Diffusion Transformers for Imputation: Statistical Efficiency and Uncertainty Quantification
Published 2 Oct 2025 in cs.LG, math.ST, stat.ML, and stat.TH | (2510.02216v1)
Abstract: Imputation methods play a critical role in enhancing the quality of practical time-series data, which often suffer from pervasive missing values. Recently, diffusion-based generative imputation methods have demonstrated remarkable success compared to autoregressive and conventional statistical approaches. Despite their empirical success, the theoretical understanding of how well diffusion-based models capture complex spatial and temporal dependencies between the missing values and observed ones remains limited. Our work addresses this gap by investigating the statistical efficiency of conditional diffusion transformers for imputation and quantifying the uncertainty in missing values. Specifically, we derive statistical sample complexity bounds based on a novel approximation theory for conditional score functions using transformers, and, through this, construct tight confidence regions for missing values. Our findings also reveal that the efficiency and accuracy of imputation are significantly influenced by the missing patterns. Furthermore, we validate these theoretical insights through simulation and propose a mixed-masking training strategy to enhance the imputation performance.
The paper introduces a transformer architecture that unrolls gradient descent to efficiently approximate the conditional score function for imputation.
It establishes non-asymptotic sample complexity bounds, detailing how missing data patterns and condition numbers impact imputation performance.
The work proposes a mixed-masking training strategy that enhances model robustness and produces well-calibrated confidence regions for uncertainty quantification.
Diffusion Transformers for Imputation: Statistical Efficiency and Uncertainty Quantification
Overview and Motivation
This paper presents a rigorous theoretical and empirical analysis of Diffusion Transformers (DiT) for time series imputation, focusing on statistical efficiency and uncertainty quantification. The work addresses two central questions: (1) how well can diffusion models capture the conditional distribution of missing values, and (2) how do missing patterns affect imputation performance. The analysis is grounded in the context of Gaussian process (GP) data, which provides a tractable yet expressive framework for modeling spatio-temporal dependencies.
Problem Formulation and Conditional Diffusion Modeling
The imputation task is formalized as conditional distribution estimation: given observed entries $\xb_{\rm obs}$ of a multivariate time series, infer the distribution of missing entries $\xb_{\rm miss}$. For GP data, the conditional distribution $P(\xb_{\rm miss}|\xb_{\rm obs})$ is Gaussian, with closed-form expressions for the conditional mean and covariance. The paper leverages this structure to analyze the learning and approximation properties of DiT architectures.
Diffusion models are trained to estimate the conditional score function $\nabla \log p_t(\vb_t|\xb_{\rm obs})$, which governs the reverse-time SDE for sample generation. The score function for the GP case is a linear function involving matrix inverses of conditional covariance components, which presents challenges for neural network approximation.
Transformer-Based Score Approximation via Algorithm Unrolling
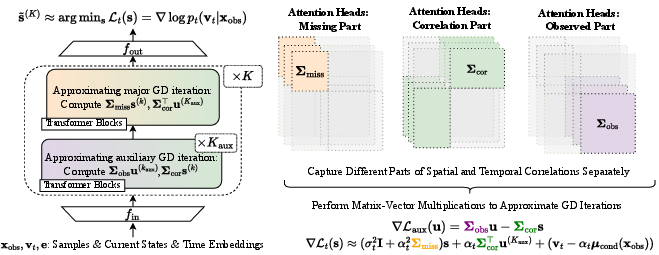
A key technical contribution is the construction of a transformer architecture that efficiently approximates the conditional score function by unrolling a nested gradient descent algorithm. The outer loop solves for the score via quadratic optimization, while the inner loop approximates matrix-vector products involving covariance inverses. The architecture is designed so that each transformer block corresponds to a gradient descent iteration, with attention heads capturing different covariance components.
Figure 1: Within each transformer block, attention heads focus on different covariance components, enabling efficient approximation of matrix-vector multiplications required for score estimation.
Theoretical analysis yields explicit bounds on the representation error as a function of the number of gradient steps and the condition numbers of the covariance matrices. The transformer size and depth scale polynomially with the worst-case condition number, which is determined by the missing pattern.
Statistical Efficiency and Sample Complexity
The paper establishes non-asymptotic sample complexity bounds for learning the conditional distribution with DiT. The main result shows that the total variation distance between the learned and true conditional distributions scales as O~(Hd2κ5/n), where H is sequence length, d is feature dimension, κ is the condition number of the conditional covariance, and n is the number of training samples. The convergence rate is n−1/2, with mild polynomial dependence on H and strong dependence on κ.
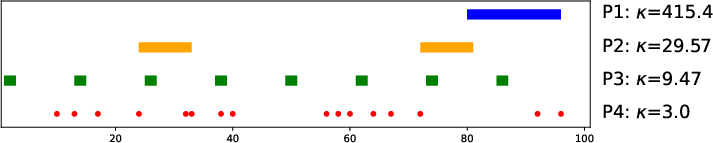
The analysis reveals that clustered missing patterns (e.g., consecutive missing blocks) induce large condition numbers, making the imputation task statistically harder. In contrast, dispersed missing patterns yield smaller condition numbers and require fewer samples for accurate estimation.
Figure 2: Visualization of four missing patterns and their associated condition numbers, illustrating the impact of missingness structure on statistical difficulty.
Uncertainty Quantification and Confidence Region Construction
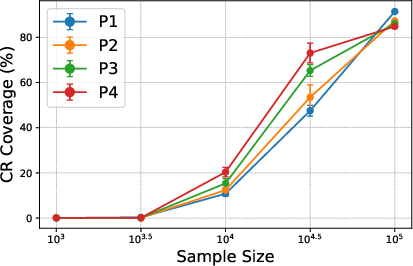
Leveraging the generative nature of DiT, the paper proposes a method for constructing confidence regions (CRs) for imputed values by sampling from the learned conditional distribution. Theoretical guarantees are provided for the coverage probability of these CRs, showing convergence to the nominal level at the same rate as distribution estimation. The coverage is sensitive to both the missing pattern and the distribution shift between training and test observed values.
Empirical results demonstrate that DiT-generated CRs achieve coverage rates close to the desired level, with performance degrading as sequence length increases or missing patterns become more clustered.
Figure 3: Percentage of real data samples falling within the DiT-generated 95% confidence region, and coverage rates as a function of sequence length and missing pattern.
Mixed-Masking Training Strategy
To mitigate the impact of distribution shift and improve robustness, the paper introduces a mixed-masking training strategy. Instead of training on fully random masks, the strategy samples a diverse set of missing patterns during training, including both easy (dispersed) and hard (clustered) cases. Empirical results show that mixed-masking consistently improves both point estimation and uncertainty quantification, outperforming models trained on single-pattern masks.
Empirical Validation
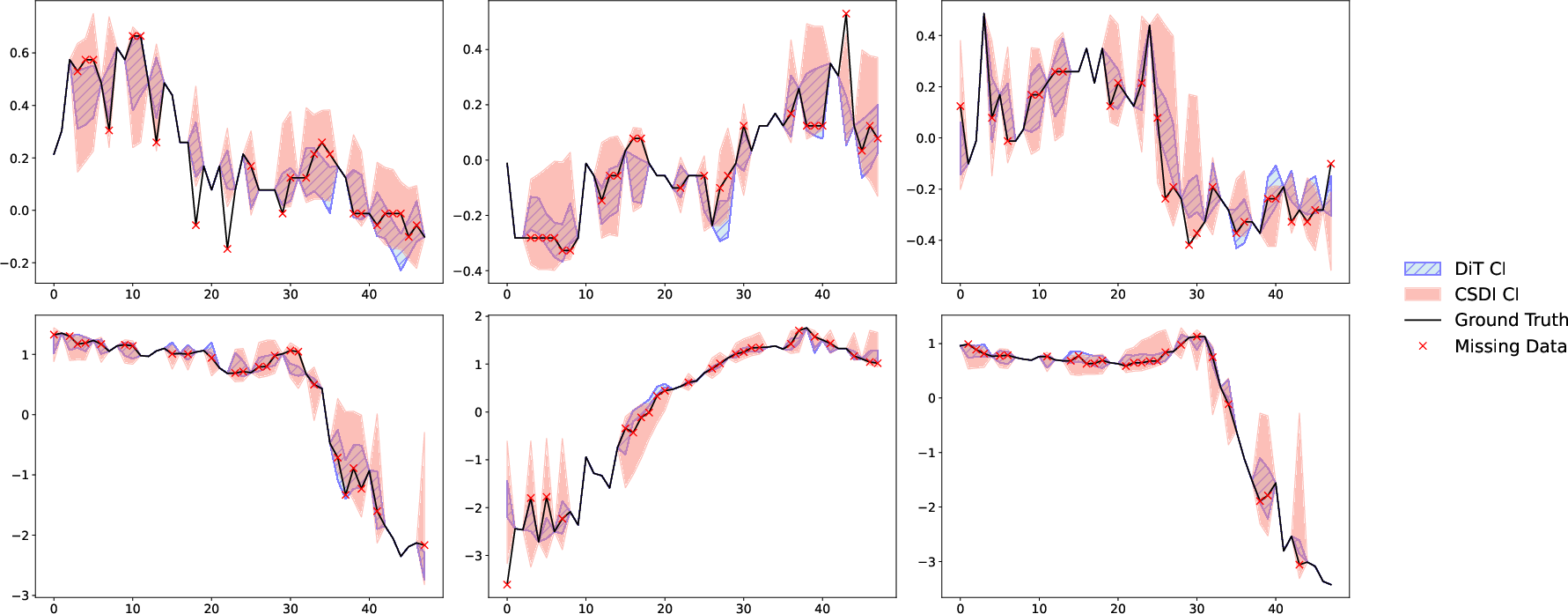
Experiments on synthetic GP data and nonlinear latent GP transformations validate the theoretical findings. DiT outperforms baseline generative imputation models (CSDI, GPVAE) in both mean squared error and CR coverage, especially when trained with mixed-masking. The results generalize to real-world datasets (e.g., air quality, electricity consumption), where DiT achieves lower imputation error and tighter, well-calibrated confidence regions.
Figure 4: Comparison of imputation methods on the Electricity dataset, showing DiT's tighter and more accurate confidence regions.
Implementation Considerations
Architecture: The transformer should be sized according to the worst-case condition number induced by the masking strategy. For long sequences or high-dimensional data, careful regularization and early stopping are necessary to avoid overfitting and instability.
Training: Mixed-masking is essential for robustness. The optimal mixing ratio is data-dependent and may require validation on held-out patterns.
Computational Requirements: The nested gradient descent unrolling increases depth, but the polynomial scaling is manageable for moderate H and d. Attention heads should be allocated to capture covariance structure efficiently.
Deployment: For uncertainty quantification, generate multiple samples per imputation and construct empirical confidence regions. Monitor coverage rates and recalibrate if necessary.
Implications and Future Directions
The results provide a principled foundation for using diffusion transformers in time series imputation, with explicit guidance on architecture design, training strategies, and uncertainty quantification. The dependence on missing pattern structure highlights the need for adaptive masking and model selection in practical deployments. Future work should extend the analysis to heavy-tailed and non-Gaussian time series, and develop automated methods for optimal masking strategy selection.
Conclusion
This paper delivers a comprehensive theoretical and empirical framework for diffusion transformer-based time series imputation, elucidating the interplay between model architecture, missing pattern structure, statistical efficiency, and uncertainty quantification. The mixed-masking training strategy is shown to be critical for robust performance. The findings have direct implications for the design and deployment of imputation systems in domains where missing data and uncertainty are pervasive.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.