- The paper introduces a novel distillation procedure and joint reinforcement learning strategy to achieve high-fidelity few-step image generation.
- It employs a timestep-aware loss decoupling that uses DM loss for structural alignment and Pixel-GAN loss for detail refinement, significantly reducing training cost.
- Experiments demonstrate that Flash-DMD outperforms baselines by achieving competitive human preference scores and improved realism with minimal resource use.
Authoritative Summary of "Flash-DMD: Towards High-Fidelity Few-Step Image Generation with Efficient Distillation and Joint Reinforcement Learning" (2511.20549)
Introduction and Motivation
Diffusion models have become a central paradigm for high-quality generative modeling across text-to-image and related domains. Despite state-of-the-art fidelity, the iterative nature of diffusion inference (often 20–100 steps) poses severe computational limits for real-time and resource-constrained applications. Timestep distillation approaches compress the inference process to a few steps, but this efficiency comes with substantial training overhead and noticeable degradation in visual quality. Moreover, RL-based finetuning for human alignment in distilled models is unstable and susceptible to reward hacking with oversimplified or unnatural outputs.
Flash-DMD is proposed as a unified framework that aims to decisively address these limitations by (1) redesigning the distillation procedure for maximum efficiency, and (2) establishing a stable joint optimization regime between distillation and preference-based RL. The methodology innovates on both the loss structure and update dynamics to consistently improve convergence rates, sample quality, and stability.
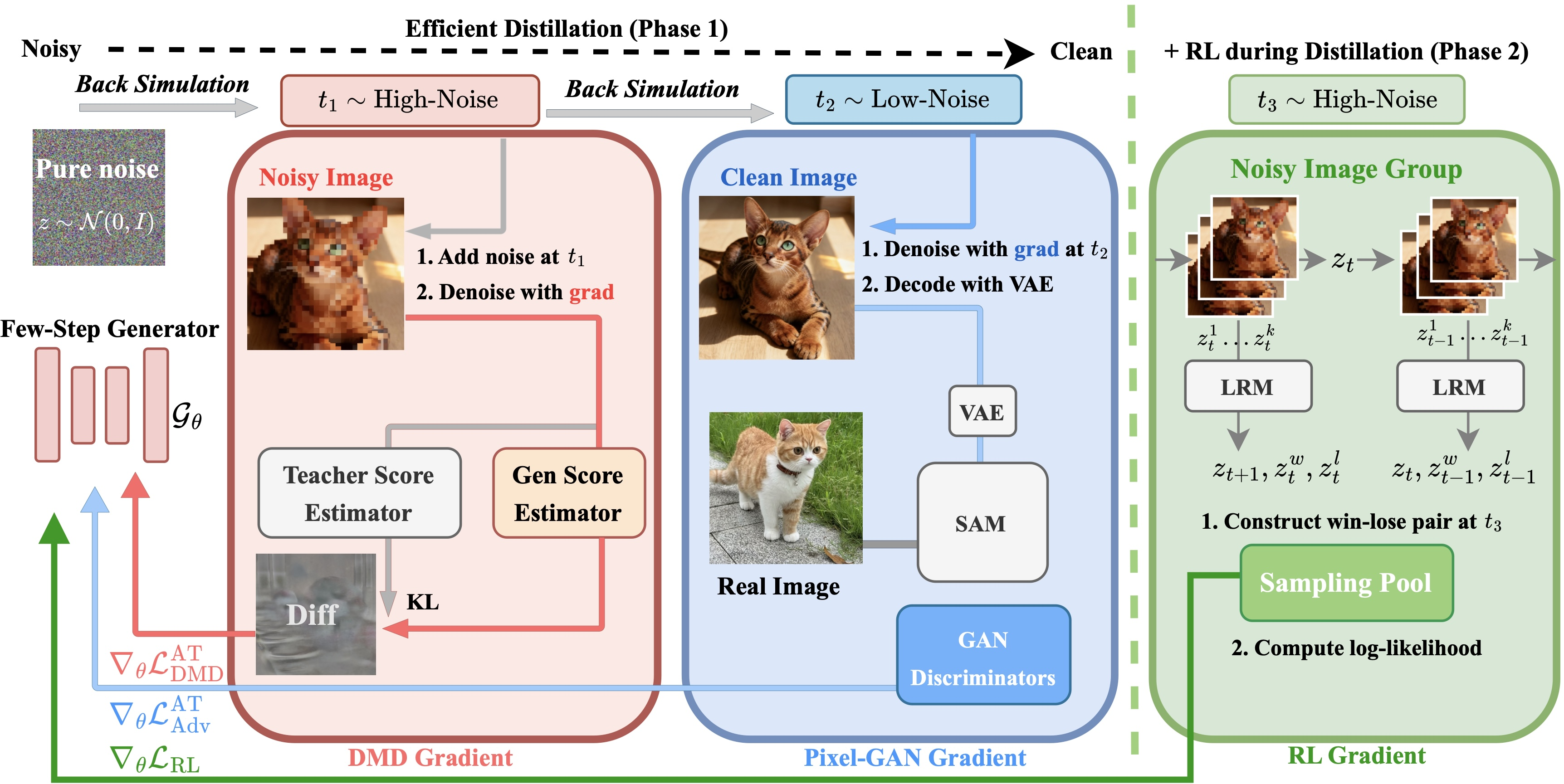
Figure 1: The Flash-DMD framework splits objectives by timestep: DMD loss accelerates early-stage alignment, while Pixel-GAN loss at later timesteps refines realism; joint RL during distillation integrates stable preference optimization.
Methodological Framework
Timestep-Aware Loss Decoupling
Empirical observation shows that generative objectives vary by noise regime in diffusion denoising. Flash-DMD explicitly decouples the loss landscape:
- High-noise (low-SNR) timesteps: Dominated by global structure and semantic composition. The Distribution Matching (DM) loss enables the student to rapidly track the trajectory of the teacher's latent distribution.
- Low-noise (high-SNR) timesteps and final outputs: Focused on texture, realism, and photorealistic details. Adversarial Pixel-GAN loss, implemented with a SAM-based discriminator, is uniquely applied to the pixel space, enforcing fine-grained realism and avoiding mode-seeking behavior typical in KL-based alignment.
This schedule-based separation prevents conflicting gradients and aligns learning signals with the capabilities of the few-step generator at each stage.

Figure 2: Sampling variance across denoising steps; high-noise stages offer improved diversity for downstream preference optimization.
Score Estimator Stabilization
Contrary to prior approaches (e.g. DMD2) which imbue the score estimator with adversarial and distribution tracking capacities, Flash-DMD enforces a pure diffusion-track paradigm. The score estimator is only updated via diffusion losses and synchronized to the generator via EMA, yielding stable distributional tracking and eliminating the need for high-frequency TTUR updates. Experiments demonstrate that TTUR ratios as low as 1 or 2 are sufficient for stability, dramatically reducing training cost.
Joint RL Training
Flash-DMD integrates preference-based RL into distillation using a latent reward model (LRM), which supports timestep-aware evaluation. RL (via LPO-style objectives) is performed at high-noise steps, sampling diverse candidates and constructing win-lose pairs to directly optimize for human-centric metrics. Crucially, RL and distillation are performed jointly, with the stable distillation objective regularizing RL updates and mitigating reward hacking/degenerate outputs.

Figure 3: Comparison of RL-finetuned models on SDXL; Flash-DMD avoids overexposed and smoothed artifacts seen in baselines, delivering natural, detail-rich generations.
Empirical Results
Distillation Efficiency and Fidelity
On SDXL and SD3-Medium, Flash-DMD demonstrates an order-of-magnitude reduction in training cost relative to DMD-series baselines, with only 2.1% of DMD2’s resource use yielding higher human preference scores and competitive fidelity metrics:
- In 4-step generation, TTUR1-1k and TTUR2-4k variants match or surpass DMD2 and SDXL-Turbo across ImageReward, PickScore, and MPS metrics.
- Pixel-GAN and EMA for score estimator are confirmed via ablations to enhance both perceptual realism and preference scores.
- The method generalizes robustly to Flow Matching architectures (e.g., SD3-Medium).
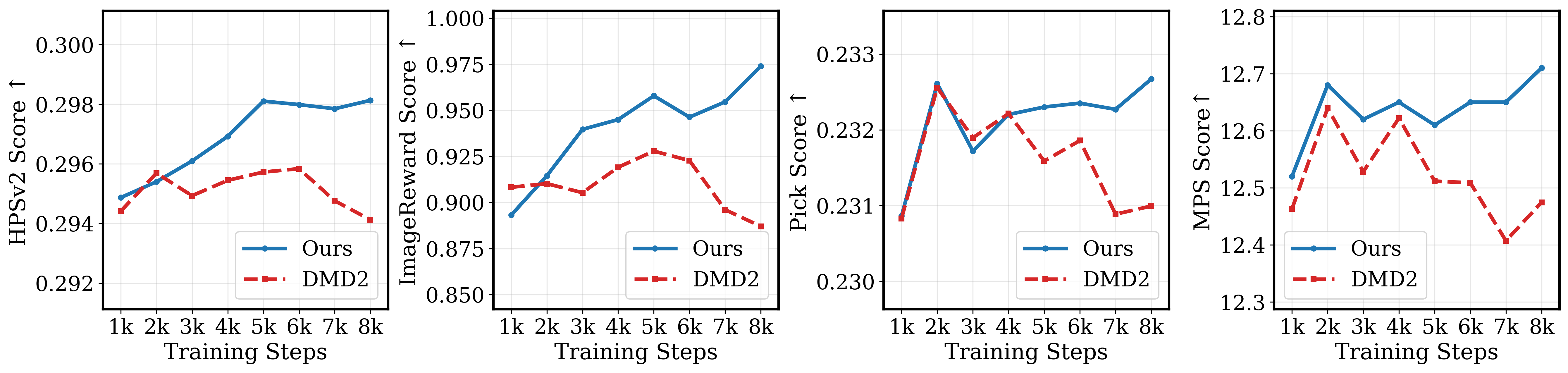
Figure 4: DMD2 vs. Flash-DMD on SDXL (TTUR=2); Flash-DMD exhibits stable quality improvements and efficient convergence over training.
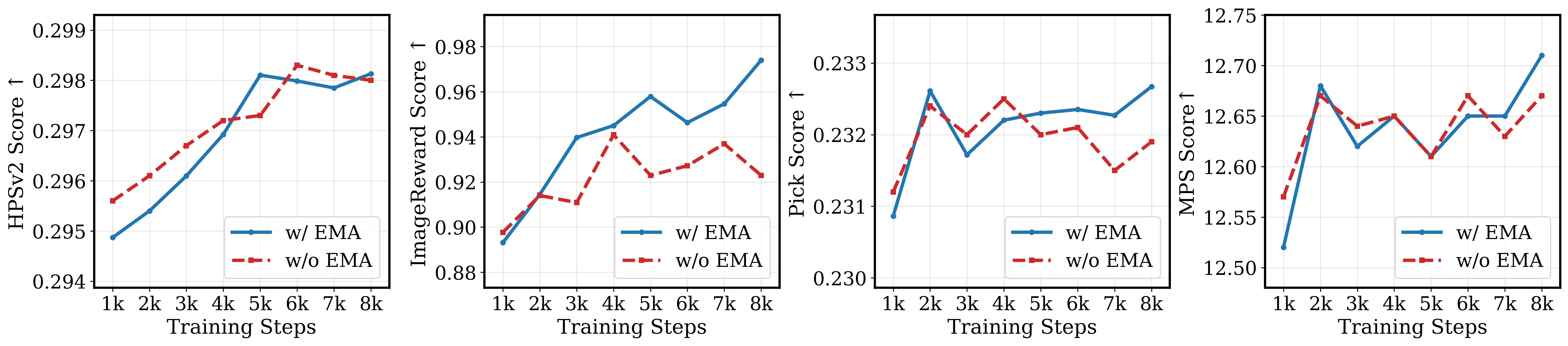
Figure 5: EMA ablation on score estimator for Flash-DMD; EMA yields consistently better preference and realism metrics during distillation.
Joint Distillation + RL: Robust Preference Optimization
- Flash-DMD achieves competitive or superior results versus Hyper-SDXL, PSO-DMD2, and LPO-SDXL baselines at a fraction of their GPU hours.
- RL performed on all timesteps versus just high-noise confirms improved sample diversity and less reward hacking when guided by the joint distillation signal.
- Online RL integrated during distillation yields better scores than post-training RL, validated across aesthetic, alignment, and MPS benchmarks.
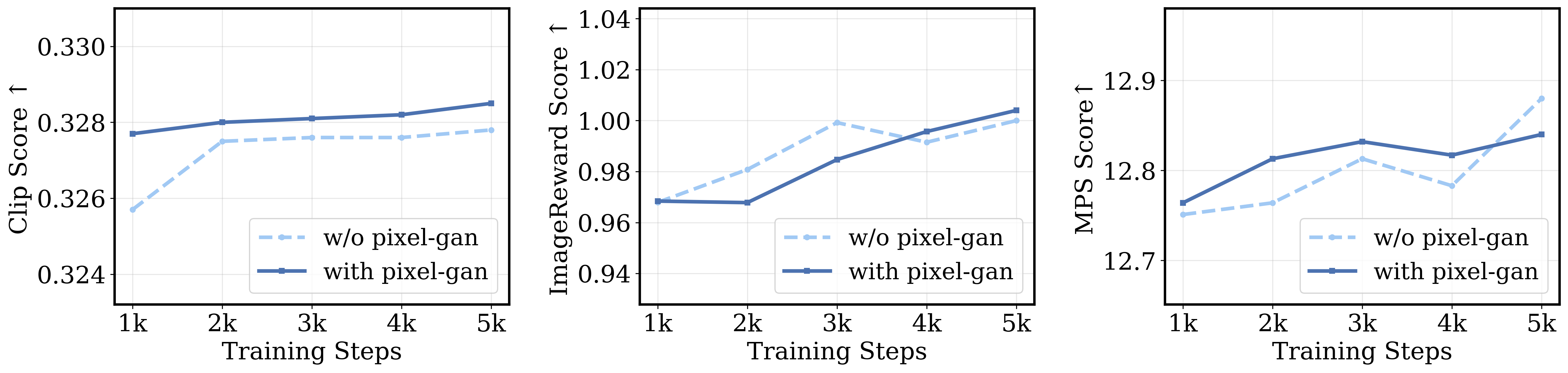
Figure 6: Reinforcement learning with/without Pixel-GAN; Pixel-GAN integration helps maintain perceptual quality through RL updates.

Figure 7: Qualitative comparisons with SOTA models; Flash-DMD outperforms in generating detailed, realistic, and preference-aligned samples.
Applications, Implications, and Future Directions
Flash-DMD establishes a resource-efficient protocol for training few-step diffusion generators with best-in-class image quality and user alignment. Its design uncouples conflicting optimization signals and demonstrates robustness against reward hacking, enabling stable application of RL preference optimization at scale.
Practical implications include:
- Democratization of high-fidelity generative modeling by lowering computational requirements.
- Real-time deployment potential for diffusion-based synthesis in interactive, mobile, and embedded settings.
- Improved generalization to new architectures, datasets, and downstream conditioning tasks (e.g., flow matching, multimodal editing).
Theoretically, the framework presents a template for joint regularized optimization regimes, where stable, interpretable objectives can anchor policy optimization in highly nonlinear or adversarial domains. Future research could extend Flash-DMD to sequential, video, or cross-modal synthesis, further explore adaptive TTUR/EMA scheduling depending on domain, and integrate foundation model-based reward estimators for broader human alignment.

Figure 8: Stage 1, 4-step Flash-DMD inference on SDXL (TTUR = 1, 1,000 steps); images show crisp details and global composition.

Figure 9: Stage 1, 4-step Flash-DMD inference on SDXL (TTUR = 2, 4,000 steps); further improvement in texture and realism.

Figure 10: Stage 2, 4-step Flash-DMD inference on SDXL post-RL optimization; refinement of visual details and preference alignment.

Figure 11: Stage 1, 8-step Flash-DMD inference on SDXL (TTUR = 2, 3,000 steps); scalable quality to additional steps.

Figure 12: Stage 2, 8-step Flash-DMD inference on SDXL post-RL optimization; preservation of detail and alignment at low latency.


Figure 13: Stage 1, 4-step Flash-DMD inference on SD3-Medium; results illustrate generalization to other architectures and datasets.
Conclusion
Flash-DMD presents a highly efficient, stable, and scalable paradigm for few-step image generation leveraging diffusion distillation and joint RL-based preference alignment. By harmonizing timestep-aware loss functions and enforcing stable score tracking, the framework surmounts longstanding challenges in speed, fidelity, and reward hacking. Comprehensive evaluations demonstrate superior sample quality, human preference alignment, and minimal resource cost across multiple architectures and metrics. This approach holds promise for broader real-time generative modeling applications and sets a new standard for the synthesis/finetuning interface in diffusion models.

