- The paper introduces a reparameterization of the loss function to target the instantaneous velocity field, stabilizing training for one-step (1-NFE) generation.
- It incorporates flexible classifier-free guidance by treating guidance scales as conditioning variables, allowing adjustable inference for diverse tasks.
- The work demonstrates significant FID reduction and parameter savings, setting a new benchmark for efficient fastforward generative models.
Improved Mean Flows: On the Challenges of Fastforward Generative Models
Introduction and Motivation
The paper "Improved Mean Flows: On the Challenges of Fastforward Generative Models" (2512.02012) addresses critical limitations in fastforward generative modeling, focusing on the MeanFlow (MF) approach for rapid, one-step sample generation. Recent work in diffusion and flow-based models has yielded remarkable generative performance, but typically at the cost of high computational complexity due to multi-step ODE/SDE solvers. Fastforward generative models, including the original MF, aim to drastically reduce generation steps, potentially even to a single function evaluation (1-NFE). However, MF's foundational design introduces instability in training and inflexibility in classifier-free guidance (CFG), limiting its practical and theoretical potential.
The Improved MeanFlow (iMF) framework introduced in this paper addresses two main pathologies: the non-standard, network-dependent regression target in MF's loss, and its inability to support variable CFG scales at inference. The authors' recasting of the loss function and architectural enhancements achieve substantial improvements in training stability, adaptability, and sample quality, setting new benchmarks for 1-NFE generative modeling on challenging tasks.
The original MeanFlow approach parameterizes an average velocity field u(zt,r,t) across two time steps. Practically, the instantaneous velocity field v(zt), which should serve as the regression target, is intractable to compute. MF circumvents this by substituting u with its own prediction uθ, coupling the loss target to the network and rendering it a non-standard regression task. This manifests as high variance and non-decreasing loss during training.
The iMF framework is predicated on a critical reformulation: recasting the MF loss as a v-loss (i.e., training on the instantaneous velocity field) reparameterized by uθ. This yields a network-independent regression target and aligns the learning problem with conventional regression paradigms.
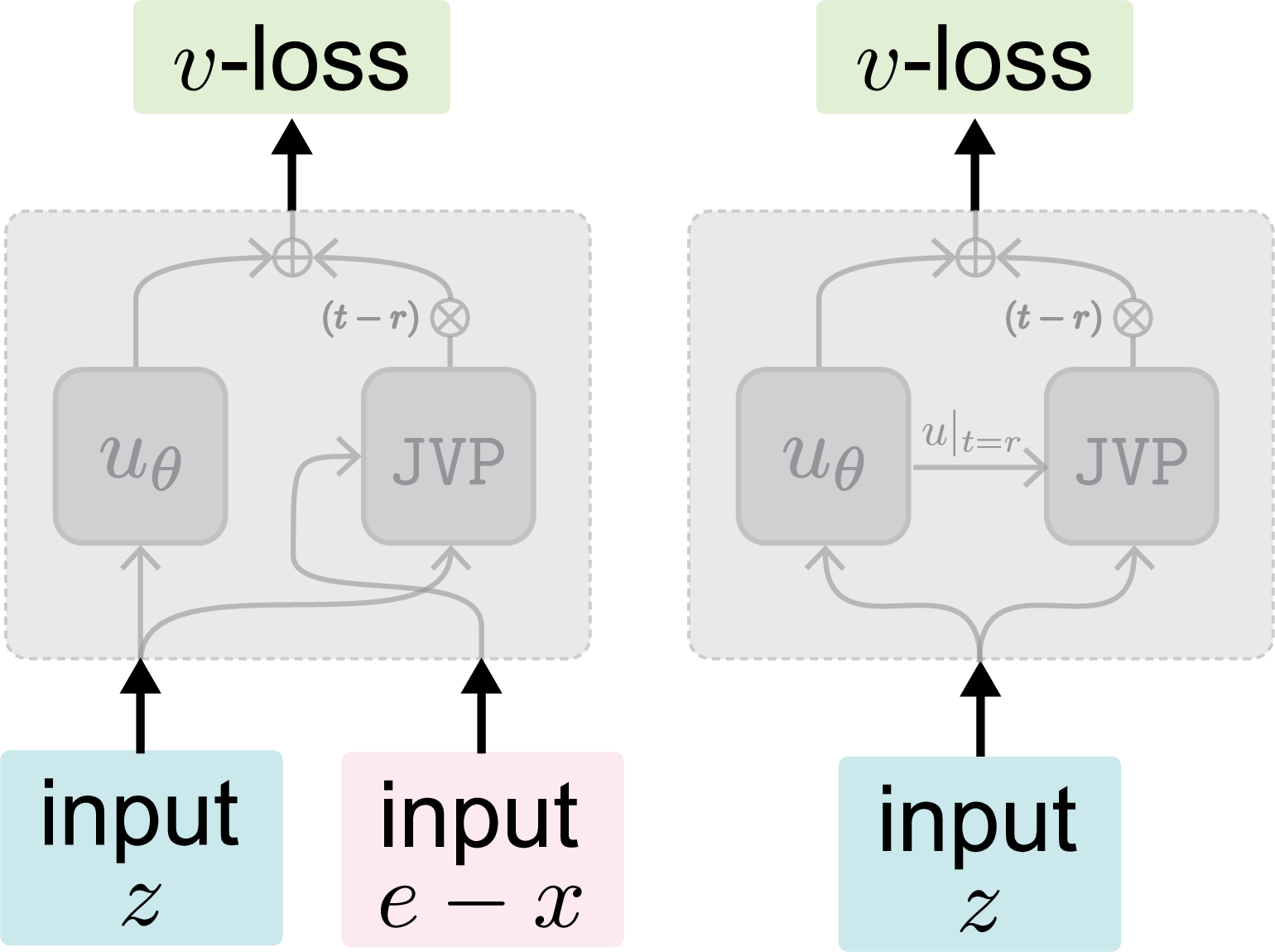
Figure 1: Visualization of the original MeanFlow approach predicting an average velocity u with the network's own output as target, resulting in network-dependent objectives.
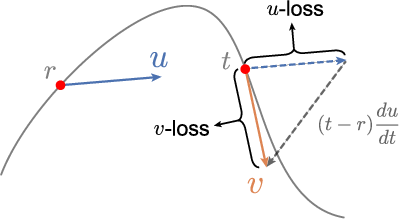
Figure 2: Improved MeanFlow reparameterizes the loss as a v-loss with only legitimate inputs, producing a proper regression target and standardizing the training process.
Empirical analysis (see below) shows that this reformulation yields more stable training dynamics, with decreasing loss and significantly improved convergence compared to the original MF.
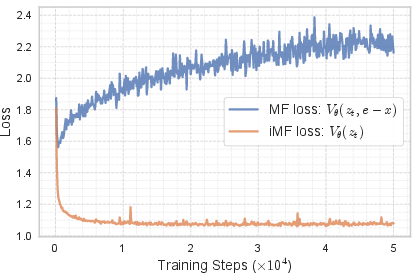
Figure 3: Training loss comparison reveals that iMF (with a standard regression formulation) exhibits lower variance and monotonic decrease, unlike the original MF's unstable behavior.
Flexible Classifier-Free Guidance (CFG)
A key limitation in the original MF is the static handling of classifier-free guidance: the guidance scale ω is fixed during training and cannot be modified at test time. This restriction precludes post-hoc tuning for downstream datasets or tasks, and empirical results highlight that the optimal guidance scale shifts with model capacity and training protocol.
The authors propose treating the CFG scale and related parameters as explicit conditioning variables, using in-context conditioning mechanisms within the network architecture. This permits the CFG scale (and even interval-based CFG as in recent literature) to be sampled during training and freely chosen during inference, dramatically enhancing flexibility and adaptability.
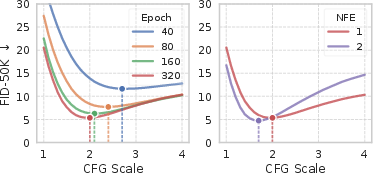
Figure 4: Optimal CFG scale varies with training regime and inference setup, motivating the need for flexible conditioning; a flexible design enables a single model to adaptively support different CFG scales.
Architectural Enhancements: In-context Conditioning
The improved MeanFlow implementation leverages in-context conditioning, representing conditions (e.g., time steps, class, guidance parameters) as learnable token embeddings, concatenated with latent image tokens, and processed via Transformer architectures. This approach stands in contrast to parameter-heavy adaLN-zero blocks, leading to a more parameter-efficient design with enhanced representational power for heterogeneous conditions.
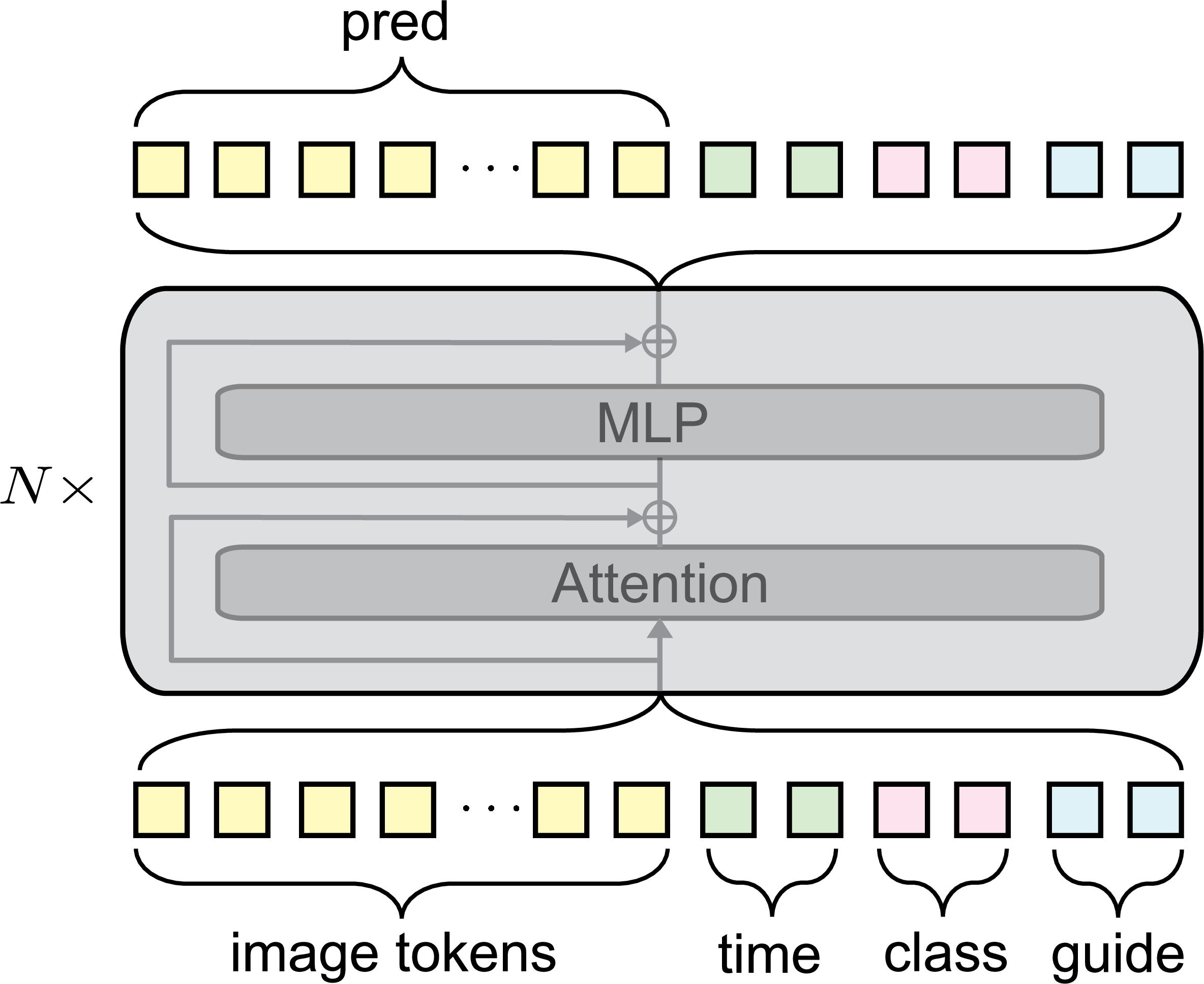
Figure 5: In-context conditioning: Each condition is transformed into multiple tokens and concatenated with the image sequence, replacing adaLN-zero and significantly reducing model size without sacrificing performance.
This change results in a substantial reduction in parameter count (up to 1/3 for the base model, from 133M to 89M), while enabling scaling to larger capacities and retaining or improving generative performance.
Experimental Results and Ablations
Comprehensive ablation studies confirm the benefit of each proposed innovation. Reformulating the loss as a v-loss with network-independent targets yields significant FID reductions. Incorporating flexible CFG conditioning further improves FID and supports new inference-time behaviors without retraining. Transitioning from adaLN-zero to in-context conditioning both improves FID and yields considerable parameter savings.
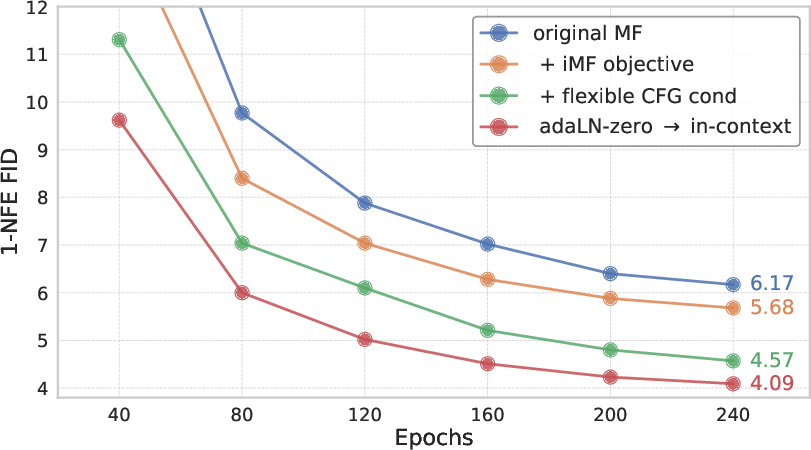
Figure 6: FID progression during training across ablations: each stage of improvement—loss reformulation, flexible CFG, in-context conditioning—appends significant performance gains and model efficiency.
On class-conditional ImageNet 256×256 at 1-NFE, the iMF-XL/2 model reaches 1.72 FID, a 50% relative reduction over the original MF, and establishes a new state-of-the-art for non-distilled, from-scratch 1-NFE generative models.
Qualitative Assessment
Qualitative sampling confirms that iMF models generate highly diverse, high-fidelity samples for a broad array of ImageNet classes in a single step.



Figure 7: Example uncurated 1-NFE generations from iMF-XL/2 on diverse ImageNet 256×256 classes.










Figure 8: Additional uncurated 1-NFE generations from iMF-XL/2—demonstrates high sample fidelity and semantic coherence.










Figure 9: Further qualitative 1-NFE samples showing diversity and consistency across ImageNet categories.
Comparison to Alternative Methods
Compared to other one-step or few-step generative models—including consistency models, shortcut models, and distillation-based techniques—iMF establishes both superior sample quality (lower FID) and model efficiency. The results approach, and even in some cases surpass, those of multi-step diffusion methods, indicating that principled fastforward training can narrow the fundamental gap between accelerated and conventional generative paradigms.
Practical and Theoretical Implications
The demonstrated progress in 1-NFE generative modeling has practical implications for real-time applications and scalable deployment, where sampling speed is at a premium. Theoretically, the recasting of fastforward objectives as standard regression problems brings clarity and tractability to fastforward generative training, establishing a new foundation for future fast-sampling generative models.
Moreover, as the performance of 1-NFE models approaches that of their multi-step counterparts, the computational burden of tokenization emerges as a dominant bottleneck. This dynamic implies the need for future innovation in more efficient latent spaces or direct pixel-space generation.
Conclusion
This work represents a substantial advance in the understanding and engineering of fastforward generative models. Through careful analysis and targeted reformulation, the iMF framework achieves robust, high-fidelity one-step generation with strong adaptability and parameter efficiency. These contributions make fastforward modeling a highly credible alternative to multi-step and distilled approaches, and open new avenues for practical generative model deployment and architectural exploration in high-speed AI applications.
