- The paper introduces a high-dynamic game video generation framework that integrates unified action representation, hybrid history conditioning, and model distillation.
- It employs autoregressive training with a variable mask indicator to maintain long-term video coherence and precise control accuracy.
- Experimental results demonstrate significant improvements in real-time gameplay, achieving superior FVD and RPE metrics compared to traditional methods.
Hunyuan-GameCraft: High-Dynamic Interactive Game Video Generation with Hybrid History Condition
Introduction
"Hunyuan-GameCraft: High-dynamic Interactive Game Video Generation with Hybrid History Condition" introduces an advanced framework for generating interactive game videos characterized by high dynamics and extended temporal coherence. This paper addresses the limitations of existing video generation methodologies, particularly in terms of action controllability, long-term consistency, and efficiency of video generation in interactive environments.
Methodology
Hunyuan-GameCraft is built upon the foundation of the text-to-video model HunyuanVideo, enhancing it with specialized techniques to cater to interactive game video generation. The methodology revolves around three primary innovations:
- Unified Action Representation: The framework introduces a shared camera representation space that integrates standard keyboard and mouse inputs (e.g., W, A, S, D) to facilitate seamless transitions between camera views and movements. This space is crucial for achieving fine-grained action control and is encoded using a lightweight action encoder that efficiently processes camera trajectories.
- Hybrid History-Conditioned Training: This novel training strategy uses autoregressive models to extend video sequences, preserving game scene information through historical context integration. The framework employs a variable mask indicator to differentiate between historical and predicted frames, effectively minimizing error accumulation over sequences and maintaining scene coherence over long durations.
- Model Distillation for Efficiency: To optimize performance for real-time application, Hunyuan-GameCraft adopts model distillation techniques that accelerate inference, reducing computational overhead while sustaining the high quality of video generation. This approach makes it feasible for real-time deployment in intricate interactive scenarios.
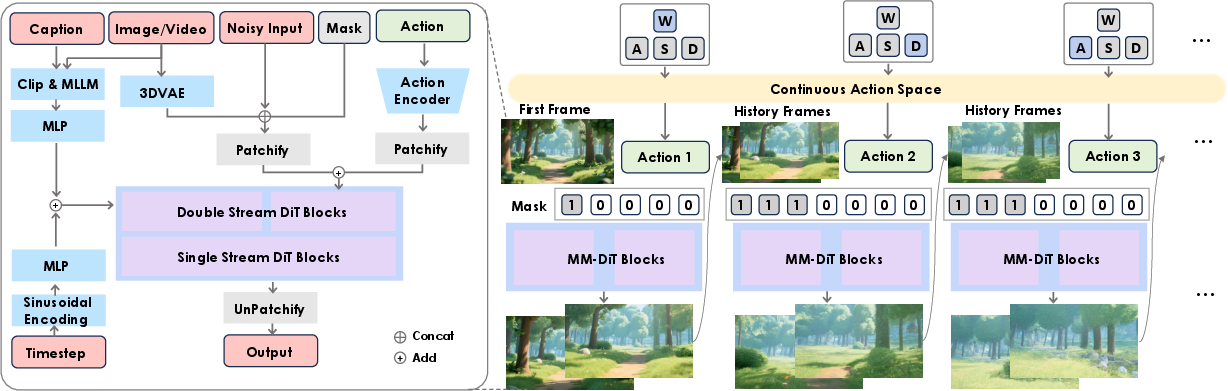
Figure 1: Overall architecture of Hunyuan-GameCraft, showcasing the transformation of inputs into the continuous camera space for action encoding and video extension.
Dataset and Training
The model is trained utilizing a comprehensive dataset sourced from over one million gameplay recordings complemented by fine-tuned synthetic data. This dataset ensures diversity across various game styles and environments, contributing to the model's robust performance in generating visually accurate and dynamically responsive videos. The dataset construction involves a meticulous process of action annotation, interaction data curation, and synthetic data generation, addressing any scarcity of annotated gameplay.
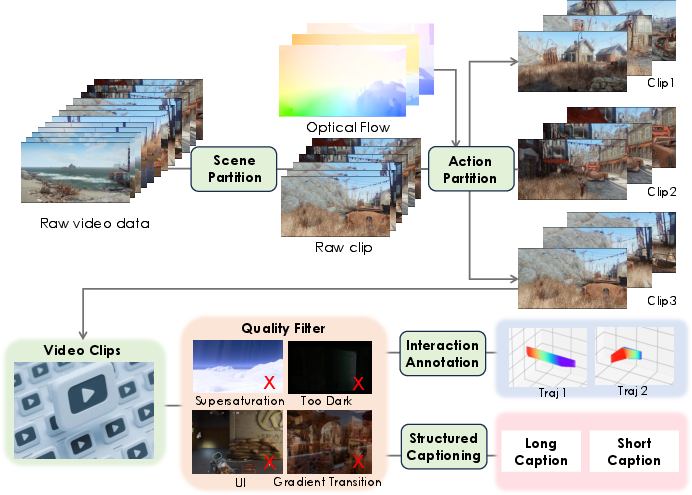
Figure 2: Dataset Construction Pipeline, detailing the pre-processing steps essential for creating a diverse and actionable dataset.
The chosen architecture and training methodology demonstrate significant enhancements over traditional video generation models, particularly in the capability for real-time interaction and control accuracy:
Future Directions
Given its current design, Hunyuan-GameCraft serves as a robust platform for further research into more diversified game interactions. The current action space focuses on basic exploratory motions; however, future iterations can incorporate a wider range of game-specific actions such as combat maneuvers or environmental interactions. Additionally, expanding the dataset to include more varied interactions will enable a more comprehensive evaluation of the model's capabilities and applications in different gaming contexts.
Conclusion
The introduction of Hunyuan-GameCraft represents a significant advancement in real-time interactive game video generation. By integrating innovations in action space representation, training methodologies, and efficiency-focused model enhancements, the framework sets a new benchmark for the generation of high-quality, dynamic game videos. This work not only contributes to the field of video generation technology but also opens new possibilities for immersive and responsive gaming experiences.
