Every Token Counts: Generalizing 16M Ultra-Long Context in Large Language Models
Abstract: This work explores the challenge of building ``Machines that Can Remember'', framing long-term memory as the problem of efficient ultra-long context modeling. We argue that this requires three key properties: \textbf{sparsity}, \textbf{random-access flexibility}, and \textbf{length generalization}. To address ultra-long-context modeling, we leverage Hierarchical Sparse Attention (HSA), a novel attention mechanism that satisfies all three properties. We integrate HSA into Transformers to build HSA-UltraLong, which is an 8B-parameter MoE model trained on over 8 trillion tokens and is rigorously evaluated on different tasks with in-domain and out-of-domain context lengths to demonstrate its capability in handling ultra-long contexts. Results show that our model performs comparably to full-attention baselines on in-domain lengths while achieving over 90\% accuracy on most in-context retrieval tasks with contexts up to 16M. This report outlines our experimental insights and open problems, contributing a foundation for future research in ultra-long context modeling.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching LLMs, like chatbots, to remember and use extremely long pieces of text—up to 16 million tokens. A “token” is just a small chunk of text (like a word or part of a word). The authors build a system that lets the model quickly find the right parts of a huge text without reading everything, so it can handle long conversations, documents, or even entire libraries of information.
Key Objectives
The paper asks: How can we build AI “machines that can remember” for a very long time? To do that, the authors focus on three big goals:
- Sparsity: Don’t look at everything—only the most relevant parts.
- Random Access: Jump directly to the right spot in the past text when needed.
- Length Generalization: Learn on short texts and still work well on much longer ones later.
How They Did It
Think of a LLM reading a very long book. If it tries to remember every word, it gets overwhelmed. Instead, the authors teach it to organize the book like a well-indexed library.
- Chunks and Landmarks:
- The long text is split into small “chunks” (like pages).
- Each chunk has a “landmark” (a summary or index card) that represents what’s on that page.
- Retrieval like a Search Engine:
- When the model needs information for the next word, it uses the landmarks to score which chunks are most relevant, picks the top few (“top-k”), and focuses on those.
- Attention per Chunk, then Fuse:
- “Attention” is the model’s way of focusing on important text. Instead of attending to all chunks at once, the model attends to the selected chunks one by one and then combines the results, weighting each by how relevant it was. This is like reading the few most relevant pages carefully and then merging what you learned.
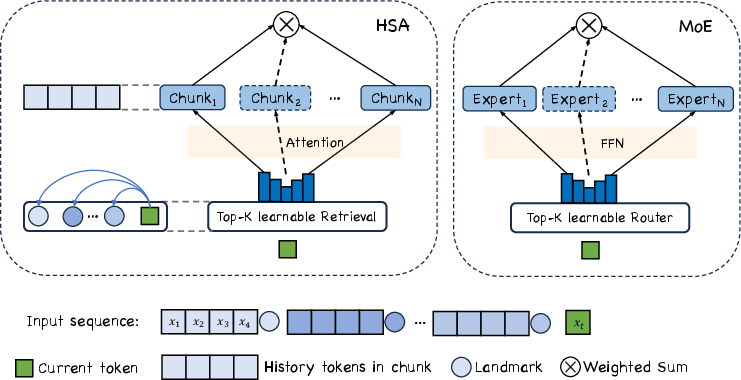
This approach is called Hierarchical Sparse Attention (HSA). It’s “hierarchical” because it first searches chunks using landmarks (coarse search), then reads inside the chosen chunks (fine reading). It’s “sparse” because it only reads a few chunks, not the whole book.
To make this work inside a modern model:
- Sliding-Window Attention (SWA): The model still uses a short “local” window (like reading the last few pages carefully) to keep immediate context strong.
- NoPE vs RoPE:
- Positional encoding helps models know where tokens are in the text.
- The authors use RoPE in the short local window (it works well there).
- They use No Positional Encoding (NoPE) for the long-range HSA part, which helps the model generalize to much longer texts than it saw during training.
- Mixture-of-Experts (MoE):
- Imagine having many mini-experts specialized in different kinds of text.
- The model routes tokens to a few relevant experts, which makes it powerful without being too slow.
- KV Cache Sharing:
- The model stores intermediate summaries of chunks (like keeping notes) and shares them across layers to save memory.
- Training in Stages:
- Warm-up: Start with a small local window and let HSA see the whole sequence so it learns retrieval.
- Pre-training: Increase the local window to 4K tokens, make HSA sparser.
- Long-context mid-training: Use data with longer “effective contexts” (texts where earlier parts matter) and expand context to 32K.
- Annealing: Polish the model on high-quality data.
- Supervised fine-tuning (SFT): Teach the model to follow instructions and do tasks better.
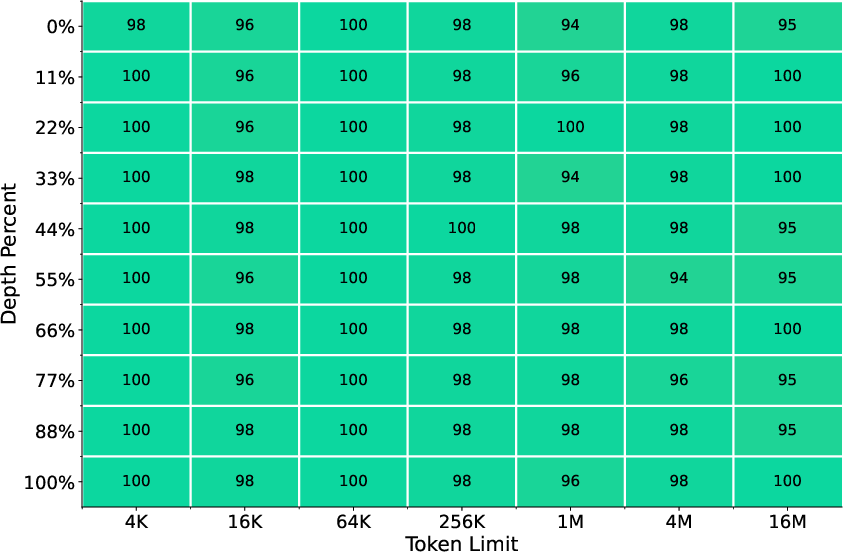
For evaluation, they use standard benchmarks (math, coding, general knowledge) and special tests like “Needle-in-a-Haystack” (NIAH), where a hidden word or fact is buried inside a very long text, and the model must retrieve it.
Main Findings
Here are the most important results and why they matter:
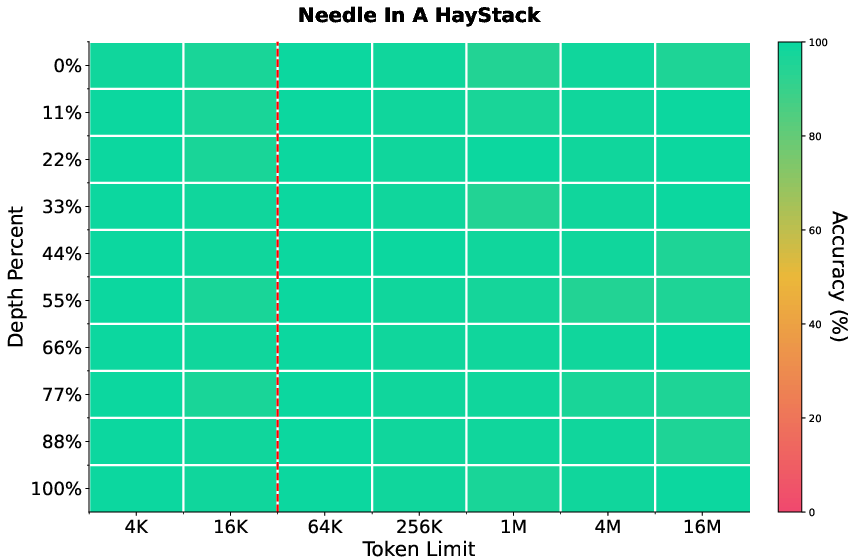
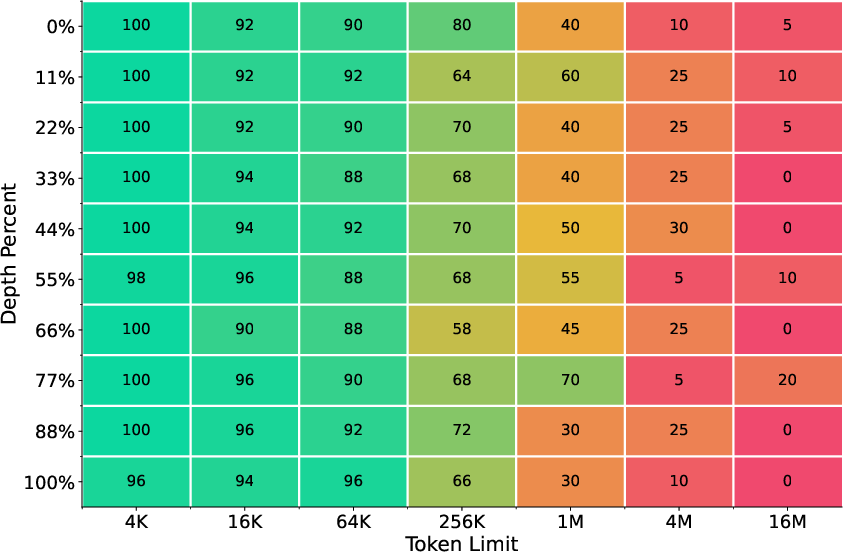
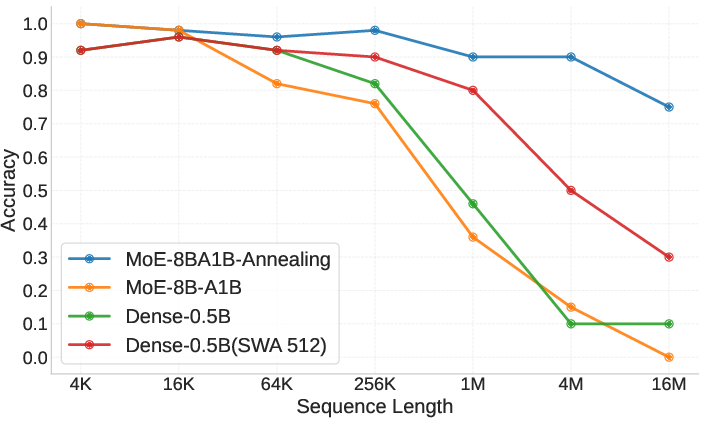
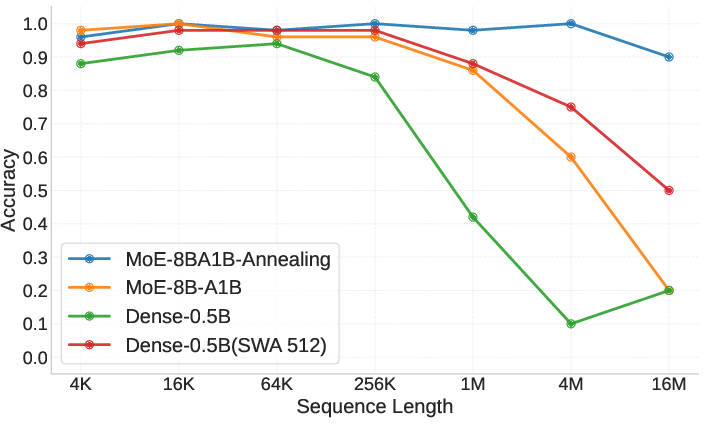
- Ultra-long retrieval works: Even though the model was trained with 8K–32K context windows, it can retrieve the right information from contexts up to 16 million tokens with over 90% accuracy on most retrieval tasks. That’s a huge jump beyond its training length.
- Comparable in normal contexts: On usual benchmarks (math, coding, general knowledge), the HSA-based model performs similarly to standard full-attention models, even though it looks at fewer tokens at a time. This shows you don’t have to sacrifice everyday performance to get long memory.
- The right data matters: “Effective context length” (how often earlier text truly matters) strongly affects how well the model generalizes to long sequences. Training on data where distant information is actually useful helps it learn to retrieve better over long ranges.
- Balance between local and global attention: There’s a “seesaw effect.” If the local sliding window is too big, HSA doesn’t learn to retrieve as well, because the local window already solves many short-range problems. Smaller local windows during some training phases help HSA learn retrieval that scales to long contexts.
- Bigger models reason better: Larger models (like the 8B MoE) do better on tasks that require both retrieval and reasoning (for example, tracking variables over long texts), even if smaller models are fine at simple retrieval.
- Efficiency trade-offs: For short sequences, standard fast attention (like FlashAttention-3) is quicker. HSA becomes more efficient as sequences get very long, because it doesn’t process everything—only the important chunks.
Why This Is Important
If AI can remember and use very long histories, it can:
- Keep track of long conversations and personal preferences over time.
- Learn new information “in context” (from text you give it) without always retraining its internal weights.
- Act more like an assistant that builds a memory of your projects, documents, and codebase, and quickly retrieves what you need.
In short, this research moves AI closer to having a practical, scalable long-term memory.
Implications and Impact
This approach could lead to:
- Personalized AI agents that remember what matters to each user over weeks, months, or years.
- Better tools for reading and searching massive documents, code repositories, or scientific literature.
- More efficient models for extremely long inputs, saving time and compute by focusing only on relevant parts.
There are still challenges: balancing local vs global attention, fixing the current head layout constraints in HSA, and speeding up kernels so short texts are also fast. But the core idea—retrieve relevant chunks and attend to them individually, then fuse the results—shows a promising path toward “machines that can remember” at truly massive scales.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances Hierarchical Sparse Attention (HSA) for ultra-long context modeling, but several aspects remain missing, uncertain, or unexplored. Future researchers could address the following gaps:
- Lack of evaluation on real-world tasks at million-token to 16M-token contexts (e.g., multi-document QA, code retrieval across large repositories, long-form summarization), beyond synthetic RULER/NIAH-style probes.
- No systematic analysis of failure modes for HSA retrieval at very long lengths (e.g., robustness to distractors, noise, adversarial prompts, dense repetition, or pointer-chasing/indirection tasks).
- Unclear causal correctness of the bi-directional chunk encoder used to produce landmark representations: potential information leakage within a chunk for token positions earlier than the chunk’s end is not ruled out; a causal or prefix-masked alternative and its trade-offs are not studied.
- The “seesaw” interaction between Sliding-Window Attention (SWA) and HSA is observed but not quantified; there is no principled schedule, curriculum, or multi-objective training method to preserve extrapolation through SFT and downstream tuning.
- Limited ablation on architectural hyperparameters: sensitivity to chunk size , top- retrieval, number and placement of HSA layers, number of groups , and fusion weighting schemes is not thoroughly characterized for both in-domain and extrapolation performance.
- Positional encoding choices are narrow (“RoPE for short, NoPE for long”); alternatives (e.g., ALiBi, RoPE scaling, relative position encodings, hybrid or learned positional schemes per module) are not compared for extrapolation stability.
- Retrieval fusion is fixed to softmax-normalized landmark scores; alternative fusion strategies (e.g., gating networks, sparsemax, confidence calibration, margin-based fusion, or retrieval-aware regularizers) and their impact on stability and performance are unexplored.
- No explicit regularization or balancing for HSA chunk selection (analogous to MoE load balancing); risks of retrieval collapse, popularity bias, or over-concentration on frequent chunks are not analyzed or mitigated.
- Head ratio constraint (16:1 query heads to key–value heads) is acknowledged as a bottleneck, but there is no exploration of kernel, architectural, or parameterization changes to relax this constraint while maintaining stability.
- KV-cache sharing across HSA modules is proposed without a thorough study of interference, capacity limits, eviction/TTL policies, and the impact on retrieval accuracy as the memory grows.
- The effect of top- scaling with context length (e.g., how should increase with number of chunks for stable accuracy) and the computational/latency trade-offs are not quantified.
- The definition and measurement of “effective context length” in training data is informal; there is no methodology to estimate, curate, or enforce long-range dependencies in corpora, nor an analysis of how much long-context signal is needed to achieve specific extrapolation targets.
- Warm-up strategies (self-copy, full-HSA + short-SWA) are promising but under-specified: optimal durations, schedules (e.g., gradual reduction), data mixtures, and their interaction with later mid-training and annealing are not systematically evaluated.
- Model-size scaling beyond 8B-A1B MoE is not studied for long-context extrapolation; how parameter count interacts with retrieval accuracy, reasoning+retrieval tasks, and the HSA/SWA balance remains unclear.
- Efficiency claims are kernel-bound: HSA only outperforms FlashAttention-3 at very long sequences; there is no CUDA/Hopper-optimized HSA implementation or multi-GPU/sequence-parallel scaling analysis to demonstrate end-to-end throughput at 1M–16M tokens.
- Memory and compute complexity for HSA (e.g., cost of scanning landmarks across chunks, cache bandwidth, and fusion overhead) is not fully profiled; strategies like hierarchical indexing, approximate search, or multi-stage retrieval are not explored.
- No comparison to alternative recurrent/state-space approaches (e.g., Mamba, linear attention) on combined retrieval+reasoning tasks at ultra-long lengths with matched training data and contexts.
- Confounds in baseline comparisons (e.g., different pretraining context windows: HSA-UL at 16K vs TRM-MoE at 4K; differing MoE configurations) are not controlled, making it hard to isolate HSA contributions.
- Limited cross-lingual and domain-specific long-context evaluation (e.g., multilingual long books, codebases, scientific corpora) to test generalization beyond English web and code data.
- Absence of privacy, safety, and alignment analyses for models that can “remember” via large contexts; how to avoid leakage or harmful retrieval from user histories is not addressed.
- No release or reproducible pipeline for the long-context datasets (175B/400B tokens) or tools to construct data with long effective contexts; contamination checks and data-quality controls for probe tasks are not discussed.
- Landmark representation learning is entirely implicit via next-token loss; potential benefits of auxiliary retrieval objectives (e.g., contrastive learning, supervised keys/labels, self-retrieval consistency) are not evaluated.
- Lack of theoretical understanding of why NoPE enables extrapolation in HSA while RoPE degrades it; a principled analysis of positional bias, attention concentration, and gradient flow with chunk-wise attention is missing.
- Inference-time behaviors at ultra-long contexts (e.g., latency per token, batching constraints, memory fragmentation, streaming across sessions, partial recomputation policies) are not characterized.
- No study of robustness over time in growing contexts: how retrieval accuracy changes as the context becomes extremely large (e.g., 16M→64M), and whether there are practical upper bounds or degradation regimes.
Practical Applications
Below is a structured synthesis of practical, real-world applications that follow from the paper’s findings and innovations around Hierarchical Sparse Attention (HSA) and the HSA‑UltraLong architecture. Each item is categorized as either deployable now or requiring further development, and includes sector links and feasibility notes where useful.
Immediate Applications
These can be piloted or deployed today with current HSA‑UltraLong capabilities (e.g., 16M-token effective contexts, MoE 8B with 1B activated parameters, SWA+HSA stack, KV-cache sharing, bi-directional chunk landmark encoder, NoPE for long-range, retrieval-score fusion).
- Enterprise knowledge assistants over massive document corpora
- Sector: software, legal, consulting, insurance
- Use case: QA and summarization across huge policy libraries, contracts, technical reports, eDiscovery collections without heavy external RAG integration.
- Tools/workflow: chunking pipeline (S=64), landmark encoder, HSA top‑k retrieval, shared KV memory; guardrails via SFT datasets; deployment on H800-class GPUs.
- Assumptions/dependencies: availability of long effective-context data; privacy/compliance controls; compute budget.
- Codebase-scale developer assistants for monorepos
- Sector: software/DevTools
- Use case: navigating multi-million-token repositories, cross-file symbol tracking, design history recall, long-range variable tracking (validated by variable-tracking and MQ-NIAH results).
- Tools/workflow: repo ingestion to chunks + landmarks, IDE integration, in-context retrieval for refactoring and bug triage.
- Assumptions/dependencies: robust tokenization of code; efficient chunk summaries for binaries; GPU backends.
- Long-horizon meeting and CRM memory
- Sector: sales, customer support, operations
- Use case: persistent assistant recalling multi-year meeting notes, tickets, and emails; preparing briefs; tracking commitments across sessions.
- Tools/workflow: streaming ingestion → chunking → landmark index; SWA for local turns, HSA for archival recall; strict access policies.
- Assumptions/dependencies: clean, time-ordered logs; data governance and role-based access.
- Scientific literature navigators
- Sector: academia, biotech/pharma R&D
- Use case: cross-paper synthesis over huge citation graphs and decades of publications; targeted retrieval for methods, results, and limitations.
- Tools/workflow: domain-specific tokenization; chunk-level bibliographic landmarks; retrieval probes (RULER/NIAH-style) inserted for quality checks.
- Assumptions/dependencies: ingestion rights; metadata quality (DOIs, topics); GPU capacity for long contexts.
- Regulatory and compliance monitoring
- Sector: finance, energy, telecommunications
- Use case: tracking evolving regulations, internal policies, audit trails across long histories; pinpointing obligations and controls.
- Tools/workflow: compliance corpus → chunk summaries → guided retrieval; policy QA; change-log tracing.
- Assumptions/dependencies: timely updates; legal review; reproducible retrieval logs.
- Log analytics and incident forensics
- Sector: cybersecurity, SRE/AIOps
- Use case: correlating multi-million-token operational logs across prolonged windows; identifying root causes and patterns.
- Tools/workflow: streaming logs chunked into fixed-size segments; landmarks built on semantic + temporal features; HSA top‑k retrieval for cross-episode linkage.
- Assumptions/dependencies: well-structured log schemas; secured pipelines; efficiency gains become notable as sequence length grows.
- Legal case construction and brief drafting
- Sector: legal
- Use case: assembling arguments from prior filings, case law, discovery materials spanning millions of tokens.
- Tools/workflow: case corpus chunking with landmark representations for precedents, facts, exhibits; retrieval-assisted drafting.
- Assumptions/dependencies: confidentiality and privilege handling; jurisdictional filters.
- Multilingual corpora exploration
- Sector: localization, global operations
- Use case: cross-language retrieval (leveraging training mix including multilingual data) over large internal documentation sets.
- Tools/workflow: language-aware chunk summaries; SWA for sentence-level accuracy; HSA for global retrieval; alignment evaluation (e.g., IFEval) for instruction-following.
- Assumptions/dependencies: mixed-language tokenization quality; SFT for multilingual instructions.
- Education: course and cohort memory for tutoring systems
- Sector: education/EdTech
- Use case: tracking student progress, assignments, and feedback across semesters; generating personalized study plans.
- Tools/workflow: LMS ingestion → chunk landmarks (units, outcomes, errors); retrieval in multi-session tutoring.
- Assumptions/dependencies: student consent; bias/feedback mitigation; data security.
- Healthcare: longitudinal clinical note retrieval (pilot, non-diagnostic)
- Sector: healthcare
- Use case: recall across long EHR narratives to aid administrative tasks (summaries, prior history mentions), not clinical decision-making.
- Tools/workflow: HIPAA-compliant ingestion; chunk landmarks on visits/problems; controlled retrieval prompts.
- Assumptions/dependencies: strict privacy/regulatory compliance; clinical validation for any decision support kept out-of-scope initially.
- Memory-augmented RAG alternatives
- Sector: software/AI infrastructure
- Use case: replace or complement external RAG with in-context retrieval via HSA for large, contiguous memory streams.
- Tools/workflow: “memory-as-a-service” layer that maintains chunk KV caches and landmark indices; observability on retrieval scores.
- Assumptions/dependencies: data with long effective contexts; monitoring to avoid the HSA/SWA seesaw (keep short SWA in warmup/pretraining when extending contexts).
- Benchmarking and research tooling for long-context evaluation
- Sector: academia/AI labs
- Use case: deploy RULER/NIAH probes, variable tracking tasks to measure length extrapolation and retrieval accuracy; share datasets and operators.
- Tools/workflow: reproducible pipelines; TileLang HSA kernels; top‑k tuning; Query–Key normalization; NoPE layers.
- Assumptions/dependencies: stable kernels; Hopper-class GPUs (H800) for performance; open-source operator availability.
Long-Term Applications
These require further engineering, scaling, kernel optimization, or policy development (e.g., resolving head-ratio constraints, improving short-context efficiency, mitigating HSA/SWA seesaw, and broad SFT on long effective contexts).
- Lifelong personal AI agents (“machines that can remember”)
- Sector: consumer AI
- Use case: continuously accumulate personal experiences (journals, photos metadata, chats) over years; dynamic in-context learning of preferences and routines.
- Tools/workflow: OS-level memory fabric; privacy-preserving on-device chunk stores; adaptive top‑k retrieval; incremental annealing.
- Assumptions/dependencies: privacy-by-design; efficient on-device kernels; legal/ethical frameworks.
- Clinical decision support over complete patient lifetime records
- Sector: healthcare
- Use case: evidence synthesis across decades of EHR, imaging summaries, genomics notes; supporting clinicians with long-horizon context.
- Tools/workflow: validated clinical chunk landmarks; regulatory-grade audit trails; integration with CDS hooks.
- Assumptions/dependencies: rigorous clinical validation; liability and safety regimes; stronger real-time efficiency.
- Long-horizon robotics and autonomous systems
- Sector: robotics, automotive
- Use case: planning and adaptation with memory of past missions, environment dynamics, and failures; combining retrieval with policy learning.
- Tools/workflow: cross-modal chunking (text + telemetry); HSA-based memory fused with control policies; NoPE for robust extrapolation.
- Assumptions/dependencies: multi-modal HSA; real-time kernels competitive with CUDA for short sequences; safety cases.
- Financial market and risk memory models
- Sector: finance
- Use case: in-context modeling over decades of filings, market events, risk reports; compliance and stress testing with long-range traceability.
- Tools/workflow: domain-tuned landmarks (entities, events); supervisory probes; immutable audit KV.
- Assumptions/dependencies: governance and model risk management; efficient inference at scale; hybrid RAG+HSA for heterogeneous sources.
- National-scale policy archives and legislative assistants
- Sector: public policy/government
- Use case: cross-referencing statutes, amendments, regulatory guidance, comment periods across decades; scenario analysis for new rules.
- Tools/workflow: curated, time-stamped chunk repositories; retrieval score transparency; public audit interfaces.
- Assumptions/dependencies: public records normalization; accountability frameworks; equity and access concerns.
- Knowledge management platforms with “infinite” context
- Sector: enterprise SaaS
- Use case: end-to-end memory OS for organizations—project histories, decisions, design rationales—served through HSA retrieval rather than parameter updates.
- Tools/workflow: memory fabric APIs; landmark indexing services; annealing cycles for quality; context governance policies.
- Assumptions/dependencies: kernel-level optimizations to match FlashAttention-3 for shorter sequences; scalable storage-compute orchestration.
- Streaming analytics and real-time event correlation
- Sector: cybersecurity, IoT, smart cities
- Use case: continuous memory over long streams; anomaly correlation across prolonged periods; trend-aware alerts.
- Tools/workflow: stream chunkers; adaptive top‑k selection; sliding “effective context” management; edge deployment when feasible.
- Assumptions/dependencies: low-latency kernels; energy-efficient inference; robust privacy for citizen data.
- Education: lifelong learner profiles and adaptive curricula
- Sector: education/EdTech
- Use case: persistent, cross-program learner memory; adaptive guidance informed by multi-year performance and feedback.
- Tools/workflow: standardized learning landmarks; growth tracking dashboards; bias and fairness safeguards.
- Assumptions/dependencies: consent models; fairness audits; long-context SFT across diverse curricula.
- Software “design memory” and automated architecture review
- Sector: software
- Use case: capture rationale, ADRs, and evolution for large systems; automated reviews grounded in historical constraints and prior incidents.
- Tools/workflow: semantic landmarking (requirements, ADRs); retrieval-driven reviewers; CI integration.
- Assumptions/dependencies: disciplined documentation practices; integration with build systems; organizational adoption.
- Federated or on-device memory assistants
- Sector: consumer electronics, privacy tech
- Use case: privacy-preserving local long-context recall (emails, notes, browsing); federated aggregation without centralizing raw data.
- Tools/workflow: on-device HSA kernels; encrypted chunk stores; federated annealing.
- Assumptions/dependencies: efficient kernels on edge hardware; secure key management; user controls.
- Cross-modal HSA (text + code + tables + time-series)
- Sector: multi-modal AI, analytics
- Use case: unified retrieval across diverse artifacts—notes, data tables, logs—supporting richer reasoning.
- Tools/workflow: modality-specific landmark encoders; unified retrieval fusion; evaluation suites beyond text-only RULER.
- Assumptions/dependencies: encoder design; calibration across modalities; mixed-tokenization stability.
- Industry-wide standards for long-context AI memory
- Sector: policy, standards bodies
- Use case: common protocols for memory privacy, auditability, and retrieval transparency; certification for “memory-safe” assistants.
- Tools/workflow: retrieval logging specs; bias and safety benchmarks; lifecycle governance policies.
- Assumptions/dependencies: multi-stakeholder collaboration; legal harmonization; public trust.
Notes on feasibility constraints highlighted by the paper:
- HSA/SWA seesaw: excessive SWA windows can degrade long-range extrapolation; training regimens must protect HSA learning signal (warmup with short SWA + full HSA; mid-training on long effective contexts).
- Head-ratio constraint: current need for 16:1 query-to-KV heads creates an information bottleneck; kernel-level advances are required.
- Efficiency: HSA kernels (TileLang) trail FlashAttention-3 for short sequences; long-context gains appear only at large sequence lengths; CUDA-grade implementations would help.
- Data: strong extrapolation depends on training with corpora having genuinely long effective contexts (not just long token windows).
- Compliance: applications touching sensitive data (healthcare, finance, personal memories) need robust privacy, auditability, and alignment (e.g., instruction-following, role-based access).
- Cost: trillion-token training and H800-class inference imply nontrivial compute budgets; productization should include memory tiering and context budgeting.
Glossary
- Annealing: A later training stage used to refine or stabilize a model, often on higher-quality data or with a decaying learning rate. "Annealing. Perform annealing on high-quality data while keeping a 32K context length."
- Attention field scaling: Scaling experiments focused on how far attention can effectively reach or operate, beyond just model/data size. "lacks results on data scaling, parameter scaling, and attention field scaling."
- BabiLong: A benchmark designed to test long-context reasoning abilities of LLMs. "more than 10M context length while keeping high accuracy on the RULER and BabiLong benchmark"
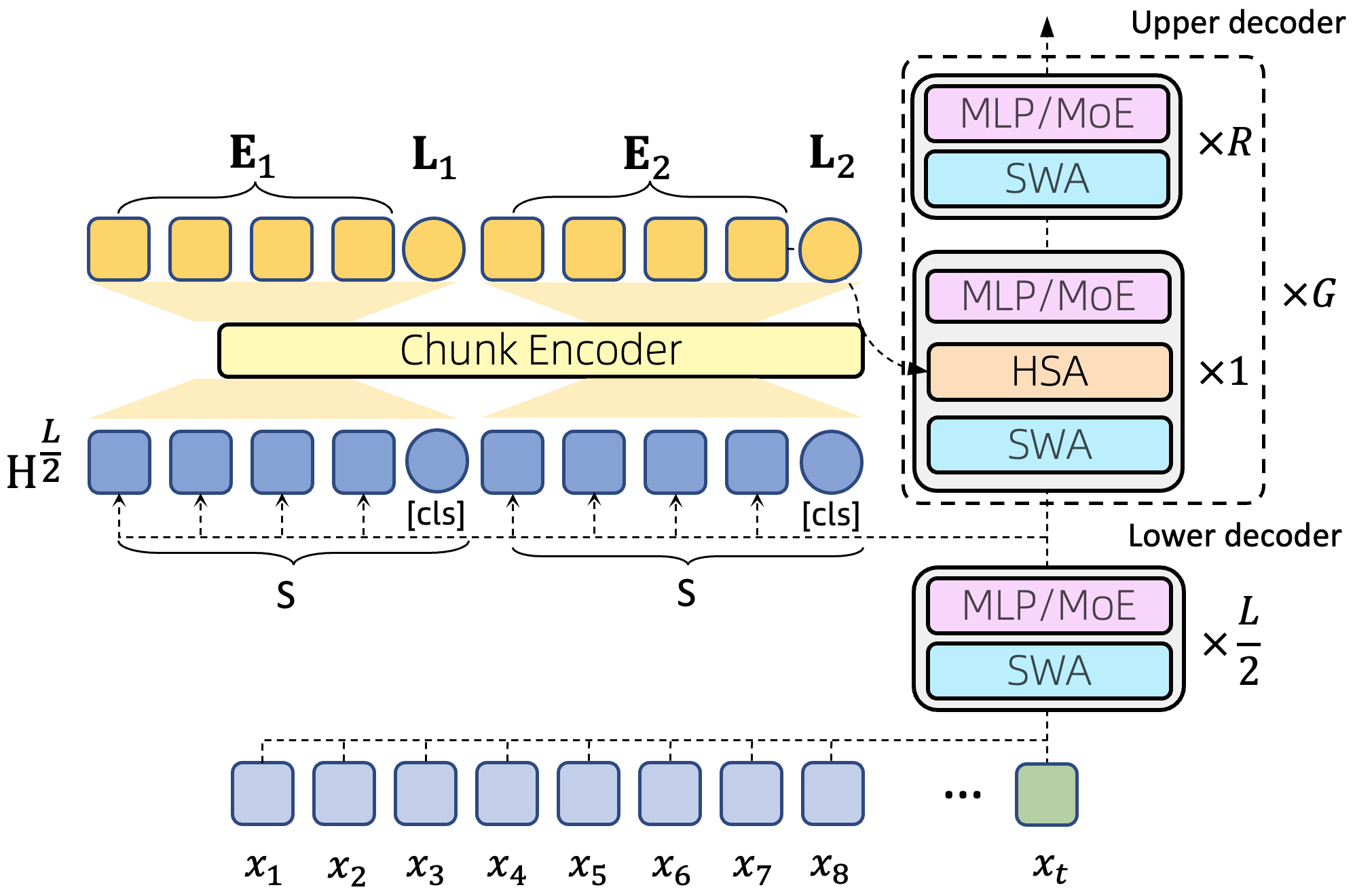
- Bi-directional encoder: An encoder that processes tokens in both forward and backward directions to produce richer representations (e.g., for chunk summaries). "For each chunk, we use a bi-directional encoder to obtain its summary representation."
- Chunk-wise sparse attention: An attention strategy that partitions sequences into chunks and performs attention only within a small set of retrieved chunks. "chunk-wise sparse attention, such as Hierarchical Sparse Attention (HSA)"
- Effective context length: The actual span of meaningful dependencies present in training data, which can be much shorter than the nominal context window. "The effective context length in the training corpus strongly influences length extrapolation."
- FlashAttention-3: A high-performance attention kernel/library optimized for fast and memory-efficient attention computation. "FlashAttention-3"
- FSDP2: A distributed training scheme (Fully Sharded Data Parallel v2) that shards model states to scale training efficiently. "We use FSDP2 for distributed training."
- Hierarchical Sparse Attention (HSA): An attention mechanism that retrieves top-k relevant chunks via landmark vectors, attends within each chunk, and fuses outputs by learned retrieval scores. "Hierarchical Sparse Attention (HSA), a novel attention mechanism that satisfies all three properties."
- KV cache: Cached key and value tensors used to avoid recomputing attention context during autoregressive decoding or long-sequence processing. "the KV cache grows with the sequence length."
- KV cache sharing: Reusing a common KV cache across modules or layers to reduce memory usage while maintaining performance. "we share the intermediate layer KV cache among all HSA modules"
- Landmark representations: Per-chunk summary vectors used to score and retrieve relevant chunks for attention. "with landmark representations; each token retrieves top-k relevant past chunks via these landmarks."
- Length generalization: The ability of a model trained on shorter contexts to maintain performance when evaluated on much longer contexts. "Effective length generalization requires the combination of chunk-wise attention, retrieval score–based fusion, and NoPE (No Positional Encoding);"
- Length extrapolation: Evaluating or achieving performance at context lengths far beyond those seen during training. "balance in-domain performance with length extrapolation capabilities"
- Load balancing strategy (MoE): Techniques to distribute tokens evenly across experts in Mixture-of-Experts layers without additional auxiliary losses. "We use training-free balance strategy as the expert balancing strategy."
- Mixture-of-Experts (MoE): An architecture that routes tokens to a subset of multiple specialized expert networks and fuses their outputs. "The overall process closely resembles the Mixture-of-Experts (MoE)"
- Needle-in-a-Haystack (NIAH): A probe task for long-context retrieval where the model must find and use a small “needle” of information buried in a very long context. "appending the Needle-in-a-Haystack (NIAH) prompt and answer at the end of the sample"
- NoPE (No Positional Encoding): A configuration that removes positional encoding from certain components to improve length extrapolation. "No Positional Encoding (NoPE) supports extrapolation better than RoPE"
- Query–Key Normalization: A normalization technique applied to query and key vectors to stabilize attention, especially in long-context or sparse settings. "$\Norm$ is the Query-Key Normalization"
- Query–Key/Value head ratio: A constraint on the number of query heads relative to key–value heads that can create information bottlenecks in sparse attention kernels. "requires a 16:1 ratio of query heads to keyâvalue heads"
- Random-Access Flexibility: A property of a model that enables efficient retrieval of arbitrary, distant information on demand. "Random-Access Flexibility:"
- Retrieval scores: Learned relevance scores (e.g., via dot products with landmarks) that rank chunks and weight their attention outputs. "weighted by the softmax-normalized retrieval scores"
- RoPE: Rotary Positional Embeddings, a positional encoding method that rotates query/key vectors to encode relative positions. "No Positional Encoding (NoPE) supports extrapolation better than RoPE"
- RULER: An evaluation suite probing the true effective context size and long-context capabilities of models. "The results for RULER tasks are reported in Figure~\ref{fig:ruler_eval_line}"
- Router (MoE): The gating module in MoE that selects which experts a token should be routed to. "similar to how MoE uses a router to select top- experts."
- Seesaw effect (HSA vs SWA): A trade-off where strengthening sliding-window attention can weaken HSA’s learned retrieval and long-range generalization. "A seesaw effect exists between HSA and Sliding Window Attention."
- Sliding window attention (SWA): Local attention limited to a fixed-size window around each token, used for efficient short-range modeling. "We use a short sliding window attention (SWA) of 512 tokens"
- TileLang: A tiled-programming framework used to implement high-performance kernels (e.g., for HSA). "with HSA implemented using TileLang"
- Top-k selection: Selecting the k highest-scoring items (e.g., chunks or experts) for sparse computation. "the top- chunks are selected"
- Variable Tracking Task: A long-context benchmark task requiring models to track and use variable assignments across long sequences. "Variable Tracking Task."
Collections
Sign up for free to add this paper to one or more collections.

