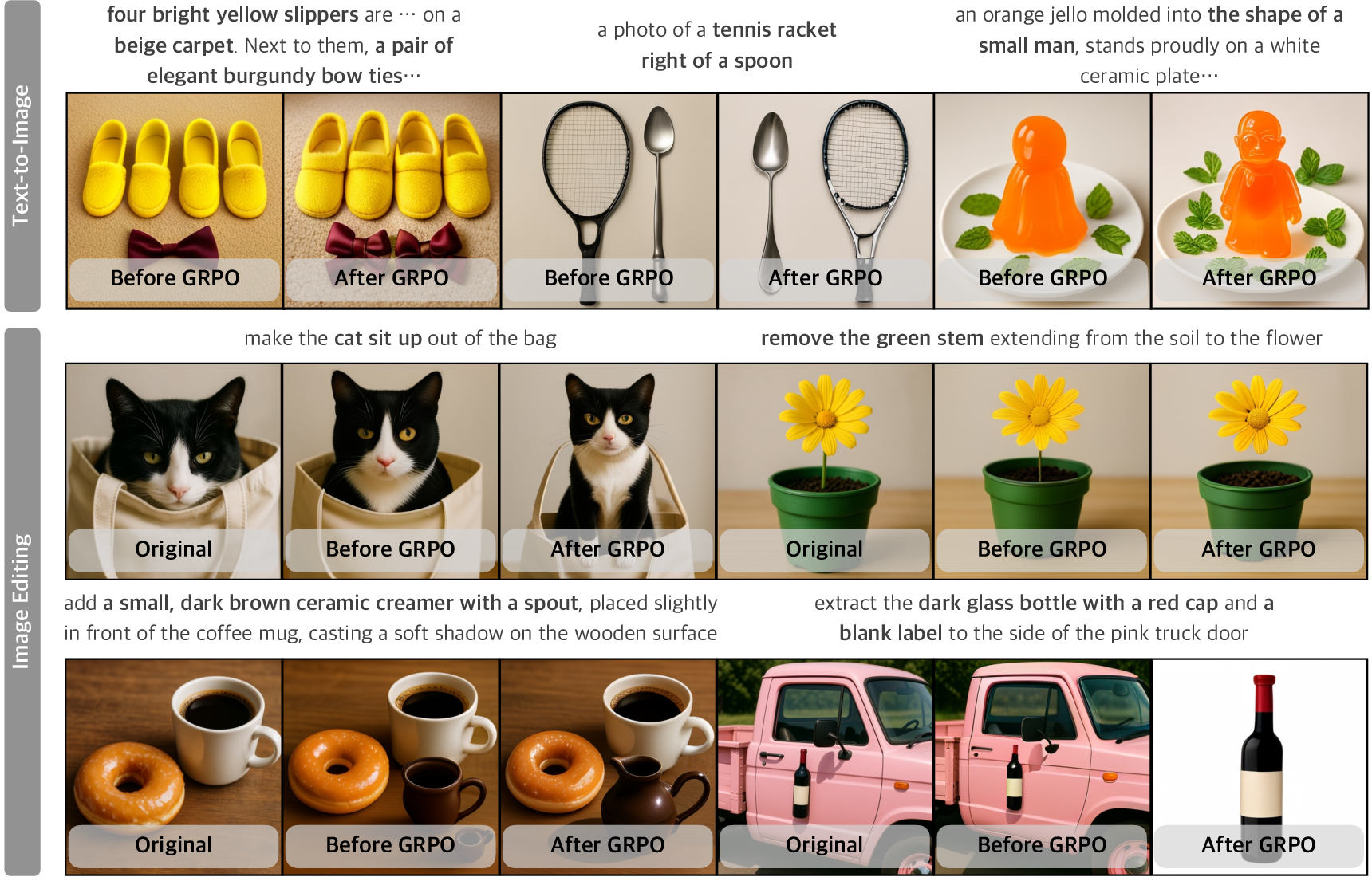
- The paper presents a novel RL-based framework unifying image generation and editing via reward unification, achieving improved semantic fidelity and controllability.
- The methodology integrates both discrete and continuous visual tokenizers with an Edit Instruction Alignment stage to optimize semantic and low-level features.
- Empirical results demonstrate state-of-the-art performance in text-to-image generation and image editing, highlighting significant advances in multimodal tasks.
UniGen-1.5: Reward Unification for Unified Image Generation and Editing via Reinforcement Learning
Introduction and Motivation
UniGen-1.5 introduces a unified multimodal LLM (MLLM) capable of image understanding, text-to-image generation, and fine-grained image editing. The model is built upon the UniGen framework, emphasizing architectural expansion and post-training strategies specifically designed for image editing and high-fidelity generation. The key innovation lies in formulating both generation and editing as RL tasks and leveraging a shared reward model, which systematically improves semantic fidelity and controllability across tasks. The model further incorporates an Edit Instruction Alignment post-SFT stage to optimize comprehension of complex editing instructions, addressing a documented bottleneck in prior MLLMs.
Model Architecture
UniGen-1.5 employs Qwen2.5-7B as the backbone LLM, with visual tokenization handled by discrete (MAGViTv2) and continuous (SigLIP2) encoders. The architecture supports three modalities:
- Image Understanding: SigLIP2 encodes variable-sized images to continuous tokens, facilitating semantic reasoning by aligning visual and text embeddings before next-token prediction.
- Text-to-Image Generation: The model uses masked token prediction, encoding images into discrete tokens via MAGViTv2. Token masks are sampled per schedulers, and the LLM reconstitutes masked tokens from a conditional text prompt. Reconstruction proceeds autoregressively.
- Image Editing: Both encoders extract semantic and low-level features from a condition image. The LLM concatenates these with edit instruction text embedding and autoregressively generates discrete tokens for the edited output.
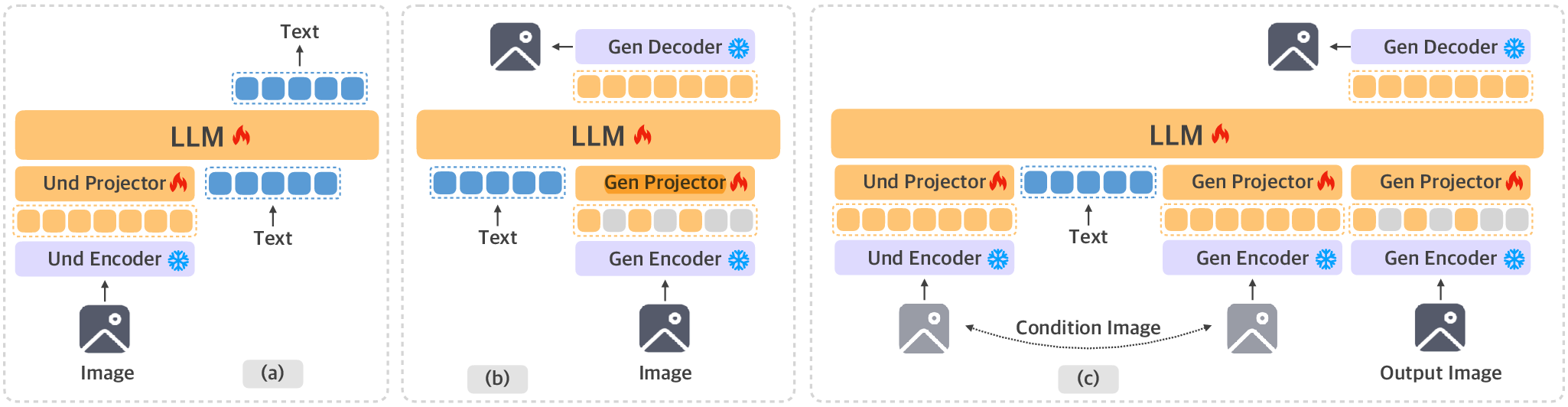
Figure 1: UniGen-1.5 architecture supporting image understanding, text-to-image generation, and image editing under a unified tokenization schema.
Training Pipeline and RL Unification
Pre-training and Supervised Fine-Tuning
Pre-training sources millions of curated image-text pairs, with frozen visual tokenizers. Joint SFT leverages synthetic data from models like GPT-4o and BLIP-3o and includes image editing samples from GPT-Image-Edit-1.5M. Understanding tasks use high-resolution samples with token-efficient resizing.
Edit Instruction Alignment
After SFT, UniGen-1.5 undergoes Edit Instruction Alignment—a light post-training step optimizing the mapping between edit instructions and the semantic content of target images. This is achieved by predicting output captions given condition images and edit instructions, enhancing RL learning signals for editing tasks with improved instruction fidelity.
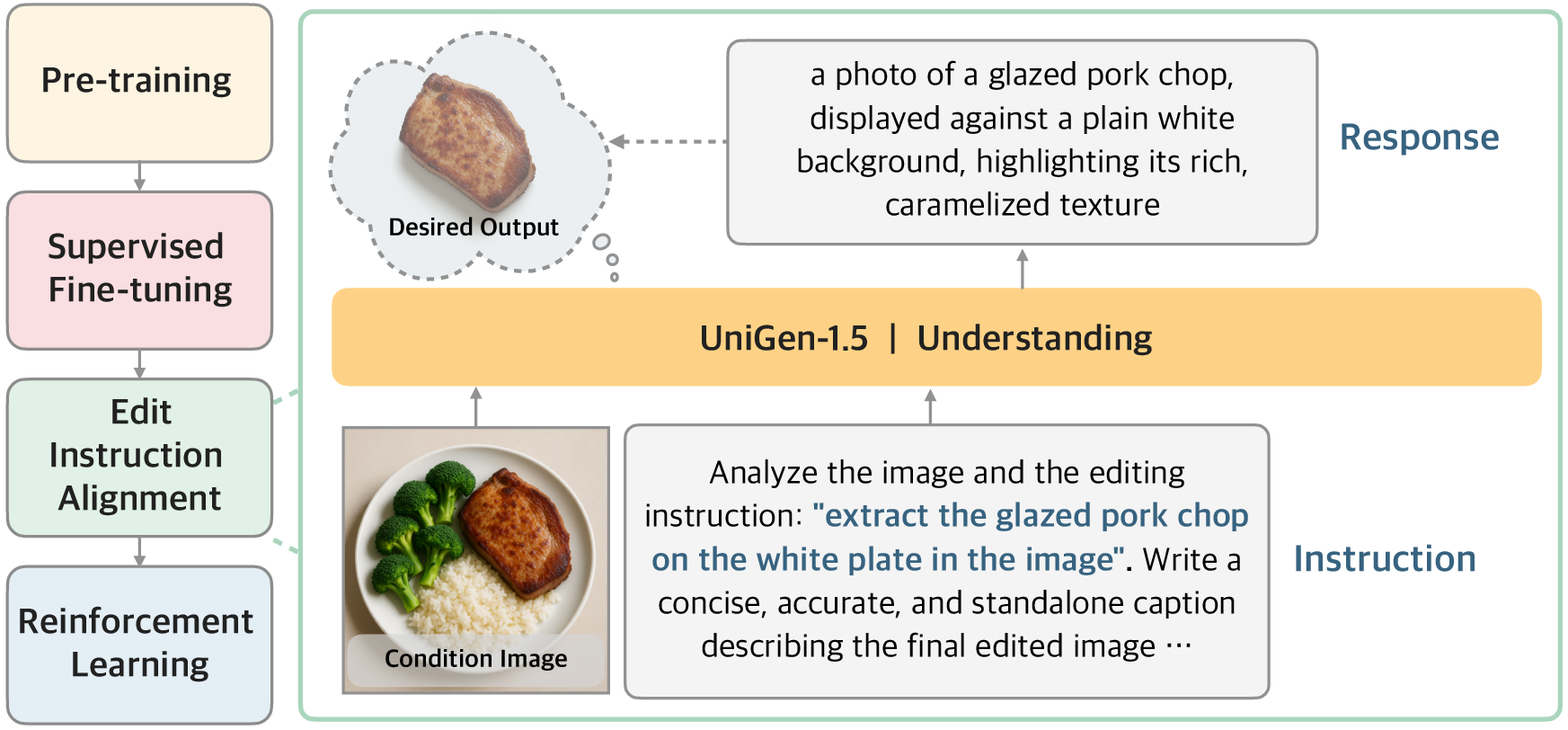
Figure 2: Edit Instruction Alignment process in UniGen-1.5's training pipeline for enhanced instruction comprehension.
Reinforcement Learning: Group Relative Policy Optimization
UniGen-1.5's visual generation and editing RL are unified via GRPO, which employs shared reward models to evaluate either generated or edited images with respect to corresponding textual descriptions. For both generation and editing, the reward function measures semantic alignment between image outputs and their textual specifications—using ground-truth prompts for generation and expert-synthesized captions for editing.
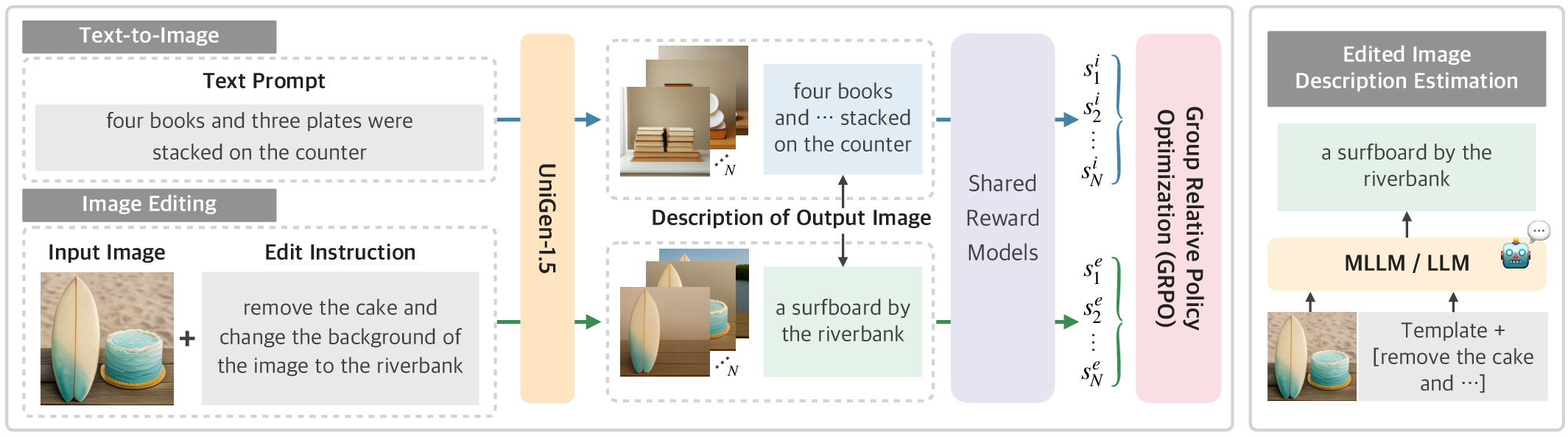
Figure 3: GRPO pipeline of UniGen-1.5: shared reward models enable RL for text-to-image generation and image editing; right, pipeline for synthesized edited image descriptions.
Rewards are computed using an ensemble of vision and semantic experts: CLIP-H for image-text similarity, HPSv2 for aesthetic alignment, Unified-Reward-7B for fine-grained consistency, and ORM for outcome verification. RL trains with multiple candidate generations per input, normalizing reward advantages across batches.
Empirical Results
UniGen-1.5 significantly advances state-of-the-art in unified MLLM benchmarks, yielding strong numerical results:
Ablations highlight the necessity of unified RL (jointly optimizing generation and editing yields the highest scores) and Edit Instruction Alignment (crucial for extracting robust RL signals in editing tasks). Architectural experiments demonstrate optimal design wherein semantic and low-level visual features are properly ordered for editing.
Limitations and Failure Modes
Although UniGen-1.5 excels in semantic alignment, it fails in rendering text characters within images or maintaining perfect visual consistency during editing (e.g., identity shifts in facial texture or color across edits). These limitations arise from the model's discrete token reconstruction and reliance on a lightweight visual detokenizer; diffusion-based refinement may alleviate this. Additionally, editing-specific reward modeling remains an open challenge for improving visual consistency.

Figure 5: Failure cases demonstrating UniGen-1.5's limitations in text rendering and identity preservation during editing.
Implications and Future Directions
UniGen-1.5 establishes an extensible baseline for joint image understanding, generation, and editing in unified MLLMs. By reformulating editing as generation within an RL schema, it opens avenues for scalable training via shared semantics and reward functions, reducing annotation cost and improving data efficiency. The approach demonstrates that bridging understanding and controllable generation/editing under RL yields substantial performance benefits. Future work should investigate hybrid AR-diffusion architectures, dedicated visual consistency rewards, and scaling tokenization strategies to address fine-grained structural fidelity and general edit reliability.
Conclusion
UniGen-1.5 advances unified MLLM research through principled reward unification and RL-driven optimization of joint image generation and editing. Its architecture, augmented by Edit Instruction Alignment, demonstrates strong controllability, semantic alignment, and utility across generation, editing, and understanding—suggesting unified RL strategies as a promising direction for multimodal intelligence advancement.
Reference: "UniGen-1.5: Enhancing Image Generation and Editing through Reward Unification in Reinforcement Learning" (2511.14760).