- The paper's main contribution is demonstrating that coupling a frequency-domain gait generator with a PPO-based controller yields natural and robust bipedal walking.
- It employs a neural gait generator that encodes human joint angles via FFT and leverages morphological conditioning to adapt to variable speeds and slopes.
- Experimental results reveal high fidelity in joint trajectories, accurate velocity tracking, and resilience to terrain disturbances, outperforming traditional RL and classical controllers.
Frequency-Based Human Imitation for Robust Bipedal Locomotion
Overview
The paper "Human Imitated Bipedal Locomotion with Frequency Based Gait Generator Network" (2511.17387) presents a two-stage control architecture for bipedal walking, integrating human motion-capture-based gait generation with reinforcement learning. The methodology leverages a frequency-domain neural network as a generative motion prior and couples it with a torque-level PPO policy, facilitating adaptive and human-like gaits across varying speeds, slopes, and high-frequency terrain disturbances. The approach emphasizes data-driven human imitation, task-conditioned robustness, and scalable training, establishing a principled pipeline for natural bipedal gait synthesis.
Methodology
Frequency-Based Gait Generator
The first stage involves training a neural gait generator from motion-capture data. Human joint angles are encoded via a 32-point FFT, representing periodic gait cycles. Input features to the generator are desired walking speed and individualized limb lengths, while outputs are full joint angle trajectories over a gait cycle. Morphological conditioning allows the generator to retain individual body dimensions rather than canonicalizing skeletons, enhancing the generalization capacity for synthetic agents or humans with varied sizes.
PPO-Based Imitation Controller
The gait generator provides reference joint trajectories to a PPO-based controller. The full pipeline, illustrated in the controller loop
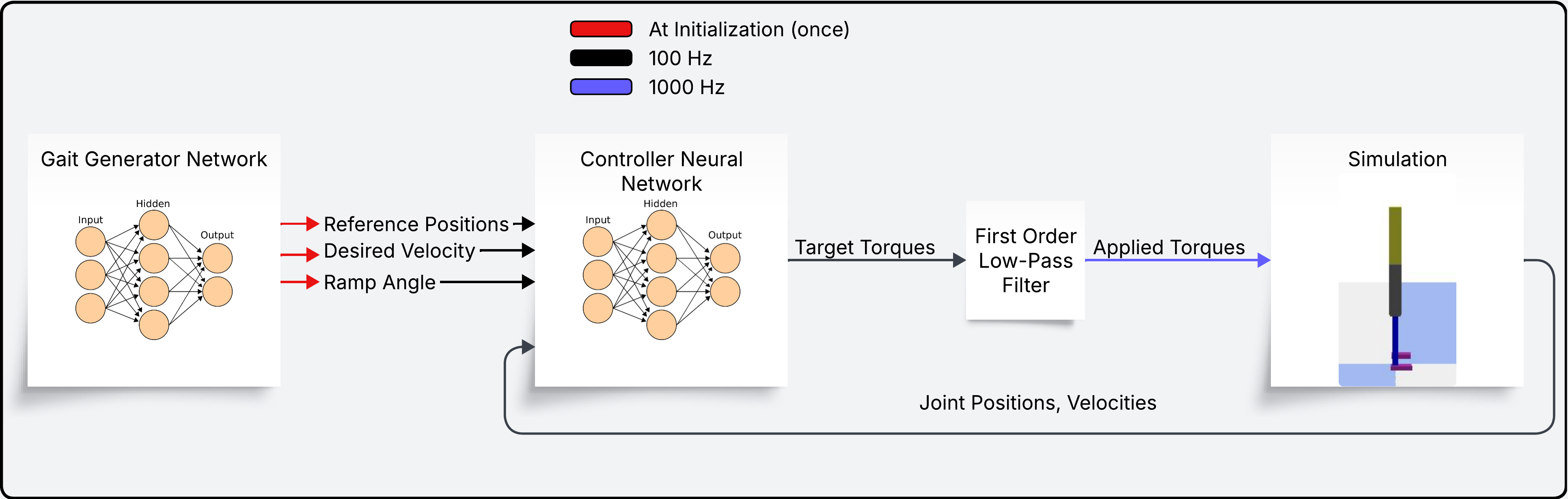
Figure 1: Controller loop depicting the interface between gait generator, reference trajectory preview, and torque-level PPO control.
uses a compact, history-plus-preview observation space incorporating commanded and measured velocity, joint angles, reference previews, and previous torques. Actions are torques issued at 7 DoF of a planar biped model within the Pybullet simulation framework. Policy architectures range from feedforward to recurrent (see policy network configurations in Figure 2).
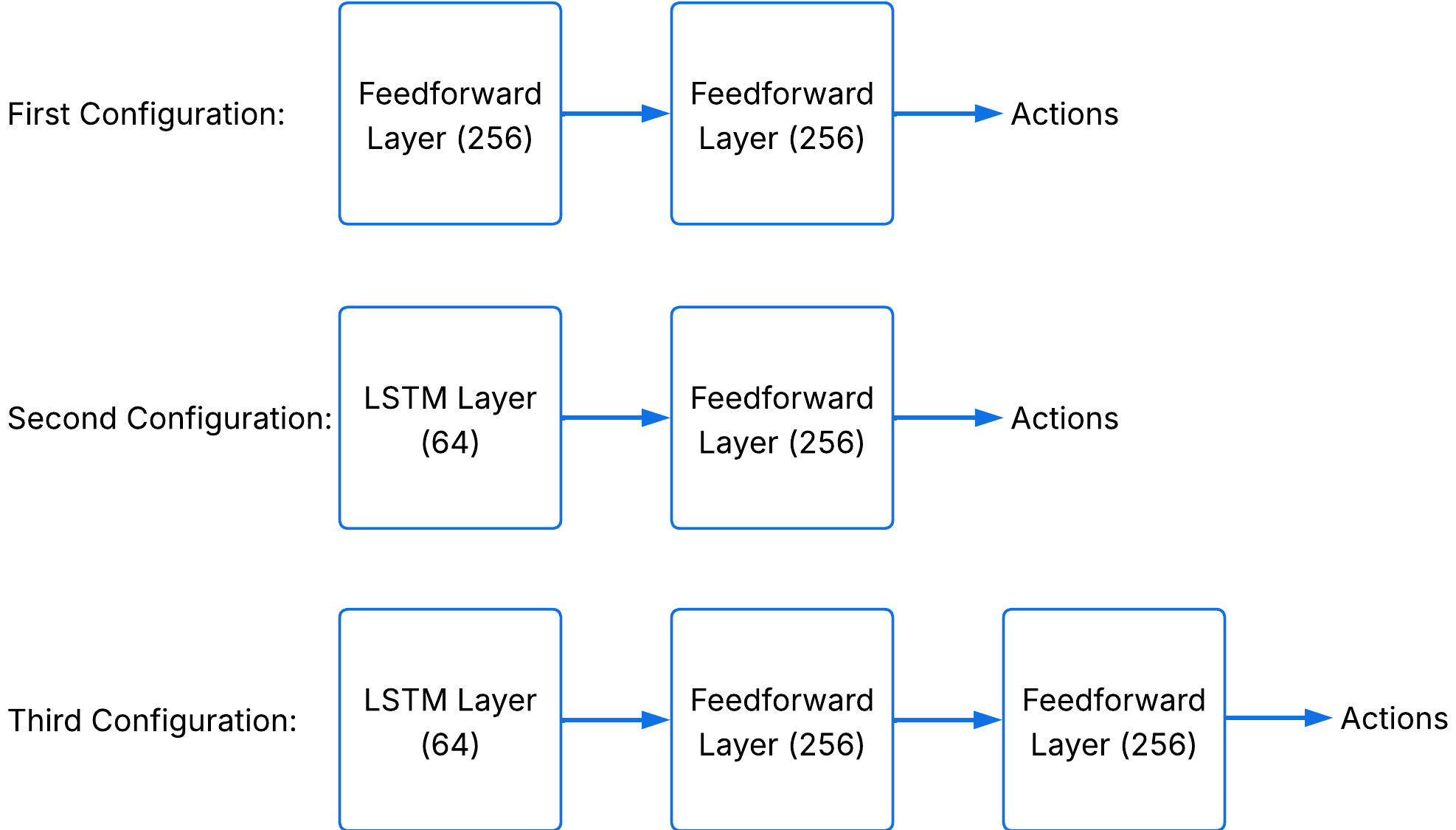
Figure 2: Policy network architectures evaluated, including MLP and recurrent variants.
PPO training leverages RSI for initial state diversity, early episode termination for stability enforcement, and a reward decay schedule for balancing imitation and gait objectives. The reward structure aggregates joint-matching (with differentiated emphasis for hips, knees, and ankles), speed tracking, postural safety, ground contact dynamics, and energy minimization.
Experimental Results
Joint Trajectory Fidelity
Quantitative and qualitative analyses demonstrate that the imitation-based controller produces joint trajectories closely matching motion-capture references at nominal walking speeds. Contrasted with ablated variants (no RSI, omitted imitation reward), fidelity to human movement is notably superior and phase transitions remain smooth over multiple cycles.
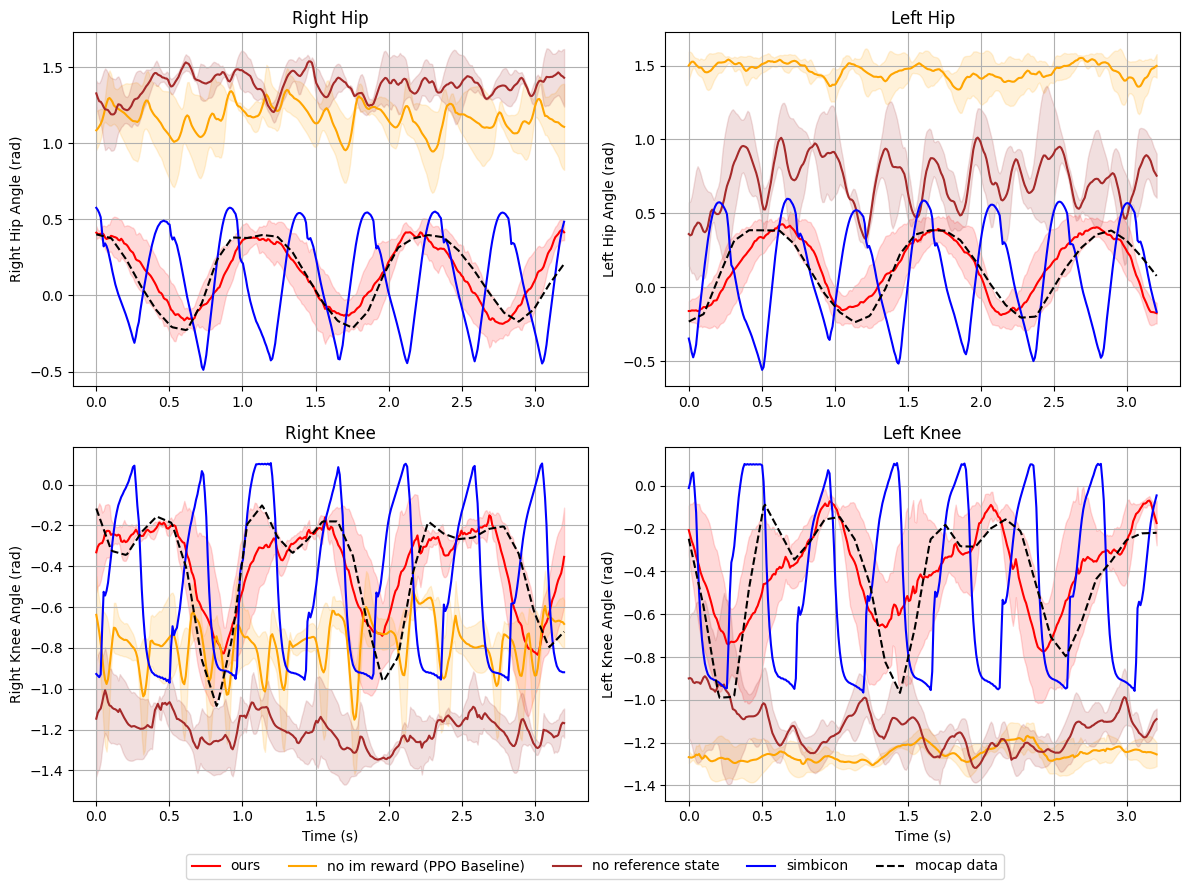
Figure 3: Joint angle trajectory comparison at 1.2 m/s between controller output, ablated variants, and human motion-capture reference.
Velocity Tracking and Speed Generalization
Across a range of commanded velocities ($0$–2.2 m/s), the system tracks speed commands accurately, maintaining errors within 10% up to 1.5~m/s, and only minor degradation at higher speeds. Imputation decay and RSI enhance adaptation at high speeds, surpassing both RL-only and classical controller baselines.
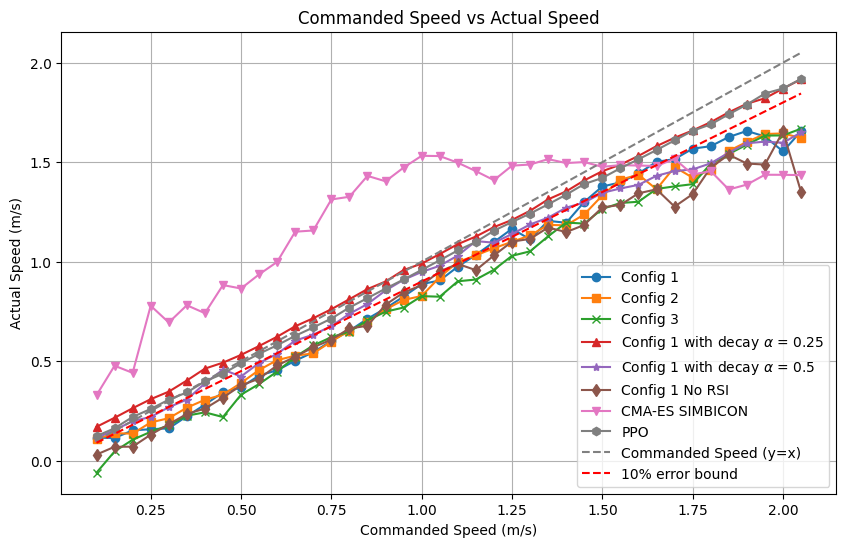
Figure 4: Velocity comparison demo, highlighting linearity between commanded and achieved speed across tested configurations.
Slope Adaptation and Ramp Disturbance Robustness
The PPO-based policies generalize to ramp angles outside training exposure, achieving a success rate exceeding 95% for inclines up to 5∘ and retaining up to 80% performance at 15∘. Notably, performance on declined ramps remains universally high, but recurrent policies and non-RSI variants demonstrate reduced robustness when slope increases.
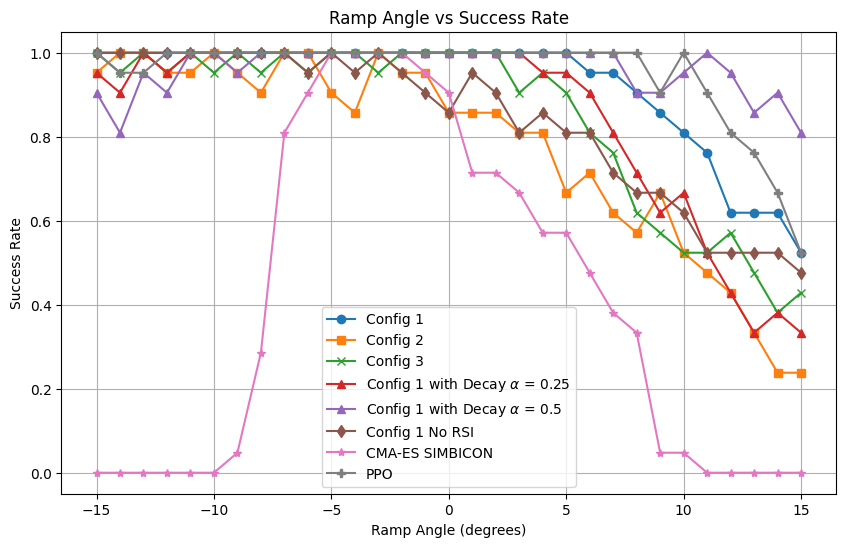
Figure 5: Mean success rate across variable ramp inclinations, illustrating adaptability and generalization.
Terrain Noise Tolerance
The controller's resilience to spatially correlated terrain noise is evaluated on stochastic planes with varying roughness. Traversal range before failure remains high for amplitude perturbations up to $10$–15 cm, with graceful degradation observed for the frequency-based PPO controller relative to recurrent and baseline approaches. Classical (CMA-ES/SIMBICON) references fail under moderate noise, confirming the necessity of human-inspired priors and imitation-driven RL.
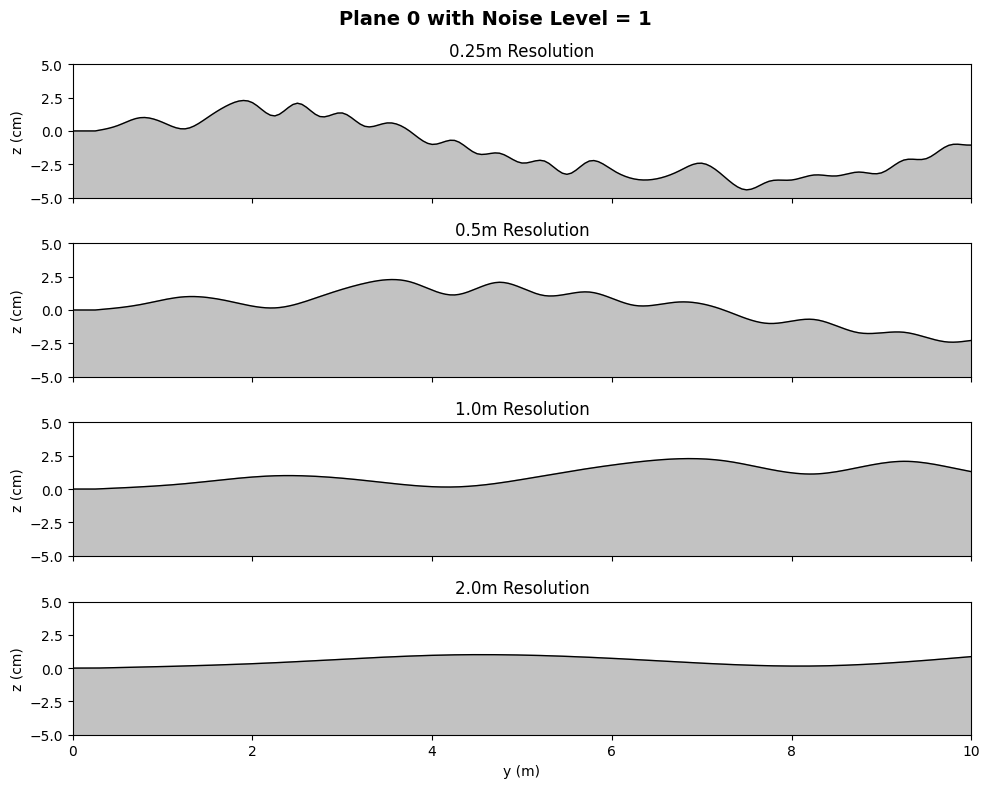
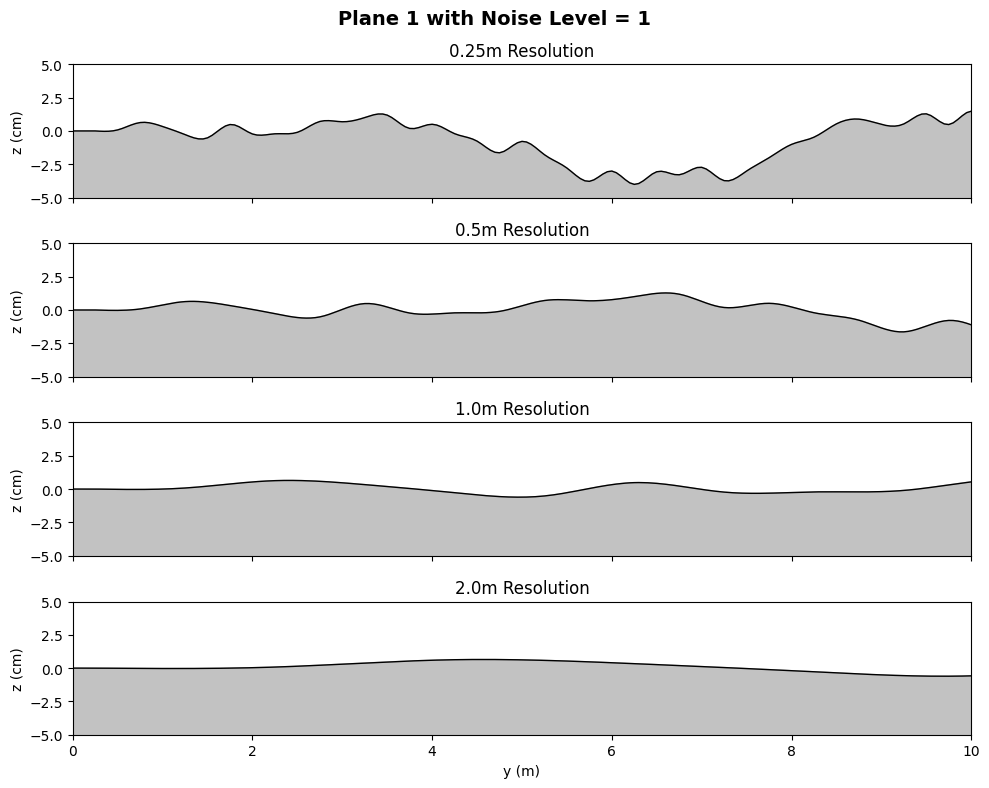
Figure 6: Representative noisy plane profiles for terrain perturbation benchmarking.
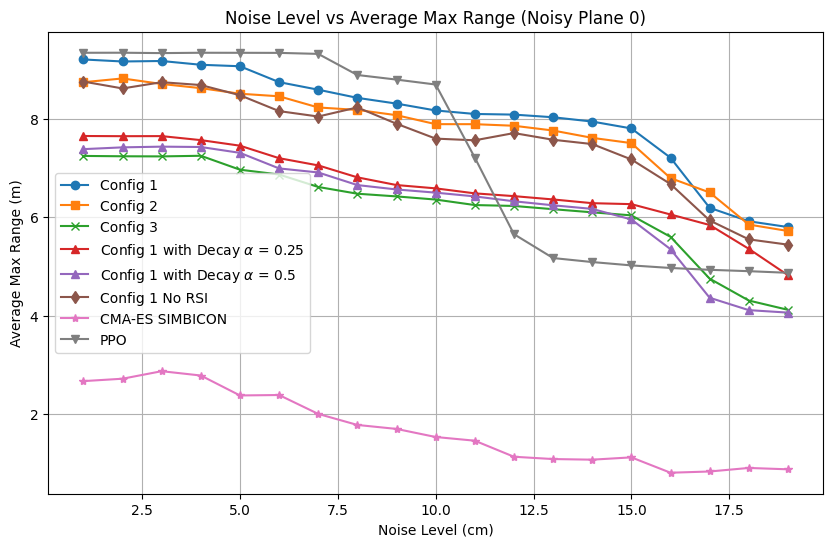
Figure 7: Noisy Plane~0: average max range as a function of terrain noise amplitude.
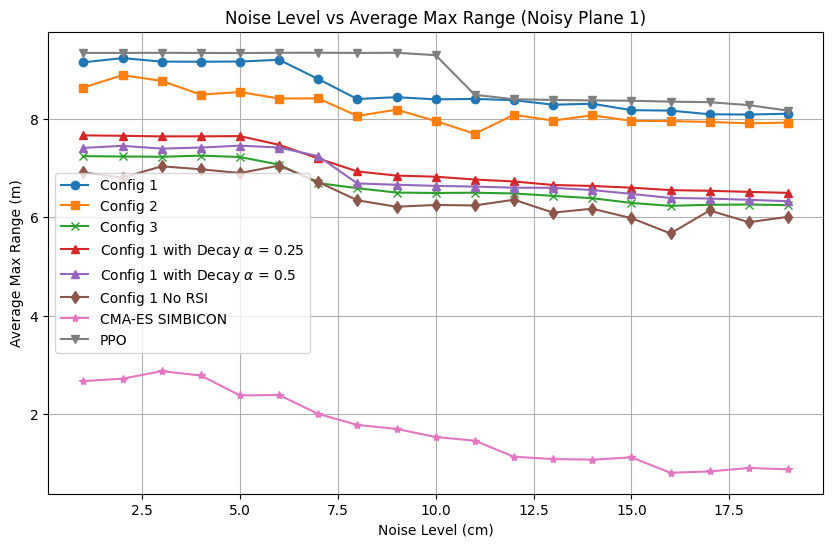
Figure 8: Noisy Plane~1: average max range as a function of terrain noise amplitude.
Transient Velocity Tracking
When required to follow a nonstationary speed profile within a single episode, the controller exhibits smooth transient response, maintaining accurate tracking with modest lag, further validating its online adaptability.
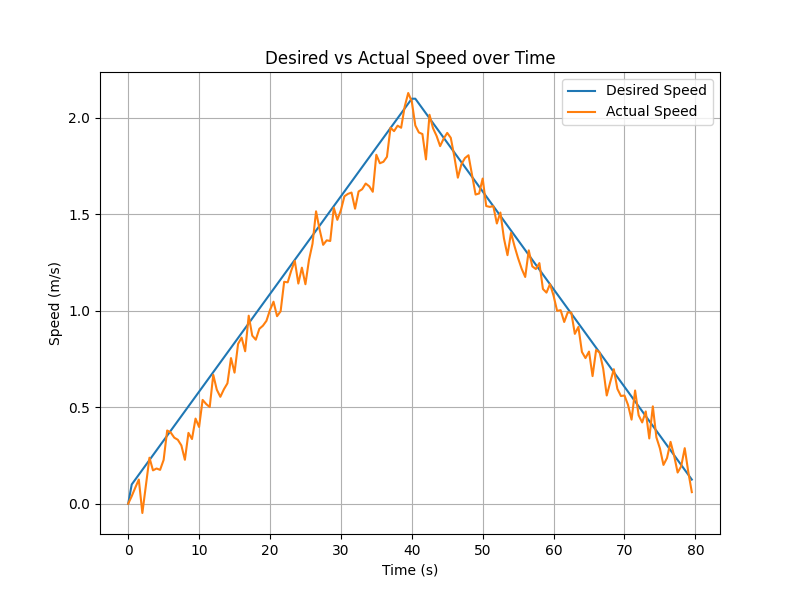
Figure 9: Dynamic velocity tracking over time-varying commanded speed profile.
Implications and Future Directions
The proposed pipeline bridges the representational power of human-derived frequency-domain motion priors with the adaptability of DRL. The results imply that morphological and speed-conditioned imitation is critical for robust locomotion, particularly in unstructured or adversarial environments. Practical implications include the design of scalable locomotion controllers for bipedal robots operating outside laboratory conditions, as well as the potential extension to full-body humanoid agents and prosthetic devices.
Theory-wise, the approach substantiates that compact, morphology-generalizing motion representations coupled with reward scheduling and random state initialization can circumvent the brittleness of classic controllers and the inefficiency of RL-only systems. Training in the spectral domain enables decomposition and synthesis of diverse gait patterns, crucial for data-limited deployments.
Further research will target 3D extensions, integration of richer proprioceptive and exteroceptive feedback, and adaptation to dynamically changing substrates and contacts.
Conclusion
This work demonstrates a principled control framework for bipedal gait generation, coupling a frequency-domain gait generator network with task- and human-imitation-conditioned PPO. Empirical evaluations establish that this design achieves state-of-the-art robustness and fidelity in velocity tracking, slope adaptation, terrain generalization, and transient control in a planar biped simulation. The methodology opens new directions for generalizable, naturalistic bipedal locomotion by unifying human priors and RL within a compact, morphology-aware reference architecture.