- The paper introduces HuMo, a unified framework that leverages collaborative multi-modal conditioning to overcome limitations in text editability, subject flexibility, and audio-visual sync.
- It employs a progressive two-stage training paradigm with minimal-invasive reference injection and a focus-by-predicting strategy, enhancing identity preservation and lip synchronization.
- Extensive experiments and ablation studies demonstrate superior performance in aesthetics, text adherence, and sync metrics, setting a robust foundation for future AI-driven video synthesis research.
HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
Introduction and Motivation
The paper introduces HuMo, a unified framework for Human-Centric Video Generation (HCVG) that leverages collaborative multi-modal conditioning across text, image, and audio inputs. The motivation stems from the limitations of prior HCVG methods, which either rely on subject-complete start frames (restricting text editability and subject flexibility) or fail to integrate audio-driven articulation, thus lacking synchronized lip movements and speech control. HuMo addresses two core challenges: the scarcity of high-quality, triplet-paired multimodal datasets and the difficulty of achieving balanced, collaborative control across modalities without compromising subject preservation, text adherence, or audio-visual sync.

Figure 1: HuMo supports flexible input compositions (text-image, text-audio, text-image-audio) and generalizes to humans, objects, stylized artworks, and animations.

Figure 2: Comparison of prior HCVG methods, highlighting HuMo's superior collaborative performance in video quality, subject consistency, audio-visual sync, and text controllability.
Multimodal Data Processing Pipeline
HuMo's data pipeline is designed to construct a high-quality, diverse dataset with paired text, reference images, and audio. The pipeline operates in two stages:
- Stage 1: Starting from large-scale text-video samples, reference images are retrieved from a billion-scale corpus using detection, matching, and verification to ensure semantic alignment but visual diversity. This discourages direct frame replication and enhances text editability.
- Stage 2: Audio modality is incorporated by filtering for speech segments and performing lip-sync analysis, resulting in tightly aligned audio-visual pairs.
This pipeline yields a dataset with O(1)M video samples for text-image pairs and O(50)K samples for text-image-audio triplets, enabling robust multimodal training.
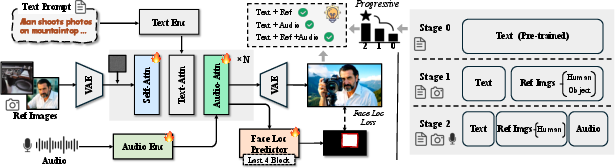
Figure 3: HuMo's framework overview, showing the DiT-based backbone and progressive learning of subject preservation and audio-visual sync via the data processing pipeline.
Progressive Multimodal Training Paradigm
HuMo employs a two-stage progressive training paradigm:
- Stage 1: Subject Preservation Task
- Reference images are injected minimally invasively by concatenating VAE latents at the end of the video latent sequence.
- Only self-attention layers are updated, preserving the DiT backbone's text-image alignment and synthesis capabilities.
- This design prevents the model from treating the reference as a start frame, instead propagating identity information via self-attention.
- Stage 2: Audio-Visual Sync Task
- Audio features (extracted via Whisper) are incorporated using cross-attention layers in each DiT block.
- A focus-by-predicting strategy is introduced: a mask predictor estimates facial regions, supervised by ground-truth masks with a size-aware BCE loss. This soft regularization steers attention to facial regions for improved lip sync without hard gating, preserving flexibility for full-body and complex interactions.
- Progressive Task Weighting: Training begins with an 80/20 split favoring subject preservation, gradually shifting to 50/50 as audio-visual sync capabilities mature. Only self-attention and audio modules are updated throughout.
Inference: Flexible and Fine-Grained Multimodal Control
HuMo introduces a time-adaptive Classifier-Free Guidance (CFG) strategy for inference, enabling dynamic adjustment of guidance strengths for text, image, and audio modalities at different denoising steps. Early steps prioritize text/image for semantic layout, while later steps emphasize audio/image for fine-grained details and sync.

Figure 4: Time-adaptive CFG balances text guidance and identity preservation during denoising.
Experimental Results
Subject Preservation
Qualitative and quantitative evaluations demonstrate HuMo's superiority in text following, subject consistency, and visual quality. HuMo maintains multiple distinct identities and accurately follows prompts, outperforming baselines in aesthetics (AES), image quality (IQA), human structure plausibility (HSP), and identity similarity metrics.

Figure 5: Qualitative comparison for subject preservation, showing HuMo's superior identity maintenance and text adherence.
Audio-Visual Sync
HuMo achieves high scores in audio-visual sync (Sync-C, Sync-D), text following, and identity similarity, surpassing specialized open-source models and closely matching commercial systems. The model's ability to synthesize specific details (e.g., "silver guitar", "golden light") and maintain clear facial identity under challenging conditions is highlighted.

Figure 6: Qualitative comparison for audio-visual sync, demonstrating HuMo's precise lip movement and semantic control.
Ablation Studies
Ablation experiments confirm the necessity of minimal-invasive finetuning, progressive training, and focus-by-predicting for optimal performance. Removing these components degrades video quality, text alignment, identity consistency, and lip sync.

Figure 7: Qualitative ablation study illustrating the impact of training and inference strategies.
Controllability Analysis
HuMo enables collaborative text-image controllability: varying text prompts with the same reference image alters appearance while preserving identity. The framework also supports movie-level customization, as demonstrated by re-creating scenes from "Game of Thrones" with different reference identities and input modalities.

Figure 8: Collaborative text-image controllability with consistent identity and variable appearance.

Figure 9: Movie-level re-creation using text-audio and text-image-audio modes, integrating reference identity into new semantic contexts.
Implications and Future Directions
HuMo establishes a scalable, unified approach for multimodal video generation, supporting flexible input compositions and fine-grained control. The framework's progressive training and time-adaptive inference strategies set a precedent for balancing heterogeneous modalities without sacrificing individual capabilities. The release of the multimodal dataset will facilitate reproducibility and further research in controllable video synthesis.
Potential future developments include:
- Extension to longer-form content and higher-resolution outputs.
- Integration of additional modalities (e.g., gesture, scene context).
- Exploration of more sophisticated attention mechanisms for improved cross-modal alignment.
- Addressing ethical concerns related to deepfake generation and non-consensual content, with emphasis on transparency and responsible deployment.
Conclusion
HuMo presents a comprehensive solution for human-centric video generation with collaborative multi-modal conditioning. Through a carefully designed data pipeline, progressive training paradigm, and adaptive inference strategy, HuMo achieves state-of-the-art performance in subject preservation, text adherence, and audio-visual sync. The framework's flexibility and scalability position it as a robust foundation for future research and practical applications in AI-driven video synthesis.