CuES: A Curiosity-driven and Environment-grounded Synthesis Framework for Agentic RL
Abstract: LLM based agents are increasingly deployed in complex, tool augmented environments. While reinforcement learning provides a principled mechanism for such agents to improve through interaction, its effectiveness critically depends on the availability of structured training tasks. In many realistic settings, however, no such tasks exist a challenge we term task scarcity, which has become a key bottleneck for scaling agentic RL. Existing approaches typically assume predefined task collections, an assumption that fails in novel environments where tool semantics and affordances are initially unknown. To address this limitation, we formalize the problem of Task Generation for Agentic RL, where an agent must learn within a given environment that lacks predefined tasks. We propose CuES, a Curiosity driven and Environment grounded Synthesis framework that autonomously generates diverse, executable, and meaningful tasks directly from the environment structure and affordances, without relying on handcrafted seeds or external corpora. CuES drives exploration through intrinsic curiosity, abstracts interaction patterns into reusable task schemas, and refines them through lightweight top down guidance and memory based quality control. Across three representative environments, AppWorld, BFCL, and WebShop, CuES produces task distributions that match or surpass manually curated datasets in both diversity and executability, yielding substantial downstream policy improvements. These results demonstrate that curiosity driven, environment grounded task generation provides a scalable foundation for agents that not only learn how to act, but also learn what to learn. The code is available at https://github.com/modelscope/AgentEvolver/research/CuES.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI helpers (called “agents”) how to learn in complicated places like apps and websites, even when nobody has written training exercises for them. The authors introduce a system named CuES that lets an AI agent explore its environment, figure out useful things to practice, and turn those discoveries into clear, solvable tasks it can learn from.
Key Questions
The paper tries to answer a simple but important question: If an AI agent can use tools and click around inside an app or website, but there are no ready-made tasks to train on, how can the agent:
- discover what kinds of tasks are possible,
- make sure those tasks actually work,
- and use them to get better at doing things?
Methods and Approach
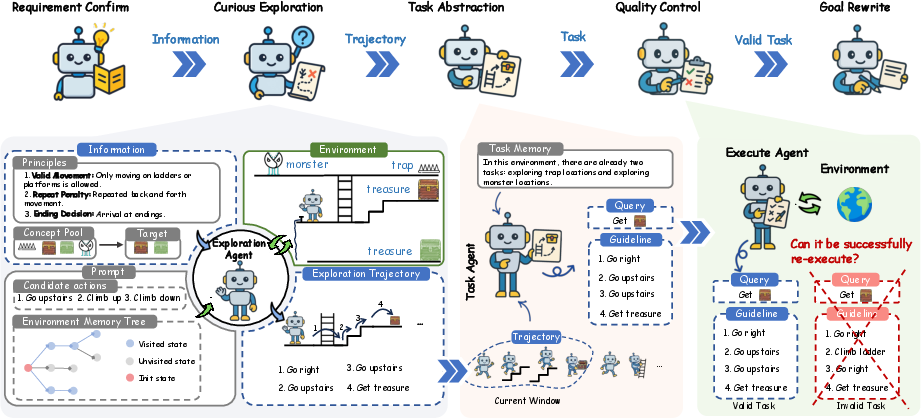
Think of the environment (like an app or shopping website) as a new playground. There are objects (buttons, pages, forms) and actions (click, search, type), but no teacher or assignment list. CuES helps the agent invent and test its own “games” (tasks) in five steps:
- Requirement Confirmation: Before exploring, the agent builds a “concept pool” from descriptions of the environment. This is like listing the main places and tools (e.g., “login button,” “search bar,” “add to cart”). It also sets simple rules (“principles”) to keep exploration focused, especially if a user has specific needs.
- Curious Exploration: The agent explores using intrinsic curiosity—like trying new actions it hasn’t done before. It keeps an “environment memory” so it doesn’t repeat the same clicks in the same place. Each step records what state it was in, what action it took, and what happened next.
- Task Abstraction: From these action trails, the agent lifts out mini-missions. For example, a trail like “open website → search ‘headphones’ → sort by price → choose item” becomes a task: “Find budget headphones,” plus a short guideline of how to do it.
- Quality Control: The agent replays each task to make sure it actually works. If a task fails or is unclear, it gets filtered out. Only tasks that the agent can complete are kept.
- Goal Rewrite: The agent adjusts difficulty by adding hints. A task can be rewritten in versions that are more guided (good for beginners) or more open-ended (good for advanced practice), so the training set covers easy to hard challenges.
Along the way, CuES follows three design goals:
- Executability: Tasks must be doable from start to finish.
- Diversity: Tasks should cover different tools, actions, and topics, not just one easy pattern.
- Relevance: Tasks should match what the environment is about (e.g., shopping tasks for a store, music tasks for a music app).
Main Findings
The authors tested CuES in three environments:
- AppWorld (a collection of app-like tasks),
- WebShop (an online shopping website),
- BFCL (a multi-turn, tool-using benchmark).
They found that:
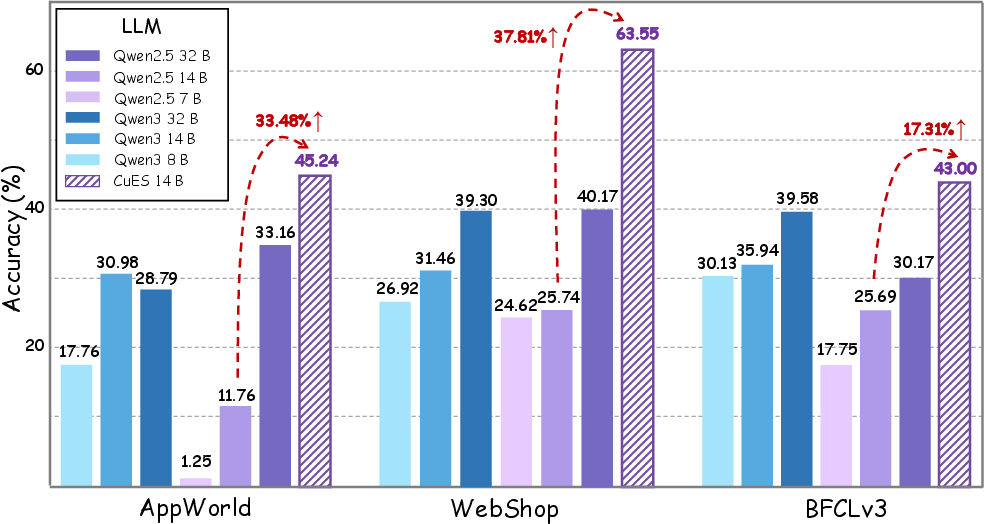
- CuES can create task sets that are as varied and executable as (or better than) human-made ones.
- Training agents on CuES-generated tasks improves how well the agents act later, often beating standard methods and even larger, more powerful models that rely on hand-crafted data.
- The tasks stay practical and transferable: even when evaluation formats differ (like multi-turn conversations), the agent still performs strongly because the tasks came from real interactions with the environment.
Why this matters: Instead of needing lots of human-written tasks, the agent learns to “learn what to learn,” turning exploration into a steady supply of good training tasks.
Implications and Impact
CuES shows a path toward scalable, self-improving AI agents:
- Less human effort: Agents can build their own training sets directly from the apps and websites they’ll use.
- Better grounding: Because tasks come from real actions the environment supports, they’re less likely to fail or be unrealistic.
- Flexible training: By rewriting goals with hints, agents get a natural curriculum from easy to hard.
- Broader adoption: This approach could help train agents in new, unfamiliar environments quickly, making them more useful in everyday tools and platforms.
In short, CuES helps AI agents not only learn how to act, but also decide what’s worth learning—an important step toward practical, reliable AI assistants.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, prioritized for actionable follow-up by future researchers.
- Intrinsic curiosity is invoked but not specified: the paper does not define or implement a formal intrinsic reward (e.g., prediction error, novelty bonus, or information gain), instead using “not-yet-attempted actions” with memory. Clarify the curiosity signal, provide equations, and ablate against standard curiosity baselines.
- Reward modeling for RL training is under-specified: the paper introduces via guidelines but does not detail how rewards are computed during policy optimization, which RL algorithm is used, or how rewards are shaped over long horizons. Provide the full training pipeline, hyperparameters, and learning curves.
- Theoretical alignment between and is unproven: no guarantees or bounds are provided on transfer from proxy tasks to target tasks. Derive conditions under which executability/diversity/relevance in imply improvement in .
- Executability judging relies on LLM-based verification without error analysis: false positives/negatives in the Judge Agent are not quantified. Measure judge accuracy against ground-truth environment signals and analyze failure cases.
- Concept pool extraction function Φ is opaque: how entities, actions, and affordances are reliably parsed from (and seed goals) is not formalized. Specify parsing heuristics/models, quantify robustness to noisy or incomplete environment descriptions, and compare against API/schema-driven extraction.
- Environment identifier extraction and memory-tree similarity are under-defined: how states are mapped to identifiers and how “similar states” are retrieved is not formalized. Define state embedding, similarity metrics, and their effects on exploration efficiency and redundancy.
- Scalability and compute cost of synthesis are not reported: the paper omits wall-clock time, token budgets, environment service overhead, and memory footprint for the five-stage pipeline across environments. Provide cost breakdowns and scaling laws.
- Robustness to non-deterministic or dynamic environments is untested: WebShop and GUIs can change over time; the paper does not assess task staleness, re-execution variance, or adaptation strategies. Add longitudinal tests and task freshness checks.
- Generalization beyond the three benchmarks is unknown: applicability to other domains (e.g., APIs without GUIs, robotics with continuous controls, multi-agent environments, partial observability) remains unverified. Conduct cross-domain studies and adapt CuES for continuous/POMDP settings.
- Safety and constraint-aware exploration are not addressed: curiosity-driven actions in real tools/web may trigger harmful or policy-violating behavior. Integrate constraint models, safety filters, and audit logs; evaluate safe exploration rates.
- Curriculum efficacy of Goal Rewrite is not demonstrated: L (rewrite depth) is introduced without showing its impact on learning progression. Ablate L, measure curriculum benefits, and propose adaptive hint scheduling.
- Data leakage and evaluation contamination are insufficiently ruled out: similarity analyses are indirect; the paper does not guarantee that synthesized training tasks do not overlap with validation/test objectives. Implement strict splits and leakage detection.
- Fairness of comparisons is unclear: CuES uses Qwen2.5 14B while baselines use heterogeneous models and “think” settings; it is uncertain if performance gains stem from synthesis or model/config differences. Include controlled ablations with the same backbone and mode across methods.
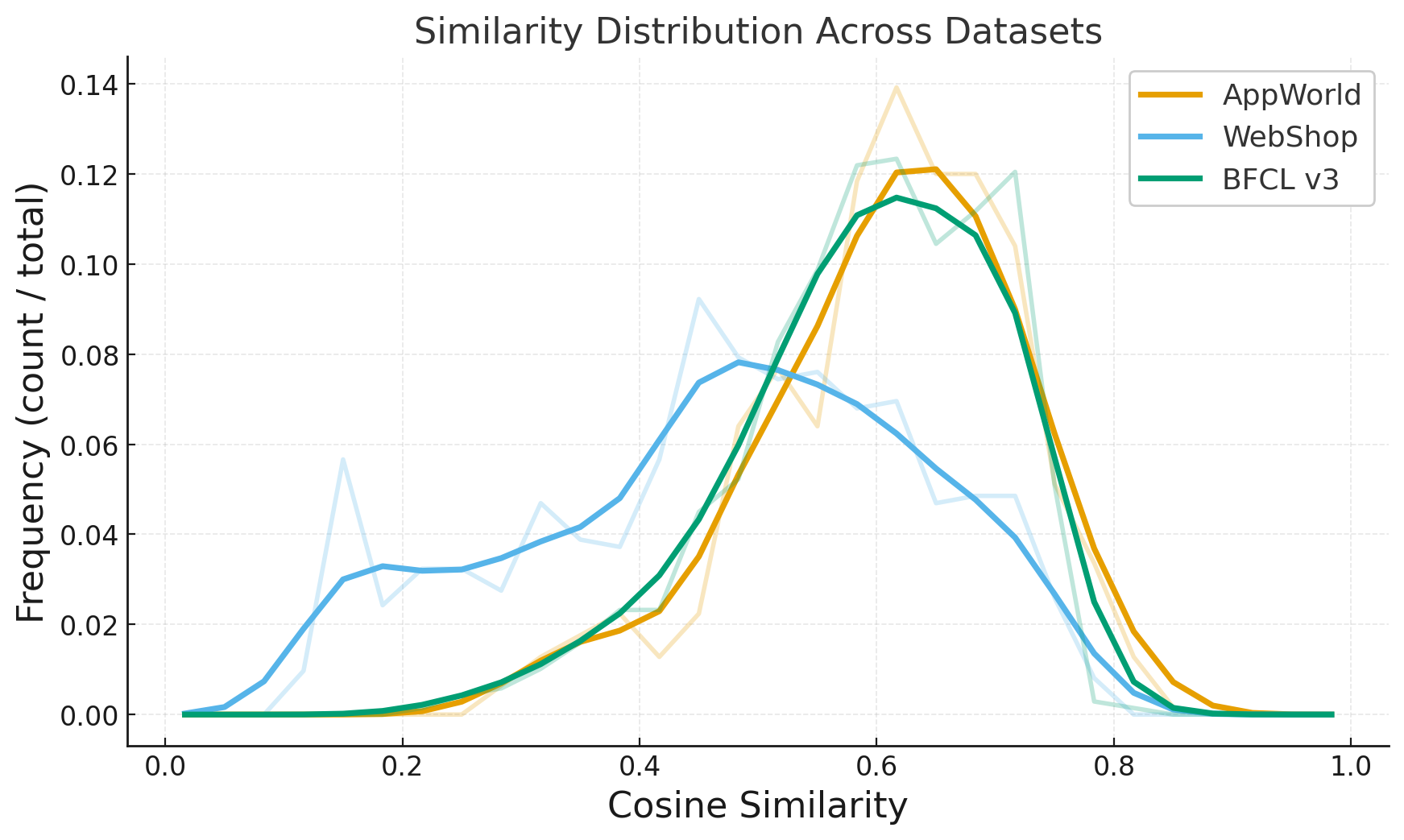
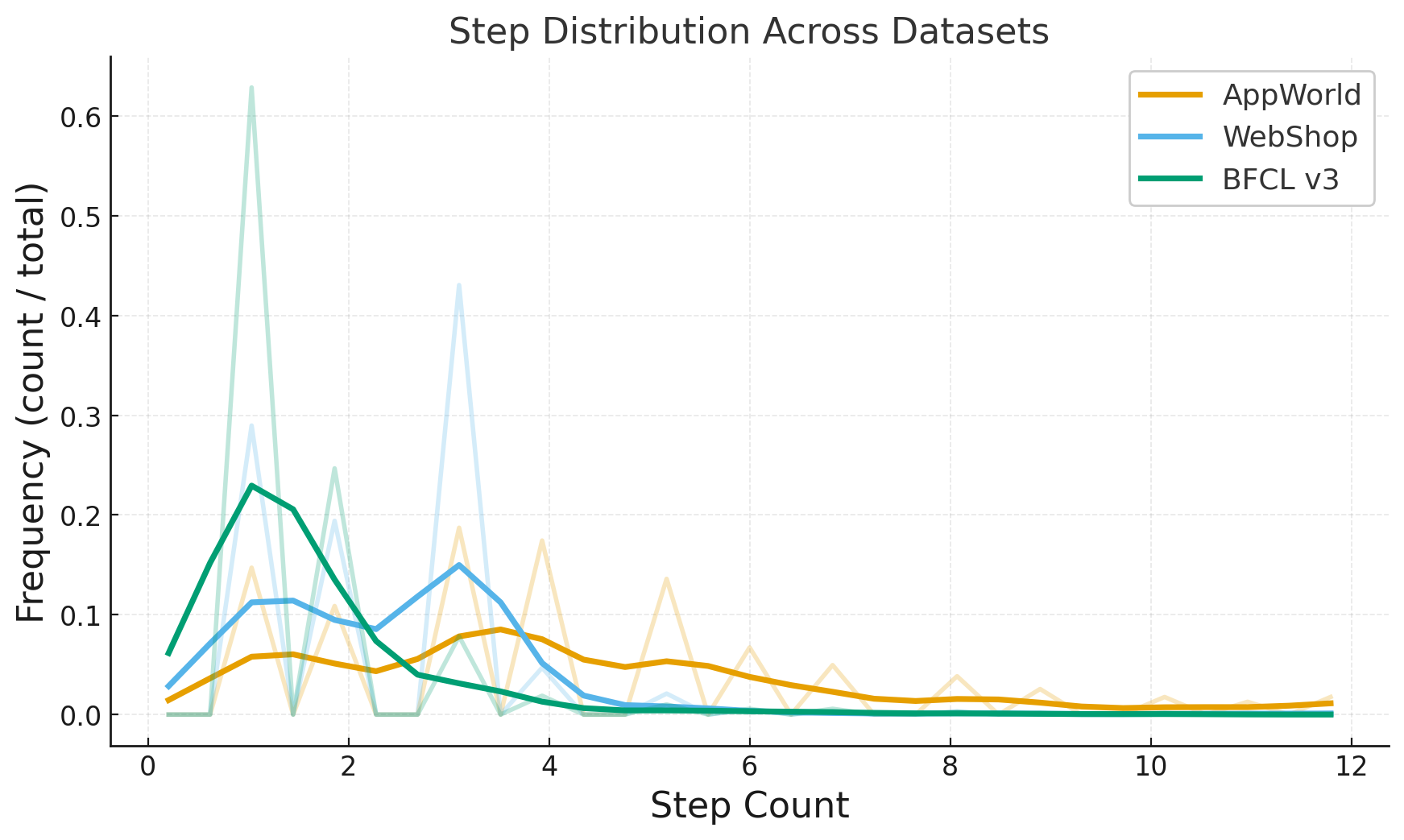
- Approximate metrics (PR, SR@k, ED_rel) may not reflect true diversity/relevance: reliance on TF–IDF+SVD embeddings could mischaracterize semantics. Evaluate with stronger encoders (e.g., SimCSE, instructor embeddings) and add human/behavioral assessments.
- No ablation of critical pipeline components: memory tree, requirement confirmation, and quality control are not individually ablated beyond limited toggles. Perform component-wise ablations to isolate contribution and interactions.
- Handling long-horizon dependencies and delayed preconditions is not analyzed: how CuES avoids myopic segments and captures prerequisites for multi-step tasks is unclear. Study segment selection strategies and precondition inference.
- Task usefulness for policy improvement lacks granular evidence: the paper reports end metrics but not per-task utility, task difficulty distributions, or sample-efficiency curves. Introduce task-level learning gain measurements and difficulty-normalized improvements.
- Handling parameterized actions and tool arguments is underspecified: how arguments are inferred/validated in guidelines and judged for correctness is not detailed. Formalize argument schemas and add argument-level executability checks.
- On-policy synthesis and closed-loop selection are deferred: CuES is largely off-policy with fixed rollouts; adaptive task selection to maximize marginal learning is an open direction. Integrate bandit/task-selection policies and measure gains.
- Robustness to noisy or missing and absence of seed goals is not quantitatively evaluated: although seeds are “optional,” performance without seeds or with degraded descriptions is not reported. Test no-seed and noisy-description regimes.
- Impact of environment timeouts and step caps on synthesis quality is unexamined: the chosen 30s/30-step limits may truncate tasks. Vary caps, measure task completeness, and adapt exploration to environment latency.
- Multi-modal grounding (e.g., vision for GUIs) is not described: how the agent perceives and abstracts visual states into tasks is unclear. Detail the visual encoder, state representations, and their role in task abstraction.
- Transfer to different interaction protocols (“think” vs “no-think,” chain-of-thought) is not fully explored: performance shifts with prompting modes may affect synthesis and training. Evaluate protocol robustness and standardize prompts.
- Failure mode taxonomy is missing: reasons for task rejection during quality control (invalid actions, partial goals, environment inconsistencies) are not categorized. Provide diagnostics and targeted fixes to raise pass rate.
Practical Applications
Immediate Applications
Below are applications that can be deployed today using the CuES framework and its demonstrated components (requirement confirmation, curiosity-driven exploration, environment memory, task abstraction, quality control, and goal rewrite).
- Enterprise UI/RPA Task Synthesis (Software, RPA)
- Automatically generate diverse, executable workflows (e.g., form submissions, report exports, data reconciliation) across internal web dashboards and desktop apps to train or fine-tune LLM-based automation agents.
- Potential tools/products/workflows: CuES-as-a-Service for RPA platforms (UiPath, Automation Anywhere), “Task Synthesizer” microservice exposing endpoints for requirement confirmation, exploration, QC, and rewrite; integration into CI/CD for agents.
- Assumptions/Dependencies: instrumented sandbox environments with tool APIs, access to environment documentation or UI schemas, reliable Execution/Judge agents, governance for credentials and audit logs.
- Continuous Training for Tool-Augmented Copilots (Software Engineering, IT Ops)
- Maintain a rolling proxy goal distribution aligned to real tools to improve agent policies without human-authored tasks (e.g., cloud console operations, ticket routing, knowledge-base updates).
- Potential tools/products/workflows: “Agent Curriculum Designer” pipeline in MLOps; environment-indexed memory store for reusable task schemas; scheduled synthesis runs with quality gates.
- Assumptions/Dependencies: stable environment interfaces, compute for exploration/QC, monitoring for drift between synthesized tasks and current operation norms.
- E-commerce Assistant Training and Evaluation (Retail/E-commerce)
- Generate shopping tasks (search, filter, compare, checkout) grounded in live or simulated catalogs to improve purchase success and product discovery behaviors.
- Potential tools/products/workflows: “ShopFlow Task Library” for agent RL; WebNav datasets with progressive goal rewrites for curriculum learning.
- Assumptions/Dependencies: controlled web environment or staging site, product metadata access, session management and anti-abuse safeguards.
- Executable User-Flow Generation for QA (Software QA/Test Automation)
- Produce validated regression scenarios (including edge cases) for GUI and web apps that reflect actual affordances, improving test coverage and reducing flaky tests.
- Potential tools/products/workflows: “Exploration-QA” generator integrated into test pipelines; concept pool–guided scenario targeting for new features.
- Assumptions/Dependencies: deterministic test environments, versioned UI/build artifacts, stable observation APIs for execution traces.
- Customer Support Workflow Automation (Customer Service/CRM)
- Craft tasks for ticket triage, macro creation, structured data extraction, and knowledge-base updates, aligned with CRM tool semantics.
- Potential tools/products/workflows: CRM-specific concept pool builder; agent training datasets with verified paths; progressive rewrites for novice-to-expert workflows.
- Assumptions/Dependencies: access-controlled CRM sandboxes, PII/privacy constraints, logging and rollback capabilities.
- Educational Lab Simulations and Auto-Curricula (Education/EdTech)
- Build executable tasks for coding labs, data exploration, or software literacy tutorials; use goal rewrite to shape difficulty from beginner hints to expert prompts.
- Potential tools/products/workflows: “Auto-Curriculum” builder for sandboxed learning platforms; task memory per course/environment.
- Assumptions/Dependencies: pedagogical alignment (learning objectives mapped to concepts), safe sandboxes, instructor review of synthesized goals.
- Benchmark Refresh and Task Scarcity Mitigation (Academia, Evaluation)
- Create environment-grounded, diverse benchmarks to assess agentic RL without relying on static or hand-curated tasks (reducing “overfitting to benchmarks”).
- Potential tools/products/workflows: open-source synthesis pipelines standardized around executability/diversity/relevance; shared task repositories with provenance.
- Assumptions/Dependencies: transparent environment specifications, agreed metrics (pass rate, self-redundancy, energy distance), reproducible synthesis configurations.
- Personal Digital Assistant “Skill Discovery” (Daily Life/Consumer Software)
- In local app ecosystems (mail, calendar, files), discover repeatable interactions and propose turnkey automations (e.g., filing receipts, organizing attachments).
- Potential tools/products/workflows: on-device CuES in privacy-preserving mode; user-in-the-loop approval for tasks and rewrites; safety filters for sensitive actions.
- Assumptions/Dependencies: local sandboxing, strict privacy/consent, throttled exploration to avoid disruption, robust rollback.
- Data Augmentation for Web Navigation/Search (Software, Information Retrieval)
- Generate solvable navigation tasks for training agents in browsing, query refinement, and structured extraction, grounded in page affordances.
- Potential tools/products/workflows: “WebNav-Synth” datasets; lightweight top-down guidance via concept pools to reduce drift.
- Assumptions/Dependencies: availability of crawlable/staged sites, content stability during synthesis, anti-scraping compliance.
- Agent Memory and Concept Pool Services (Enablement/Platform)
- Productize environment-indexed memory and concept pool construction as reusable components for multiple teams and domains.
- Potential tools/products/workflows: “Agent Task Graph” store capturing validated goals and trajectories; concept pool builder from environment docs and seed tasks.
- Assumptions/Dependencies: versioning of environments and tasks, multi-tenant storage, access controls, lifecycle management.
Long-Term Applications
These applications require further research, scaling, domain adaptation, safety validation, or integration with additional components (e.g., reward modeling, formal verification).
- Embodied Robotics Task Generation (Robotics)
- Extend CuES to physical environments to autonomously craft manipulation/navigation tasks from discovered affordances in simulation and real-world setups.
- Potential tools/products/workflows: sim-to-real curriculum synthesis; sensor-driven concept pools (objects, constraints); safety-aware exploration policies.
- Assumptions/Dependencies: high-fidelity simulation, robust perception and actuation, stringent safety guardrails, formal hazard detection and recovery.
- Healthcare EHR/EMR Workflow Training (Healthcare)
- Generate validated clinical admin workflows (order entry, coding, referral management) aligned to EHR affordances, improving agent copilots for clinicians.
- Potential tools/products/workflows: HIPAA-compliant synthesis pipelines; human-in-the-loop QC; domain-specific reward shaping.
- Assumptions/Dependencies: strict privacy, regulatory approval, institutional partnerships, comprehensive audit, fail-safe execution policies.
- Industrial Control/SCADA Task Synthesis (Energy/Manufacturing)
- Produce operator training tasks for SCADA/HMI systems (alarms, setpoints, trend analysis) grounded in device and system affordances.
- Potential tools/products/workflows: certified training environments; curriculum progression for abnormal scenarios; formal verification of task executability.
- Assumptions/Dependencies: safety-critical certification, sandboxing that mirrors real constraints, incident response integration.
- Finance Ops and Compliance Agents (Finance)
- Generate tasks in trading/back-office UIs (reconciliation, reporting, KYC checks) with strong rule adherence and audit trails.
- Potential tools/products/workflows: compliance-focused concept pools; policy-aware goal rewrite to encode constraints; risk scoring for synthesized tasks.
- Assumptions/Dependencies: regulatory mappings, explainability and logging, change management in fast-moving platforms.
- Scientific Experiment Design Assistants (Academia/Research)
- Use concept pools from lab equipment/protocols to synthesize executable experiment plans and data collection workflows in digital labs.
- Potential tools/products/workflows: “Auto-Protocol” generation; validation against lab simulators; curricula for scientific method steps.
- Assumptions/Dependencies: domain ontologies, causal grounding beyond text affordances, instrument APIs or high-fidelity simulators.
- On-Policy Synthesis with Learned Reward Models (AI/ML Platforms)
- Close the loop by coupling CuES with environment-specific reward modeling and on-policy data generation for continual improvement.
- Potential tools/products/workflows: adaptive synthesis schedules; reward model training from Judge/Execution traces; stability controls for RL.
- Assumptions/Dependencies: robust reward estimation, avoidance of feedback loops and exploitation, scalable training infrastructure.
- Cross-Environment Knowledge Transfer (Enterprise Platforms)
- Build organization-wide task graphs that generalize across tools (e.g., CRM, ERP, BI) and versions, reducing cold-start in new environments.
- Potential tools/products/workflows: global concept repository; transfer learning of task schemas; drift detection across releases.
- Assumptions/Dependencies: consistent abstraction layers, stable identifiers/ontologies, strong versioning and provenance.
- Safety-Aware Exploration and Governance (Policy, Safety)
- Embed normative constraints (privacy, safety, fairness) and audit requirements directly into requirement confirmation and judge policies.
- Potential tools/products/workflows: policy-aware synthesis templates; guardrail libraries; compliance scorecards for synthesized tasks.
- Assumptions/Dependencies: codified policies, formal constraint checking, external audits, continuous monitoring.
- Standardization of Environment-Grounded Benchmarks (Policy, Standards)
- Develop sector-specific standards for executability, diversity, and relevance metrics to evaluate agent performance on dynamic, tool-rich environments.
- Potential tools/products/workflows: public benchmark suites with synthesis recipes; certification programs for agent readiness.
- Assumptions/Dependencies: multi-stakeholder consensus, open measurement protocols, reproducible environments.
- Multi-Agent Collaborative Synthesis (Software/Robotics)
- Coordinate multiple explorer agents with complementary concept pools to cover larger or more complex environments efficiently.
- Potential tools/products/workflows: coordination protocols; shared memory trees; conflict resolution and redundancy minimization.
- Assumptions/Dependencies: communication and synchronization primitives, scalable memory stores, strategies to mitigate emergent bias or mode collapse.
Glossary
- Affordances: Action possibilities offered by tools or objects within an environment. "where tool semantics and affordances are initially unknown."
- Agentic RL: Reinforcement learning centered on autonomous agents that decide and act in complex environments. "limits progress in agentic RL"
- Bottom-up exploration: Discovering tasks by interacting with the environment rather than starting from predefined goals. "via Bottom-Up Exploration and Top-Down Guidance"
- Concept pool: A curated set of environment-specific entities and actions used to guide exploration. "a concept pool $\tilde{\mathcal{C}$, which grounds subsequent exploration"
- Energy distance: A statistical measure of distributional difference used to compare sets of embeddings. "The energy distance is"
- Environment-grounded task generation: Creating executable tasks directly from environment dynamics and structure. "environment-grounded task generation can effectively replace costly human task design."
- Environment-indexed memory: A memory keyed by environment identifiers to avoid redundant exploration and reuse learned traces. "we maintain an environment-indexed memory that reuses what was tried before."
- Executability: The property that proposed tasks can be successfully executed to recognizable outcomes. "Executability ensures proposed goals are admissible and terminate in recognizable outcomes"
- Goal-conditioned policy: A policy that selects actions conditioned on a specified goal state. "a goal-conditioned policy aims to maximize"
- Goal Rewrite: A stage that adjusts task difficulty by progressively adding hints derived from the execution guideline. "we introduce the Goal Rewrite stage"
- Interaction sandbox: An environment specification of states, actions, and transitions that omits rewards and explicit tasks. "Formally, the sandboxed environment is"
- Intrinsic curiosity: Internal motivation guiding exploration without external rewards, used to discover solvable behaviors. "CuES drives exploration through intrinsic curiosity"
- Markov Decision Process (MDP): A formal framework for sequential decision-making with states, actions, transitions, and rewards. "In contrast to a standard Markov Decision Process"
- Proxy Objective for Environment-Conditioned Agentic Learning: The optimization target defined over synthesized goals when true goal distributions and rewards are unavailable. "which serves as the Proxy Objective for Environment-Conditioned Agentic Learning."
- Requirement Confirmation: A stage that extracts environment concepts and actionable principles to guide relevant exploration. "Requirement Confirmation stage"
- Self-Redundancy (SR@k): A diversity metric quantifying similarity among synthesized intents via k-nearest neighbors. "diversity by Self-Redundancy over nearest neighbors"
- t-SNE: A dimensionality reduction technique for visualizing high-dimensional embeddings. "Figure~\ref{fig:dist_grid} shows t-SNE projections of sentence embeddings"
- Task Abstraction: Transforming raw interaction trajectories into reusable, executable task specifications. "Task Abstraction stage takes a consecutive mini-batch of exploration triples"
- Task mapping: A mapping from an environment to a trainable goal distribution used for proxy optimization. "We induce a trainable goal distribution from the environment by defining the task mapping"
- TF–IDF+SVD embeddings: Text embedding method combining TF–IDF weighting with low-dimensional projection via SVD. "TFâIDF+SVD embeddings"
- Top-down guidance: Lightweight directives that shape exploration priorities without prescribing exact tasks. "lightweight top-down guidance"
- Top-down imitation-based synthesis: Generating tasks by expanding seed goals or mimicking existing datasets. "Top-down imitation-based synthesis: mimicking existing data"
Collections
Sign up for free to add this paper to one or more collections.