- The paper introduces InfiniteHiP, a framework that extends language model context up to 3 million tokens using hierarchical token pruning and paged block sparse attention.
- It achieves an 18.95x speedup in attention decoding and optimizes GPU memory by offloading key-value caches during inference.
- Empirical results demonstrate superior scalability and efficiency compared to baselines like FA2 and StreamingLLM, ensuring robust out-of-length generalization.
InfiniteHiP: Extending LLM Context Up to 3 Million Tokens on a Single GPU
Introduction
The constraints of extending context length in modern LLMs have posed significant challenges owing to increased memory costs and slower inference speeds. Existing pre-trained LLMs often fail to generalize beyond their training sequence lengths, necessitating new strategies to utilize longer contexts practically and efficiently. The paper "InfiniteHiP: Extending LLM Context Up to 3 Million Tokens on a Single GPU" introduces InfiniteHiP, an innovative LLM inference framework designed to overcome these challenges. By employing a modular hierarchical token pruning algorithm and optimizing RoPE adjustments, InfiniteHiP facilitates processing up to 3 million tokens on a single GPU without permanent context loss.
Methodology
InfiniteHiP leverages a combination of advanced techniques to achieve its objectives:
- Modular Hierarchical Token Pruning: This component dynamically prunes irrelevant context tokens, significantly reducing computational overhead. The pruning stages progressively refine the candidate key indices, which enhances efficiency during attention tasks.
- Paged Block Sparse Attention: The use of paged block sparse attention allows InfiniteHiP to perform attention calculations efficiently, selectively focusing on relevant tokens. This method optimizes both memory and computational resources.
- Offloading and GPU Memory Management: By offloading the key-value cache to host memory during inference, InfiniteHiP alleviates GPU memory pressure. This innovation is crucial for managing the extended context lengths without degradation in performance.
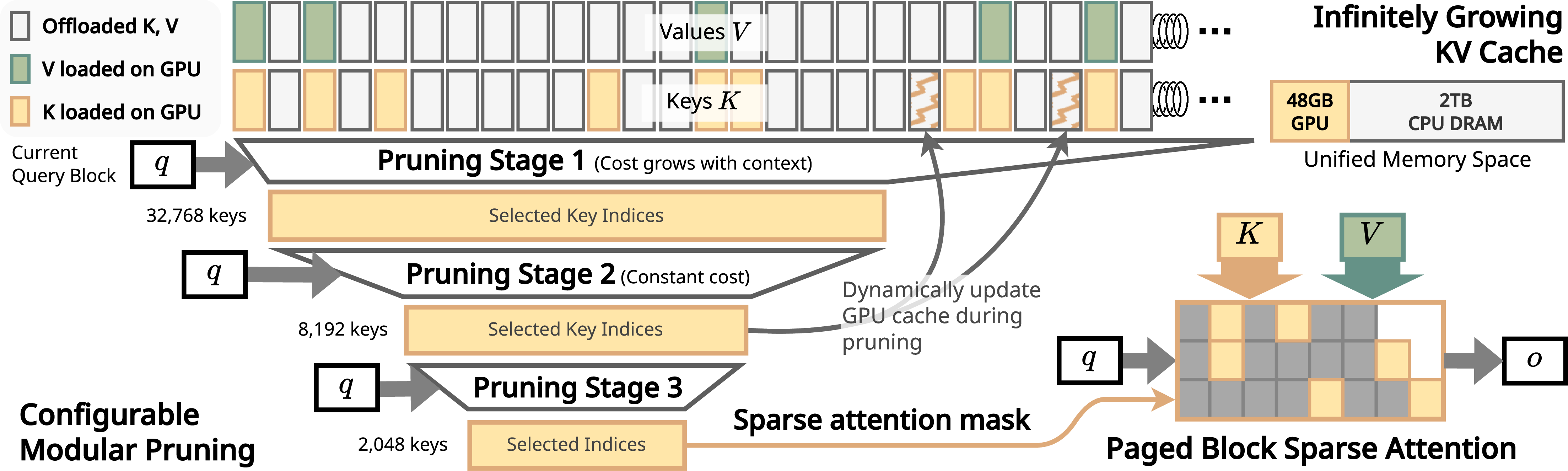
Figure 1: Overview of InfiniteHiP. This figure highlights the infinitely growing key-value cache, modular pruning, and paged block sparse attention mechanisms.
Empirical Evaluation
The empirical results demonstrate the practicality and effectiveness of InfiniteHiP:
- Speed and Efficiency: InfiniteHiP provides an 18.95x speedup in attention decoding for contexts containing 1 million tokens without additional training requirements. This performance is achieved by leveraging its innovative attention mechanisms and memory management strategies.
- Generality and Scalability: The framework supports out-of-length (OOL) generalization by applying various RoPE adjustment strategies in line with the attention patterns inherent to specific LLM components. This flexibility is pivotal in maintaining performance across longer contexts.
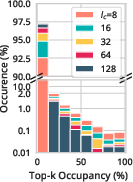
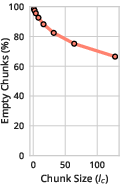
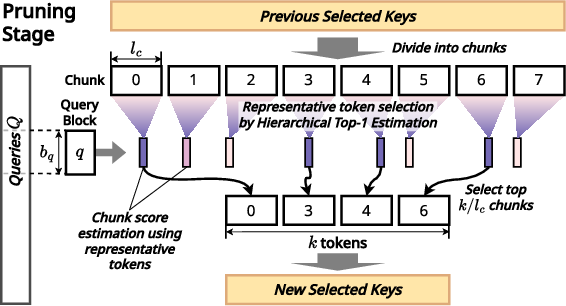
Figure 2: Chunk sparsity analysis relevant to attention score distribution in a 128K context.
Comparison with Baselines
InfiniteHiP was evaluated against prominent methods such as FA2, InfLLM, and StreamingLLM across multiple benchmarks like LongBench and ∞Bench. The results highlight:
- Superior Performance: InfiniteHiP achieves significantly higher average relative scores, particularly in contexts exceeding 100K tokens, showcasing its enhanced capability to handle extensive input lengths.
- Resource Optimization: In benchmarks, InfiniteHiP utilized a fraction of the GPU memory compared to FA2, demonstrating its efficient memory management through dynamic cache offloading and sparse attention techniques.
Discussion
InfiniteHiP addresses crucial challenges in deploying LLMs for long-context tasks without necessitating retraining or extended fine-tuning, a common requirement in other methods. The hierarchical pruning facilitates faster and contextually-aware attention without degrading the LLM's comprehensive understanding capabilities.
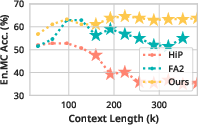
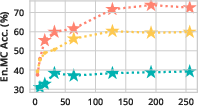
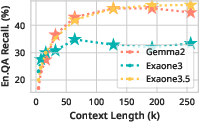
Figure 3: Performance comparison of InfiniteHiP against other methods, highlighting its superior handling of extensive contexts on Llama 3 and Mistral models.
Conclusion
InfiniteHiP emerges as a robust framework for extending LLM context length efficiently on a single GPU. Its innovative approach integrates modular pruning and attention adjustment strategies to enhance both speed and memory efficiency. As AI applications increasingly demand the processing of longer contexts, frameworks like InfiniteHiP will be essential in driving these advancements, reducing resource overhead, and maintaining high performance in real-world scenarios. Future research could explore further optimizations, potentially integrating more adaptive pruning strategies and additional memory management enhancements to push the limits of context length handling even further.