- The paper introduces an end-to-end image-to-G-code system that bypasses traditional CAD modeling and rule-based slicing in additive manufacturing.
- It employs a frozen DinoV2 visual encoder with a U-Net DDPM backbone to fuse geometric features and generate accurate G-code trajectories.
- Experimental results demonstrate efficient, diverse toolpaths with a 2.40% reduced mean travel distance and robust performance on both synthetic and real-world inputs.
End-to-End Image-to-G-code Generation for Additive Manufacturing
Introduction and Motivation
Additive manufacturing (AM), particularly material extrusion (MEX), is bottlenecked by a labor-intensive CAD-to-G-code workflow requiring significant expertise and repeated manual intervention. The reliance on explicit 3D CAD modeling and rule-based slicing presents scaling disadvantages in rapid prototyping, customized small-batch production, and educational environments. Existing machine learning approaches that generate intermediate generation models (VAEs, GANs) suffer from fidelity and stability limitations, while even successful image-based DDPM methods cannot directly map visual input to manufacturing instructions without decomposition into multiple stages. This paper introduces Image2Gcode, an end-to-end system that generates printer-ready G-code toolpaths directly from images or sketches, bypassing CAD and intermediate mesh representations entirely.
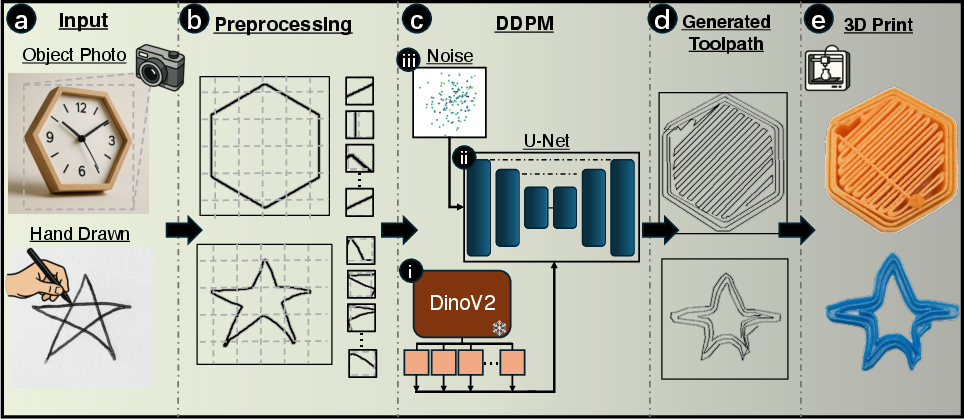
Figure 1: Overview of the Image2Gcode pipeline from (a) image/sketch input through (b) geometric boundary extraction, (c) DDPM-based denoising sequence generation, to (d) G-code trajectory prediction and (e) physical fabrication.
Methodological Advances
Dataset and Preprocessing
Image2Gcode leverages the Slice-100K dataset, consisting of 100,000 aligned STL-G-code pairs, to frame the learning task at the per-layer slice level. Each slice is preprocessed to extract spatial (X,Y) and extrusion E channels, normalized to [−1,1], and padded or truncated to a fixed length. The G-code parsing ensures consistent coordinate systems and precise synchronization between image-based slice rendering and toolpath trajectory extraction.
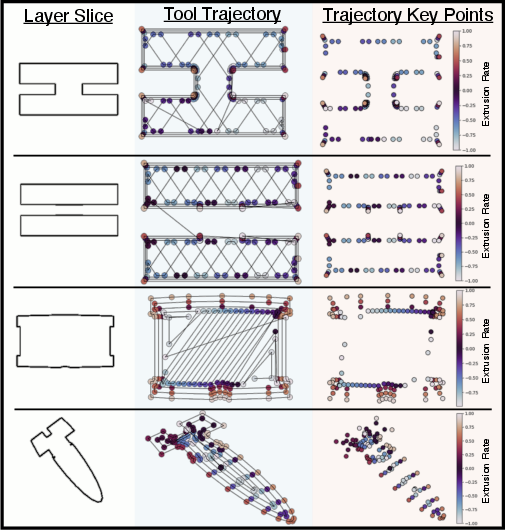
Figure 2: Visualization of slice-level training pairs highlighting (X,Y) and normalized E values extracted from toolpaths to capture spatial and material deposition characteristics.
Model Architecture
The framework comprises a frozen DinoV2 transformer-based visual encoder for multi-scale geometric feature extraction and a 1D U-Net DDPM sequence generator. The U-Net incorporates cross-attention blocks for hierarchical fusion between visual context and trajectory sequences across all resolution levels. This architectural choice ensures both global and local geometric dependencies are encoded in the synthesized G-code.
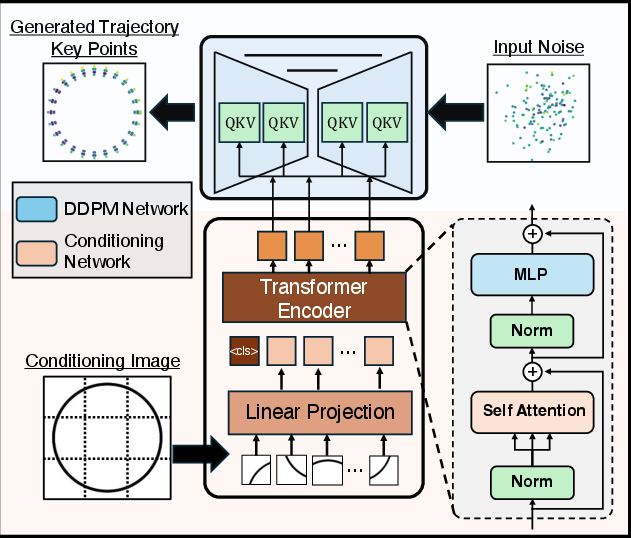
Figure 3: Schematic of the conditioning network (DinoV2-based) and DDPM denoising network with cross-attention mechanisms for trajectory synthesis.
During inference, trajectories are sampled via iterative denoising from Gaussian noise across 500 steps, yielding discrete (X,Y,E) sequences which are denormalized and converted to printer-agnostic G-code instructions. Feedrate and initialization codes are appended using standard validation checks to generate executable toolpaths.
Experimental Results
Generation Quality
Qualitative evaluation on the held-out Slice-100K validation split demonstrates structural coherence in generated toolpaths, accurate boundary reconstruction, and infill pattern selection that is both compatible with manufacturing constraints and diverse across geometric primitives. Physical part prints exhibit dimensional fidelity, surface quality, and manufacturability without layer delamination or extrusion failures.
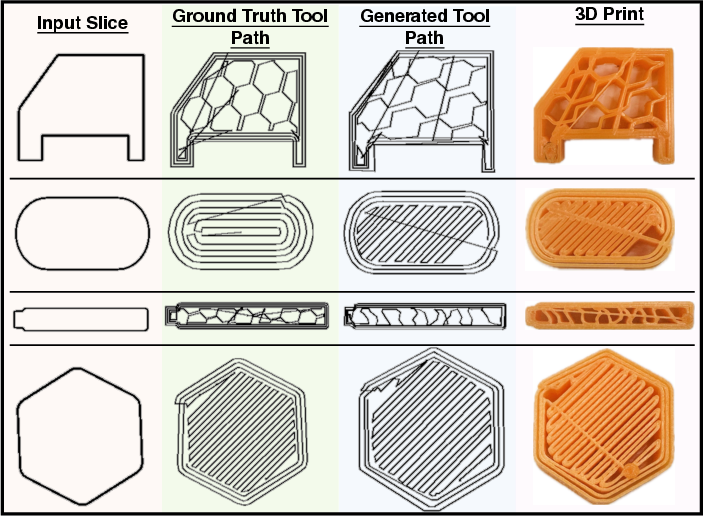
Figure 4: Generated toolpaths and corresponding physical prints validating accuracy and manufacturability across diverse shapes and infill architectures.
Generalization Beyond Training Distribution
Robustness to real-world input is established via testing on photographs and hand-drawn sketches, with preprocessing extracting boundary geometry enabling seamless toolpath generation even under significant domain shifts from synthetic training data. Physical fabrication confirms the manufacturability and fidelity of outputs from a variety of input modalities.
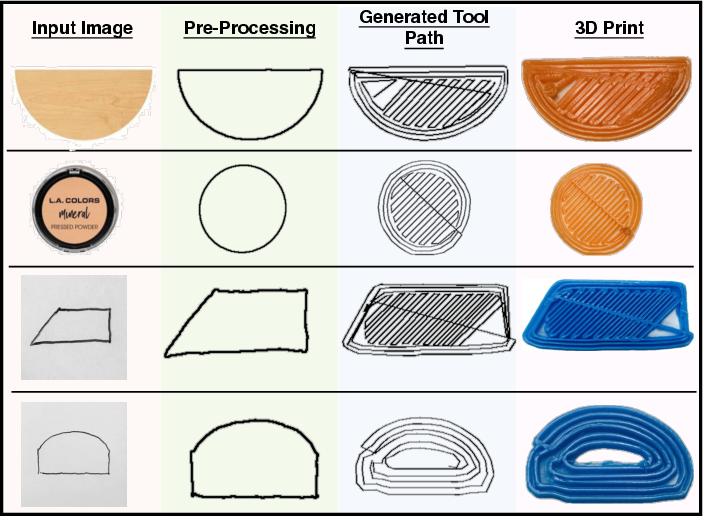
Figure 5: Results demonstrating generalization capability to both real object photographs and hand-drawn sketches, enabling direct concept-to-part workflows.
Diversity in Learned Distributions
The DDPM backbone enables stochastic sampling yielding valid but topologically distinct infill strategies for identical boundary inputs. Comparative visualizations reveal generated distributions that span diagonal hatching, mixed infill, and non-concentric architectures, evidencing learning beyond mere memorization of training exemplars.
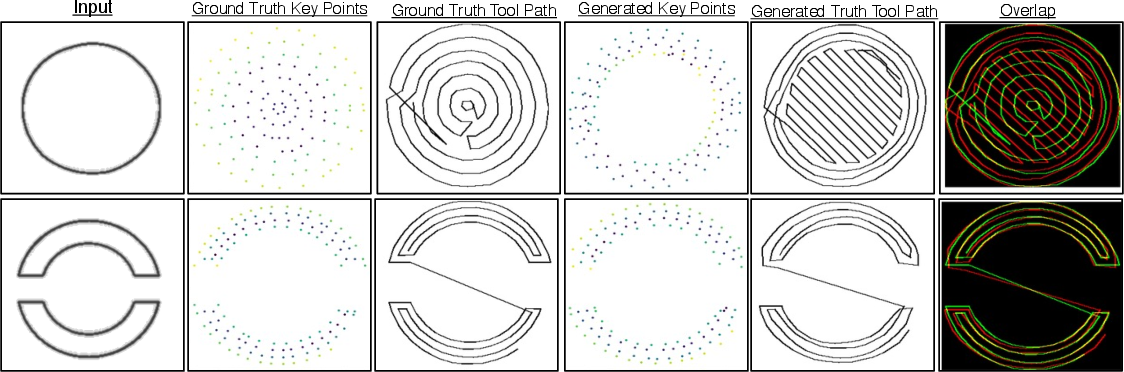
Figure 6: Side-by-side comparison of ground truth versus generated infill patterns, with overlap highlighting alternative yet structurally valid approaches.
Travel distance analysis reveals a statistically significant 2.40% reduction in mean travel distance for generated toolpaths relative to heuristic slicer outputs, with high consistency across multiple runs. This points towards emergent path planning efficiency as part of the learned optimization metric.
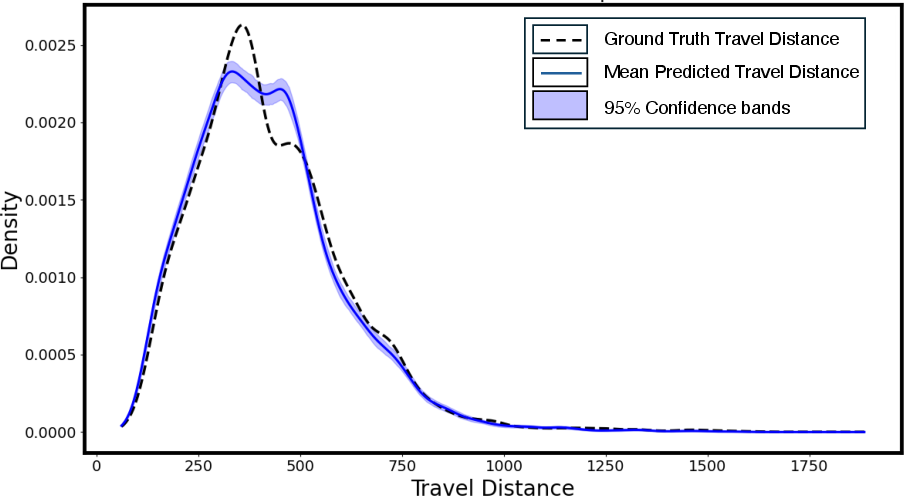
Figure 7: Kernel density estimation showing reduction in travel distances for synthetic toolpaths compared to baselines, demonstrating efficient learning.
Limitations and Prospects
The current slice-based decomposition restricts applicability to pseudo-2D objects and cannot fully encode inter-layer constraints or topology-altering features present in complex 3D parts. Fidelity declines for geometries with extreme variation or resolution. Future work should extend architectures to hierarchical generation pipelines interfacing with coarse 3D primitives and propagate conditioning signals for explicit control over infill, mechanical response, or material constraints. Integration of volumetric context or depth cues will be essential for end-to-end full-object toolpath synthesis. Further, coupling with LLM-driven manufacturing agents promises high-level, intent-aware system integration for adaptive and autonomous fabrication planning.
Conclusion
Image2Gcode establishes a data-driven, end-to-end method for direct image-to-G-code generation in MEX additive manufacturing, eliminating CAD dependencies and procedural slicing. Its DDPM-Transformer construction enables robust visual-to-toolpath mapping, generalizes to non-synthetic input modalities, and yields physically validated, efficient, and diverse manufacturing instructions. These advances lower AM entry barriers and facilitate rapid, scalable prototyping and design iteration. Future research should address architectural extensions for volumetric complexity, multi-objective conditioning, and tight integration with autonomous process control in AI-driven manufacturing pipelines.
Reference:
"Image2Gcode: Image-to-G-code Generation for Additive Manufacturing Using Diffusion-Transformer Model" (2511.20636)

