- The paper introduces C-BET, a framework that leverages prior experiences to learn exploratory policies transferable across different environments.
- It combines agent-centric and environment-centric strategies by using intrinsic rewards based on state visitation and novel environmental changes.
- Experimental results in MiniGrid and Habitat show enhanced scene coverage and faster task completion compared to state-of-the-art methods.
Exploring Task-Agnostic Reinforcement Learning through Intrinsically Motivated Agents
Introduction
Exploration remains a pivotal challenge in designing intelligent agents that emulate human-like behavior, especially within the framework of Reinforcement Learning (RL). Traditional approaches to exploration are bifurcated into task-driven, where rewards guide the agent, and task-agnostic, where the environment lacks explicit rewards, requiring intrinsic motivation instead. The paper "Interesting Object, Curious Agent: Learning Task-Agnostic Exploration" (2111.13119) critiques the isolation inherent in existing task-agnostic methods, proposing a paradigm shift: to utilize prior experiences in learning more effective exploratory policies transferrable across environments, akin to human learning processes.
The authors argue against the concept of tabula rasa learning, where agents approach new environments devoid of prior experiences. Instead, they propose a multi-environment interaction framework to learn exploratory policies, focusing on two core components: agent-centric (encouraging exploration of unknown areas) and environment-centric (seeking inherently interesting objects). The aim is for an agent to exploit these learned policies in new, unseen environments, thus achieving efficient exploration without needing to start afresh.
Methodology: Change-Based Exploration Transfer (C-BET)
C-BET, the proposed approach, innovatively fuses agent-centric and environment-centric strategies to devise exploration policies. It posits that exploration should prioritize both simplistic (navigational) and complex (interaction with novel objects) rewards. The intrinsic reward is formulated as inversely proportional to visitation counts of states and changes, fostering interest in less-explored states and environmental changes.
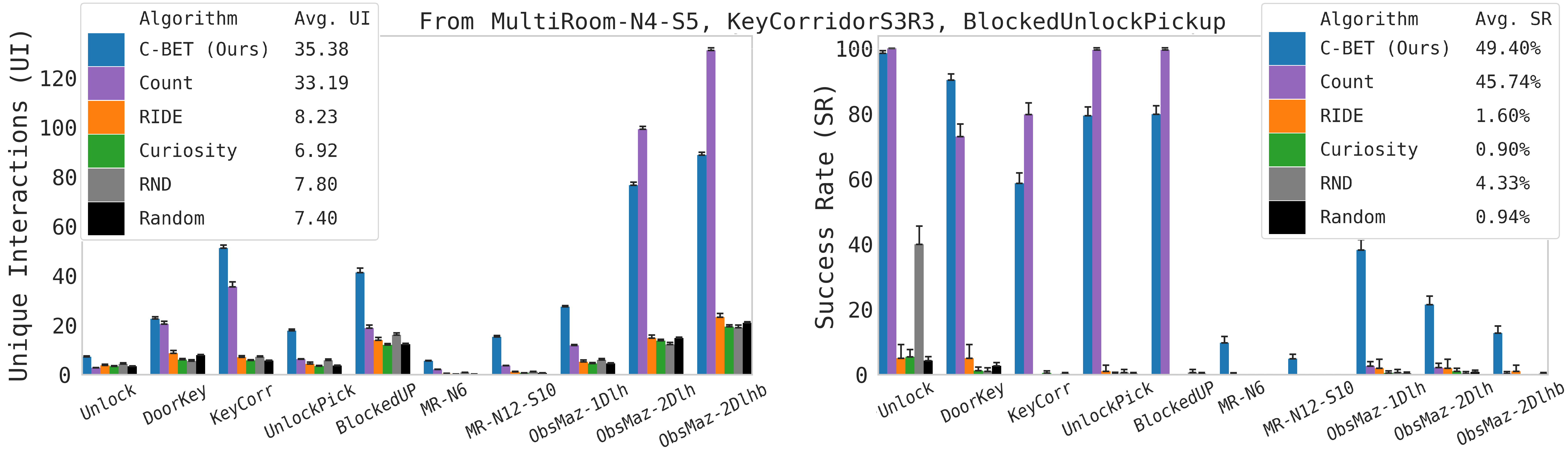
Figure 1: Pre-training phase in multiple MiniGrid environments showing accumulated unique interactions, indicating effective exploration policies.
Evaluation Framework
C-BET is evaluated across two primary environments: MiniGrid, a grid-based world featuring distinct objects like doors and keys, and Habitat, a realistic navigation simulator. The agent's success is measured by its ability to transfer learned exploration strategies to completely new environments and achieve task goals with minimal additional learning.
Figure 2: Results showcasing C-BET's performance across MiniGrid environments, emphasizing significant success transfer and quick task completion.
Experimental Results
MiniGrid Experiments: C-BET's exploration policy, pretrained in multiple MiniGrid environments, outperformed state-of-the-art methods, achieving higher interaction success rates and goal accomplishment in new settings. Without extrinsic rewards during pre-training, C-BET's inherent understanding of exploration improved task-specific performance post-transfer.
Habitat Experiments: The transferability of C-BET was further validated in more complex, visually rich environments. The learning agent demonstrated superior scene coverage and state exploration compared to baseline methods, even when faced with new scenes that included unseen attributes.
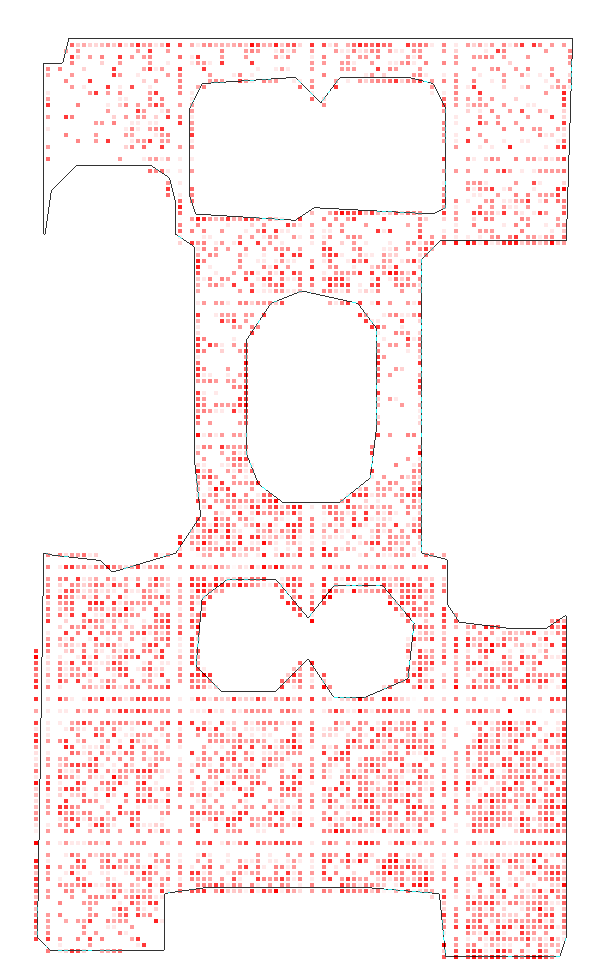
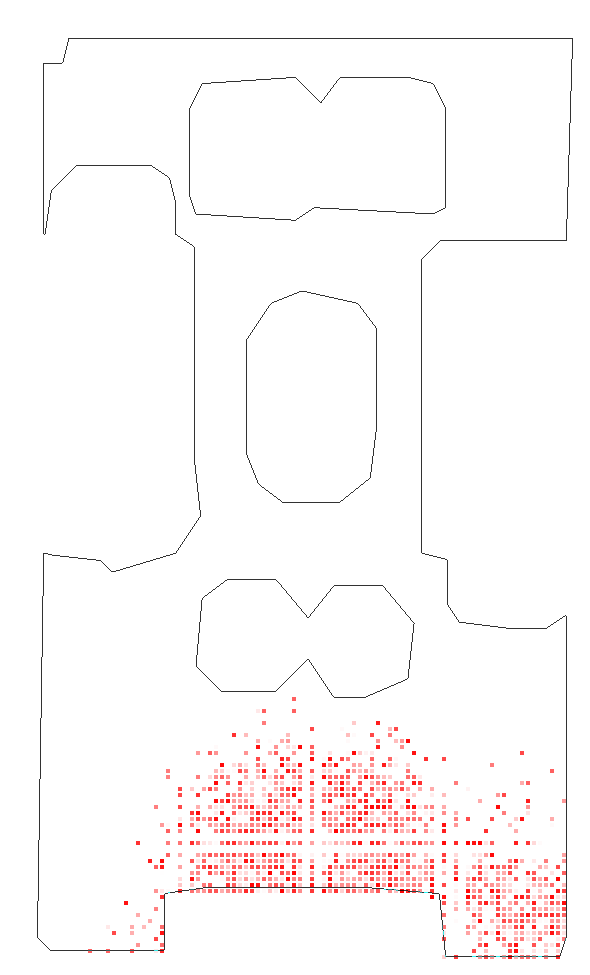
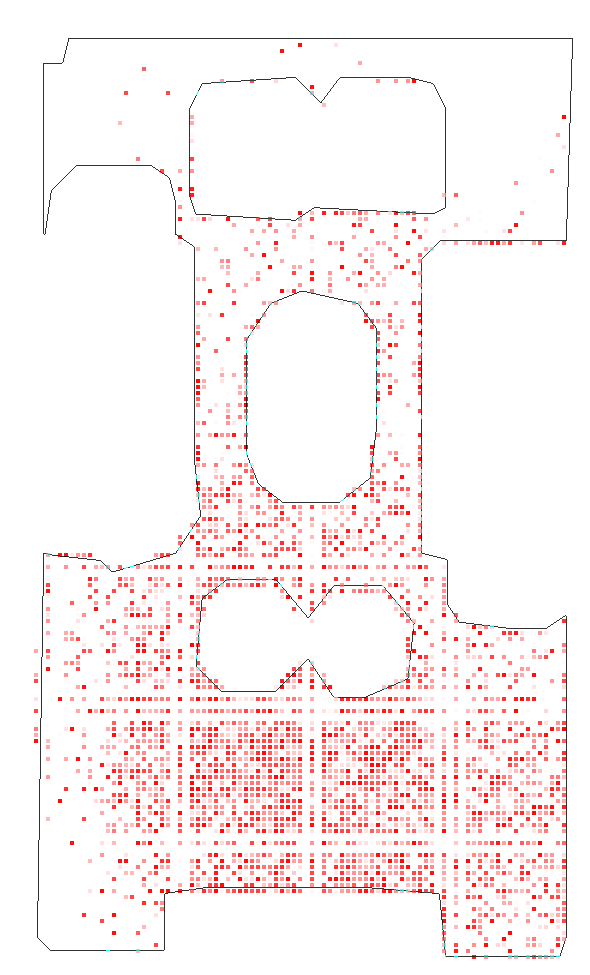
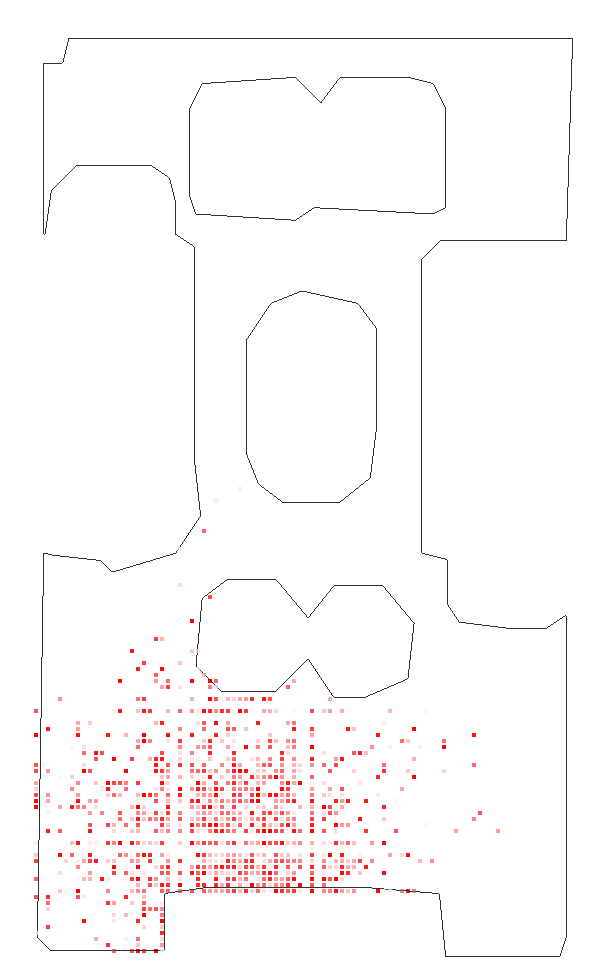
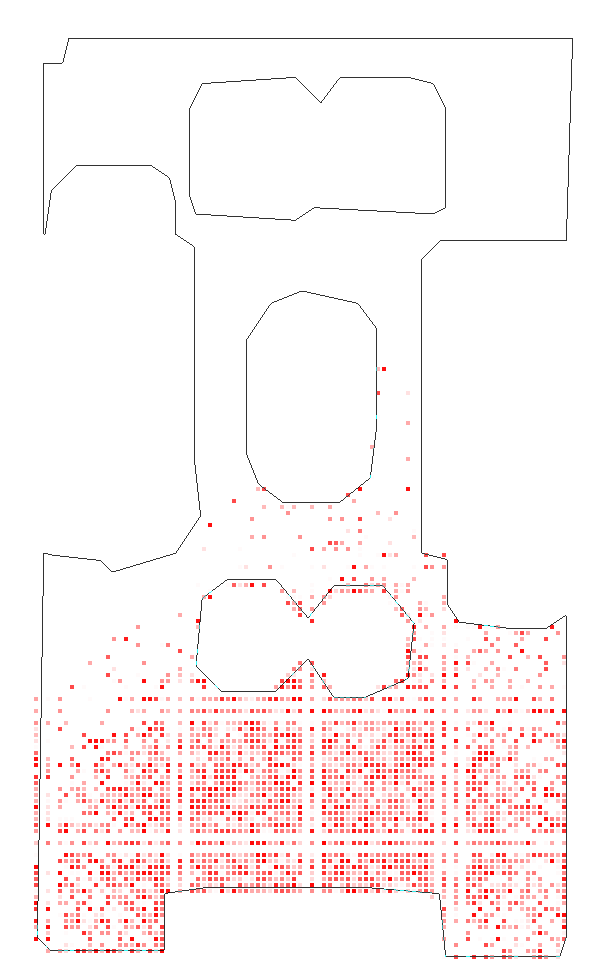
Figure 3: Detailed scene coverage in Habitat tests, where the robustness of C-BET's transfer policy is highlighted through its ability to uniformly explore unfamiliar environments.
Implications and Future Directions
The findings underscore the potential of learning exploratory behaviors via accumulated experiences across diverse settings. Practically, C-BET can significantly heighten efficiency in applications such as autonomous navigation, where preliminary exploration is costly or impractical. Theoretically, the shift to environment-centric motivations could foster innovations in how models simulate and adapt to real-world complexities.
Future research may explore the implications of exploration policy transfer in domains with continuous state variables or detailed object interactions, potentially introducing additional mechanisms to handle environments with stochastic transitions or dynamic changes, which could further refine the efficacy and versatility of such task-agnostic exploration protocols.
Conclusion
In advancing the conceptual landscape of task-agnostic exploration, this work provides a sophisticated framework that blends intrinsic motivations with cross-environment learning strategies. Through C-BET, the potential for better integration of experience-driven learning in AI systems is illuminated, thereby paving the way for a more adaptive and context-aware generation of intelligent agents.