- The paper demonstrates that optimizing for point accuracy can lead to poorly calibrated uncertainty estimates across different imputation models.
- The study rigorously benchmarks statistical, matrix-based, and deep generative imputation methods using repeated runs, conditional sampling, and direct predictive outputs.
- The paper highlights that methods such as MIWAE and MICE offer distinct trade-offs between accuracy, calibration reliability, and computational efficiency, guiding safer applications.
Empirical Evaluation of Uncertainty Calibration in Imputation
Introduction and Motivation
Accurate imputation of missing data is crucial for robust statistical inference and machine learning workflows, yet traditional evaluations focus predominantly on point accuracy, neglecting the role of uncertainty estimation. The paper "Beyond Accuracy: An Empirical Study of Uncertainty Estimation in Imputation" (2511.21607) provides a rigorous comparative analysis of imputation methods that not only assess their ability to reconstruct missing values, but more importantly, examine the reliability and calibration of their associated uncertainty estimates. This is central for high-stakes domains where overconfident or miscalibrated imputations may mislead downstream analysis or critical decisions.
Imputation Methods and Uncertainty Quantification Strategies
The paper systematically benchmarks a diverse spectrum of imputation approaches, sampling from three methodological paradigms:
- Statistical regression-based (e.g., MICE)
- Matrix/optimization-based (e.g., SoftImpute, OT-Impute)
- Deep generative modeling (e.g., GAIN, MIWAE, TabCSDI)
For uncertainty estimation, the study identifies and standardizes three extraction strategies applicable across these methods:
- Repeated model runs: Captures both aleatoric and epistemic uncertainty by executing the imputation pipeline multiple times with stochasticity injected through different random seeds or data bootstraps.
- Conditional sampling: Suitable for deep generative models, allowing efficient sampling from the learned conditional distribution after a single training.
- Direct predictive distribution outputs: Where the imputer is explicitly trained to output distributional parameters (e.g., mean and variance) per cell.
These strategies are implemented for various methods as permitted by their structure (for instance, MICE supports only repeated runs, while MIWAE and GAIN support all three).
Datasets, Missingness Mechanisms, and Experimental Design
The empirical analysis leverages five numerical tabular datasets, injecting synthetic missingness according to three canonical mechanisms:
- MCAR (Missing Completely at Random)
- MAR (Missing at Random)
- MNAR (Missing Not at Random)
Rigorous control over missingness rates and mechanisms permits quantitative comparison of imputation accuracy (via MAE) and uncertainty calibration (via calibration curves and Expected Calibration Error, ECE) on ground-truth-known benchmarks.
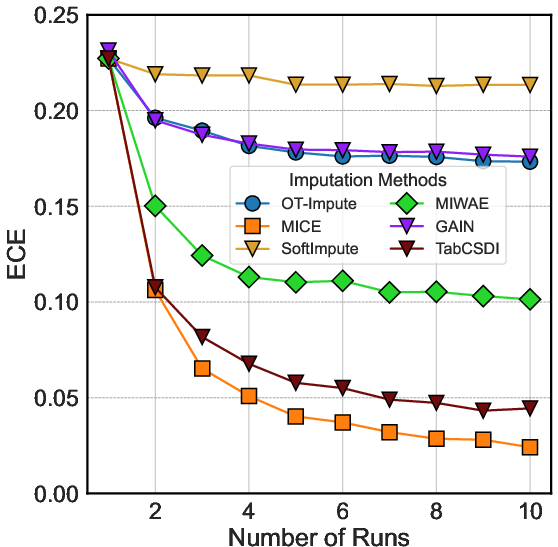
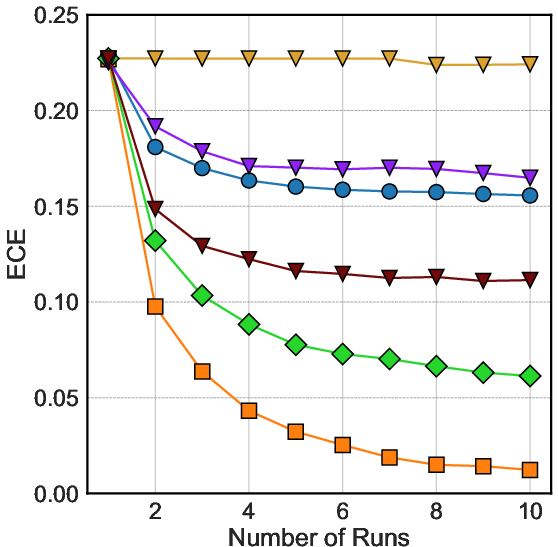
Figure 1: Calibration curves on the wine dataset reveal substantial inter-method variability in the alignment between nominal confidence and empirical coverage.
Key Quantitative Results
Imputation Accuracy
Across datasets and missingness regimes, deep generative models—especially MIWAE—frequently yield the lowest MAE, particularly under high missingness and nontrivial data correlations. Matrix completion approaches (SoftImpute, OT-Impute) are competitive on low-rank or highly-structured datasets but exhibit calibration deficiencies. GAIN displays variable performance depending on hyperparameter stability.
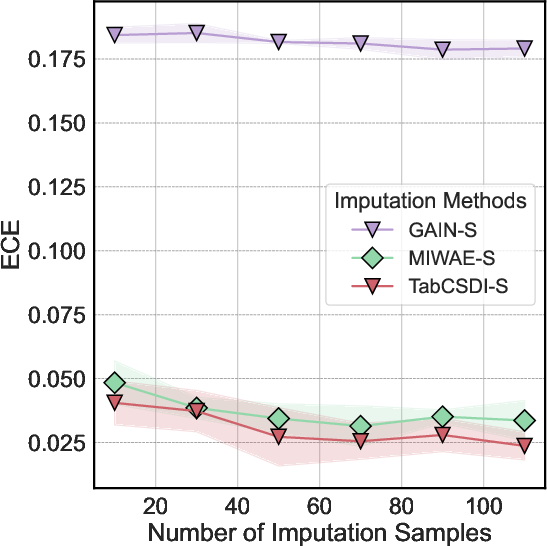
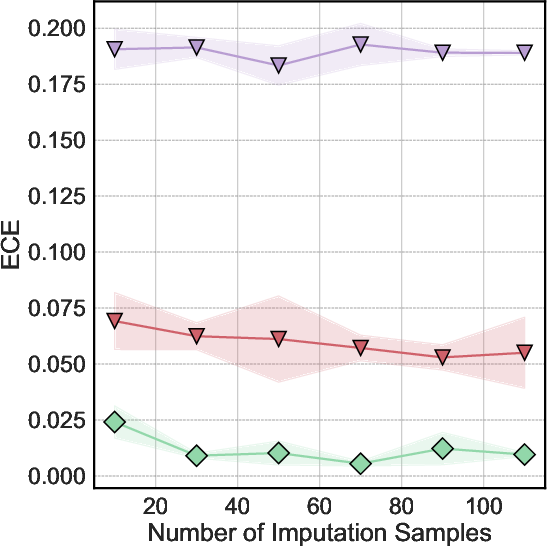
Figure 2: MAE plotted against missing rate for the wine dataset, showing monotonic error increases with missingness but divergent error curves across methods.
Uncertainty Calibration
A primary and striking finding is the systematic disassociation between reconstruction accuracy and uncertainty calibration. For instance, MICE, while often less accurate in point estimation, achieves superior calibration curves, closely aligning its nominal and empirical confidence—even under MNAR, where other methods degrade.
SoftImpute, in contrast, offers no meaningful uncertainty calibration as its determinism negates variability; any uncertainties derived post-hoc display poor empirical coverage (flat, misaligned calibration curves).
Deep generative models, especially MIWAE (and its -S/-U variants), provide well-calibrated uncertainty when trained and sampled appropriately. Calibrated intervals reflect true uncertainty and capture both model and data-driven sources of variability, as illustrated by low ECE values and near-diagonal calibration curves.
Figure 3: MIWAE-S achieves effective calibration on the wine dataset, with its empirical coverage tracking nominal levels even at higher confidence thresholds.
GAIN's uncertainty output variant (GAIN-U) occasionally matches MIWAE in calibration, but is prone to training instability, which can undermine consistency—especially evident in high-dimensional or noisy regimes.
Diffusion models (TabCSDI, TabCSDI-S) display strong calibration under favorable settings, yet their high computational cost and sensitivity on heterogeneous attributes limit broad practical adoption.
Figure 4: Visualization of ECE and calibration dynamics across imputation approaches under 30% MCAR for the wine dataset.
Computational Cost and Practical Considerations
Among classical methods, MICE stands out for computational efficiency and robust calibration, albeit with reduced point accuracy. Deep generative and diffusion-based models incur substantial costs due to both training and required sampling, making them less suitable for large-scale or low-latency use cases where rapid imputation is essential.
When targeting high-quality uncertainty estimates, repeated runs and sampling-based approaches require careful parameterization (number of runs/samples) to reconcile variance stability with tractable runtime.
Theoretical and Practical Implications
The evidence demonstrates that accuracy and calibration are generally orthogonal objectives in imputation. Practitioners optimizing solely for reconstruction error may obtain highly over- or under-confident uncertainty estimates, compromising reliability in downstream tasks. For applications such as medical diagnosis or fairness-sensitive automation, prioritizing methods that yield calibrated uncertainties—even at the expense of slight accuracy loss—is advisable.
The calibration-first framework advocated here suggests modifications to the evaluation standards of future imputation benchmarks and may inform the development of active querying or selective imputation protocols that leverage uncertainty for risk management and data prioritization.
The findings also indicate methodological directions:
- Development of uncertainty-aware objectives and loss functions for deterministic methods (e.g., augmenting matrix completion with uncertainty quantification)
- Efficient hybrid approaches that integrate strengths of deep generative modeling with classical computational efficiency
- Systematic decomposition and modeling of aleatoric vs. epistemic uncertainty, enabling finer control and interpretability
Future Directions in AI and Imputation
A promising avenue is extending this uncertainty-centric paradigm to mixed-type (categorical, ordinal) and large-scale real-world datasets, which exacerbate both modeling and calibration challenges. There is also potential impact in integrating calibrated imputation into end-to-end pipelines with fairness, interpretability, and robust decision support as primary constraints.
For AI more broadly, this work underscores the necessity of shifting from accuracy-centric metrics toward multi-criteria evaluation—including probabilistic calibration—for trustworthy deployment.
Conclusion
This study delivers the most comprehensive multi-method, multi-dataset empirical assessment of uncertainty calibration in tabular data imputation to date. The conclusion is unambiguous: reliable uncertainty is a distinct and essential facet of imputation that cannot be inferred from accuracy alone. Method selection should explicitly consider calibration, especially in safety-critical or risk-aware applications. The results and framework presented establish a new standard for rigorous evaluation and point toward data imputation as a mature subfield spanning both statistical and modern machine learning methodologies.

