Scalable GANs with Transformers
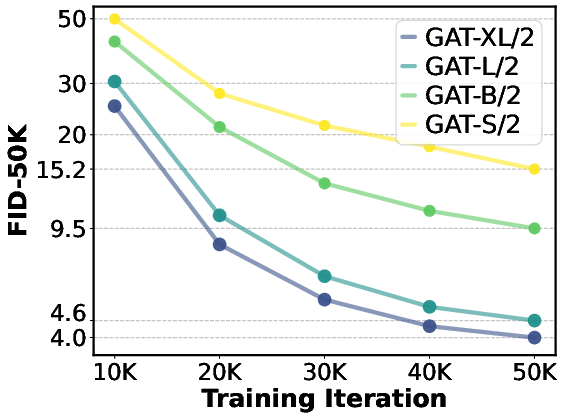
Abstract: Scalability has driven recent advances in generative modeling, yet its principles remain underexplored for adversarial learning. We investigate the scalability of Generative Adversarial Networks (GANs) through two design choices that have proven to be effective in other types of generative models: training in a compact Variational Autoencoder latent space and adopting purely transformer-based generators and discriminators. Training in latent space enables efficient computation while preserving perceptual fidelity, and this efficiency pairs naturally with plain transformers, whose performance scales with computational budget. Building on these choices, we analyze failure modes that emerge when naively scaling GANs. Specifically, we find issues as underutilization of early layers in the generator and optimization instability as the network scales. Accordingly, we provide simple and scale-friendly solutions as lightweight intermediate supervision and width-aware learning-rate adjustment. Our experiments show that GAT, a purely transformer-based and latent-space GANs, can be easily trained reliably across a wide range of capacities (S through XL). Moreover, GAT-XL/2 achieves state-of-the-art single-step, class-conditional generation performance (FID of 2.96) on ImageNet-256 in just 40 epochs, 6x fewer epochs than strong baselines.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making a type of AI image generator, called a GAN (Generative Adversarial Network), work well when it gets bigger. The authors build a new GAN that uses transformers (the same kind of model behind many modern AI systems) and trains in a compact space called a “latent space” from a VAE (Variational Autoencoder). Their goal is to keep GANs fast and high-quality as they scale up, and to show clear rules for making bigger models train stably.
What questions does the paper ask?
The paper focuses on two main questions:
- How can we design a GAN that gets better as we make it larger, without falling apart during training?
- What simple tricks help a big GAN use all its layers effectively and keep training stable?
How does their method work?
Think of a GAN as an artist and a critic:
- The generator (artist) tries to create realistic images.
- The discriminator (critic) checks if images look real or fake.
Here’s what the authors changed and added:
- Training in VAE latent space: Instead of drawing full-size pictures pixel by pixel, the generator works in a compact “code-like” image space made by a VAE. Imagine shrinking a high-res photo into a small, smart thumbnail that still captures important details. This makes training much faster while keeping image quality.
- Pure transformers for both generator and discriminator: Transformers are models that “pay attention” to important parts of data. They scale well with more layers and wider networks, so the team uses transformer blocks in both the artist and the critic.
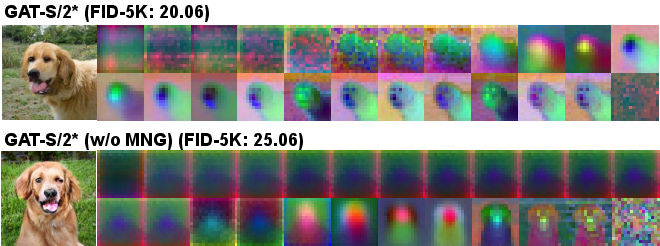
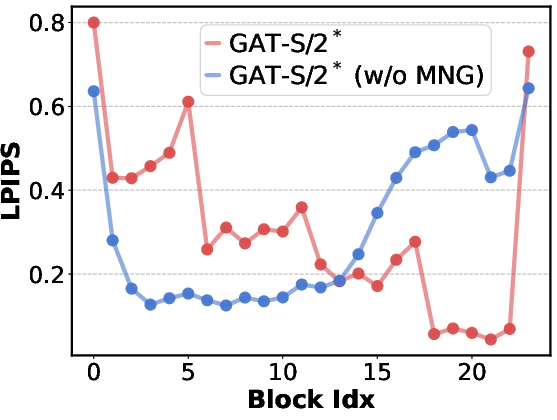
- Fixing “sleepy” early layers with multi-level noise guidance (MNG): When GANs get larger, early layers of the generator can become lazy and not contribute much. To fix this, the generator outputs several intermediate images along the way. The discriminator sees these images after adding different amounts of noise:
- Early outputs are matched to more heavily noised targets (learn big shapes).
- Later outputs are matched to lightly noised or clean targets (add fine details).
- This encourages a “coarse-to-fine” process, so every layer has a job.
- Keeping training stable with a width-aware learning rate: Bigger models can change too quickly with the same learning rate, causing instability. The authors use a simple rule: as the model gets wider (more channels), reduce the learning rate roughly in proportion. It’s like driving a faster car—you turn the steering wheel more gently to stay in control.
- Better discriminator features using a VFM (Vision Foundation Model): They nudge the discriminator’s internal features to look similar to features from a strong, pre-trained vision model (like DINOv2). This helps the critic learn more meaningful visual understanding, which then guides the generator better.
What did they find?
The authors tested their method on ImageNet at 256×256 resolution (a large dataset of labeled images) with class-conditional generation (the model is told which category to draw, like “tiger” or “guitar”). They used a score called FID (Frechet Inception Distance) where lower is better.
Key results:
- Their largest model, GAT-XL/2, reaches a state-of-the-art FID of about 2.96 for single-step image generation, and does it in only 40 epochs (around 6 times fewer training rounds than strong baselines). “Single-step” means it makes an image in one pass, much faster than diffusion models that need many steps.
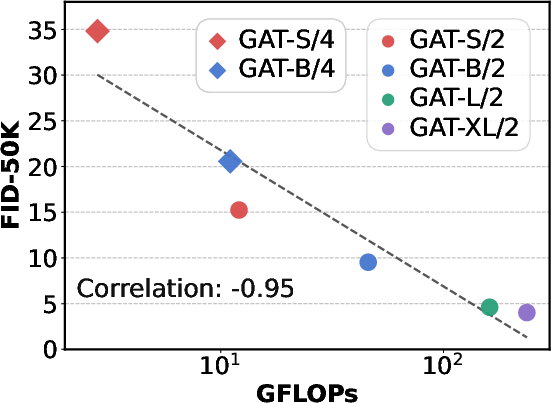
- Scaling works: Larger models consistently get better scores. More compute (GFLOPs) strongly correlates with better FID.
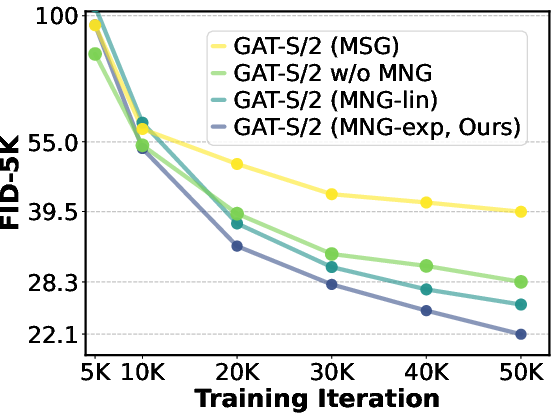
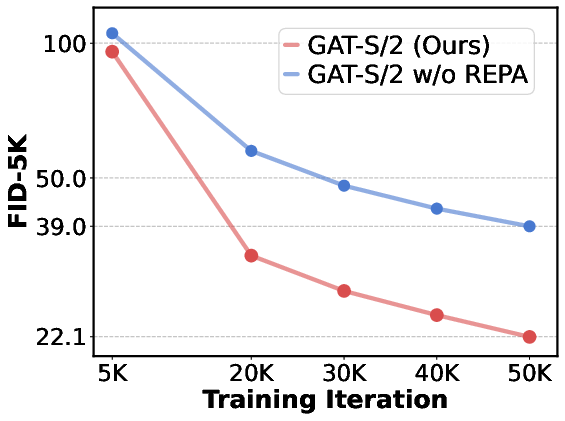
- The multi-level noise guidance (MNG) makes early layers actively contribute and improves image quality throughout training.
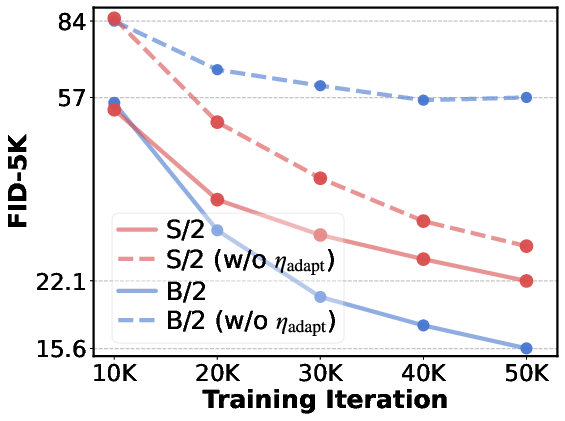
- The adaptive learning rate rule prevents training from diverging and makes scaling simple—no heavy re-tuning for each size.
- Aligning the discriminator’s features with a strong vision model further boosts performance.
Why is this important?
- Speed: GANs can generate images in one step, which is much faster than methods that need hundreds of steps. This makes them great for real-time or large-scale use.
- Quality and scalability: The paper shows that GANs can match or beat other models in quality when designed and trained carefully, and they can improve as they get bigger.
- Simple, practical rules: The two main fixes—multi-level noise supervision and width-aware learning rate—are easy to implement and make training more reliable.
What does this mean for the future?
- Better, faster image generators: This work suggests we can build big, fast, high-quality GANs using transformers and latent-space training, making them useful for apps like instant image creation, video, or 3D.
- Clear scaling recipes: The simple training rules help teams avoid trial-and-error when making larger GANs.
- Stronger critics matter: Improving the discriminator’s understanding of images (using foundation models) can significantly improve the generator. Future work may focus even more on smarter discriminators.
Overall, the paper shows a practical path to scaling GANs: use transformer backbones, train in VAE latent space for efficiency, guide early layers with multi-level noise, and adjust learning rate by width. With these tools, they achieve top-tier results quickly and reliably.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and uncertainties that could guide future research directions:
- Generalization beyond ImageNet-256: No evaluation on other datasets (e.g., FFHQ, LSUN, COCO, LAION subsets), domains (medical, satellite), or long-tail/imbalanced settings; robustness to distribution shift remains unknown.
- Resolution scalability: Only 256×256 is reported; feasibility and performance at higher resolutions (512, 1024, 2048) are untested, especially given quadratic token growth in transformers.
- Conditioning scope: Results are class-conditional only; applicability to unconditional and text-conditional generation (e.g., CLIP/LLM conditioning) is unexplored.
- Tokenizer dependence: The approach relies on SD-VAE with 8× downsampling and fixed 32×32 latents; the impact of the VAE bottleneck (reconstruction artifacts, semantic loss) on adversarial learning and ultimate image quality is not analyzed.
- Alternative latent/tokenizers: No comparison to alternative latent spaces (e.g., improved VAEs, VQ-VAEs, MAE-like continuous latents) or to jointly fine-tuning the tokenizer with G/D.
- End-to-end training: The effects of jointly updating the VAE (encoder/decoder) with GAN training are not studied (stability, quality, compute trade-offs).
- MNG design space: Multi-level Gaussian noise is the only corruption tested; other perturbations (blur, masking, downsample, JPEG, stochastic augmentations, diffusion-style noise schedules) and hybrid schemes are not evaluated.
- Number and placement of intermediate outputs: Choice of K=4 and uniform stage spacing lacks sensitivity analysis; optimal K, stage placement, and adaptive schedules are unknown.
- Discriminator interface for multi-level inputs: Architectural alternatives for ingesting and fusing multiple noised outputs (token concatenation vs. cross-attention vs. shared towers) are not compared.
- Memory/compute overhead of MNG: Wall-clock training cost, memory footprint, and throughput impact of multiple intermediate outputs and noised passes are not quantified.
- Stability and theory of LR scaling: The proposed width-aware learning-rate rule does not address depth, batch size, optimizer betas, EMA decay, weight decay, or gradient clipping; theoretical justification and cross-setting robustness are limited.
- Generality of LR rule: Applicability to non-transformer GANs, different normalizations (LayerNorm vs RMSNorm), activations, or architectures with non-constant channel width is untested.
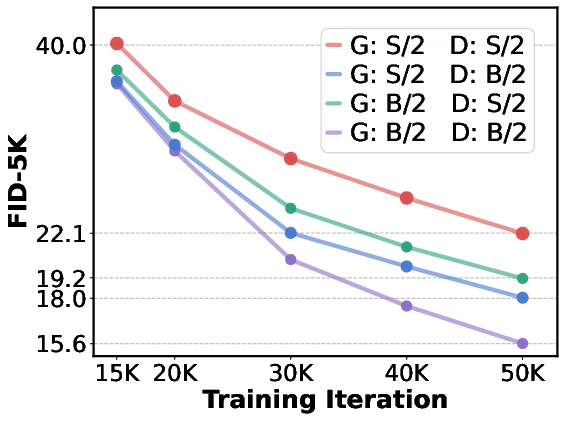
- Discriminator–generator capacity ratio: While scaling D helps more than G, the optimal capacity allocation (G:D parameters/compute) and dynamic scheduling across training are not established.
- Training dynamics: Detailed analyses of adversarial game stability (e.g., oscillations, mode collapse, gradient norms, spectral properties) and how MNG/LR scaling modulate them are absent.
- Regularization interactions: Interplay of approximated gradient penalty, DiffAug, Layerscale, and MNG is not disentangled; ablations on each component’s necessity at scale are limited.
- Metric coverage: Only FID (5K/50K) is reported; no precision/recall, density/coverage, IS, CLIP score, human preference, or diversity metrics; mode coverage and trade-offs with guidance are unknown.
- Memorization and privacy: No nearest-neighbor, train–test overlap, or membership inference analyses; risk of memorization at XL scale is unassessed.
- Seed variance and reliability: Training variance across random seeds and run-to-run stability are not reported; reproducibility under minimal hyperparameter tuning is unclear.
- Compute–performance trade-offs: GFLOPs vs FID is shown for generator forward passes, but not end-to-end wall-clock, energy, memory, or throughput; fairness vs baselines in compute budgets is not established.
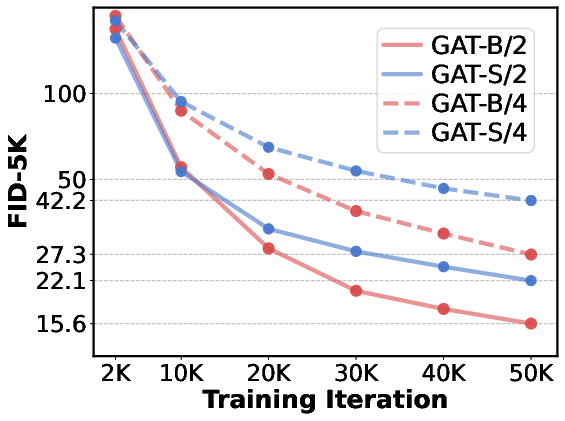
- Patch size scaling: Only p=2 and p=4 tested on smaller models; impact of tokenization granularity at larger scales (L/XL) and on visual fidelity vs compute is not characterized.
- Latent dimension: The latent size is fixed (d_z=64); effects of latent dimensionality on diversity, controllability, and stability are not explored.
- Latent semantics: Claims of latent interpolation are qualitative; no quantitative disentanglement or semantic direction analysis is provided.
- Inference-time guidance: Latent-space guidance is briefly used; its effects on diversity, class consistency, and failure modes (e.g., overfitting to class means) are not systematically studied.
- Bias and feature leakage: REPA aligns D to DINOv2 (ImageNet-trained); potential leakage, domain bias, and fairness impacts on evaluation (FID) are not analyzed.
- Domain transfer of REPA: Efficacy of VFM alignment on non-ImageNet domains, high resolutions, or with different VFMs (e.g., CLIP variants) is untested; when does REPA hurt/help?
- MNG vs MSG and coarse-to-fine alternatives: Comparative studies with hierarchical resolution generators, explicit pyramids, and self-conditioning approaches are limited.
- Early-layer underuse: Root causes beyond lack of supervision (e.g., attention patterns, token mixing, initialization) are not deeply probed; architectural remedies other than MNG are not evaluated.
- Layerscale and RMSNorm choices: Criticality of Layerscale initialization, RMSNorm vs LayerNorm, qk-normalization, RoPE, and SwiGLU is not ablated for stability and scale-up.
- Data efficiency claims: While fewer epochs are used, compute-normalized comparisons (FLOPs×epochs) against baselines are missing; benefits under limited data regimes are unknown.
- OOD robustness: Behavior under corruptions (ImageNet-C/P), stylization, adversarial perturbations, or domain shifts has not been evaluated.
- Safety and content control: The framework’s controllability, safety filtering, and bias mitigation (especially for scaling to web-scale data) are unaddressed.
- Failure case taxonomy: No qualitative/quantitative analysis of common failure modes (e.g., background artifacts, class mixing, texture bias) to guide targeted improvements.
- Open-sourcing and reproducibility: Public availability of code, pretrained models, and training logs for verification and extension is not specified.
- Multi-modal extensions: Integration with text encoders and LLMs, and compatibility with instruction following or compositional prompts are unexplored.
- Theoretical perspective on MNG: Formal connections to diffusion’s noise-conditioning and multi-scale learning, or guarantees about layer utilization and gradient signal routing, are not provided.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage the paper’s findings (GAT: transformer-only GANs trained in VAE latent space with multi-level noise guidance and width-aware learning-rate scaling).
- Low-latency image generation for creative production
- Sectors: media/entertainment, advertising, e-commerce, design
- Tools/workflows: single-step, class-conditional image generators for rapid A/B testing of product shots, ad creatives, thumbnails; plug-ins for Adobe/Blender/Figma to generate and iterate images in real time
- Assumptions/dependencies: access to a pretrained SD-VAE tokenizer; domain-appropriate fine-tuning data (labels for class-conditional); content safety filters and licensing for training data; GPU for best quality/latency; quality currently validated at 256×256
- Interactive latent-space editing and interpolation tools
- Sectors: creative software, gaming, AR/VR prototyping
- Tools/workflows: UI sliders for semantic style/content manipulation (interpolation between latent codes), batch style transfer for design exploration
- Assumptions/dependencies: reliance on GAN’s semantic latent space; requires UX integration and light fine-tuning for domain semantics
- Cost- and energy-efficient image synthesis in production systems
- Sectors: cloud platforms, MLOps, energy-conscious AI deployments
- Tools/workflows: replacing multi-step diffusion components with one-step GAT modules in services where speed/throughput dominates; autoscaling microservices with per-model LR scaling and small-batch training
- Assumptions/dependencies: integration with existing inference serving; monitoring for GAN failure modes; model selection (S/B/L/XL) matched to latency and quality requirements
- Rapid synthetic data augmentation for vision classifiers
- Sectors: retail (product recognition), manufacturing (defect detection), agriculture, remote sensing
- Tools/workflows: class-conditional augmentation pipelines to balance long-tail classes or stress-test models; mix real and GAT-generated samples to improve robustness
- Assumptions/dependencies: careful validation against domain shift; bias auditing; label availability for class-conditional training; SD-VAE suitability for domain
- Single-GPU/edge-friendly image generation with small GAT variants
- Sectors: mobile/edge devices, on-prem solutions with constrained compute
- Tools/workflows: deploy GAT-S/B with quantization/graph optimizations for kiosks, retail endpoints, or design workstations; on-device prototyping apps
- Assumptions/dependencies: model compression/quantization; optimized attention kernels; power/thermal limits; resolution constraints
- Stable scaling recipes for existing GAN-based tasks
- Sectors: super-resolution, image-to-image translation, face synthesis
- Tools/workflows: adopt width-aware learning-rate rule to stabilize large transformer-based GANs; add multi-level noise-perturbed guidance to reactivate early layers
- Assumptions/dependencies: adaptation of MNG to task-specific architectures; re-tuning noise schedules; compatibility with task losses
- Discriminator-as-encoder for downstream perception
- Sectors: visual search, QA of generated content, anomaly detection
- Tools/workflows: reuse REPA-aligned discriminator features (aligned with DINOv2) as embeddings for similarity search or quality scoring
- Assumptions/dependencies: training D with REPA; licensing/compliance for VFM (e.g., DINOv2); calibration for target tasks
- Academic baseline for scaling studies in adversarial learning
- Sectors: academia, research labs
- Tools/workflows: reproducible S→XL scaling curves, GFLOPs–FID analyses, ablations (MNG, LR scaling, VFM alignment) as teachable benchmarks
- Assumptions/dependencies: availability of code and SD-VAE; standardized evaluation (FID-5k/50k); compute for XL models (or smaller scales for coursework)
- Procurement and sustainability guidance for ML ops
- Sectors: policy/enterprise governance, sustainability teams
- Tools/workflows: prefer single-step generators to reduce training epochs and inference NFEs; estimate carbon savings when swapping multi-step diffusion with GAT
- Assumptions/dependencies: life-cycle analysis data; organizational readiness to measure/track compute and emissions
Long-Term Applications
These use cases are promising but require further research, scaling, adaptation to new modalities, higher resolutions, or stronger controls.
- High-resolution and text-to-image extensions
- Sectors: design, advertising, synthetic media platforms
- Tools/workflows: extend class-conditional GAT to robust text conditioning (e.g., via T5/CLIP encoders) and to 512–4k resolutions; integrate guidance and compositional controls
- Assumptions/dependencies: conditioning architecture changes; more data and compute; improved tokenizers for high-res fidelity; evaluation beyond FID (human/rating studies)
- Real-time content generation on consumer devices
- Sectors: mobile apps, AR filters, creator tools
- Tools/workflows: compressed/quantized GAT variants running on NPUs/GPUs in phones or glasses; interactive photo creation/editing without cloud
- Assumptions/dependencies: advanced model compression, attention acceleration, memory-aware architectures; power constraints; on-device safety filters
- Video and multi-frame generation with temporal consistency
- Sectors: advertising, pre-viz, gaming, telepresence
- Tools/workflows: adapt MNG’s coarse-to-fine supervision across time to enforce temporal coherence; one-step or few-step video GANs in latent space
- Assumptions/dependencies: temporal tokenization, recurrent/attention designs, temporal discriminators; large-scale video data; new stability recipes
- 3D/NeRF and multi-view-consistent asset generation
- Sectors: VFX, gaming, CAD/PLM, e-commerce 3D
- Tools/workflows: GAT as a backbone for generating multi-view-consistent images or radiance fields; latent-space controls for shape/style interpolation
- Assumptions/dependencies: 3D-consistency losses, multi-view data, geometry-aware discriminators, integration with 3D pipelines (NeRF/mesh)
- Domain-specific synthetic data factories for regulated sectors
- Sectors: healthcare (medical imaging), finance (document synthesis), autonomous driving (corner cases)
- Tools/workflows: GAT-based synthetic datasets with rigorous bias/fairness controls, privacy safeguards, and uncertainty modeling; fast class-balanced scenario generation
- Assumptions/dependencies: regulatory approval, clinical/industry validation, domain-specific tokenizers, robust OOD detection and audit trails
- General-purpose visual encoders from adversarial training
- Sectors: foundation model pretraining, search/retrieval
- Tools/workflows: train discriminators with REPA or similar alignment at scale to produce strong, generalizable vision features; pretrain–finetune pipelines
- Assumptions/dependencies: large curated datasets; careful alignment objectives; evidence of transfer superiority vs. existing VFMs
- Synthetic content governance and provenance ecosystems
- Sectors: policy, platforms, cybersecurity
- Tools/workflows: watermarking and detection adapted to single-step GANs; provenance metadata pipelines; platform policies tuned to scalable, efficient generators
- Assumptions/dependencies: robust watermarking for GAN outputs; standards adoption (e.g., C2PA); cooperative platform enforcement and legal frameworks
- Energy- and cost-aware generative AI infrastructure
- Sectors: cloud/edge providers, sustainability initiatives
- Tools/workflows: scheduling and autoscaling tuned to one-step models; SLA tiers based on NFE and compute footprints; carbon-aware routing
- Assumptions/dependencies: reliable telemetry for model energy; pricing models that incentivize low-NFE generation; shared benchmarks
- Programmatic controllability for enterprise workflows
- Sectors: marketing ops, e-commerce PIM, DAM systems
- Tools/workflows: APIs exposing class-conditional or latent controls (brand palettes, layouts) to auto-generate on-brand variants; approval loops with human-in-the-loop
- Assumptions/dependencies: robust conditioning interfaces, brand-safe datasets, governance for IP and content integrity
- Cross-modal extensions (image–text–layout; image–audio)
- Sectors: publishing, education, accessibility
- Tools/workflows: GAT variants conditioned on layouts, captions, or audio cues for multimodal content assembly
- Assumptions/dependencies: cross-modal tokenizers, multimodal discriminators, datasets with aligned annotations
Notes on feasibility and dependencies across applications
- Core technical dependencies: SD-VAE (or equivalent) quality and license; access to labeled data for class-conditional training; availability of VFMs for REPA (e.g., DINOv2) with compatible licenses.
- Compute: while one-step sampling and reduced epochs cut costs, XL-scale training still requires multi-GPU clusters; deployment on edge requires compression and kernel optimization.
- Generalization: reported state-of-the-art is on ImageNet-256; transferring to higher resolutions, domains, or modalities requires further validation.
- Safety/ethics: content filters, watermarking, and dataset governance are essential for responsible deployment, particularly in consumer and policy-sensitive contexts.
Glossary
- AdaLN-zero: A transformer normalization variant used in diffusion models that initializes adaptive layer normalization parameters to zero to stabilize training. "DiT-XL/2 & 675M & 2502 & 2.27 ~~ SiT-XL/2 & 675M & 2502 & 2.06 ~~ SiT-XL/2+REPA & 675M & 2502 & 1.42" (mentions "AdaLN-zero layer" in the additional related works section)
- AdamW: An optimizer that combines Adam with decoupled weight decay for better generalization. "The optimizer is AdamW with (following common GAN practice such as StyleGAN)."
- Adaptive learning rate: Adjusting the learning rate based on model scale to keep update magnitudes stable. "we use identical hyperparameters for every scale of models except the learning rate, which we adaptively modify as elaborated in Sec.~\ref{sec 2.4: adaptive lr} ."
- Autoregressive models: Generative models that produce outputs sequentially, often token by token or patch by patch. "\multicolumn{4}{l}{autoregressive/masking}"
- bfloat16 precision: A 16-bit floating-point format that balances range and precision for efficient training. "Also, we use a batch size of $512$, bfloat16 precision, gradient checkpointing, and PyTorch Scaled Dot-Product Attention~(SDPA) implementation."
- Class-conditional generation: Generating images conditioned on class labels to control the output category. "We conduct all experiments with class-conditional generation on ImageNet~\citep{imagenet} at a resolution of 256×256."
- Classifier-Free Guidance (CFG): A sampling technique that improves diffusion/flow model outputs by adjusting conditional/unconditional predictions. "Diffusion/flow entries are reported under CFG, when applicable."
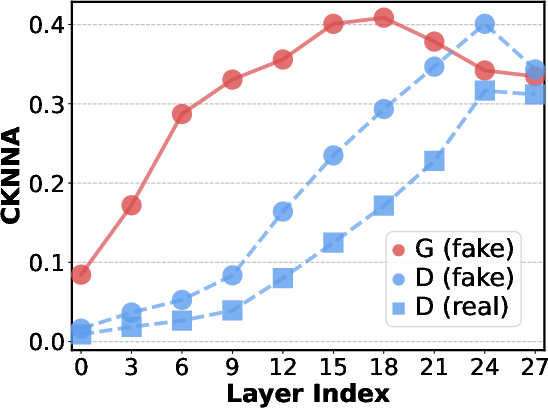
- CKNNA: A feature-alignment metric used to compare model representations against foundation models. "\subcaption{CKNNA of G and D}"
- [CLS] token: A special transformer token used for classification tasks, appended to the input sequence. "a dedicated token is appended to the sequence of visual tokens before the first transformer block."
- Differentiable augmentation: Data augmentation methods implemented as differentiable operations within the training graph. "During training, we apply differentiable augmentation~\citep{diffaug}."
- DINOv2: A vision foundation model providing strong image representations used for alignment. "Let be a frozen vision foundation model~(e.g., DINOv2~\citep{dinov2}),"
- Equalized learning rate: A technique that scales parameter updates to be invariant to layer/channel size for stable training. "Our rule is conceptually related to the equalized learning rate~\citep{progan} used in conventional GANs,"
- Exponential Moving Average (EMA): Smoothing of model parameters over training steps to stabilize and improve generation. "We apply exponential moving average~(EMA) to the generator with decay $0.999$."
- FID (Fréchet Inception Distance): A metric that quantifies the quality and diversity of generated images by comparing feature distributions. "GAT-XL/2 achieves state-of-the-art single-step, class-conditional generation performance~(FID of 2.96) on ImageNet-256 in just 40 epochs,"
- GFLOPs: Giga Floating Point Operations, a measure of computational complexity for model forward passes. "Model complexity is commonly measured by GFLOPs."
- GAT (Generative Adversarial Transformers): A GAN framework that uses transformers in VAE latent space for scalable image synthesis. "We introduce Generative Adversarial Transformers~(GAT), a transformer-based GAN framework at the latent space of VAE, for the first time."
- GAN (Generative Adversarial Networks): A framework with a generator and discriminator trained adversarially to synthesize realistic data. "Generative Adversarial Networks~(GAN)~\citep{GAN} is an adversarial learning framework between two networks, the generator and discriminator ."
- Gradient checkpointing: A memory-saving technique that trades compute for reduced activation storage by recomputing during backpropagation. "Also, we use a batch size of $512$, bfloat16 precision, gradient checkpointing, and PyTorch Scaled Dot-Product Attention~(SDPA) implementation."
- Layerscale: A per-layer learnable scaling mechanism that stabilizes deep transformer training by modulating block outputs. "with Layerscale applied to the output of each transformer block."
- Latent interpolation: Smoothly transitioning between latent codes to demonstrate semantic continuity in the generator’s latent space. "while keeping the characteristics of GANs such as latent interpolation~(bottom two rows)."
- Latent-space guidance: A guidance technique operating entirely within the GAN’s latent/style space to steer outputs with negligible overhead. "we employ latent-space guidance~\citep{gandance} with a strength of 1.1, applied to the first 30\% of transformer blocks."
- LPIPS: A perceptual similarity metric based on deep features that correlates with human judgment. "LPIPS distances while ablating Transformer blocks one by one."
- Mapping network: An MLP that transforms latent code and condition into style vectors used to modulate generator features. "we employ a mapping network, a simple MLP, that generates a style vector from and ."
- MNG (Multi-level Noise-perturbed image Guidance): A training strategy that supervises generator intermediate outputs at multiple noise levels to activate early layers. "To this end, we propose the Multi-level Noise-perturbed image Guidance~(MNG) strategy for training GANs."
- NFE (Number of Function Evaluation): The number of model evaluations required during sampling; lower NFE implies faster generation. "(Left) 1 or 2 Number of Function Evaluation~(NFE) generative models."
- PCA (Principal Component Analysis): A dimensionality reduction technique used here to visualize intermediate features across layers. "we visualize intermediate features for each transformer block using PCA."
- Patchify/unpatchify layer: Operations to convert images to token sequences (patchify) and back to images (unpatchify) for ViT-based models. "we remove the patchify layer and instead introduce an unpatchify layer"
- Projection discriminator: A discriminator that incorporates class conditioning via inner products with class embeddings. "For class conditioning of discriminator, we use the projection discriminator~\citep{projection-disc}."
- qk-normalization: A normalization technique applied to query and key tensors in attention to stabilize training. "Rotary Positional Embeddings~(RoPE)~\citep{rope}, SwiGLU-FFN~\citep{swigluffn}, and qk-normalization."
- REPA: A representation alignment objective that aligns discriminator tokens with features from a vision foundation model. "The REPA objective substantially improves performance, indicating that advances from diffusion models can transfer effectively to GAT."
- Relativistic pairing loss: An adversarial loss where the discriminator compares real and fake logits relativistically to enhance stability. "we deploy relativistic pairing loss~\citep{rpgan} with the approximated version of two-sided gradient penalty~\citep{seaweed-apt}, following R3GAN~\citep{r3gan}."
- RMSNorm: A normalization layer that scales activations by their root mean square without a bias term. "Since we adopt RMSNorm, the shift parameter is omitted."
- RoPE (Rotary Positional Embeddings): A positional encoding method that injects rotation-based position information into attention. "Rotary Positional Embeddings~(RoPE)~\citep{rope}, SwiGLU-FFN~\citep{swigluffn}, and qk-normalization."
- SDPA (Scaled Dot-Product Attention): The attention computation used in transformers, here via PyTorch’s optimized implementation. "PyTorch Scaled Dot-Product Attention~(SDPA) implementation."
- SD-VAE (Stable Diffusion VAE): The variational autoencoder from Stable Diffusion used as a tokenizer to map images to latent space. "we employ the pre-trained Stable Diffusion variational autoencoder~(SD-VAE)~\citep{LDM} as a tokenizer"
- Style vector: A vector derived from latent code and condition that modulates transformer features via adaptive normalization. "This style is then used to modulate features through adaptive normalization and Layerscale"
- SwiGLU-FFN: A feed-forward network variant using SwiGLU activation for improved transformer performance. "Rotary Positional Embeddings~(RoPE)~\citep{rope}, SwiGLU-FFN~\citep{swigluffn}, and qk-normalization."
- Truncation trick: A sampling technique that limits latent deviations to improve sample quality at the cost of diversity. "evaluated without the truncation trick or guidance~\citep{gandance}, unless specified."
- Two-sided gradient penalty: A regularization that penalizes discriminator sensitivity by comparing outputs on perturbed real and fake inputs. "we deploy relativistic pairing loss~\citep{rpgan} with the approximated version of two-sided gradient penalty~\citep{seaweed-apt},"
- VAE latent space: A lower-dimensional representation learned by a variational autoencoder where generative models can be trained efficiently. "we build GAT on the latent space of VAE~\citep{LDM}, following the recent advances in generative models"
- VFM (Vision Foundation Models): Powerful pretrained vision models whose features are used for representation alignment. "Vision Foundation Models~(VFM)"
- ViT (Vision Transformer): A transformer architecture for images that operates on patch tokens rather than convolutional features. "Our generator adopts a standard Vision Transformer~(ViT) architecture"
- Width-aware learning-rate adjustment: Scaling the learning rate inversely with channel width to keep output changes consistent across model sizes. "Accordingly, we provide simple and scale-friendly solutions as lightweight intermediate supervision and width-aware learning-rate adjustment."
Collections
Sign up for free to add this paper to one or more collections.

