution shift analysis; GenPilot increases descriptive richness via adjectives and proper nouns compared to other methods.
System Prompts and Agent Design
GenPilot leverages a suite of system prompts for each agent, including prompt engineering, error analysis, VQA, captioning, rating, and refinement. These prompts are designed for high coverage, interpretability, and modularity, supporting extensibility to new models and tasks.
(Figure 8–15)
Figures 8–15: System prompt templates for each agent, illustrating the modular and interpretable design of GenPilot.
Practical Considerations and Limitations
- Computational Overhead: GenPilot introduces additional inference-time computation due to iterative candidate generation, scoring, and clustering. Parallelization and early stopping mitigate, but latency remains a consideration for real-time applications.
- MLLM Dependency: The quality of error analysis and scoring is contingent on the capabilities of the underlying MLLM agents. Suboptimal MLLMs may degrade performance.
- Model-Agnosticism: GenPilot is compatible with any T2I model that accepts textual prompts, requiring no model retraining or fine-tuning.
Implications and Future Directions
GenPilot establishes a new paradigm for test-time prompt optimization, shifting the focus from model-centric to input-centric scaling. This approach enables dynamic, interpretable, and model-agnostic enhancement of T2I generation, particularly for complex and compositional prompts. The release of error patterns and refinement strategies provides a valuable resource for future research on prompt controllability, automated prompt engineering, and human-in-the-loop systems.
Potential future developments include:
- Integration with real-time interactive systems for user-guided prompt refinement.
- Extension to other generative modalities (e.g., video, 3D, audio).
- Incorporation of more advanced search and optimization algorithms in the prompt space.
- Further reduction of computational overhead via more efficient agent architectures or pruning strategies.
Conclusion
GenPilot presents a comprehensive, modular, and interpretable framework for test-time prompt optimization in image generation. By leveraging multi-agent collaboration, systematic error analysis, clustering-based exploration, and memory-driven iterative refinement, GenPilot achieves robust improvements in text-image alignment and image quality across diverse T2I models and prompt types. The system's model-agnostic design, extensibility, and empirical effectiveness position it as a strong foundation for future research and practical deployment in prompt-based generative AI systems.