SAM 3: Segment Anything with Concepts
Abstract: We present Segment Anything Model (SAM) 3, a unified model that detects, segments, and tracks objects in images and videos based on concept prompts, which we define as either short noun phrases (e.g., "yellow school bus"), image exemplars, or a combination of both. Promptable Concept Segmentation (PCS) takes such prompts and returns segmentation masks and unique identities for all matching object instances. To advance PCS, we build a scalable data engine that produces a high-quality dataset with 4M unique concept labels, including hard negatives, across images and videos. Our model consists of an image-level detector and a memory-based video tracker that share a single backbone. Recognition and localization are decoupled with a presence head, which boosts detection accuracy. SAM 3 doubles the accuracy of existing systems in both image and video PCS, and improves previous SAM capabilities on visual segmentation tasks. We open source SAM 3 along with our new Segment Anything with Concepts (SA-Co) benchmark for promptable concept segmentation.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces SAM 3, a powerful AI system that can “find and cut out” things in pictures and videos just by being told what to look for. You can tell it a short phrase like “yellow school bus” or show it an example box around one bus, and it will highlight all the matching buses, keep track of them over time in a video, and let you interactively fix mistakes. The team also built a giant, high-quality dataset and a new benchmark (SA-Co) to train and test SAM 3 on millions of different concepts.
Goals and Questions
The researchers wanted to solve a more general and useful version of “segment anything”:
- Instead of finding one object at a time with clicks or boxes, can we find and segment all instances of a concept (like “cats” or “red apples”) across an image or a video?
- Can this work with simple text prompts (short noun phrases) and image examples, and keep identities consistent in videos?
- Can it work for a huge variety of concepts, not just a fixed list of categories?
- Can it be interactive, fast, and accurate enough for real-world uses?
How did they do it?
What is Promptable Concept Segmentation (PCS)?
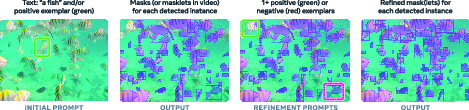
Imagine you say “striped cat” or draw a box around one striped cat in a photo. PCS means the model should:
- Find all striped cats in the entire image or video
- Color in each one precisely (a “segmentation mask” is like painting the exact pixels that belong to the object)
- In videos, keep track of which cat is which across frames (so each cat has a consistent ID over time)
- Let you add more examples or clicks to refine the result if it misses something or makes mistakes
To keep things clear and reliable, prompts are limited to short noun phrases (like “red apple” or “soccer ball”) rather than long sentences that require complex reasoning.
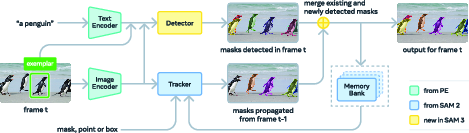
How the model works
Think of SAM 3 as two main parts working together:
- The detector (for images): This is like a smart searchlight. It reads your prompt (text or example boxes), looks at the image, and proposes where matching objects are, along with their “cutouts” (masks).
- It uses a DETR-style transformer (a type of neural network) and a shared vision backbone called a Perception Encoder.
- A special “presence head” helps the detector separate two jobs:
- Recognition (is this concept even present in the image?)
- Localization (where are the matching objects?)
- The “presence token” acts like a global “is it here?” switch that improves accuracy, especially when the model sees tricky, similar-looking non-matches (called “hard negatives”).
- The tracker (for videos): This is like a follow-cam that remembers what each object looks like and where it was, and updates its position mask as the video plays.
- It inherits the memory-based approach from SAM 2, using “masklets” (think of them as sticky labels attached to each object across frames).
- It matches tracked objects with fresh detections and fixes common problems like occlusions by refreshing its memory from the detector’s high-confidence results.
Interaction and examples:
- You can add image exemplars: boxes marked “positive” (this is the thing) or “negative” (this is not the thing) to help the model include or exclude similar objects.
- You can refine individual masks with clicks, like in earlier SAM versions.
- Training happens in stages: pretrain the vision backbone, train the detector, fine-tune it, then train the tracker.
Building the dataset and benchmark
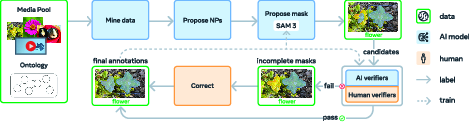
Good data is crucial. The team created a “data engine” that combines humans and AI to curate and verify labels at huge scale:
- Media curation: They pulled images and videos from diverse sources, not just one type of dataset.
- Label curation: AI models propose many noun phrases, including hard negatives (tricky look-alikes), guided by a concept “ontology” (a map of categories).
- Label verification: Fine-tuned multimodal LLMs act as “AI verifiers” to check mask quality and whether all instances have been found, doubling the annotation speed versus humans alone. Humans focus on the toughest cases.
What they built:
- High-quality training data with roughly 4 million unique phrases and over 50 million masks
- A synthetic dataset at extreme scale (over a billion masks) generated by the mature pipeline
- SA-Co benchmark: a public evaluation set with about 207,000 unique concepts across more than 120,000 images and videos, designed to test open-vocabulary segmentation and tracking
Handling ambiguity:
- Some phrases can be vague or have multiple meanings (“mouse” animal vs. “mouse” device).
- They reduce ambiguity with clear guidelines, collect multiple human annotations per item, and evaluate in a way that allows several valid interpretations.
Main Findings
Here are the key results the paper reports:
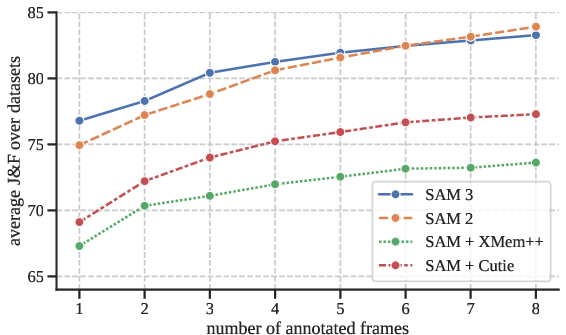
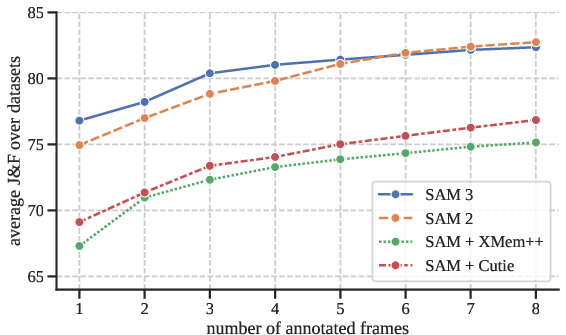
- Accuracy: SAM 3 is about twice as accurate as previous systems on the new SA-Co benchmark, and sets new state-of-the-art results in many image and video tests (for example, a big jump in the LVIS segmentation metric).
- Speed: On a strong GPU, SAM 3 can process a single image with more than 100 objects in about 30 milliseconds. In video, it runs near real-time with around five objects.
- Video tracking: It handles open-vocabulary video instance segmentation well, keeping object identities consistent across frames and outperforming strong baselines.
- Interactivity: Adding just a few exemplar boxes quickly improves results compared to text-only prompting. You can then switch to fine-grained clicks (classic SAM style) to polish individual masks.
- Counting: It beats several LLMs on object counting tasks while also returning precise masks for each counted object.
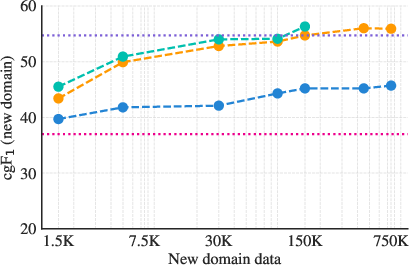
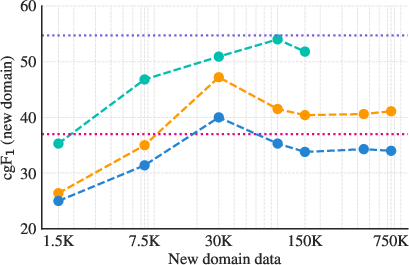
- Few-shot transfer: With only a handful of examples from new domains, SAM 3 adapts better than popular detection systems and generalist LLMs.
- Complex language via an agent: When paired with an MLLM “agent” that plans step-by-step noun phrases and checks masks, SAM 3 handles more complex query types without extra training, outperforming prior zero-shot methods.
Why this is important
- Practical uses: This kind of “segment anything with concepts” is useful for robotics (finding all the parts or tools), video editing (cutting out multiple objects), augmented reality (labeling what you see), and science (counting and tracking organisms or cells).
- Open vocabulary: Because SAM 3 works with short phrases instead of a fixed list of categories, it’s flexible enough for real-world variety and rare concepts.
- Human + AI data pipeline: Their data engine shows a scalable way to build huge, high-quality datasets, using AI to speed up verification while keeping humans in the loop for the hardest cases.
- Interactivity: Being able to guide and correct the system with examples and clicks makes it practical and dependable.
- Building blocks for multimodal AI: SAM 3 combines vision, language, and memory. It can be plugged into larger systems (like LLMs) to handle complex instructions, moving us closer to helpful multimodal assistants.
In short, SAM 3 takes a big step from “segment one thing” to “segment all things of a concept,” across images and videos, with strong accuracy, speed, and interactivity—and it comes with open-source code and a robust benchmark to help the community build on it.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for future research.
- Language coverage: the system and datasets appear primarily English NP–centric; multilingual prompts, cross-lingual synonymy, and polysemy are untested and unsupported.
- Beyond simple noun phrases: handling long referring expressions, compositional queries, and reasoning-heavy prompts is delegated to external MLLMs; there is no principled, native treatment inside SAM 3.
- Formal prompt semantics: the model’s behavior is “undefined” when prompts conflict (e.g., mixing category-level text with part-level exemplars); a formal semantics for prompt consistency, logical composition (AND/OR/NOT), part–whole relations, and attribute constraints is missing.
- Cross-image exemplars: exemplars are defined as in-frame boxes; support for gallery-style exemplars from separate images, multiple views, or synthetic references, and their impact on generalization, is not studied.
- Attribute prompts: robustness to attribute-boundary ambiguities (e.g., “large,” “cozy,” “striped,” color under lighting changes) and how to calibrate such attributes for consistent segmentation is not addressed.
- Video length and scale: PCS is scoped to short videos (≤30 s) with near real-time performance for ~5 concurrent objects; scaling to longer streams, higher object counts, and memory constraints is untested.
- Re-identification under long occlusions: the tracker uses single-frame propagation, IoU matching, and periodic re-prompting; learned association, long-term re-ID, ID-switch analysis, and recovery after long disappearances are not explored.
- End-to-end training: detector and tracker are trained separately with the backbone frozen for tracking; joint multi-task training, shared objectives, and trade-offs between identity separation and open-vocab detection are open.
- Memory bank policies: dynamic memory management (size, eviction, confidence gating), prevention of drift, and retention policies for long videos are heuristic; learned memory policies and their effects are unstudied.
- Multi-concept and concurrent prompts: PCS handles one concept at a time; segmentation of multiple concepts concurrently, inter-concept conflicts, and cross-concept identity maintenance are not supported.
- Calibration and thresholds: main metrics enforce a fixed 0.5 confidence threshold; per-phrase calibration, reliability curves, threshold optimization, and deployment-specific cost-sensitive evaluation are missing.
- Presence head design space: while effective, the global presence token is one decoupling strategy; alternatives (multi-scale global context, hierarchical gating, phrase-specific presence modules) and their calibration trade-offs are not analyzed.
- Hard-negative sampling: optimal negative phrase generation, sampling distribution, difficulty calibration, and their interactions with presence gating and open-vocab generalization need systematic study.
- Ambiguity measurement: test-time “oracle” scoring over 3 annotators masks disagreement; inter-annotator agreement statistics, ambiguity taxonomies, and model behavior under controlled ambiguous cases are not reported.
- Group masks for tiny objects: the pipeline allows group masks when instances are hard to separate; the impact on training for instance-level segmentation and counting, and conversion strategies from group to instances, are not evaluated.
- Semantic vs. instance heads: the semantic head is binary per prompt; multi-class multi-label semantics, panoptic consistency between semantic and instance outputs, and conflicts between heads are unexamined.
- Data engine biases: ontology- and LLM-driven NP mining may encode domain, cultural, and demographic biases; quantitative audits (by domain, geography, demographics), fairness diagnostics, and bias mitigation strategies are absent.
- AI verifiers: fine-tuned MLLM verifiers are claimed near-human; cross-domain generalization, failure modes, calibration, robustness to distribution shift, and error propagation into training data need auditing.
- Synthetic labels at scale: the 1.4B-mask synthetic dataset’s label quality, noise characterization, and impact on downstream performance and failure modes are not quantified.
- Domain/modal coverage: performance on specialized or non-RGB modalities (e.g., infrared, depth, medical, satellite, underwater) is unknown; transfer and adaptation strategies for such domains are not explored.
- Counting in dense scenes: counting results cover limited benchmarks; dense, tiny-object scenes, temporal counting across videos, and reconciliation between detection-based and track-based counts are open.
- Agent orchestration: the “SAM 3 Agent” lacks analysis of termination criteria, prompt selection policies, number of tool calls, robustness across MLLMs, and failure recovery; a benchmark for complex reasoning segmentation is needed.
- Interactive strategy: PCS plateaus after ~4 clicks; algorithms to automatically recommend when to switch from global PCS to local PVS, suggest optimal positive/negative exemplars, and minimize user interaction are not developed.
- Boundary policies: consistent treatment of part vs. whole (e.g., “mirror” including frame, “car” excluding roof rack) is not formalized; per-class extent policies and their incorporation into training/evaluation are missing.
- Exhaustivity in video: verifying “all instances found across frames” relies on heuristics and limited human checks; systematic measures of per-concept recall, temporal exhaustivity, and targeted mining for misses are lacking.
- Identity persistence and state changes: how identities persist through appearance changes, occlusions, or concept transitions (e.g., “person” to “cyclist”) is not characterized.
- Real-time deployment: latency and memory on commodity GPUs, mobile/edge devices, and under resource constraints (e.g., many tracked objects) need profiling and optimization (e.g., quantization, distillation).
- Safety, privacy, licensing: data sourcing, consent, privacy preservation, and license compliance in the large-scale data engine are not discussed; reproducible, privacy-preserving pipelines are an open need.
- Robustness to adversarial or inconsistent prompts: explicit detection and user feedback for ungroundable, adversarial, or inconsistent prompts (e.g., conflicting positive/negative exemplars) are missing.
- Cross-image generalization of exemplars and negatives: leveraging exemplars from different scenes or synthetic prototypes to improve rare-concept recall and reduce false positives is untested.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that can be implemented now, leveraging SAM 3’s promptable concept segmentation, interactive refinement, video tracking, open-source release, and AI-in-the-loop data engine.
- Open‑vocabulary auto‑labeling and pre‑annotation for computer vision datasets (academia, software, robotics, automotive)
- Tools/products/workflows: “Smart Labeling” plugins for CVAT/Label Studio/Roboflow; a cloud “Promptable Segmentation Service” where annotators use noun phrases and exemplar boxes to mass‑label images/videos; incorporation of hard negatives and ontology‑guided phrasing to raise label quality and recall.
- Assumptions/dependencies: GPU availability for near real‑time throughput (e.g., ~30 ms per image on H200, real‑time for ~5 objects in video); domain adaptation may be required for non‑natural scenes; consistent noun‑phrase prompts to avoid ambiguity.
- Video editing with intelligent object selection and tracking from natural language (media, creator tools, AR/VR)
- Tools/products/workflows: “Segment by phrase” for video editors; live tracking and compositing of “all ‘yellow school bus’ instances”; interactive refinement with exemplar boxes and clicks; background removal and scene relighting based on segmented masks.
- Assumptions/dependencies: Cloud inference or workstation‑class GPUs; limits on very crowded scenes; UI integration for iterative refinement.
- Content moderation and brand safety (policy, trust & safety, advertising)
- Use cases: Detect and mask/remove objects like “gun,” “alcohol,” “explicit logos,” or “nudity‑related regions” across platforms; enforce regional policy variations via prompt sets and hard negatives; compute calibrated image‑level presence scores to reduce false alarms.
- Assumptions/dependencies: Careful phrase design to avoid polysemy (“mouse” animal vs device) and cultural context; human review for borderline cases; privacy/legal compliance.
- E‑commerce product tagging, attribute extraction, and shoppable content (retail, marketing)
- Use cases: Segment all “red sneakers,” “striped dresses,” “logo placements” across user photos/videos; generate clean product cutouts; count inventory in visual audits; auto‑create shoppable videos by tracking product instances.
- Assumptions/dependencies: Ontology of product attributes; handling subjective modifiers (“cozy,” “luxury”) with stricter definitions; scalable serving for large catalogs.
- Robotics perception in controlled environments (lab automation, warehouse robotics)
- Use cases: Prompt robots to find and track “metal screws,” “wooden pallets,” “green bins” and perform pick‑and‑place or inspection; switch quickly to new noun phrases without retraining; interactive corrections when scene changes.
- Assumptions/dependencies: Edge inference or low‑latency streaming; the task scope remains atomic NP concepts (no full reasoning); careful evaluation for safety‑critical deployment.
- Industrial inspection and defect localization (manufacturing, quality control)
- Use cases: Segment “paint bubbles,” “scratches,” “missing bolts” in frames; count defect occurrences; deploy noun‑phrase prompts per SKU or defect taxonomy; use tracking to follow defects across production stages.
- Assumptions/dependencies: Defect visibility and consistent ontology; subjectivity in defect severity; potential few‑shot fine‑tuning for rare defects.
- Precision agriculture and environmental monitoring (agriculture, conservation)
- Use cases: Count and segment “ripe apples,” “grapes,” “pests,” “weeds” from drone or handheld video; derive yield estimates; track wildlife (“deer,” “birds”) for conservation.
- Assumptions/dependencies: Domain shift across seasons/lighting; exemplar‑guided refinement when objects are small/occluded; edge‑GPU or offline batching.
- Healthcare and life sciences pre‑annotation and counting (healthcare, bioimaging)
- Use cases: Segment “cells,” “nuclei,” “tissue regions,” count instances per slide; accelerate dataset creation for downstream medical models; use presence head for better calibration in triage.
- Assumptions/dependencies: Domain‑specific validation and regulatory constraints; potential few‑shot adaptation for specialized modalities (e.g., fluorescence microscopy); expert supervision.
- Traffic analytics and smart city operations (transportation, public sector)
- Use cases: Segment and count “bicycles,” “buses,” “pedestrians,” “construction cones” for planning and compliance; track flows across cameras; test scenarios without retraining via text prompts.
- Assumptions/dependencies: Privacy and policy compliance; calibrated thresholds to avoid over‑enforcement; handling occlusions and crowding.
- Academic benchmarking and method development (academia)
- Use cases: Adopt SA‑Co for open‑vocabulary segmentation and tracking evaluation; study ambiguity handling via multi‑annotator comparisons; reuse the presence head to decouple recognition/localization in new architectures; explore scaling laws and hard‑negative mining.
- Assumptions/dependencies: Reproducible setup and compute access; clear prompt protocols to minimize ambiguity in experiments.
- Analytics and counting modules for operations dashboards (software, retail, logistics)
- Use cases: Deploy SAM 3’s counting capability for “number of boxes on pallet,” “cars in lot,” “people in queue”; expose counts with masks for auditability; integrate time‑series analytics via video tracking.
- Assumptions/dependencies: Controlled camera placement; phrase normalization; integration with BI pipelines.
- Photo organization and consumer utilities (daily life)
- Use cases: Search “all photos with striped cats,” “red backpack,” auto‑make albums; background removal for product listings; quickly blur sensitive regions (“license plates,” “faces”) using text prompts.
- Assumptions/dependencies: On‑device optimization or cloud processing; privacy settings; disambiguation UI when prompts are vague.
- Replicable AI‑in‑the‑loop data engine for faster, cheaper annotation (industry, academia, public sector)
- Tools/products/workflows: Port the paper’s MV/EV pipeline—fine‑tuned MLLMs as “AI verifiers,” noun‑phrase proposal with ontology mining, hard‑negative generation—to your domain to double throughput; prioritize human effort on difficult edge cases.
- Assumptions/dependencies: Availability of domain ontologies; small amounts of domain‑specific human labels to bootstrap verifiers; governance for AI‑assisted labeling.
- SAM 3 Agent for complex text queries via MLLMs (software, media, R&D)
- Use cases: An agent that decomposes complex requests (“segment the person carrying the blue umbrella behind the bus”) into NP prompts, iteratively refines masks, and returns results; integrates with Gemini/Qwen/Llama‑based systems.
- Assumptions/dependencies: Reliability and latency of the chosen MLLM; standardized system prompts; fallback to interactive exemplars when reasoning is required.
Long‑Term Applications
These use cases are feasible with additional research, scaling, optimization, or policy development.
- On‑device, real‑time multi‑object concept segmentation for mobile AR and wearables (AR/VR, consumer hardware)
- Potential products: Smartphone SDKs and smart‑glasses apps that let users segment “all mugs” or “my keys” in live view.
- Dependencies: Model compression, distillation, and efficient backbones; energy‑aware scheduling; robust performance beyond ~5 concurrent objects.
- Safety‑critical robotics and autonomous driving perception (robotics, automotive)
- Use cases: Open‑vocabulary perception in dynamic, crowded scenes; “find all road hazards,” “temporary signage” without retraining.
- Dependencies: Certified safety pipelines, formal verification, extensive domain adaptation; robust occlusion handling; low‑latency edge compute.
- Regulatory standards for AI‑assisted annotation and open‑vocabulary benchmarks (policy, standards bodies)
- Use cases: Formalize MV/EV tasks and ambiguity protocols; publish domain‑specific SA‑Co variants; require calibrated presence scores in procurement specs.
- Dependencies: Multi‑stakeholder consensus; bias and fairness audits; transparent reporting of model/MLLM verifier performance.
- Automated video post‑production with semantic directives (media, entertainment)
- Use cases: “Replace all ‘brand logos’ with generative fills,” “retime scenes when ‘main actor’ is present,” “track props across shots.”
- Dependencies: Robust tracking through occlusion and shot changes; advanced reasoning agents; integration with generative editing tools.
- Scientific discovery workflows with open‑vocabulary segmentation (sciences, R&D)
- Use cases: Microscopy and field videos segmented by evolving concept taxonomies (“motile cells with elongated morphology,” “insect species”); automated hypothesis testing via counts and tracks.
- Dependencies: Domain ontologies and expert curation; cross‑modal alignment to experimental metadata; specialized finetuning.
- Privacy‑preserving edge analytics (public sector, enterprise)
- Use cases: On‑camera segmentation/counting for “faces,” “license plates,” “badges,” emitting only aggregates or masked frames to protect privacy.
- Dependencies: Edge hardware and secure enclaves; policy frameworks; adversarial robustness.
- Intelligent data engines for low‑resource domains (global health, public datasets)
- Use cases: Rapidly bootstrap labeled datasets for rare languages or underserved regions using AI verifiers and human‑in‑the‑loop corrections.
- Dependencies: Localized ontologies; human capacity building; evaluation protocols for cross‑cultural ambiguity.
- Multimodal assistant systems with compositional reasoning (software agents)
- Use cases: Agents chain SAM 3 segmentation with spatial reasoning (“segment ‘the third car from the left of the red hydrant’”), grounding long referring expressions and scene graphs.
- Dependencies: Improved agent planning, memory, and grounding; benchmarks of compositional visual tasks; latency‑aware tool orchestration.
- Generative “segment‑to‑synthesize” pipelines (media, synthetic data)
- Use cases: Use SAM 3 masks to drive controllable image/video generation, domain randomization, and synthetic dataset creation with ground‑truth instance masks and IDs.
- Dependencies: Stable generative models; alignment to target distributions; QA of synthetic labels.
- Cross‑domain, open‑vocabulary evaluation ecosystems (academia, community)
- Use cases: Community‑maintained SA‑Co extensions (e.g., medical, satellite, industrial) with standardized metrics (classification‑gated F1, multi‑annotator oracle scoring).
- Dependencies: Funding and governance; clear licensing; reproducible pipelines and baselines.
- Adaptive retail operations and inventory robots (retail, logistics)
- Use cases: Robots dynamically re‑prompt to new product concepts without retraining; combine segmentation + counting + tracking for automated shelf audits.
- Dependencies: Robustness to packaging changes; human‑robot interaction protocols; integration with store systems.
- Scene‑level analytics for urban planning and ESG reporting (policy, enterprise)
- Use cases: Measure “pedestrian accessibility,” “green cover,” “waste bins,” “wheelchair ramps” at scale from imagery.
- Dependencies: Calibrated thresholds; auditor‑verified ontologies; periodic model auditing for drift.
- Universal photo/video search by fine‑grained attributes (consumer apps)
- Use cases: Search “striped cat on a sofa,” “person with blue umbrella,” “car with roof rack” across personal libraries.
- Dependencies: Efficient indexing of masks and attributes; privacy controls; UI for ambiguity resolution.
- Medical decision support (healthcare)
- Use cases: Pre‑screen scans by segmenting and counting particular findings; route to specialists.
- Dependencies: Clinical validation, regulatory approvals, domain‑specific finetuning, comprehensive safety monitoring.
Notes on Assumptions and Dependencies (applicable across items)
- Compute and latency: H200 benchmark suggests server‑side deployment is practical; edge/mobile use will require optimization, compression, or distillation.
- Prompt design: SAM 3 expects atomic noun phrases; long referring expressions need an MLLM agent layer; ambiguous prompts require interactive refinement.
- Domain shift: High performance in natural scenes; specialized domains may need few‑shot fine‑tuning and tailored ontologies.
- Calibration and thresholds: The paper’s evaluation emphasizes calibrated presence scores; production systems should gate masks on presence confidence and implement human review loops.
- Ethics, privacy, and compliance: Applications in surveillance, healthcare, and public spaces require governance, minimization of personally identifiable information, and adherence to regional laws.
- Data licensing and reproducibility: SA‑Co and SAM 3 are open sourced; ensure license‑compatible use and reproducible pipelines when porting the data engine.
Glossary
- Align loss: A training loss used in detection-transformer models to better align predictions with targets. "During training, we adopt dual supervision from DAC-DETR~\citep{NEURIPS2023_edd0d433}, and the Align loss~\citep{aligndetr}."
- average precision (AP): A standard detection metric summarizing precision–recall performance (area under the curve). "Detection metrics such as average precision (AP) do not account for calibration,"
- box-region-positional bias: A positional prior that guides attention to focus near candidate box regions. "We use box-region-positional bias~\citep{plaindetr} to help focalize the attention on each object,"
- calibration: The degree to which model confidence scores reflect true likelihoods of correctness. "Detection metrics such as average precision (AP) do not account for calibration,"
- classification logit: The raw output score (before a sigmoid/softmax) indicating class membership. "Each decoder layer predicts a classification logit for each object query (in our case, a binary label of whether the object corresponds to the prompt),"
- COCO-O: A COCO-derived benchmark focused on out-of-distribution/open-set evaluation. "AP\textsubscript{o} corresponds to COCO-O accuracy,"
- cross-attention: An attention mechanism where one set of tokens attends to another set (e.g., image features to prompts). "The fusion encoder then accepts the unconditioned embeddings from the image encoder and conditions them by cross-attending to the prompt tokens."
- DAC-DETR: A DETR variant that provides dual supervision to improve detection training. "During training, we adopt dual supervision from DAC-DETR~\citep{NEURIPS2023_edd0d433},"
- DETR: A transformer-based object detector framing detection as set prediction with learned queries. "The detector is a DETR-based~\citep{carion2020end} model conditioned on text, geometry, and image exemplars."
- Exhaustivity Verification (EV): An annotation step checking whether all instances of a concept are labeled. "Exhaustivity Verification (EV) annotators check if all instances of the NP have been masked in the input."
- exemplar encoder: A module that encodes user-provided example regions (and labels) into prompt tokens. "Each image exemplar is encoded separately by the exemplar encoder"
- fusion encoder: A module that fuses image features with prompt tokens via attention to condition detection on the prompt. "The fusion encoder then accepts the unconditioned embeddings from the image encoder and conditions them by cross-attending to the prompt tokens."
- gIoU: Generalized Intersection-over-Union, a box-overlap metric improving IoU’s gradient properties. "ReasonSeg (gIoU)"
- hard negatives: Adversarial or confusing negative phrases/examples used to improve open-vocabulary recognition. "by leveraging an ontology and multimodal LLMs as ``AI annotators'' to generate noun phrases and hard negatives,"
- HOTA: A multi-object tracking metric capturing detection, association, and localization quality. "test~HOTA"
- image exemplars: User-provided example regions (positive/negative) to specify or refine the target concept. "SAM 3 supports image exemplars, given as a pair---a bounding box and an associated binary label (positive or negative)---"
- Intersection over Union (IoU): The overlap metric between predicted and ground-truth regions (intersection divided by union). "through a simple IoU based matching function"
- MAE (Mean Absolute Error): An error metric measuring the average absolute difference between predictions and ground truth. "using Accuracy (\%) and Mean Absolute Error (MAE)"
- mask decoder: The component that predicts segmentation masks from encoded features and prompts. "The mask decoder is a two-way transformer between the encoder hidden states and the output tokens."
- masklet: A spatio-temporal mask track representing an object’s segmentation across video frames. "A masklet is initialized for every object detected on the first frame."
- Mask Verification (MV): An annotation step where proposed masks are accepted or rejected based on quality and relevance. "in Mask Verification (MV) annotators accept or reject masks based on their quality and relevance to the NP."
- Matthews Correlation Coefficient (IL): A balanced binary classification metric (here at image level) ranging in [-1, 1]. "Classification is measured with image-level Matthews Correlation Coefficient~(IL) which ranges in "
- memory bank: A store of past-frame features/masks used to propagate and refine tracks over time. "and a memory bank that encodes the object's appearance using features from the past frames and conditioning frames"
- Multimodal LLM (MLLM): A large model that processes both language and visual inputs for reasoning or prompting. "combined with a Multimodal LLM (MLLM) to handle more complex language prompts."
- object queries: Learned tokens in DETR-like models that represent candidate objects to be detected/segmented. "learned object queries cross-attend to the conditioned image embeddings from the fusion encoder."
- open-vocabulary: A setting where the model recognizes concepts beyond a fixed, closed label set. "To address the challenge of open-vocabulary concept detection, we introduce a separate presence head"
- ontology: A structured hierarchy of concepts used to curate and expand label space and negatives. "by leveraging an ontology and multimodal LLMs as ``AI annotators''"
- oracle accuracy: An upper-bound evaluation where the best match among multiple ground truths is used. "We measure oracle accuracy comparing each prediction to all ground truths"
- Perception Encoder (PE): The shared vision backbone that produces aligned embeddings for detection and tracking. "from an aligned Perception Encoder (PE) backbone~\citep{bolya2025PerceptionEncoder}."
- pHOTA: A probabilistic variant of HOTA for tracking evaluation with confidence calibration. "we report 1 and pHOTA metrics (defined in \S\ref{app:video_grounding_details})"
- presence head: A classifier that predicts whether the prompted concept is present, decoupling recognition from localization. "Recognition and localization are decoupled with a presence head, which boosts detection accuracy."
- presence token: A learned global token dedicated to predicting concept presence in the image/frame. "We decouple the recognition and localization steps by introducing a learned global presence token."
- positive micro F1 (pmF1): A localization F1 score computed over positive examples at the instance level. "We evaluate localization using positive micro F1 ()"
- Promptable Concept Segmentation (PCS): The task of detecting, segmenting, and tracking all instances of a concept given text and/or exemplar prompts. "We define the Promptable Concept Segmentation task as follows:"
- Promptable Visual Segmentation (PVS): Prompted segmentation of individual objects using visual prompts like points, boxes, or masks. "focusing on Promptable Visual Segmentation (PVS) with points, boxes or masks"
- prompt tokens: The combined tokenized representations of text prompts and image exemplars used to condition the model. "We refer to the image exemplar tokens and text tokens jointly as ``prompt tokens''."
- ROI-pooled features: Region-of-Interest aggregated features extracted from specified boxes. "and ROI-pooled visual features,"
- self-attention: An attention mechanism where tokens attend to themselves to capture global context. "The memory encoder is a transformer with self-attention across visual features on the current frame and cross-attention"
- tracking-by-detection: A tracking approach that associates per-frame detections into object trajectories. "replacing our tracker with an association module based on the tracking-by-detection paradigm"
- two-way transformer: A transformer that alternates attention between encoded features and output tokens. "The mask decoder is a two-way transformer between the encoder hidden states and the output tokens."
- Video Object Segmentation (VOS): Segmenting objects across video frames, typically with an initial prompt. "including Video Object Segmentation (VOS)"
- zero-shot: Evaluating on concepts or datasets without any task-specific training or fine-tuning. "reaching a zero-shot mask AP of 48.8 on LVIS"
Collections
Sign up for free to add this paper to one or more collections.