- The paper demonstrates that decoupling CFG Augmentation from Distribution Matching enables efficient few-step diffusion distillation.
- It details a novel two-module perspective where CFG Augmentation drives content generation while Distribution Matching acts as a regularizer to mitigate artifacts.
- Empirical results show that the decoupled schedule outperforms conventional methods, yielding superior image quality and training stability.
Decoupled DMD: CFG Augmentation as the Spear, Distribution Matching as the Shield
Introduction and Motivation
Diffusion models have achieved state-of-the-art generative performance in image synthesis, but their sampling process remains prohibitively slow for real-time deployment. A key research direction is few-step distillation—retraining a student generator to match the output distribution of a high-quality, multi-step teacher using far fewer steps. Among prominent approaches, Distribution Matching Distillation (DMD) is often believed to work by aligning the output distributions between student and teacher (via Integral KL minimization). However, for text-to-image generation, DMD variants consistently require Classifier-Free Guidance (CFG) at high scales, violating the theoretical symmetry of the distribution matching setup.
This paper rigorously decomposes the practical DMD objective and provides a novel two-module perspective: (1) CFG Augmentation (CA), which operates as the main engine converting multi-step to few-step generation; and (2) Distribution Matching (DM), which is relegated to a regularization role ensuring training stability and artifact mitigation. The empirical and theoretical analysis sharply contradicts the prevailing single-mechanism narrative and motivates a principled redesign of the distillation pipeline.
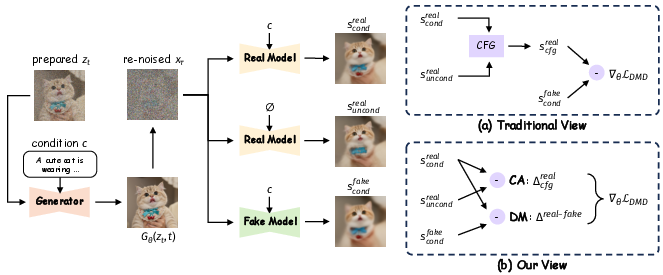
Figure 1: Two perspectives on the DMD algorithm—(a) the conventional view attributes success solely to distribution matching; (b) the proposed decoupled view distinguishes CA as the engine and DM as the regularizer.
Theoretical Decomposition of DMD
The gradient of the practical DMD objective is shown to be a sum of two distinct terms via expansion of CFG:
∇θLDMD=E[−(scondreal−scondfake)+(α−1)(scondreal−suncondreal)]∂θ∂Gθ(zt)
- The first term is Distribution Matching (DM): strict theoretical alignment between student and teacher scores.
- The second, CFG Augmentation (CA), bakes the deterministic guidance shift directly onto the generator.
Isolating these two mechanisms via ablation reveals that CA is indispensable for rapid distillation: it almost entirely drives the conversion from multi-step to few-step generation. DM, while capable of some conversion (in easier settings), is far less effective and primarily ensures avoidance of instability/artifacts.

Figure 2: Ablation study on the CA and DM components. Metrics on 1k COCO-10k prompts show CA as the dominant factor.
Regularization Roles and Comparisons
Systematic regularizer experiments (mean-variance nonparametric constraints, GAN-based losses) reveal that DM is not a unique regularizer—multiple alternatives can stabilize CA-only training, but with important trade-offs. Nonparametric regularizers (KL on mean/variance) can halt collapse, yet cannot fully mitigate higher-order artifacts. GAN regularization achieves powerful correction but suffers from notorious instability, especially in disjoint-support settings. DM occupies an optimal regime in stability–performance trade-off, validating its practical use.
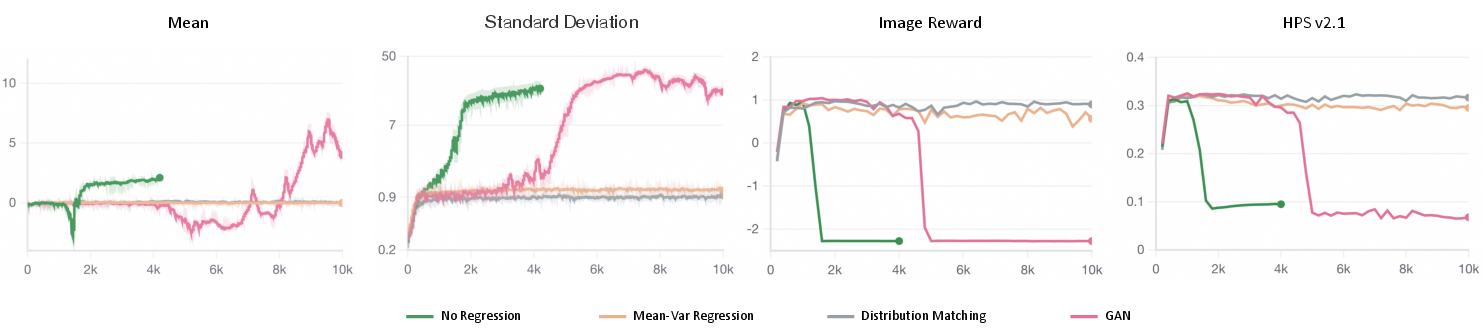
Figure 3: CFG Augmentation with different regularizers—quantitative evaluation highlights regularizer trade-offs.

Figure 4: Visual samples of CA combined with distinct regularizers, illustrating artifact suppression and detail differences.
Mechanistic Analyses: Scheduling and Correction
CA Engine
Detailed scheduling experiments show the effect of the re-noising step (τ) in CA—applying CA at low noise enhances global content, while high τ adds fine details. However, CA-only training at high τ collapses when low-frequency information is under-determined. For multi-step generation, applying CA on already-resolved content is detrimental. Thus, the optimal CA schedule is focused: restrict re-noising to unresolved (late) aspects, specifically τ>t at each step.

Figure 5: (a) Effects of re-noising timestep τ for CA alone—low τ boosts composition, high τ adds details; (b) visualization of DM's correction mechanism for artifacts.
DM Regularizer
By observing the fake model (trained on generator output) and real teacher scores on artifact-laden images, it is evident that DM gradients actively cancel persistent failure modes—fake scores adopt artifacts unique to the generator, while teacher scores do not. DM thus functions as a corrective signal, and its re-noising schedule should remain global to preserve the ability to catch both high- and low-frequency errors (τDM∈[0,1]).
Empirical Validation of Decoupled Scheduling
Generalizing the DMD gradient to independent CA and DM schedules, experiments on Lumina-Image-2.0 and SDXL unequivocally demonstrate superior performance for Decoupled-Hybrid scheduling: CA is constrained (τCA>t), while DM is left global (τDM∈[0,1]). Across both quantitative benchmarks and qualitative studies, this configuration yields the best scores and most visually plausible results, notably outperforming baselines and prior state-of-the-art distillation methods.

Figure 6: Qualitative comparison of schedule configurations; Decoupled-Hybrid yields the richest and least artifact-prone results.
User Preference and Benchmark Results
Extensive user studies corroborate the technical findings—a unanimous 100% preference rate for Decoupled-Hybrid over alternative models in both model-level and image-level rankings. Annotators explicitly cite richer detail, realistic color/texture, and reduced deformities. Fine-grained benchmark tables (HPS v2.1, HPS v3) and FID, CLIP-S, ImageReward metrics reinforce the superiority of the decoupled approach.
Theoretical Implications and Future Prospects
The decomposition challenges the field's understanding of fast diffusion distillation, showing that empirical progress relies less on strict distribution matching and more on "baking in" deterministic guidance patterns via CFG Augmentation. The analogy to sequential prediction in language modeling (see appended high-level discussion) suggests that external interventions (CFG, sampling) can be deterministically internalized to circumvent the need for iterative refinement.
This opens important questions regarding the generalization of CA's mechanism, the limits of regularization (statistical constraints vs. adversarial learning), and the broader implications for compressing generative models across modalities. More rigorous analysis of CFG's pattern-forming capacity and its interaction with student initialization will be essential for next-generation generative model distillation.
Conclusion
This work establishes a principled, empirically validated division between the engine (CFG Augmentation) and the regularizer (Distribution Matching) in few-step diffusion distillation. The new understanding not only reconciles theory and practice but also enables systematic redesign of noise schedules, delivering clear state-of-the-art improvements. Ongoing gaps in the mechanistic explanation of CA suggest fertile ground for further research in sequence modeling, guidance patterns, and model compression strategies.
Reference: "Decoupled DMD: CFG Augmentation as the Spear, Distribution Matching as the Shield" (2511.22677)