Vision Bridge Transformer at Scale
Abstract: We introduce Vision Bridge Transformer (ViBT), a large-scale instantiation of Brownian Bridge Models designed for conditional generation. Unlike traditional diffusion models that transform noise into data, Bridge Models directly model the trajectory between inputs and outputs, creating an efficient data-to-data translation paradigm. By scaling these models to 20B and 1.3B parameters, we demonstrate their effectiveness for image and video translation tasks. To support this scale, we adopt a Transformer architecture and propose a variance-stabilized velocity-matching objective for robust training. Together, these advances highlight the power of scaling Bridge Models for instruction-based image editing and complex video translation.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A plain‑English guide to “Vision Bridge Transformer at Scale”
What is this paper about?
This paper presents a new way for computers to change pictures and videos based on instructions. Instead of starting from pure random noise (like many popular AI image tools do), the model starts from the original image or video and learns the most direct path to the desired result. The authors call their approach the Vision Bridge Transformer (ViBT), and they show it works well even when the model is very large.
What questions are the researchers trying to answer?
The paper focuses on three simple questions:
- For tasks like image editing or video stylization, is it better to go directly from the input to the output instead of starting from random noise?
- Can this “bridge” idea still work when we scale it up to very big Transformer models (with billions of parameters)?
- How do we train and run such models stably and efficiently so they don’t become slow or unstable?
How does their method work?
Think of transforming an image like traveling from City A (the original image) to City B (the edited image). Traditional methods start in the wilderness (random noise) and slowly find their way to City B. ViBT instead takes a bridge directly from A to B, with a bit of controlled randomness to keep things flexible. Here’s the idea in everyday terms:
- The “bridge” idea:
- The model learns the whole journey from the input (source) directly to the output (target). This is called a “Brownian Bridge,” which you can picture as a path that starts at the input, ends at the output, and allows a little wiggle (noise) in the middle so it can learn rich variations.
- A Transformer at the core:
- ViBT uses a Transformer (the same general kind of model behind many AI breakthroughs) because it scales well and captures complex details. They start from strong existing models (for images and videos) and adapt them to the bridge idea.
- Working in a compact space:
- Images and videos are first compressed into “latent space” with a VAE (a kind of smart compressor). The model learns the transformation there, which is lighter and faster than working with full‑size pixels.
- Training without instability:
- During training, the model looks at a mixed state between the input and the output (a point along the bridge) and learns the best direction to move next.
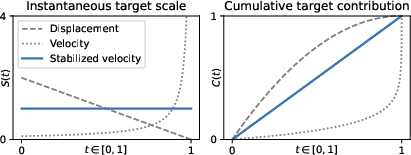
- A simple version of this can become unstable near the end of the journey (close to the target), where the math “blows up.” To fix this, the authors design a “stabilized velocity matching” trick. Think of it like using cruise control and a safe speed limit so the model doesn’t overreact near the finish line.
- This stabilization balances learning across the whole journey, not just at the beginning or the end.
- Smarter sampling at inference time:
- When generating results, the model takes several steps from input to output. Early on, it allows more randomness; close to the end, it reduces randomness. This “variance correction” is like taking careful, smaller steps as you approach your destination, avoiding shaky results.
- A simple dial for noise:
- They test a “noise scale” knob (how wiggly the bridge is overall). Different tasks prefer different settings, but too little or too much noise hurts quality.
What did they find, and why is it important?
The authors test ViBT on several practical tasks:
- Instruction‑based image editing (e.g., “make the sky pink,” “add a hat to the dog”)
- Instruction‑guided video stylization (e.g., “make this video look like a Van Gogh painting”)
- Video translation tasks, like turning depth maps into videos, colorizing videos, or smoothing motion by adding in‑between frames
Key results:
- Quality: ViBT matches or beats strong diffusion‑based baselines on many metrics. It often produces detailed, faithful edits and stable videos that follow the instructions well.
- Efficiency: Because it goes directly from input to output and doesn’t need lots of extra “conditioning tokens,” ViBT can be faster, especially for videos.
- Stability: The stabilized training objective makes learning reliable, even with very large models (up to 20 billion parameters).
- Flexibility: It works across a range of tasks, not just one specific problem.
- Ablations (tests of choices inside the method): The new stabilized objective consistently performs best. The noise scale matters and should be chosen per task. The variance‑corrected sampling step improves visual quality near the end of generation.
Why this matters:
- Many real editing tasks already start with something close to the final result (an input image or video). Building a direct bridge is more natural than starting from pure noise. This can mean better faithfulness to the input, fewer artifacts, and more speed—useful for real creative tools, video editing, or content personalization.
What could this change in the future?
- More natural editing tools: Apps could edit images and videos more accurately and quickly, keeping important details (like faces or motion) intact.
- Better video workflows: Stylizing or translating videos (e.g., depth‑to‑video) could become faster and more consistent, potentially enabling near real‑time tools.
- Easier scaling: The paper shows that “bridge” models are not just ideas that work on small problems—they can be scaled up to the largest models people use today.
- Smarter training and sampling: The stabilization and variance‑correction tricks are broadly useful techniques that others can adopt.
The authors do note one limitation: picking the best noise scale depends on the task. A next step is to make the model adapt this automatically, so it can “tune itself” for each job without manual tweaking.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues, missing analyses, and open questions that future work could address to strengthen and extend the paper’s contributions.
- Inference conditioning ambiguity: The paper’s inference algorithm takes a source–target pair , but in real conditional generation the target is unknown at test time. Clarify and validate the actual inference procedure that consumes only the source input (and any instruction/conditioning), including how text or other conditions are fed into ViBT during sampling.
- Instruction integration details: The mechanism for incorporating textual instructions (tokenization, encoder choice, attention pathways, and any architectural changes relative to the base DiT models) is not specified. Provide an explicit description and ablation of text-conditioning routes in ViBT, and quantify any token/latency overhead they introduce.
- Theoretical guarantees of stabilized velocity matching: The normalization factor is proposed empirically. Establish whether the stabilized objective yields an unbiased estimator of the true drift, preserves the correct endpoint marginal, and ensures convergence. Formalize error bounds and training stability guarantees.
- Normalization sensitivity to endpoint proximity: Because , pairs with small induce very large normalization, potentially down-weighting subtle edits. Quantify the impact on fine-grained edits and explore robust variants (e.g., clipping, per-dimension scaling, batch normalization alternatives).
- Adaptive or learnable diffusion schedule: The study varies a global noise scale but does not explore time-dependent , data-dependent , or learning jointly with . Investigate per-task or per-sample adaptive schedules, and whether learning improves stability and quality.
- Teacher trajectory optimality: Brownian Bridge is assumed as the teacher path. Assess whether non-linear or time-warped teachers (e.g., geodesics in latent space, entropic OT, Schrödinger bridges with learned potentials) yield better conditioning fidelity, temporal coherence, or sample efficiency.
- Variance-corrected sampling evaluation: The variance correction factor is justified qualitatively. Provide quantitative improvements (e.g., FVD, LPIPS, SSIM, error vs. step size curves) and compare against stronger discretizations (Milstein, predictor–corrector, high-order solvers).
- Dataset authenticity and bias: Most training and evaluation pairs are generated by large models (Qwen, Wan). Measure generalization on human-annotated or real-world datasets, and analyze bias/data contamination risks arising from training and evaluating on distributions produced by related base models.
- End-to-end efficiency accounting: Efficiency comparisons report per-forward-pass latency but not full sampling time (multiple steps), memory footprint, or energy utilization across matched quality. Provide end-to-end throughput vs. quality trade-offs and scaling curves versus strong DiT baselines.
- Long video and high-resolution scalability: Current evaluations focus on short clips and limited resolutions. Characterize performance, stability, and resource requirements on longer sequences (>30–60 s) and higher resolutions (≥4K), including attention memory scaling and failure modes.
- Multi-condition and multimodal control: ViBT is shown on image editing, video stylization, and depth-to-video. Examine combined conditions (e.g., text + pose + depth + segmentation), conflicts among modalities, and how ViBT handles multi-source constraints without reverting to token-heavy conditioning.
- Robustness to large structural changes: Brownian Bridge assumes a “short path” between source and target. Evaluate cases with large semantic/structural differences (object replacement, scene rearrangement) and measure failure modes and edit boundary artifacts.
- VAE latent dependence: All bridging occurs in a pre-trained VAE latent. Analyze how choice of VAE (architecture, compression rate, latent dimensionality ) affects , training stability, and downstream quality. Compare latent-space vs. pixel-space bridging.
- LoRA vs. full fine-tuning effects: The 20B image model is trained via LoRA (rank 128); the 1.3B video model via full updates. Quantify differences in stability, overfitting, and sample efficiency; explore rank sensitivity and mixed-partial training schemes.
- Missing comparisons with scaled Bridge baselines: There is no head-to-head comparison against state-of-the-art bridge variants (e.g., DDBM, EBDM, LBM) at similar scale and compute. Add apples-to-apples baselines to isolate the impact of the proposed objective and sampling method.
- Conditional distribution formalization: Provide a formal statement and empirical validation that the learned SDE realizes the desired conditional under the proposed loss and sampling dynamics, including endpoint consistency and identifiability conditions.
- Timestep sampling strategy: Training samples ; only qualitative scheduler discussion appears in the supplement. Systematically study non-uniform sampling (e.g., Beta distributions, curriculum schedules) and their effect on stability and quality.
- Evaluation metrics breadth: Key video metrics (e.g., FVD, KVD), perceptual divergences (LPIPS), and human evaluations are absent. Augment with human studies and stronger reference-free/reference-based metrics to better capture temporal coherence and instruction adherence.
- Inference steps and schedules: Provide quantitative ablations across tasks for step counts and different schedules (including the SD3 shift parameter ), and derive principled criteria for selecting and under compute constraints.
- Identity and content preservation: Beyond CLIPScore and VBench, measure identity consistency (e.g., face ID metrics) and scene content retention, especially in instruction-based edits and stylization.
- Safety and ethical considerations: No analysis of content safety, bias amplification, or misuse risks. Develop safeguards and auditing protocols, especially given model scaling and ease of conditional manipulation.
- Reproducibility and release: Clarify whether code, models, and synthetic datasets will be released with licenses and exact generation recipes. Provide seeds, checkpoints, and standardized benchmarks to enable faithful reproduction.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging ViBT’s scaled Brownian Bridge modeling, stabilized velocity matching, and variance-corrected sampling to deliver efficient, high-quality vision-to-vision translation.
- Instruction-based image editing for creative production
- Sectors: media/entertainment, advertising, e-commerce, social media
- What it does: Apply text-guided edits to images (add/replace/remove objects, style transfer) while preserving scene structure and details, with competitive quality and lower latency relative to conditional DiT baselines.
- Tools/products/workflows: ViBT-powered editing plugin/API for Photoshop/Figma; batch content pipelines for campaign assets; LoRA-based “brand style” packs; prompt templates tied to ImgEdit-Bench categories.
- Assumptions/dependencies: Access to pre-trained VAE + transformer backbones (e.g., Qwen-Image-Editing 20B), instruction-image pairs, GPU inference; licensing for base models; content rights and compliance.
- Instruction-guided video stylization that preserves motion and structure
- Sectors: film/TV post-production, influencer/creator tooling, AR filters
- What it does: Map input videos to target styles via text prompts without disrupting motion coherence, achieving superior perceptual and semantic alignment metrics.
- Tools/products/workflows: After Effects/Premiere plugin; cloud batch stylization service; “style prompt libraries” with LoRA adapters; pipeline: base video generation (e.g., Wan) → ViBT stylization.
- Assumptions/dependencies: Style-paired datasets (Ditto-1M or in-house), access to Wan 2.1-like backbones (1.3B), GPU clusters for throughput; brand/IP approvals for styles.
- Depth-to-video synthesis for prototyping scenes and digital twins
- Sectors: AR/VR, robotics simulation, industrial digital twins, product visualization
- What it does: Convert monocular or sensor-derived depth sequences into high-fidelity videos; maintain structure and condition-following behavior with strong VBench performance.
- Tools/products/workflows: “Depth2Video” API; phone/LiDAR capture → Depth Anything V2 → ViBT; toolchains for AR storyboard previews or robotics scene replay.
- Assumptions/dependencies: Depth quality and coverage; pairing depth/video domains for fine-tuning; robustness to real-world domain shift; rights for source footage.
- Video colorization for archives and creative reuse
- Sectors: media restoration, education, news archives
- What it does: Transform grayscale videos to color while preserving temporal coherence, ready for restoration workflows or content modernization.
- Tools/products/workflows: Archive batch colorization pipeline; curator-in-the-loop quality control; ViBT inference with variance-corrected scheduler to minimize artifacts.
- Assumptions/dependencies: Domain diversity in training; curator QA; licensed use of archival materials; acceptance of generative colorization as interpretative.
- Temporal upscaling and frame interpolation (e.g., 15 FPS → 60 FPS)
- Sectors: streaming platforms, sports/media highlights, game capture processing
- What it does: Produce smooth, temporally coherent intermediate frames; demonstrates high quality with few inference steps (e.g., 4 steps).
- Tools/products/workflows: “ViBT-Up” frame interpolation microservice; post-processing pipeline: coarse duplication → ViBT refinement; scheduler presets for motion-heavy content.
- Assumptions/dependencies: Reliable motion estimation in diverse scenes; capacity planning for batch processing; device playback constraints.
- Faster conditional generation inside transformer stacks
- Sectors: cloud ML platforms, generative AI infrastructure
- What it does: Replace token-heavy conditional DiT variants with ViBT to reduce attention overhead and latency (≈2.3× speedup for images, up to ≈4× for videos in reported settings).
- Tools/products/workflows: Drop-in “Bridge layer” for existing DiT pipelines; variance-corrected sampling scheduler; auto-selection of timestep schedules (shifted schedules).
- Assumptions/dependencies: Compatibility with existing VAEs/backbones; evaluation and rollout guardrails; performance monitoring.
- Data augmentation for supervised CV training
- Sectors: computer vision R&D, synthetic data companies
- What it does: Generate label-preserving edited/stylized variants (background swaps, object additions) to improve robustness of downstream models.
- Tools/products/workflows: Augmentation SDK with “Edit classes” aligned to ImgEdit-Bench; QA filters using CLIPScore/SSIM; audit trails for provenance.
- Assumptions/dependencies: Label consistency checks; potential human-in-the-loop validation; legal clarity for augmented datasets.
- Ready-to-use creative tool integrations
- Sectors: design software, creator platforms
- What it does: Turn ViBT into an editor plugin/toolkit (e.g., “BridgeSDK”) featuring text-guided styling, colorization, and targeted edits.
- Tools/products/workflows: Adobe/Resolve plugins; web UI for promptable batch transformations; LoRA adapter libraries for brand or theme consistency.
- Assumptions/dependencies: SDK maintenance; UI/UX safety rails; licensing and distribution policies.
- On-device video editing with the 1.3B model (edge)
- Sectors: mobile, XR devices
- What it does: Run stylization/colorization/interpolation locally via quantization/distillation of the 1.3B backbone, with efficient bridge sampling.
- Tools/products/workflows: Low-precision inference packages; task-specific LoRA adapters; hardware-accelerated kernels for variance-corrected noise.
- Assumptions/dependencies: Memory/compute constraints; device GPU/NPU capabilities; privacy requirements; battery impact.
Long-Term Applications
The following applications benefit from ViBT’s paradigm but require further research, scaling, domain adaptation, or policy alignment before widespread deployment.
- Real-time interactive editing and live stylization for streaming
- Sectors: live media, gaming, virtual events
- What it could do: Apply ViBT transformations on live video feeds with sub-100 ms latency, enabling interactive style toggles and instruction-driven edits.
- Potential tools/products/workflows: “LiveBridge” with hardware acceleration; adaptive timesteps; streaming-specific schedulers.
- Assumptions/dependencies: Model compression; specialized accelerators; robust latency/jitter management.
- Robotics/autonomous driving simulation from structured conditions (depth/segmentation/pose → video)
- Sectors: autonomy, robotics, smart cities
- What it could do: Generate realistic scene videos from sensor abstractions to augment training and test rare scenarios with temporal consistency.
- Potential tools/products/workflows: Synthetic scenario generators; curriculum datasets; safety validation suites.
- Assumptions/dependencies: Domain fidelity and generalization; rigorous safety evaluation; access to high-quality paired data.
- Medical imaging simulation and augmentation (structure-to-appearance)
- Sectors: healthcare, medical education
- What it could do: Map structural inputs (e.g., segmentation maps) to realistic imagery for training radiologists or testing algorithms.
- Potential tools/products/workflows: “MedBridge” simulators; tightly controlled datasets; clinician-in-the-loop QA.
- Assumptions/dependencies: Strict regulatory approval; clinical validation; bias and risk management; clear non-diagnostic labelling.
- Adaptive noise-scale controllers and auto-tuning frameworks
- Sectors: ML tooling, MLOps
- What it could do: Automatically select noise scale s per task/media to optimize quality and stability, reflecting paper’s task-dependent findings.
- Potential tools/products/workflows: “AutoBridge Tuner”; Bayesian/learning-to-optimize controllers; task-aware schedulers.
- Assumptions/dependencies: Robust meta-optimization; comprehensive benchmarking; generalization across domains.
- Cross-modal bridge transformers (audio-to-audio, text-to-video via vision-to-vision intermediates)
- Sectors: multimodal media, accessibility
- What it could do: Extend bridge modeling principles beyond vision to enable structure-preserving transformations across modalities.
- Potential tools/products/workflows: Multimodal encoders/VAEs; paired cross-modal datasets; unified bridge training objectives.
- Assumptions/dependencies: New encoders and datasets; careful evaluation of temporal/semantic alignment; increased engineering complexity.
- Provenance, watermarking, and policy-compliant content disclosure
- Sectors: platforms, governance, digital rights
- What it could do: Embed provenance signals during bridge trajectories and standardize disclosures for edited/stylized content.
- Potential tools/products/workflows: “BridgeMarks” watermarking; audit trails; policy templates aligned with platform guidelines.
- Assumptions/dependencies: Watermark robustness research; platform adoption; legal harmonization across jurisdictions.
- Low-energy generative infrastructure using bridge models
- Sectors: cloud providers, sustainability initiatives
- What it could do: Standardize ViBT-like conditional generation for reduced token overhead and energy per inference across large fleets.
- Potential tools/products/workflows: Energy-aware schedulers; fleet-level A/B measurements; sustainability reporting.
- Assumptions/dependencies: Verified energy savings at scale; integration with diverse workloads; organizational buy-in.
- Multicondition AR authoring (depth + pose + segmentation → coherent video)
- Sectors: AR authoring, interactive experiences
- What it could do: Combine multiple structured inputs into coherent, stylized videos for rapid prototyping and experience design.
- Potential tools/products/workflows: “AR Bridge Studio”; compositional condition encoders; interactive prompt + control UIs.
- Assumptions/dependencies: Multi-condition training stability; UI safety; high-quality compositional datasets.
- Personalized avatar and digital persona production
- Sectors: social platforms, virtual offices, education
- What it could do: Generate consistent, stylized video personas from user recordings, with instruction-based scene edits and style preservation.
- Potential tools/products/workflows: Persona creation wizard; privacy-preserving local adapters; content approval workflows.
- Assumptions/dependencies: Consent and privacy safeguards; bias/fairness considerations; secure model adaptation.
- Academic extensions in probability-path modeling and bridge objectives
- Sectors: academia, research labs
- What it could do: Use stabilized velocity matching and variance-corrected sampling as baselines for new bridge formulations, cross-task generalization studies, and theory development.
- Potential tools/products/workflows: Open benchmarks for conditional generation; ablation libraries; reproducible training scripts.
- Assumptions/dependencies: Open model and data availability; funding for large-scale experiments; community consensus on metrics.
Common assumptions and dependencies across applications
- High-quality paired source-target data and task-specific fine-tuning are critical for optimal performance and generalization.
- Access to strong pre-trained backbones (VAE + transformer) and proper licensing (e.g., Qwen-Image-Editing, Wan) is required.
- Operational efficiency depends on variance-corrected sampling, appropriate timestep schedules, and tuning noise scale s per task.
- Deployment feasibility varies with compute budgets; edge scenarios require quantization/distillation and hardware acceleration.
- Legal/ethical considerations (rights, consent, provenance) are essential when editing or stylizing real-world content.
Glossary
- Boundary conditions: Constraints specifying the distributions at the start and end of a stochastic process. Example: "with boundary conditions and "
- Bridge Models: Generative models that directly connect source and target distributions via a stochastic process. Example: "Bridge Models directly model the trajectory between inputs and outputs, creating an efficient data-to-data translation paradigm."
- Brownian Bridge: A stochastic process conditioned to start and end at specified points, with variance peaking mid-trajectory. Example: "the standard Brownian Bridge~\cite{albergo2023stochastic, li2023bbdm} incorporates stochasticity via a constant diffusion coefficient ."
- CLIPIQA: A no-reference image quality assessment metric leveraging CLIP features. Example: "including NIQE~\cite{mittal2012making}, TOPIQ-NR~\cite{chen2024topiq}, MUSIQ~\cite{ke2021musiq}, MANIQA~\cite{yang2022maniqa}, CLIPIQA~\cite{wang2023exploring}, and CLIPScore~\cite{hessel2021clipscore}."
- CLIPScore: A metric measuring text–image alignment using CLIP embeddings. Example: "including NIQE~\cite{mittal2012making}, TOPIQ-NR~\cite{chen2024topiq}, MUSIQ~\cite{ke2021musiq}, MANIQA~\cite{yang2022maniqa}, CLIPIQA~\cite{wang2023exploring}, and CLIPScore~\cite{hessel2021clipscore}."
- Conditioning tokens: Additional tokens injected into Transformer attention to encode conditioning information. Example: "incorporating additional conditioning tokens introduces substantial computational overhead under transformer architectures~\cite{tan2025ominicontrol, tan2025ominicontrol2}, especially in video settings~\cite{wan2025wan, aigc_apps_videox_fun_2025, jiang2025vace}."
- Cross-attention mechanisms: Attention layers that condition generation on external inputs (e.g., text, image features). Example: "Conditional diffusion models incorporate auxiliary signals such as text, images, poses, or depth maps through additional encoders, auxiliary branches, or cross-attention mechanisms."
- Denoising Diffusion Bridge Models (DDBM): Diffusion-based bridges designed for conditional generation between distributions. Example: "Recent diffusion-based variants, such as Denoising Diffusion Bridge Models (DDBM)~\cite{Zhou2023DenoisingDB} and Brownian Bridge methods~\cite{li2023bbdm}, demonstrated promising results for conditional generation and image translation tasks."
- DISTS: A full-reference perceptual similarity metric based on deep feature statistics. Example: "We then augmented this analysis by introducing reference-based metrics including SSIM~\cite{wang2004image}, PSNR~\cite{pyiqa}, and DISTS~\cite{ding2020image}, to quantitatively measure similarity between generated outputs and ground-truth videos."
- Diffusion coefficient: The time-dependent scalar that scales the noise term in an SDE. Example: "diffusion coefficient ,"
- Diffusion Transformers (DiT): Transformer architectures adapted for diffusion-based generative modeling. Example: "With the emergence of Diffusion Transformers (DiT)~\cite{peebles2023scalable}, recent approaches~\cite{tan2025ominicontrol, labs2025flux, wu2025qwen} incorporate conditions directly into transformer attention layers for stronger guidance."
- Entropic optimal transport: Regularized optimal transport formulation enabling efficient probabilistic coupling. Example: "and entropic optimal transport~\cite{cuturi2013sinkhorn}."
- Euler-Maruyama discretization: A numerical scheme for simulating SDEs by discretizing time and approximating stochastic integrals. Example: "we discretize the continuous-time SDE defined in Eq.~\eqref{eq:general-sde} using the Euler-Maruyama discretization~\cite{maruyama1955continuous}."
- Flow-matching models: Methods that learn velocity fields to transport one distribution to another via continuous-time dynamics. Example: "Flow-matching models~\cite{esser2024scaling, lipman2022flow} further reframed generation as learning deterministic or stochastic paths between distributions."
- Instantaneous velocity: The target vector field representing the local rate of change along a probability path at time t. Example: "Under this linear interpolation, the instantaneous velocity target simplifies to a constant vector:"
- Latent dimensionality: The number of dimensions in the latent representation space. Example: "where denotes the latent dimensionality"
- Latent space: A compact representation space (often learned by an autoencoder) where generation and translation are performed. Example: "Our method leverages a transformer-based architecture to model vision translation tasks in latent space."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that injects trainable low-rank matrices into weight updates. Example: "During training, the image model employs LoRA~\cite{hu2022lora} with a rank of 128, while the video model undergoes full-parameter updates."
- MANIQA: A no-reference image quality assessment metric focusing on perceptual quality. Example: "including NIQE~\cite{mittal2012making}, TOPIQ-NR~\cite{chen2024topiq}, MUSIQ~\cite{ke2021musiq}, MANIQA~\cite{yang2022maniqa}, CLIPIQA~\cite{wang2023exploring}, and CLIPScore~\cite{hessel2021clipscore}."
- MUSIQ: A multi-scale image quality assessment metric. Example: "including NIQE~\cite{mittal2012making}, TOPIQ-NR~\cite{chen2024topiq}, MUSIQ~\cite{ke2021musiq}, MANIQA~\cite{yang2022maniqa}, CLIPIQA~\cite{wang2023exploring}, and CLIPScore~\cite{hessel2021clipscore}."
- NIQE: Naturalness Image Quality Evaluator; a no-reference perceptual quality metric. Example: "including NIQE~\cite{mittal2012making}, TOPIQ-NR~\cite{chen2024topiq}, MUSIQ~\cite{ke2021musiq}, MANIQA~\cite{yang2022maniqa}, CLIPIQA~\cite{wang2023exploring}, and CLIPScore~\cite{hessel2021clipscore}."
- Noise scale (s): A global scalar controlling the magnitude of stochasticity in the diffusion term. Example: "they introduce a global noise scale parameter such that , leading to the generalized SDE:"
- Probability path modeling: A framework modeling continuous-time transport from a prior to a data distribution via SDEs or ODEs. Example: "Probability path modeling~\cite{lipman2022flow, liu2022flow, de2021diffusion} defines a class of generative models that describe continuous-time processes transporting mass from a prior distribution to a target distribution ."
- Prodigy optimizer: An optimization algorithm used for training large-scale models. Example: "We train our models using the Prodigy optimizer~\cite{mishchenko2024prodigy} with a learning rate of 1 and set save_warmup=True."
- PSNR: Peak Signal-to-Noise Ratio; a reference-based metric measuring fidelity to a ground truth. Example: "We then augmented this analysis by introducing reference-based metrics including SSIM~\cite{wang2004image}, PSNR~\cite{pyiqa}, and DISTS~\cite{ding2020image}, to quantitatively measure similarity between generated outputs and ground-truth videos."
- Rectified Flow: A deterministic probability path (with zero diffusion) that linearly interpolates between endpoints. Example: "Rectified Flow~\cite{liu2022flow, esser2024scaling} is a deterministic realization of probability path modeling obtained by setting in Eq.~\eqref{eq:general-sde}."
- Schrödinger bridges: Stochastic bridges derived from entropic regularization, connecting two distributions under uncertainty. Example: "Early approaches employed Schrödinger bridges~\cite{de2021diffusion}, stochastic interpolants~\cite{albergo2023stochastic}, and entropic optimal transport~\cite{cuturi2013sinkhorn}."
- Shift coefficient γ: A parameter that redistributes inference steps toward earlier times in a timestep schedule. Example: "which uses a shift coefficient to allocate more inference steps towards the earlier stages () of the diffusion process."
- SSIM: Structural Similarity Index; a reference-based image similarity metric. Example: "We then augmented this analysis by introducing reference-based metrics including SSIM~\cite{wang2004image}, PSNR~\cite{pyiqa}, and DISTS~\cite{ding2020image}, to quantitatively measure similarity between generated outputs and ground-truth videos."
- Standard Brownian motion: The canonical continuous-time stochastic process with independent Gaussian increments. Example: "and standard Brownian motion ."
- Stochastic differential equation (SDE): A differential equation with stochastic (noise) terms governing random processes. Example: "Generally, these models are represented by a stochastic differential equation (SDE):"
- Stochastic interpolants: Randomized trajectories that connect given endpoints, used for generative modeling. Example: "stochastic interpolants~\cite{albergo2023stochastic},"
- TOPIQ-NR: A no-reference image quality metric assessing perceptual quality. Example: "including NIQE~\cite{mittal2012making}, TOPIQ-NR~\cite{chen2024topiq}, MUSIQ~\cite{ke2021musiq}, MANIQA~\cite{yang2022maniqa}, CLIPIQA~\cite{wang2023exploring}, and CLIPScore~\cite{hessel2021clipscore}."
- VAE encoder: The encoder of a Variational Autoencoder that maps data into a latent space. Example: "using a pre-trained VAE encoder~\cite{kingma2013auto}, and apply the Brownian Bridge formulation to directly model the transformation from to ."
- VBench Score: A composite benchmark score capturing multiple dimensions of video generation quality. Example: "Additionally, we included the VBench Score~\cite{huang2023vbench} as an extra criterion to capture finer-grained and interpretable dimensions of video quality."
- Variance-corrected stochastic update: A sampling update that rescales the noise term to match the time-varying variance structure of a Brownian bridge. Example: "resulting in a variance-corrected stochastic update~\cite{albergo2023stochastic, li2023bbdm}:"
- Variance-stabilized velocity-matching objective: A normalized velocity loss that balances contributions across timesteps and improves numerical stability. Example: "we adopt a Transformer architecture and propose a variance-stabilized velocity-matching objective for robust training."
- Velocity field: The time-dependent vector field defining drift in a probability path. Example: "velocity field ,"
- Velocity-matching objective: A training loss aligning the predicted velocity with a target (teacher) velocity along the path. Example: "trained via a velocity-matching objective~\cite{lipman2022flow, liu2022flow}:"
Collections
Sign up for free to add this paper to one or more collections.